How to Build a Marketing Analytics Solution Using Fivetran and dbt on the Databricks Lakehouse
by Tahir Fayyaz, Bilal Aslam and Robert Saxby
Marketing teams use many different platforms to drive marketing and sales campaigns, which can generate a significant volume of valuable but disconnected data. Bringing all of this data together can help to drive a large return on investment, as shown by Publicis Groupe who were able to increase campaign revenue by as much as 50%.
The Databricks Lakehouse, which unifies data warehousing and AI use cases on a single platform, is the ideal place to build a marketing analytics solution: we maintain a single source of truth, and unlock AI/ML use cases. We also leverage two Databricks partner solutions, Fivetran and dbt, to unlock a wide range of marketing analytics use cases including churn and lifetime value analysis, customer segmentation, and ad effectiveness.
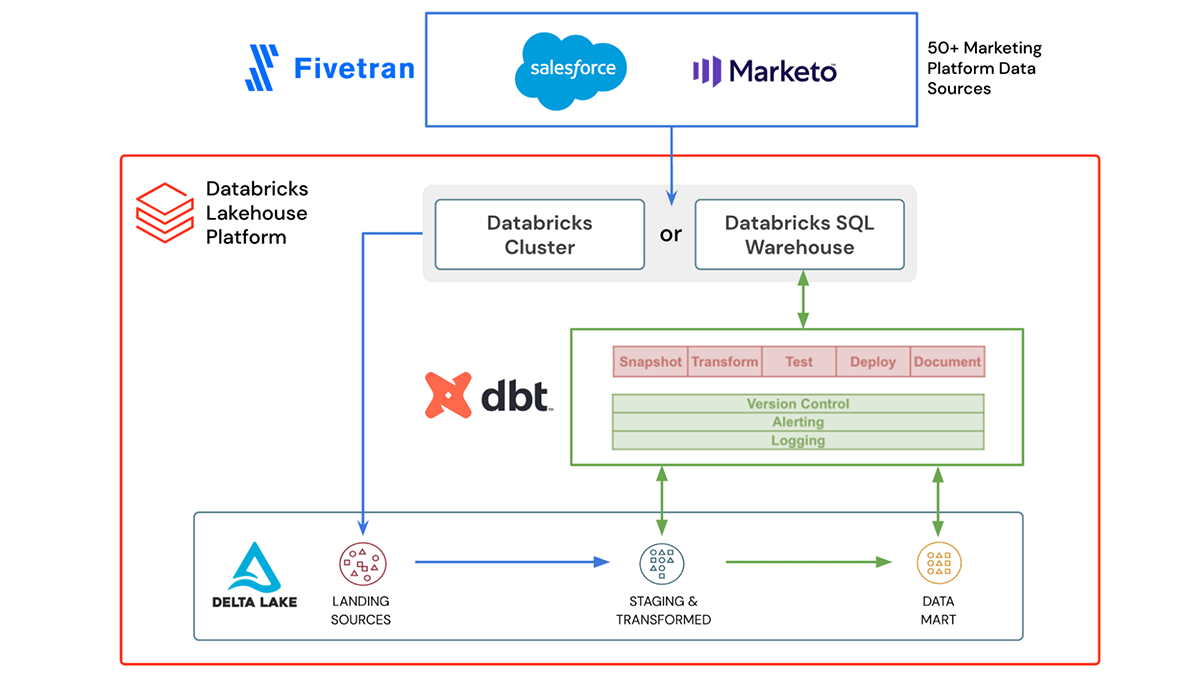
Fivetran allows you to easily ingest data from 50+ marketing platforms into Delta Lake without the need for building and maintaining complex pipelines. If any of the marketing platforms' APIs change or break, Fivetran will take care of updating and fixing the integrations so your marketing data keeps flowing in.
dbt is a popular open source framework that lets lakehouse users build data pipelines using simple SQL. Everything is organized within directories, as plain text, making version control, deployment, and testability simple. Once the data is ingested into Delta Lake, we use dbt to transform, test and document the data. The transformed marketing analytics data mart built on top of the ingested data is then ready to be used to help drive new marketing campaigns and initiatives.
Both Fivetran and dbt are a part of Databricks Partner Connect, a one-stop portal to discover and securely connect data, analytics and AI tools directly within the Databricks platform. In just a few clicks you can configure and connect these tools (and many more) directly from within your Databricks workspace.
How to build a marketing analytics solution
In this hands-on demo, we will show how to ingest Marketo and Salesforce data into Databricks using Fivetran and then use dbt to transform, test, and document your marketing analytics data model.
All the code for the demo is available on Github in the workflows-examples repository.
