MLOps on Databricks with Vertex AI on Google Cloud

Since the launch of Databricks on Google Cloud in early 2021, Databricks and Google Cloud have been partnering together to further integrate the Databricks platform into the cloud ecosystem and its native services. Databricks is built on or tightly integrated with many Google Cloud native services today, including Cloud Storage, Google Kubernetes Engine, and BigQuery. Databricks and Google Cloud are excited to announce an MLflow and Vertex AI deployment plugin to accelerate the model development lifecycle.
Why is MLOps difficult today?
The standard DevOps practices adopted by software companies that allow for rapid iteration and experimentation often do not translate well to data scientists. Those practices include both human and technological concepts such as workflow management, source control, artifact management, and CICD. Given the added complexity of the nature of machine learning (model tracking and model drift), MLOps is difficult to put into practice today, and a good MLOps process needs the right tooling.
Today's machine learning (ML) ecosystem includes a diverse set of tools that might specialize and serve a portion of the ML lifecycle, but not many provide a full end to end solution – this is why Databricks teamed up with Google Cloud to build a seamless integration that leverages the best of MLflow and Vertex AI to allow Data Scientists to safely train their models, Machine Learning Engineers to productionalize and serve that model, and Model Consumers to get their predictions for business needs.
MLflow is an open source library developed by Databricks to manage the full ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. Vertex AI is Google Cloud’s unified artificial intelligence platform that offers an end-to-end ML solution, from model training to model deployment. Data scientists and machine learning engineers will be able to deploy their models into production on Vertex AI for real-time model serving using pre-built Prediction images and ensuring model quality and freshness using model monitoring tools thanks to this new plugin, which allows them to train their models on Databricks' Managed MLflow while utilizing the power of Apache Spark™ and open source Delta Lake (as well as its packaged ML Runtime, AutoML, and Model Registry).
Note: The plugin also has been tested and works well with open source MLflow.
Technical Demo
Let's show you how to build an end-to-end MLOps solution using MLflow and Vertex AI. We will train a simple scikit-learn diabetes model with MLflow, save it into the Model Registry, and deploy it into a Vertex AI endpoint.
Before we begin, it's important to understand what goes on behind the scenes when using this integration. Looking at the reference architecture below, you can see the Databricks components and Google Cloud services used for this integration:
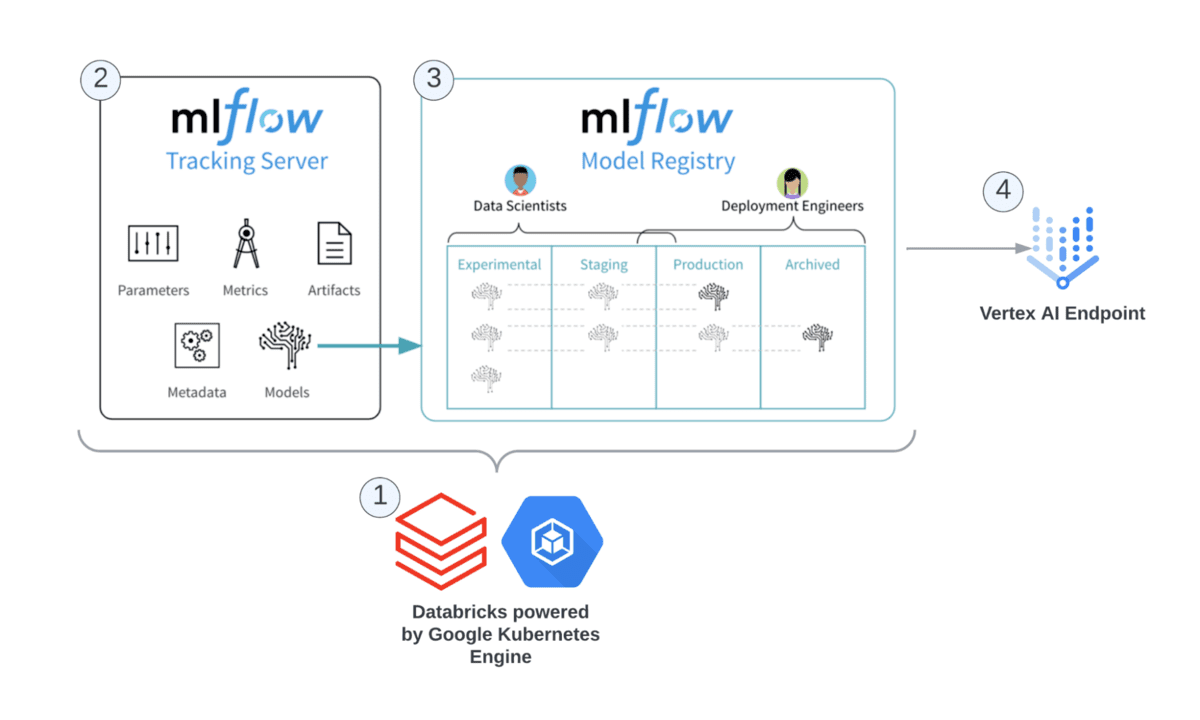
Note: The following steps will assume that you have a Databricks Google Cloud workspace deployed with the right permissions to Vertex AI and Cloud Build set up on Google Cloud.
