Top 5 Workflows Announcements at Data + AI Summit
by Bilal Aslam, Jan van der Vegt, Roland Fäustlin, Robert Saxby and Stacy Kerkela
The Data and AI Summit was chock-full of announcements for the Databricks Lakehouse platform. Among these announcements were several exciting enhancements to Databricks Workflows, the fully-managed orchestration service that is deeply integrated with the Databricks Lakehouse Platform. With these new capabilities, Workflows enables data engineers, data scientists and analysts to build reliable data, analytics, and ML workflows on any cloud without needing to manage complex infrastructure.
Build Reliable Production Data and ML Pipelines With Git Support
We use Git to version control all of our code, so why not version control data and ML pipelines? With Git support in Databricks Workflows, you can use a remote Git reference as the source for tasks that make up a Databricks Workflow. This eliminates the risk of accidental edits to production code, removes the overhead of maintaining a production copy of the code in Databricks and keeping it updated, and improves reproducibility as each job run is linked to a commit hash. Git support for Workflows is available in Public Preview and works with a wide range of Databricks supported Git providers including GitHub, Gitlab, Bitbucket, Azure DevOps and AWS CodeCommit.
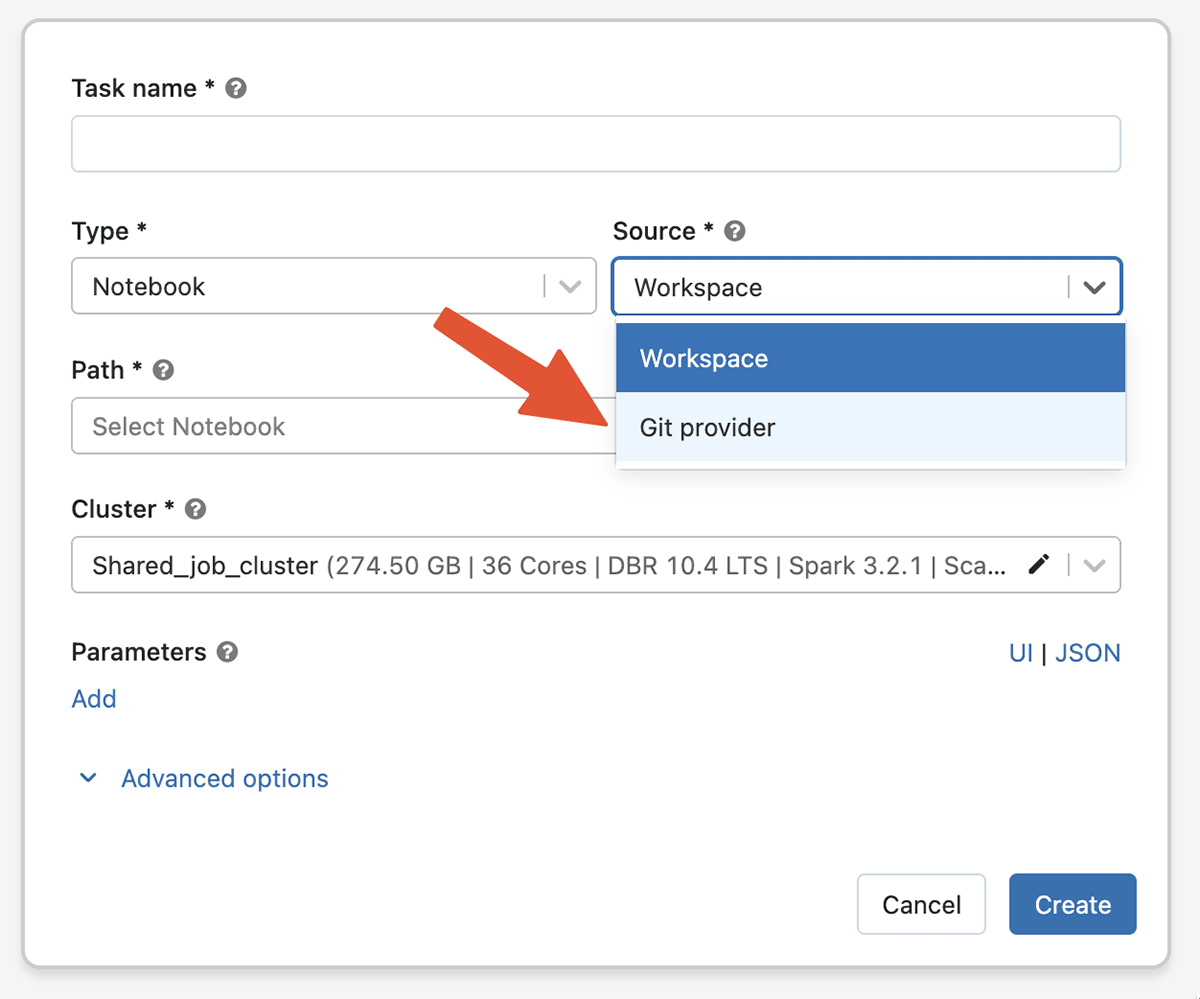
Please check out this blog post to learn more.
