Announcing Photon Engine General Availability on the Databricks Lakehouse Platform
Get radical speed at lower costs for all data use cases
by Alexander Behm, Cyrielle Simeone, Justin Breese and Sriram Krishnamurthy
We are pleased to announce that Photon, the record-setting next-generation query engine for lakehouse systems, is now generally available on Databricks across all major cloud platforms. Photon, built from the ground up by the original creators of Apache Spark™ and fully compatible with modern Spark workloads, delivers fast performance with lower TCO on cloud hardware for all data use cases.
Since its launch two years ago, Photon has processed exabytes of data, ran billions of queries, delivered benchmark-setting price/performance at up to 12x better than traditional cloud data warehouses, and received a prestigious award.
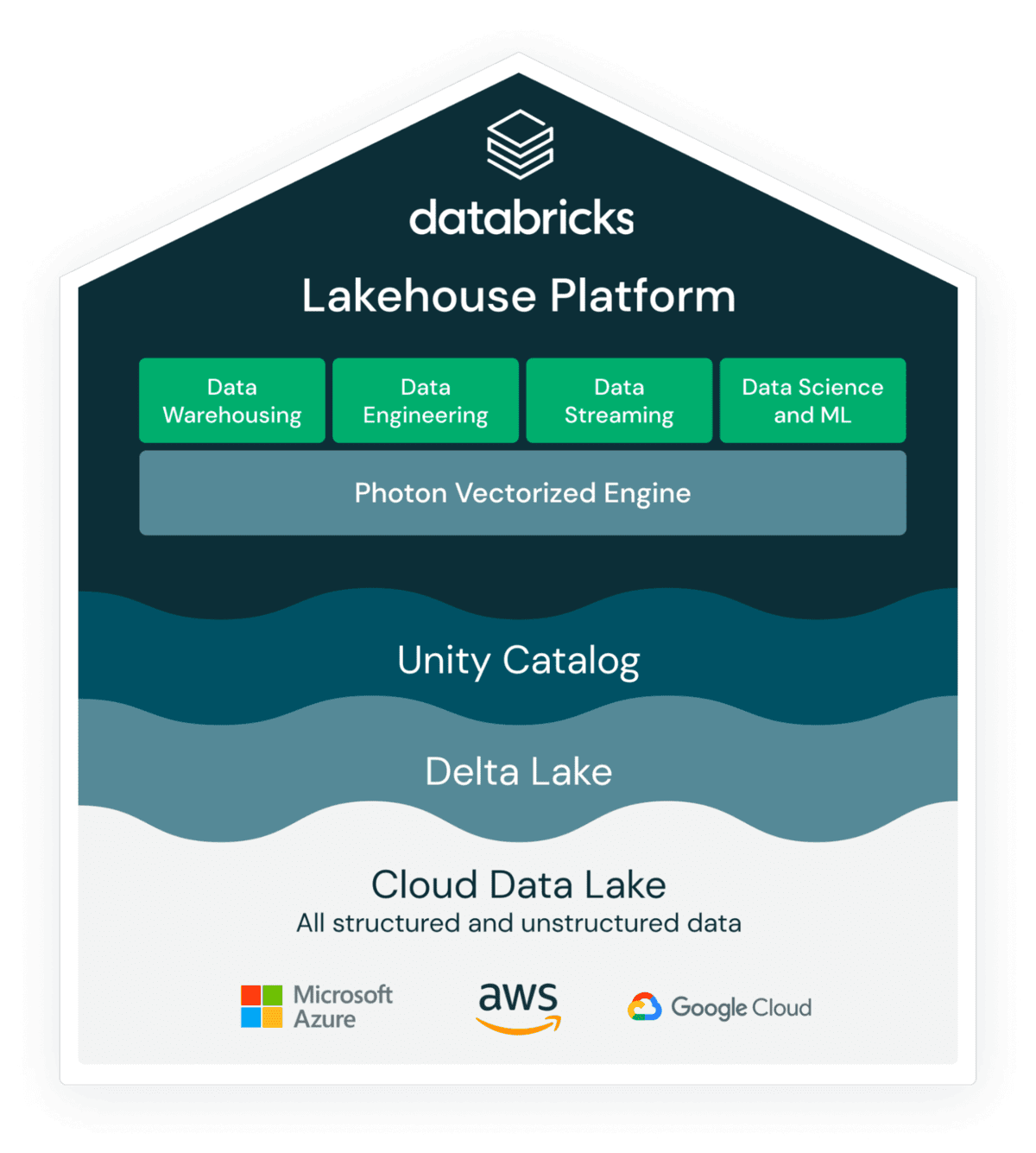
While the initial focus of Photon was on SQL to enable data warehousing workloads on your existing data lakes, we have expanded the coverage of languages (e.g. Python, Scala, Java, and R) and workloads (e.g. data engineering, analytics, and data science) to reflect modern DataFrame and SparkSQL workloads.
As a result, customers like AT&T have seen dramatic infrastructure cost savings and speed-ups on Photon not only via Databricks SQL Warehouse - but also for data ingestion, ETL, streaming, and interactive queries on the traditional Databricks Workspaces:
- Up to 80% TCO cost savings (30% on average) with Photon over traditional Databricks Runtime (Apache Spark™), and up to 85% reduction in VM compute hours (50% on average)
- Up to 5x lower latency for ⅕ of the compute using Delta Live Tables with Photon
- 3-8x faster queries on interactive SQL workloads
Furthermore, in a recent survey of 400 preview customers, 90% reported faster query execution in the workspace and 87% said they can get more work done due to faster increase in performance, so they can iterate and develop business value faster.
What's new in Photon with GA?
While Photon GA has many amazing features, we'd like to emphasize the following:
- Fast and Robust Sort: Using vectorized sort in Photon, customers have seen 3-20x performance gain during preview, which is significantly faster than in Apache Spark™.
- Accelerated Window Functions: Functions that perform calculations across a set of table rows for use cases such as aggregations, moving average, or data duplications have been reported to speed up 2-3 times during preview.
- Accelerated Structured Streaming: Photon now supports stateless Structured Streaming workloads. During the preview, customers who've had streaming jobs reported a 5x decrease in cost.
Getting Started
Follow our docs to get started with Photon, and watch our Data + AI Summit talk to dive in!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.