Loading a Data Warehouse Data Model in Real Time with the Databricks Lakehouse
Dimensional modeling implementation on the modern lakehouse using Delta Live Tables

Dimensional modeling is one of the most popular data modeling techniques for building a modern data warehouse. It allows customers to quickly develop facts and dimensions based on business needs for an enterprise. When helping customers in the field, we found many are looking for best practices and implementation reference architecture from Databricks.
In this article, we aim to dive deeper into the best practice of dimensional modeling on Databricks' Lakehouse Platform and provide a live example to load an EDW dimensional model in real-time using Delta Live Tables.
Here are the high-level steps we will cover in this blog:
- Define a business problem
- Design a dimensional model
- Best practices and recommendations for dimensional modeling
- Implementing a dimensional model in a Databricks Lakehouse
- Conclusion
1. Define a business problem
Dimensional modeling is business-oriented; it always starts with a business problem. Before building a dimensional model, we need to understand the business problem to solve, as it indicates how the data asset will be presented and consumed by end users. We need to design the data model to support more accessible and faster queries.
The Business Matrix is a fundamental concept in Dimensional Modeling, below is an example of the business matrix, where the columns are shared dimensions and rows represent business processes. The defined business problem determines the grain of the fact data and required dimensions. The key idea here is that we could incrementally build additional data assets with ease based on the Business Matrix and its shared or conformed dimensions.
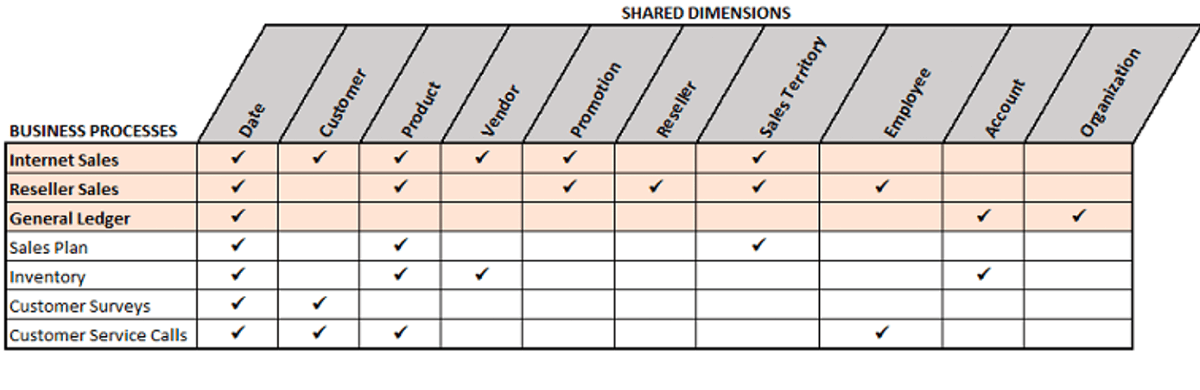
Here we assume that the business sponsor would like to team to build a report to give insights on:
- What are the top selling products so they can understand product popularity
- What are the best performing stores to learn good store practices
2. Design a dimensional model
Based on the defined business problem, the data model design aims to represent the data efficiently for reusability, flexibility and scalability. Here is the high-level data model that could solve the business questions above.