Run dbt projects in production
dbt is a popular open source tool that lets you build data pipelines using simple SQL. Everything is organized within directories as plain text, making version control, deployment, and testability simple. We announced the new dbt-databricks adapter last year, which brings simple setup and Photon-accelerated SQL to Databricks users. dbt users can now run their projects in production on Databricks using the new dbt task type in Jobs, benefiting from a highly-reliable orchestrator that offers an excellent API and semantics for production workloads.
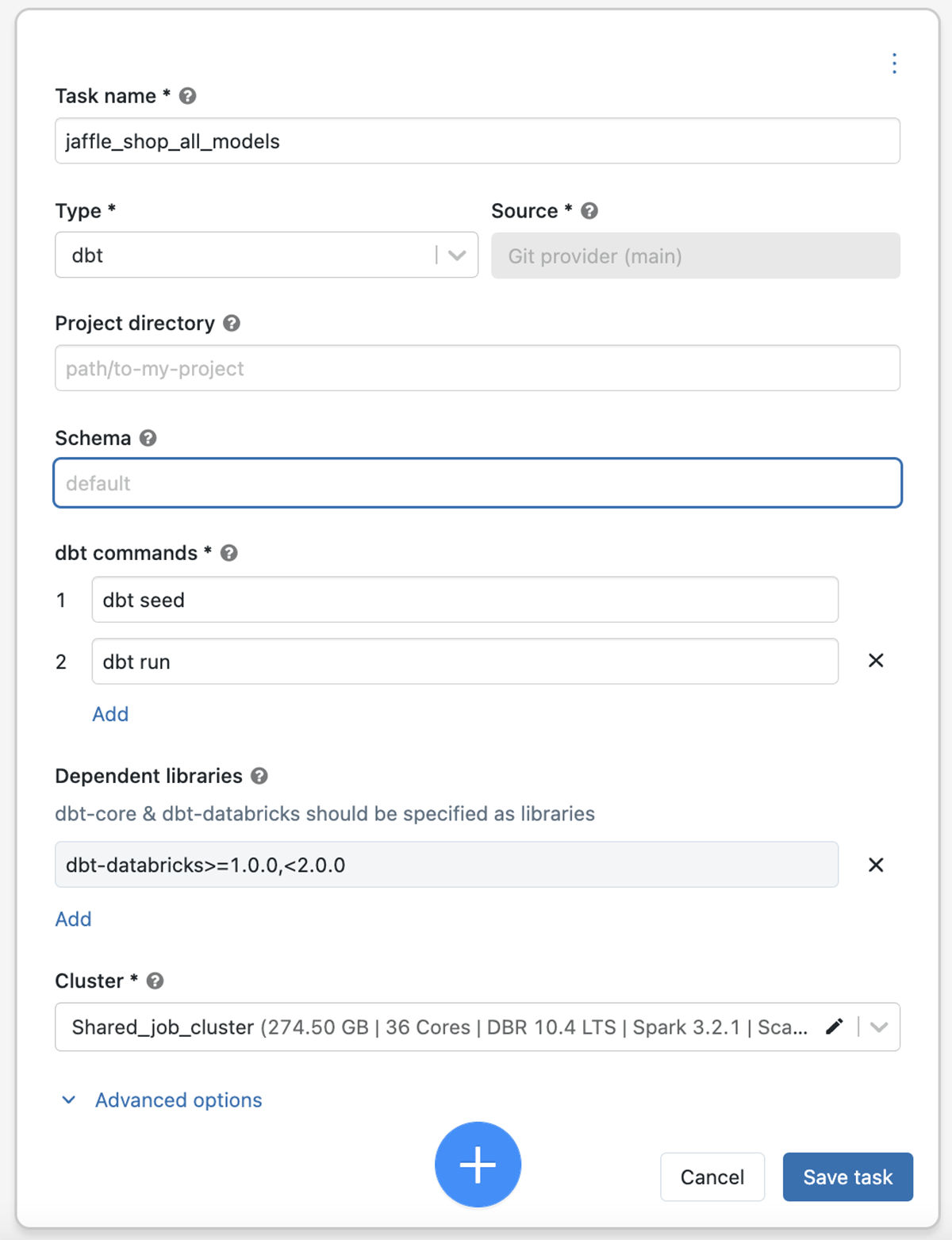
Please contact your Databricks representative to enroll in the private preview.
