Monte Carlo and Databricks Partner to Help Companies Build More Reliable Data Lakehouses
by Ariel Amster and Matt Sulkis
This is a collaborative post between Monte Carlo and Databricks. We thank Matt Sulkis, Head of Partnerships, Monte Carlo, for his contributions.
As companies increasingly leverage data-driven insights to innovate and maintain their competitive edge, it's essential that this data is accurate and reliable. With Monte Carlo and Databricks' partnership, teams can trust their data through end-to-end data observability across their lakehouse environments.
Has your CTO ever told you that the numbers in a report you showed her looked way off?
Has a data scientist ever pinged you when a critical Spark job failed to run?
What about a rise in a field's null rate that went unnoticed for days or weeks until it caused a significant error in an ML model downstream?
You're not alone if you answered yes to any of these questions. Data downtime, in other words, periods of time when data is missing, inaccurate, or otherwise erroneous, is an all-too-familiar reality for even the best data teams. It costs millions of dollars in wasted revenue and up to 50 percent of a data engineering team's time that could be spent building data products and ML models that move the needle for the business.
To help companies accelerate the adoption of more reliable data products, Monte Carlo and Databricks are excited to announce our partnership, bringing end-to-end data observability and data quality automation tools to the data lakehouse. Data engineering and analytics teams that depend on Databricks to derive critical insights about their business and build ML models that can now leverage the power of automated data observability and monitoring to prevent bad data from affecting downstream consumers.
Achieving reliable Databricks pipelines with data observability
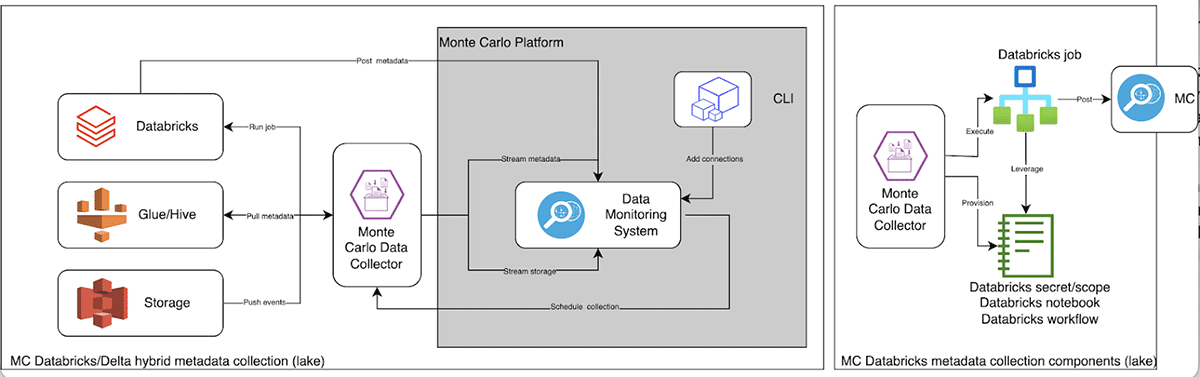
Over the past few years Databricks has established the lakehouse category, revolutionizing how organizations store and process their data at an unprecedented scale across nearly infinite use cases. Cloud data lakes like Delta Lake have gotten so powerful (and popular) that according to Mordor Intelligence, the data lake market is expected to grow from $3.74 billion in 2020 to $17.60 billion by 2026, a compound annual growth rate of nearly 30%.
Monte Carlo itself is built on the Databricks Lakehouse Platform, enabling our data and engineering teams to build and train our anomaly detection models at unprecedented speed and scale. Building on top of Databricks has allowed us to focus on our core value of improving observability and quality of data for our customers while leveraging the automation, infrastructure management, and analytics scaling tools of the lakehouse. This makes our resources more efficient and better able to serve our customers' data quality needs. As our business grows, we are confident it will scale with Databricks and enhance the value of our core offering.
Now, with Monte Carlo and Databricks' partnership, data teams can ensure that these investments are leveraging reliable, accurate data at each stage of the pipeline.
"As data pipelines become increasingly complex and companies ingest more and more data, often from third-party sources, it's paramount that this data is reliable," said Barr Moses, co-founder and CEO of Monte Carlo. "Monte Carlo is excited to partner with Databricks to help companies trust their data through end-to-end data observability across their lakehouse."