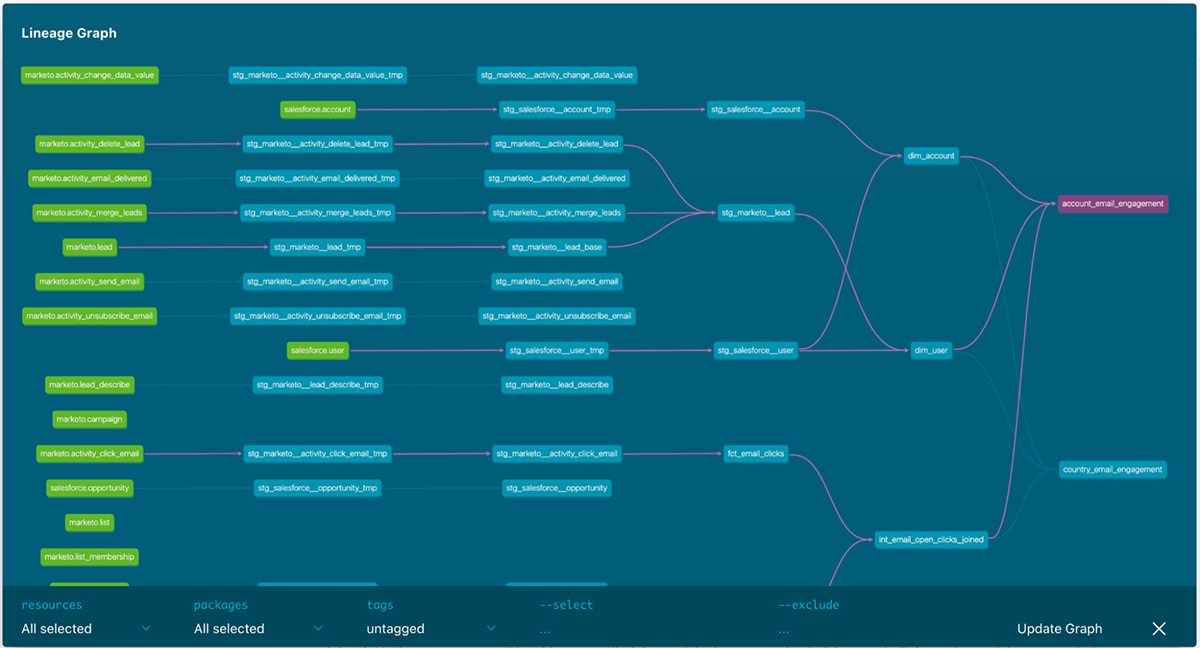
The final dbt model lineage graph will look like this. The Fivetran source tables are in green on the left and the final marketing analytics models are on the right. By selecting a model, you can see the corresponding dependencies with the different models highlighted in purple.
Data ingestion using Fivetran
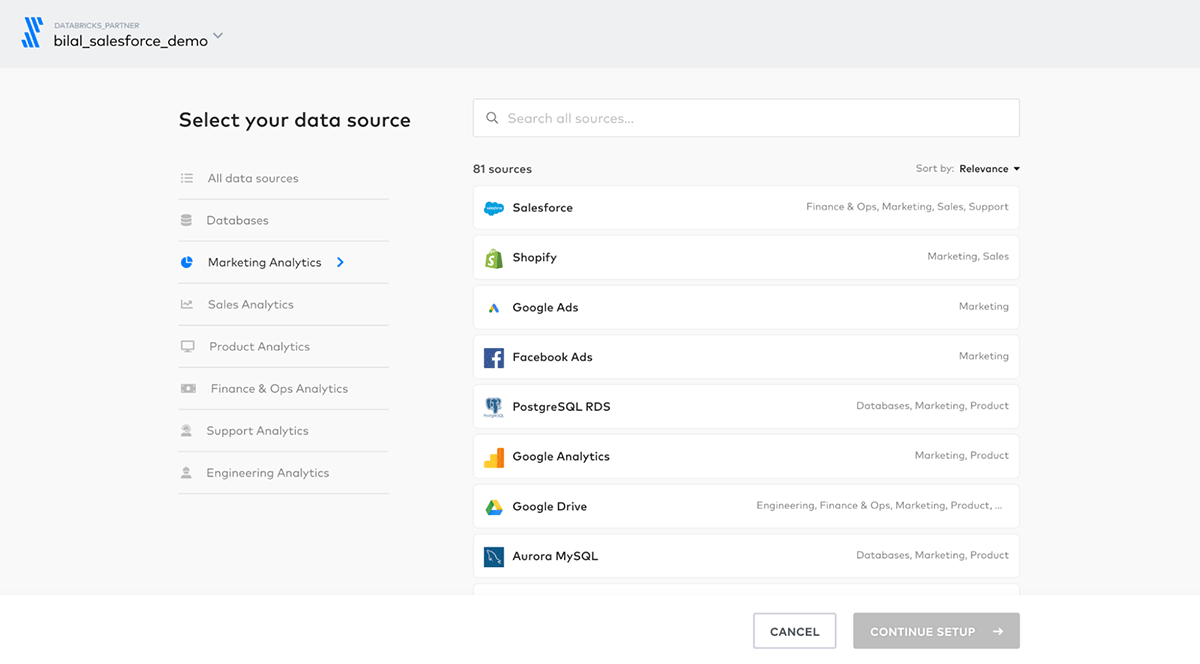
Create new Salesforce and Marketo connections in Fivetran to start ingesting the marketing data into Delta Lake. When creating the connections Fivetran will also automatically create and manage a schema for each data source in Delta Lake. We will later use dbt to transform, clean and aggregate this data.