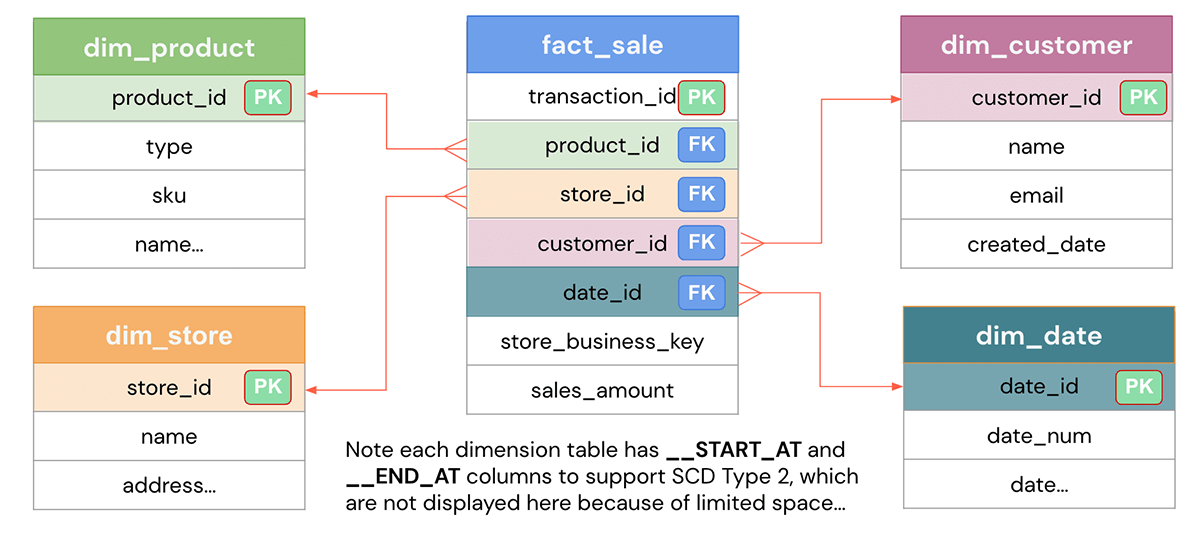
The design should be easy to understand and efficient with different query patterns on the data. From the model, we designed the sales fact table to answer our business questions; as you can see, other than the foreign keys (FKs) to the dimensions, it only contains the numeric metrics used to measure the business, e.g. sales_amount.
We also designed dimension tables such as Product, Store, Customer, Date that provide contextual information on the fact data. Dimension tables are typically joined with fact tables to answer specific business questions, such as the most popular products for a given month, which stores are the best-performing ones for the quarter, etc.
3. Best practices and recommendations for dimensional modeling
With the Databricks Lakehouse Platform, one can easily design & implement dimensional models, and simply build the facts and dimensions for the given subject area.
Below are some of the best practices recommended while implementing a dimensional model:
- One should denormalize the dimension tables. Instead of the third normal form or snowflake type of model, dimension tables typically are highly denormalized with flattened many-to-one relationships within a single dimension table.
- Use conformed dimension tables when attributes in different dimension tables have the same column names and domain contents. This advantage is that data from different fact tables can be combined in a single report using conformed dimension attributes associated with each fact table.
- A usual trend in dimension tables is around tracking changes to dimensions over time to support as-is or as-was reporting. You can easily apply the following basic techniques for handling dimensions based on different requirements.
- The type 1 technique overwrites the dimension attribute's initial value.
- With the type 2 technique, the most common SCD technique, you use it for accurate change tracking over time.
- One can easily perform SCD type 1 or SCD type 2 using Delta Live Tables using APPLY CHANGES INTO
- Primary + Foreign Key Constraints allow end users like yourselves to understand relationships between tables.
- Usage of IDENTITY Columns automatically generates unique integer values when new rows are added. Identity columns are a form of surrogate keys. Refer to the blog link for more details.
- Enforced CHECK Constraints to never worry about data quality or data correctness issues sneaking up on you.
Your compact guide to modern analytics

4. Implementing a dimensional model in a Databricks Lakehouse
Now, let us look at an example of Delta Live Tables based dimensional modeling implementation:
The example code below shows us how to create a dimension table (dim_store) using SCD Type 2, where change data is captured from the source system.
The example code below shows us how to create a fact table (fact_sale), with the constraint of valid_product_id we are able to ensure all fact records that are loaded have a valid product associated with it.