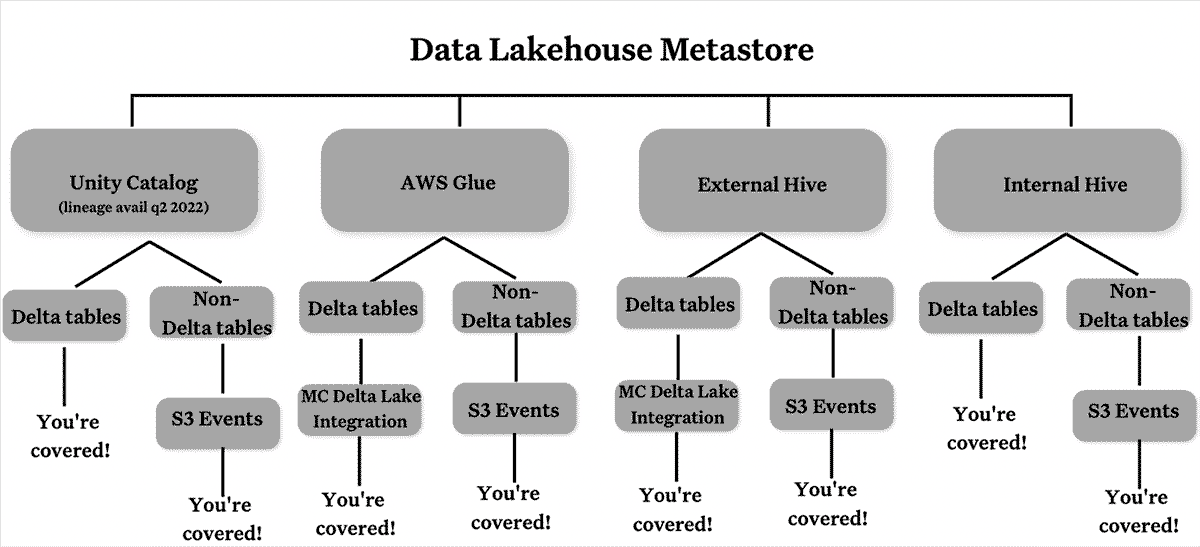
Coupled with our new Databricks Unity Catalog and Delta Lake integrations, this partnership will make it easier for organizations to take full advantage of Monte Carlo's data quality monitoring, alerting, and root cause analysis functionalities. Simultaneously, Monte Carlo customers will benefit from Databricks' speed, scale, and flexibility. With Databricks, analytics or machine learning tasks that previously took hours or even days to complete can now be delivered in minutes, making it faster and more scalable to build impactful data products for the business.
Here's how teams on Databricks and Monte Carlo can benefit from our strategic partnership:
- Achieve end-to-end data observability across your Databricks Lakehouse Platform without writing code. Get full, automated coverage across your data pipelines with a low-code implementation process. Access out-of-the-box visibility into data Freshness, Volume, Distribution, Schema, and Lineage by plugging Monte Carlo into your lakehouse.
- Know when data breaks, as soon as it happens. Monte Carlo continuously monitors your Databricks assets and proactively alerts stakeholders to data issues. Monte Carlo's machine learning-first approach gives data teams complete coverage for freshness, volume and schema changes, and opt-in distribution monitors and business-context-specific checks layered on top ensure you're covered at each stage of your data pipeline.
- Find the root cause of data quality issues fast. Pre-built machine learning-based monitoring and anomaly detection save time and resources, giving teams a single pane of glass to investigate and resolve data issues. By bringing all information and context for your pipelines into one place, teams spend less time firefighting data issues and more time innovating for the business.
- Immediately understand the business impact of bad data. End-to-end Spark lineage on top of Unity Catalog for your pipelines from the point it enters Databricks (or further upstream!) down to the business intelligence layer, data teams can triage and assess the business impact of their data issues, reducing risk and improving productivity throughout the organization.
- Prevent data downtime. Give your teams complete visibility into your Databricks pipelines and how they impact downstream reports and dashboards to make more informed development decisions. With Monte Carlo, teams can better manage breaking changes to ELTs, Spark models, and BI assets by knowing what is impacted and who to notify.