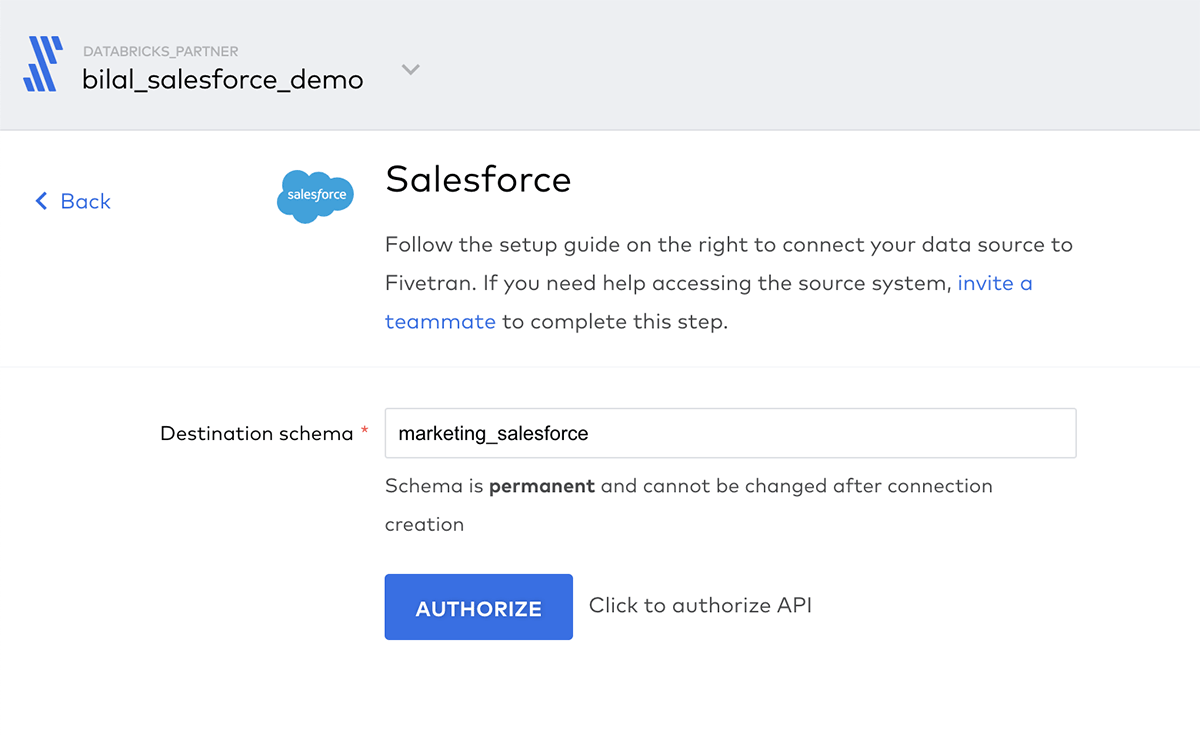
For the demo name the schemas that will be created in Delta Lake marketing_salesforce and marketing_marketo. If the schemas do not exist Fivetran will create them as part of the initial ingestion load.