Step 1: Create a Service Account with the right permissions to access Vertex AI resources and attach it to your cluster with MLR 10.x.
Step 2: Download the google-cloud-mlflow plugin from PyPi onto your cluster. You can do this by downloading directly onto your cluster as a library or run the following pip command in a notebook attached to your cluster:
Step 3: In your notebook, import the following packages:
Step 3: Train, test, and autolog a scikit-learn experiment, including the hyperparameters used and test results with MLflow.
Step 4: Log the model into the MLflow Registry, which saves model artifacts into Google Cloud Storage.
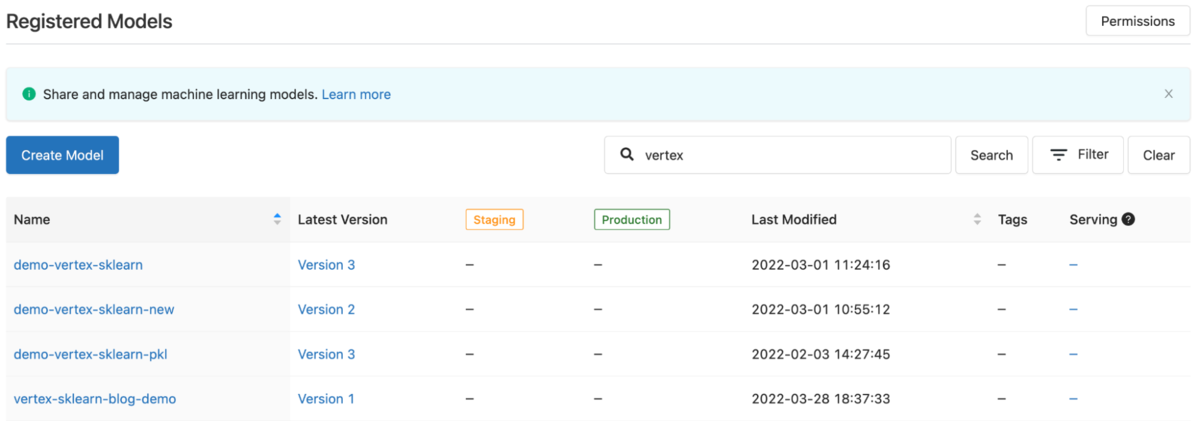
Step 5: Programmatically get the latest version of the model using the MLflow Tracking Client. In a real case scenario you will likely transition the model from stage to production in your CICD process once the model has met production standards.
Step 6: Instantiate the Vertex AI client and deploy to an endpoint using just three lines of code.
Step 7: Check the UI in Vertex AI and see the published model.
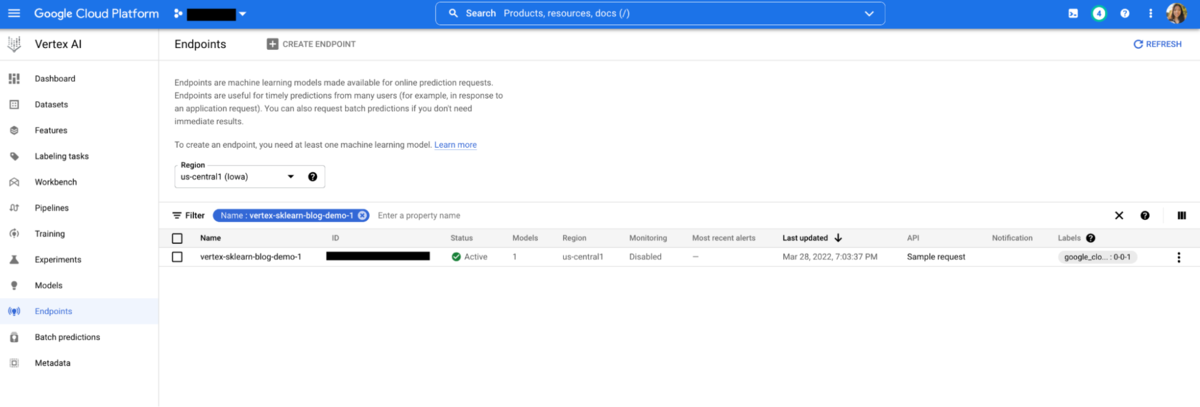
Step 8: Invoke the endpoint using the plugin within the notebook for batch inference. In a real-case production scenario, you will likely invoke the endpoint from a web service or application for real time inference.
Your predictions should return the following Prediction class, which you can proceed to parse into a pandas dataframe and use for your business needs:
Conclusion
As you can see, MLOps doesn't have to be difficult. Using the end to end MLflow to Vertex AI solution, data teams can go from development to production in matters of days vs. weeks, months, or sometimes never! For a live demo of the end to end workflow, check out the on-demand session "Accelerating MLOps Using Databricks and Vertex AI on Google Cloud" during DAIS 2022.
To start your ML journey today, import the demo notebook into your workspace today. First-time customers can take advantage of partnership credits and start a free Databricks on Google Cloud trial. For any questions, please reach out to us using this contact form.
Never miss a Databricks post
What's next?


Product
November 21, 2024/3 min read