Orchestrate even more of the lakehouse with SQL tasks
Real-world data and ML pipelines consist of many different types of tasks working together. With the addition of SQL task type in Jobs, you can now orchestrate even more of the lakehouse. For example, you can trigger a notebook to ingest data, run a Delta Live Table Pipeline to transform the data, and then use the SQL task type to schedule a query and refresh a dashboard.
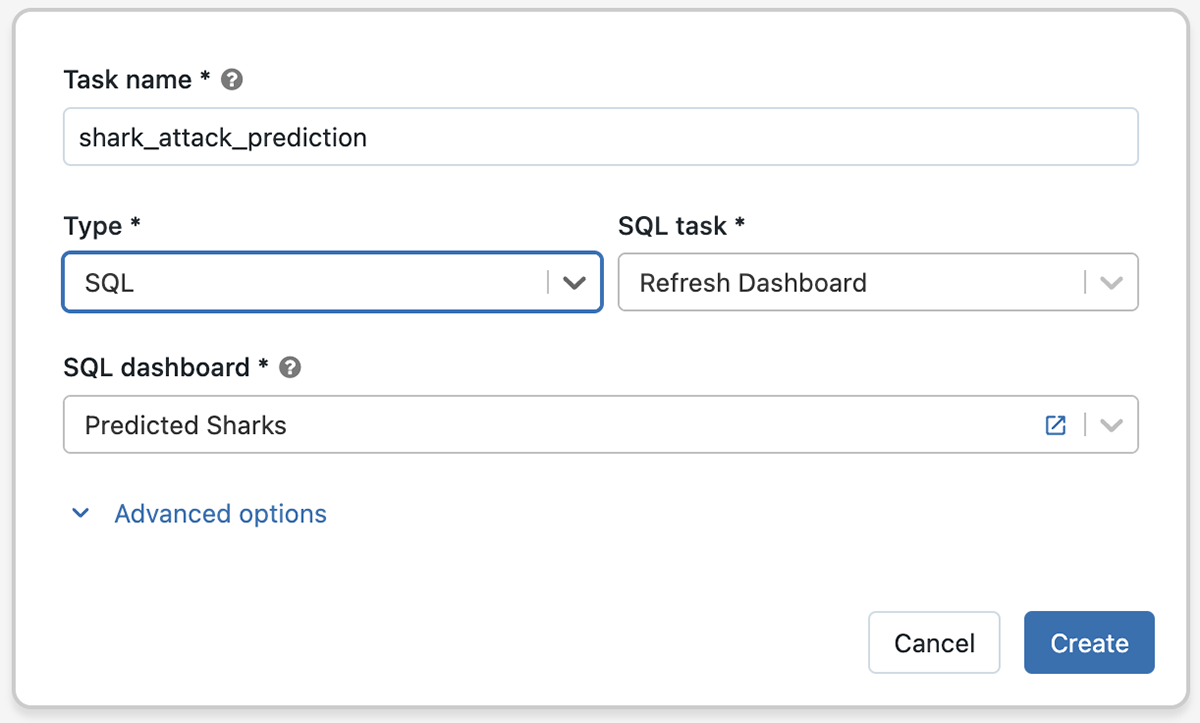
Please contact your Databricks representative to enroll in the private preview.
Save Time and Money on Data and ML Workflows With "Repair and Rerun"
To support real-world data and machine learning use cases, organizations create sophisticated workflows with numerous tasks and dependencies, ranging from data ingestion and ETL to ML model training and serving. Each of these tasks must be completed in the correct order. However, when an important task in a workflow fails, it affects all downstream tasks. The new "Repair and Rerun" capability in Jobs addresses this issue by allowing you to run only failed tasks, saving you time and money.