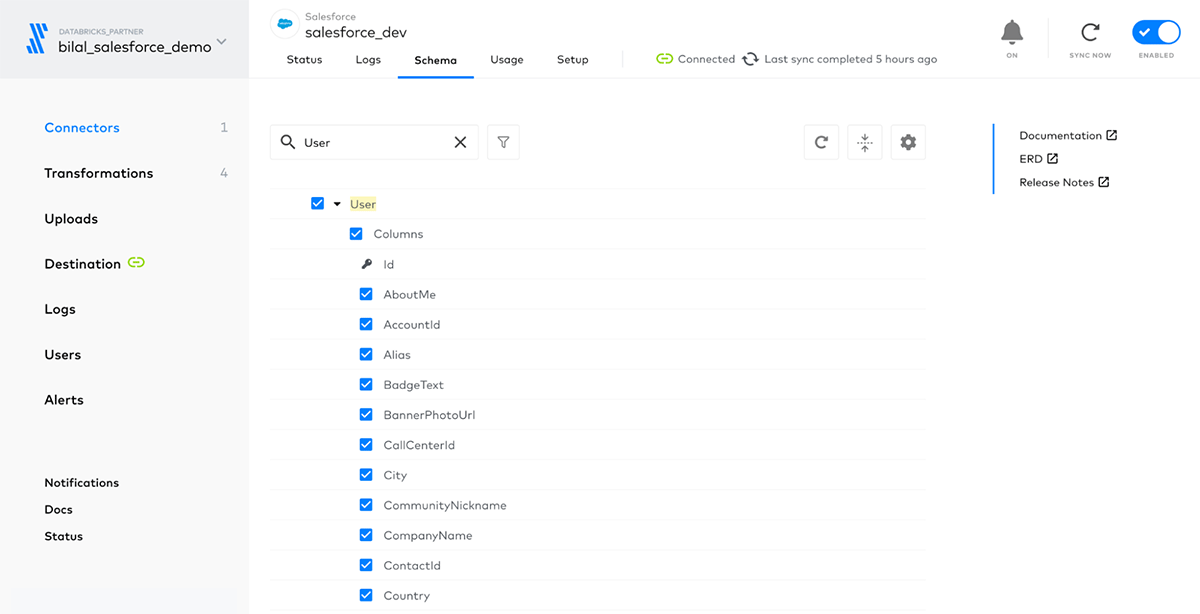
You can then choose which objects to sync to Delta Lake, where each object will be saved as individual tables. Fivetran also makes it simple to manage and view what columns are being synchronized for each table:
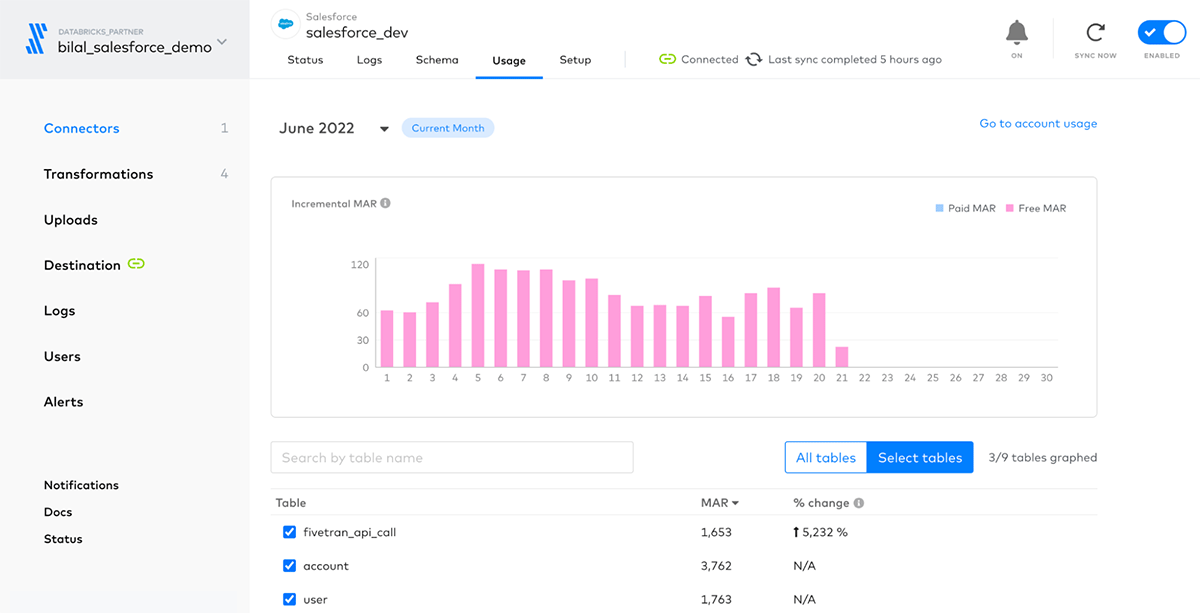
Additionally, Fivetran provides a monitoring dashboard to analyze how many monthly active rows of data are synchronized daily and monthly for each table, among other useful statistics and logs.
Data modeling using dbt
Now that all the marketing data is in Delta Lake, you can use dbt to create your data model by following these steps
Setup dbt project locally and connect to Databricks SQL
Set up your local dbt development environment in your chosen IDE by following the set-up instructions for dbt Core and dbt-databricks.