In addition to supporting existing mutual customers, Monte Carlo provides end-to-end, automated coverage for teams migrating from their legacy stacks to Databricks Lakehouse Platform. Moreover, Monte Carlo's security-first approach to data observability ensures that data never leaves your Databricks Lakehouse Platform.
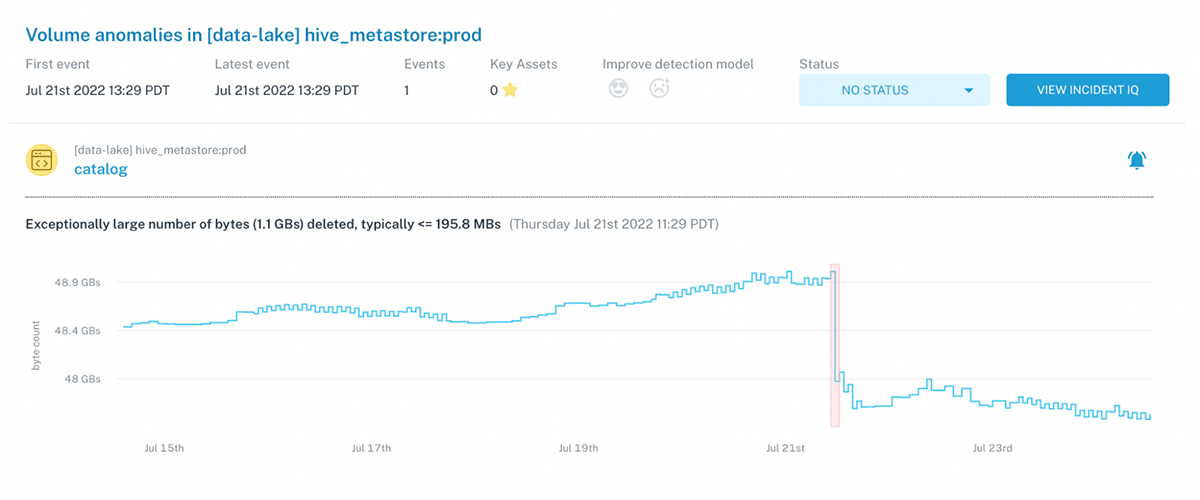
What our mutual customers have to say
Monte Carlo and Databricks customers like ThredUp, a leading online consignment marketplace, and Ibotta, a global cashback and rewards app, are excited to leverage the new Delta Lake and Unity Catalog integrations to improve data reliability at scale across their lakehouse environments.

ThredUp's data engineering teams leverage Monte Carlo's capabilities to know where and how their data breaks in real-time. The solution has enabled ThredUp to immediately identify bad data before it affects the business, saving them time and resources on manually firefighting data downtime.
"With Monte Carlo, my team is better positioned to understand the impact of a detected data issue and decide on the next steps like stakeholder communication and resource prioritization. Monte Carlo's end-to-end lineage helps the team draw these connections between critical data tables and the Looker reports, dashboards, and KPIs the company relies on to make business decisions," said Satish Rane, Head of Data Engineering, ThredUp. "I'm excited to leverage Monte Carlo's data observability for our Databricks environment."

At Ibotta, Head of Data, Jeff Hepburn and his team rely on Monte Carlo to deliver end-to-end visibility into the health of their data pipelines, starting with ingestion in Databricks down to the business intelligence layer.
"Data-driven decision making is a huge priority for Ibotta, but our analytics are only as reliable as the data that informs them. With Monte Carlo, my team has the tools to detect and resolve data incidents before they affect downstream stakeholders, and their end-to-end lineage helps us understand the inner workings of our data ecosystem so that if issues arise, we know where and how to fix them," said Jeff Hepburn, Head of Data, Ibotta. "I'm excited to leverage Monte Carlo's data observability with Databricks."
Pioneering the future of data observability for data lakes
These updates enable teams to leverage Databricks for data engineering, data science, and machine learning use cases to prevent data downtime at scale.
When it comes to ensuring data reliability on the lakehouse, Monte Carlo and Databricks are better together. For more details on how to execute these integrations, see our documentation.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.