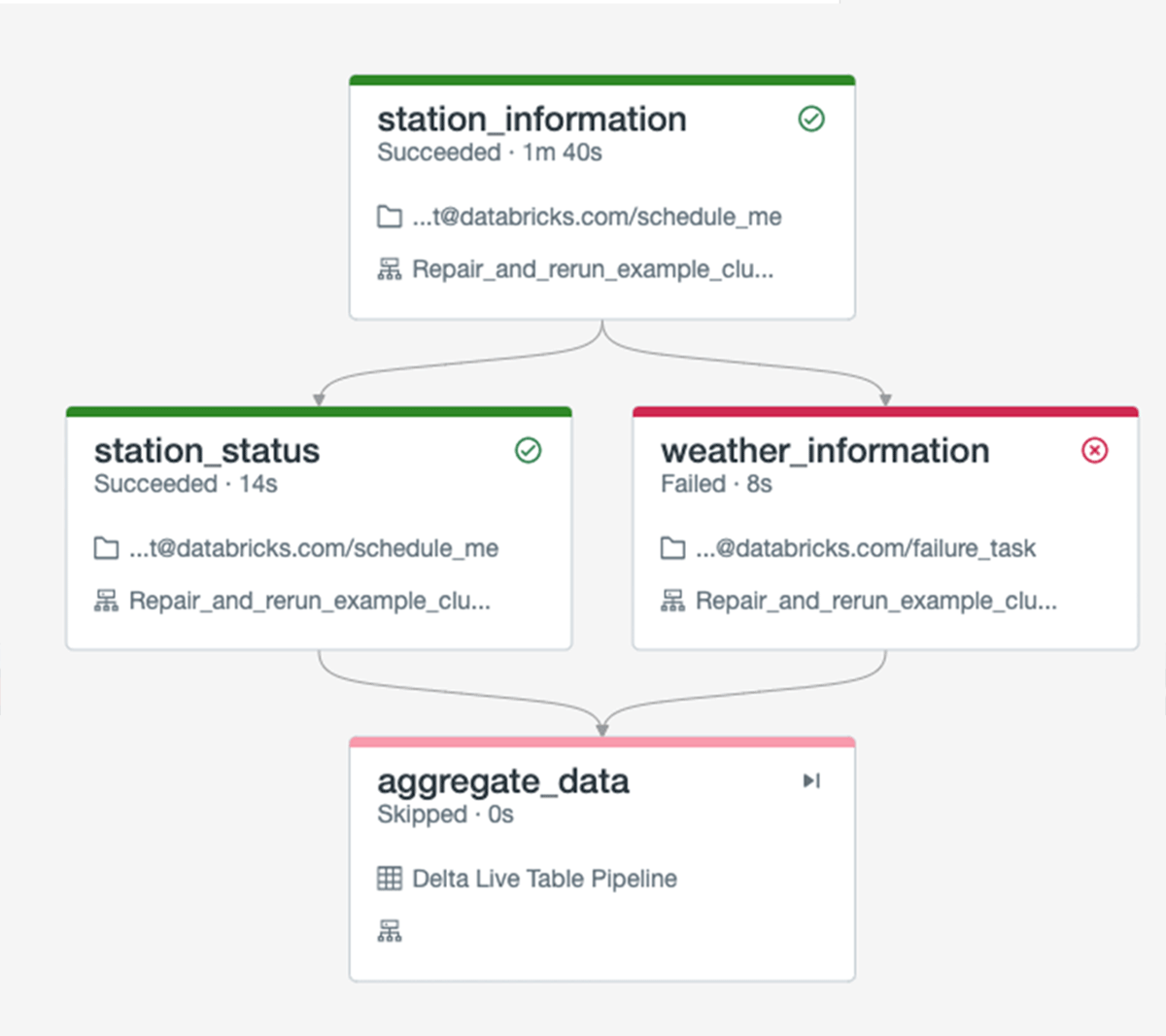
"Repair and Rerun" is Generally Available and you can learn about it in this blog post.