Scaffold a new dbt project and connect to a Databricks SQL Warehouse using dbt init, which will ask for following information.
Once you have configured the profile you can test the connection using:
Install Fivetran dbt model packages for staging
The first step in using the Marketo and Salesforce data is to create the tables as sources for our model. Luckily, Fivetran has made this easy to get up and running with their pre-built Fivetran dbt model packages. For this demo, let's make use of the marketo_source and salesforce_source packages.
To install the packages just add a packages.yml file to the root of your dbt project and add the marketo-source, salesforce-source and the fivetran-utils packages:
You should now see the Fivetran packages installed in the packages folder.
Update dbt_project.yml for Fivetran dbt models
There are a few configs in the dbt_project.yml file that you need to modify to make sure the Fivetran packages work correctly for Databricks.
The dbt_project.yml file can be found in the root folder of your dbt project.
spark_utils overriding dbt_utils macros
The Fivetran dbt models make use of macros in the dbt_utils package but some of these macros need to be modified to work with Databricks which is easily done using the spark_utils package.
It works by providing shims for certain dbt_utils macros which you can set using the dispatch config in the dbt_project.yml file and with this dbt will first search for macros in the spark_utils package when resolving macros from the dbt_utils namespace.
Variables for the marketo_source and salesforce_source schemas
The Fivetran packages require you to define the catalog (referred to as database in dbt) and schema of where the data lands when being ingested by Fivetran.
Add these variables to the dbt_project.yml file with the correct catalog and schema names. The default catalog is hive_metastore which will be used if _database is left blank. The schema names will be what you defined when creating the connections in Fivetran.
Target schema for Fivetran staging models
To avoid all the staging tables that are created by the Fivetran source models being created in the default target schema it can be useful to define a separate staging schema.
In the dbt_project.yml file add the staging schema name and this will then be suffixed to the default schema name.
Based on the above, if your target schema defined in profiles.yml is mkt_analytics, the schema used for marketo_source and salesforce_source tables will be mkt_analytics_your_staging_name.
Disable missing tables
At this stage you can run the Fivetran model packages to test that they work correctly.
If any of the models fail due to missing tables, because you chose not to sync those tables in Fivetran, then in your source schema you can disable those models by updating the dbt_project.yml file.
For example if the email bounced and email template tables are missing from the Marketo source schema you can disable the models for those tables by adding the following under the models config:
Developing the marketing analytics models
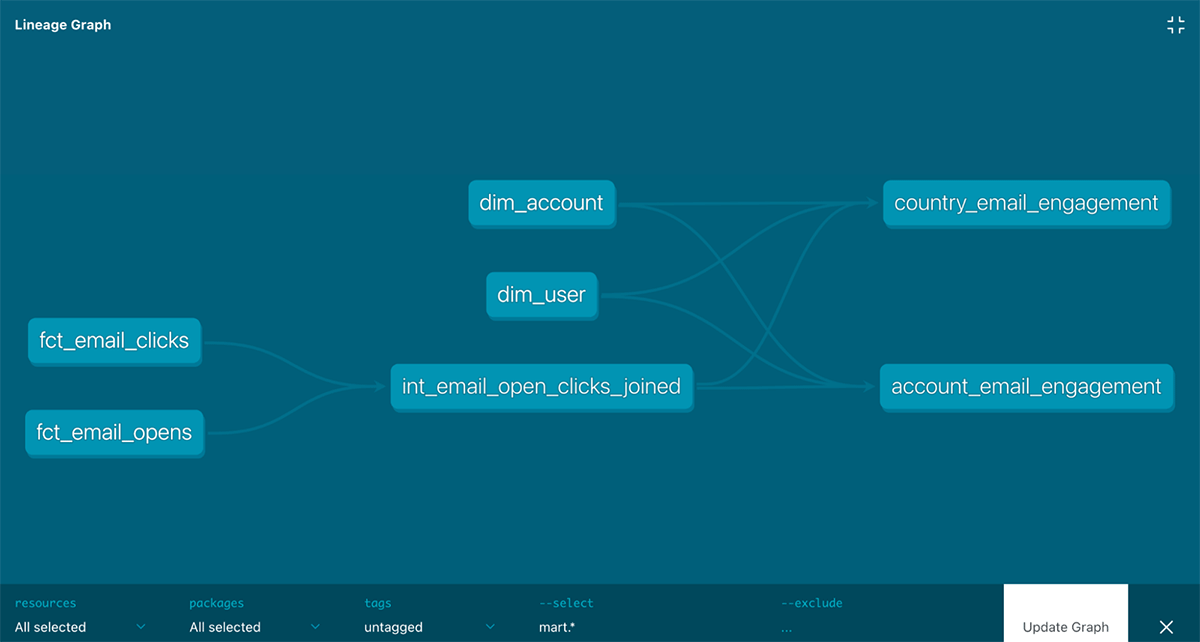
Now that the Fivetran packages have taken care of creating and testing the staging models you can begin to develop the data models for your marketing analytics use cases which will be a star schema data model along with materialized aggregate tables.