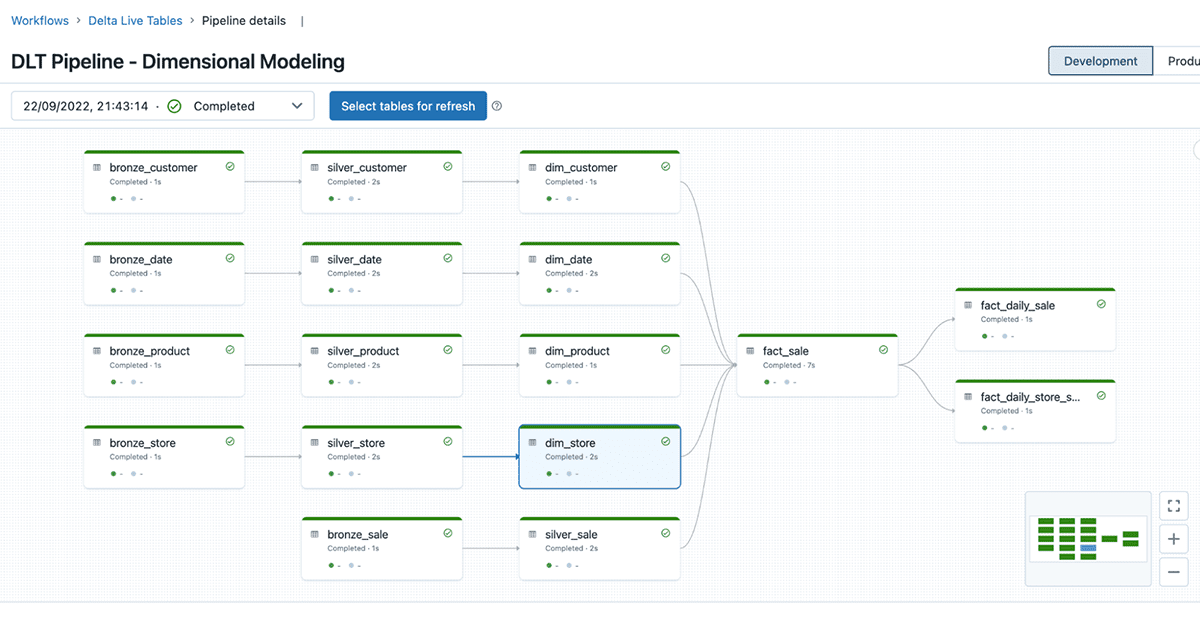
The Delta Live Table pipeline example could be found here. Please refer to Delta Live Tables quickstart on how to create a Delta Live Table pipeline. As seen below, DLT offers full visibility of the ETL pipeline and dependencies between different objects across bronze, silver, and gold layers following the lakehouse medallion architecture.
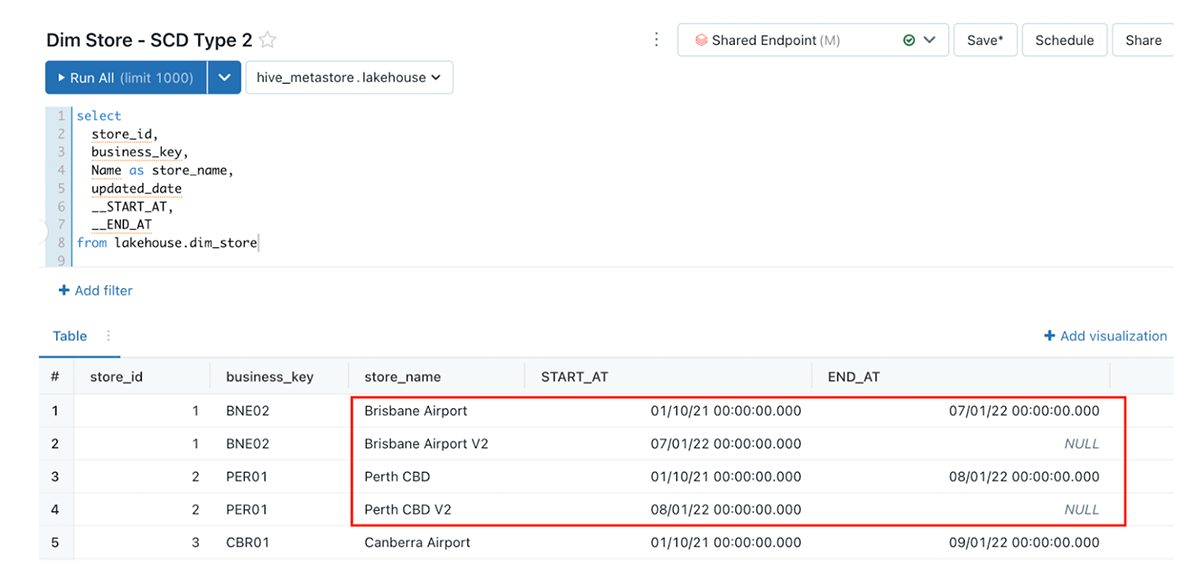
Here is an example of how the dimension table dim_store gets updated based on the incoming changes. Below, the Store Brisbane Airport was updated to Brisbane Airport V2, and with the out-of-box SCD Type 2 support, the original record ended on Jan 07 2022, and a new record was created which starts on the same day with an open end date (NULL) - which indicates the latest record for the Brisbane airport.
For more implementation details, please refer to here for the full notebook example.
5. Conclusion
In this blog, we learned about dimensional modeling concepts in detail, best practices, and how to implement them using Delta Live Tables.
Learn more about dimensional modeling at Kimball Technology.