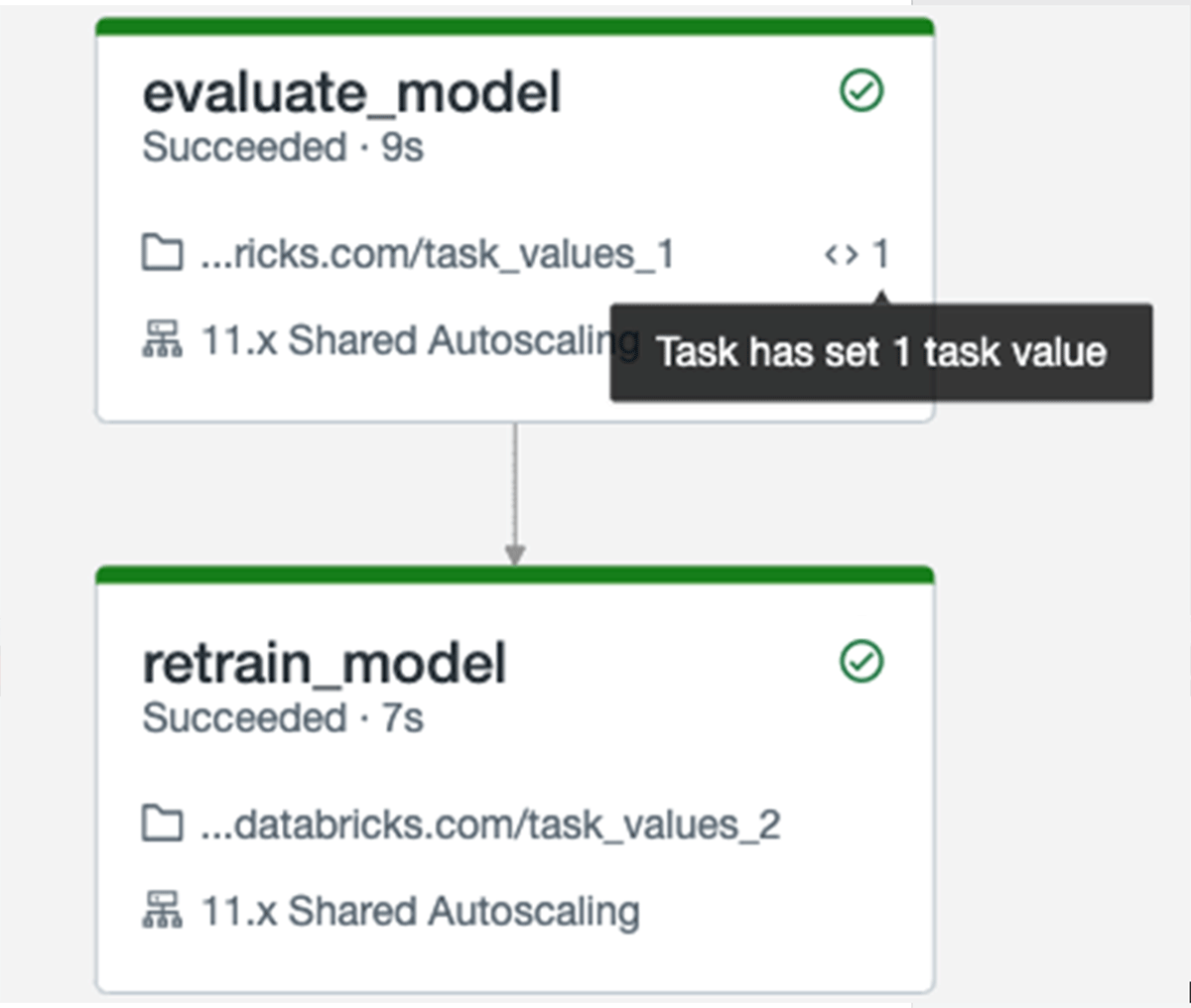
Easily share context between tasks
A task may sometimes be dependent on the results of a task upstream. For instance, if a model statistic (such as the F1 score) falls below a predetermined threshold, you would want to retrain the model. Previously, in order to access data from an upstream task, it was necessary to store it somewhere other than the context of the job, like a Delta table.
The Task Values API now allows tasks to set values that can be retrieved by subsequent tasks. To facilitate debugging, the Jobs UI displays values specified by tasks.
Learn more:
Try Databricks Workflows today
Join the conversation in the Try Databricks Community where data-obsessed peers are chatting about Data + AI Summit 2022 announcements and updates. Learn. Network. Celebrate.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.