For example, for the first marketing analytics dashboard, you may want to see how engaged certain companies and sales regions are by the number of email campaigns they have opened and clicked.
To do so, you can join Salesforce and Marketo tables using the Salesforce user email, Salesforce account_id and Marketo lead_id.
The models will be structured under the mart folder in the following way.
You can view the code for all the models on Github in the /models/mart directory and below describes what is in each folder along with an example.
Core models
The core models are the facts and dimensions tables that will be used by all downstream models to build upon.
The dbt SQL code for the dim_user model
You can also add documentation and tests for the models using a yaml file in the folder.
There are 2 simple tests in the core.yml file that have been added
Intermediate models
Some of the final downstream models may rely on the same calculated metrics and so to avoid repeating SQL you can create intermediate models that can be reused.
The dbt SQL code for int_email_open_clicks_joined model:
Marketing Analytics models
These are the final marketing analytics models that will be used to power the dashboards and reports used by marketing and sales teams.
The dbt SQL code for country_email_engagement model:
Run and test dbt models
Now that your model is ready you can run all the models using
And then run the tests using
View the dbt docs and lineage graph
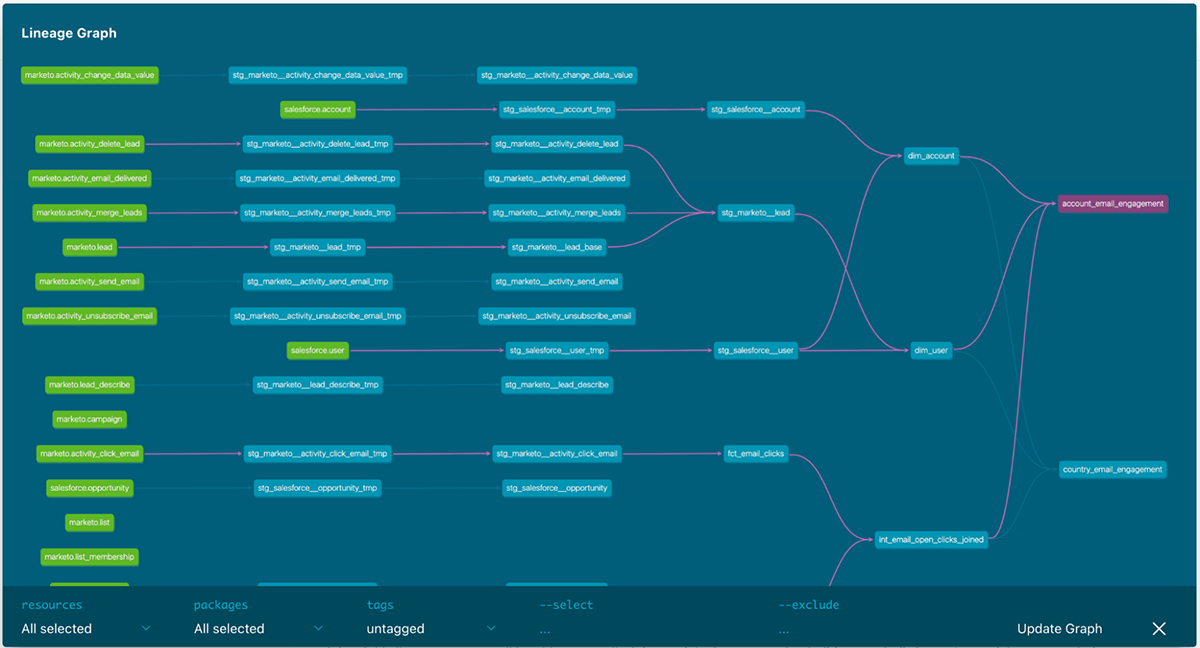
Once your models have run successfully you can generate the docs and lineage graph using
To then view them locally run
Deploying dbt models to production
Once you have developed and tested your dbt model locally you have multiple options for deploying into production one of which is the new dbt task type in Databricks Workflows (private preview).
Your dbt project should be managed and version controlled in a Git repository. You can create a dbt task in your Databricks Workflows job pointing to the Git repository.
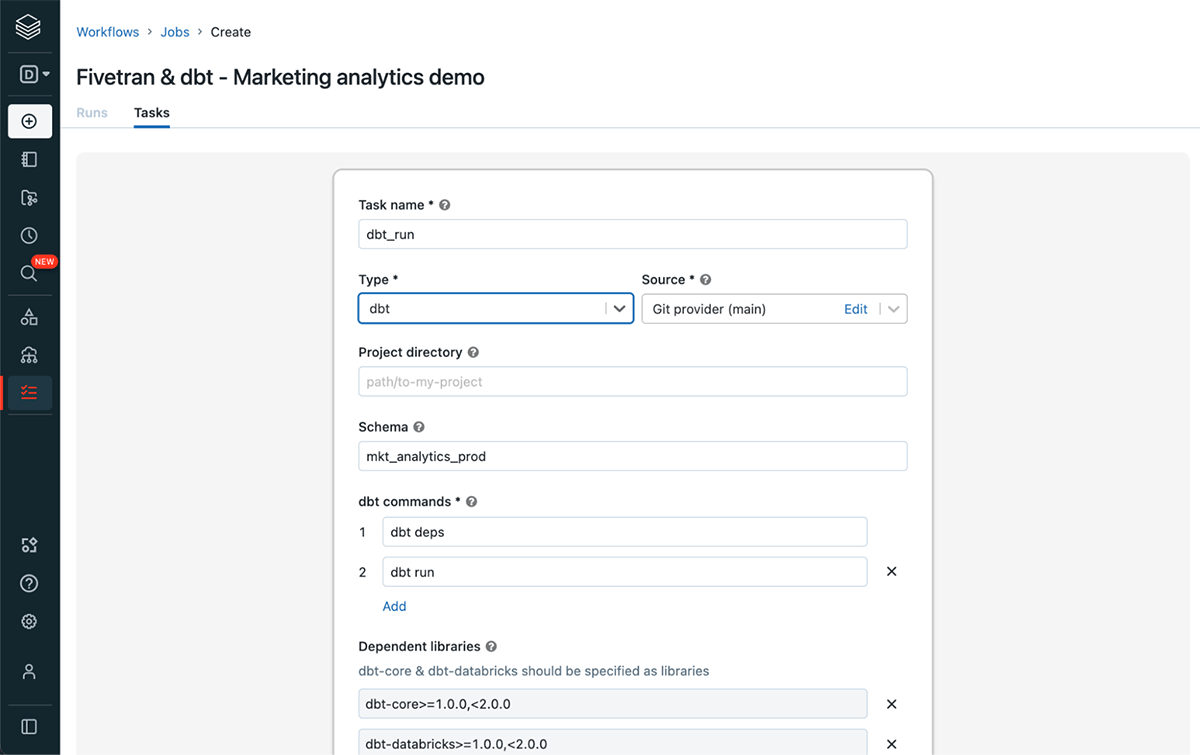
As you are using packages in your dbt project the first command should be dbt deps followed by dbt run for the first task and then dbt test for the next task.
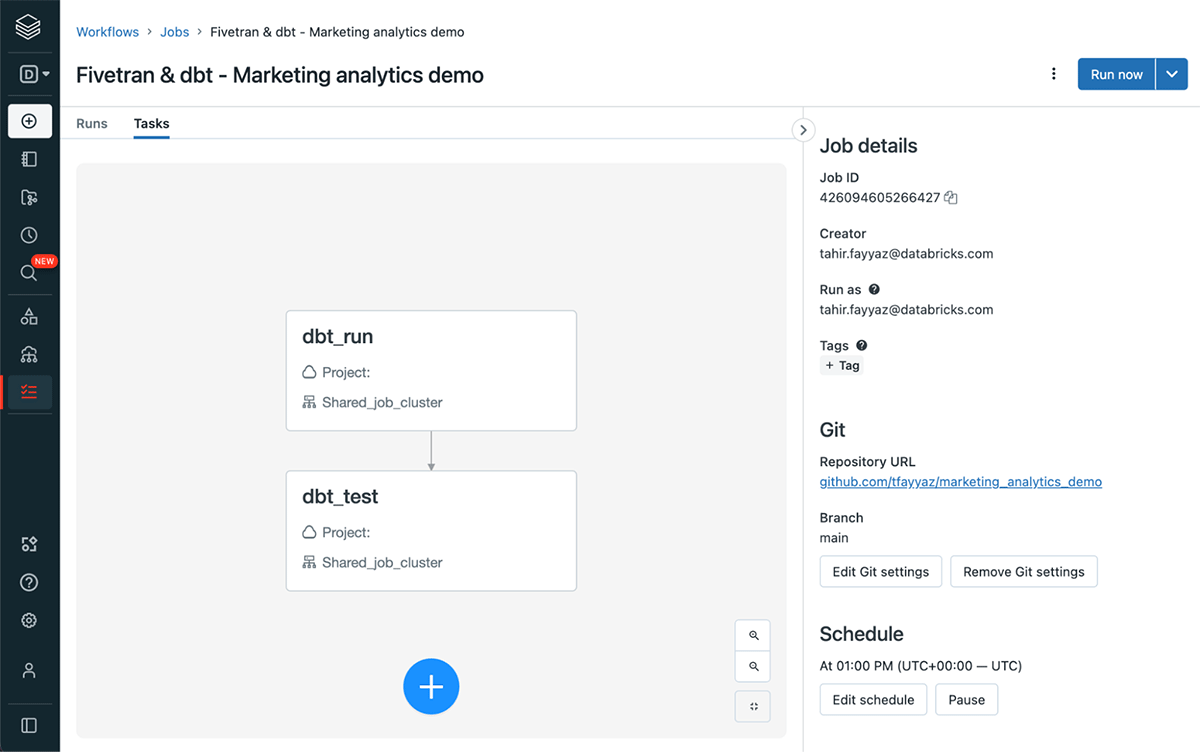
You can then run the workflow immediately using run now and also set up a schedule for the dbt project to run on a specified schedule.
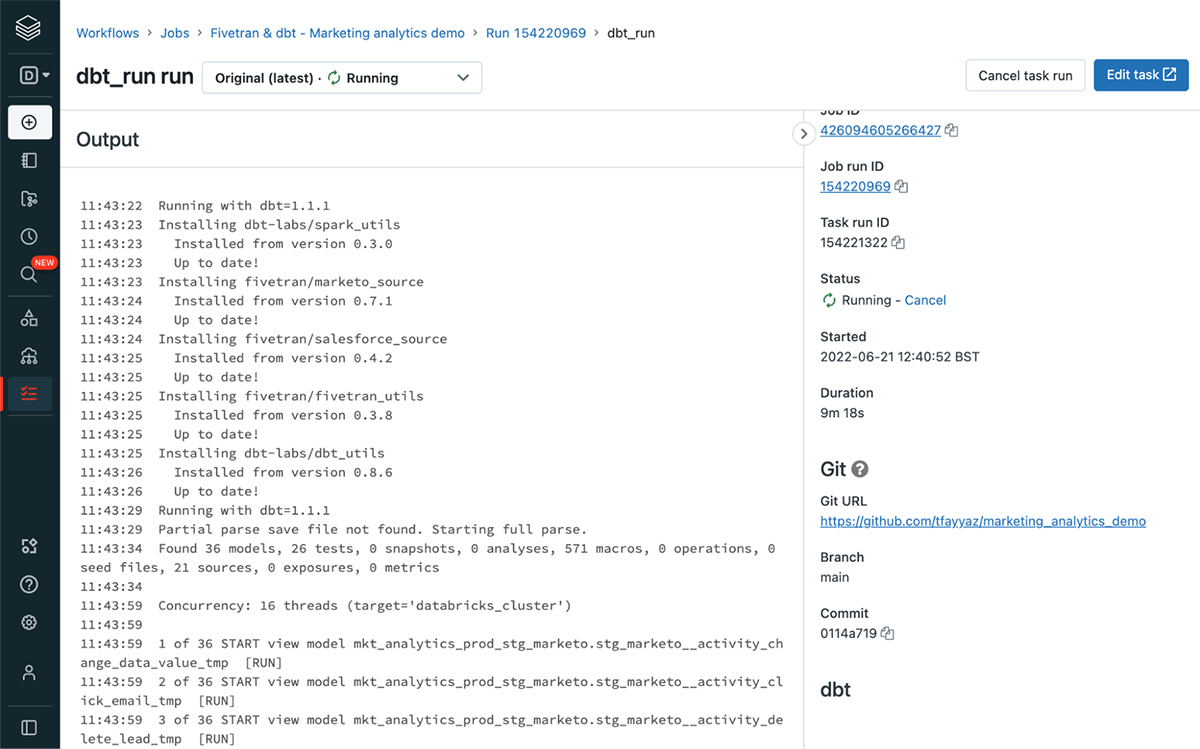
For each run you can see the logs for each dbt command helping you debug and fix any issues.
Powering your marketing analytics with Fivetran and dbt
As shown here using Fivetran and dbt alongside the Databricks Lakehouse Platform allows you to easily build a powerful marketing analytics solution that is easy to set-up, manage and flexible enough to suit any of your data modeling requirements.
To get started with building your own solution visit the documentation for integrating Fivetran and dbt with Databricks and re-use the marketing_analytics_demo project example to quickly get started.
The dbt task type in Databricks Workflows is in private preview. To try the dbt task type, please reach out to your Databricks account executive.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.