Building a Semantic Lakehouse With AtScale and Databricks
Learn how a universal semantic Layer can democratize your Databricks Lakehouse and enable self-service BI

This is a collaborative post between AtScale and Databricks. We thank Kieran O'Driscoll, Technology Alliances Manager, AtScale, for his contributions.
Kyle Hale, Solution Architect with Databricks, coined the term "Semantic Lakehouse" in his blog a few months back. It is a nice overview of the potential to simplify the BI stack and leverage the power of the lakehouse. As AtScale and Databricks collaborate more and more on supporting our joint customers, the potential for leveraging AtScale's semantic layer platform with Databricks to rapidly create a Semantic Lakehouse has taken shape. A semantic lakehouse provides an abstraction layer on the physical tables and provides a business-friendly view of data consumption by defining and organizing the data by different subject areas, and defining the entities, attributes and joins. All of this simplifies the data consumption by business analysts and end users.
Most enterprises still struggle with data democratization
Making data available to decision-makers is a challenge that most organizations face today. The larger the organization, the more challenging it becomes to impose a single standard for consuming and preparing analytics. Over half of enterprises report using three or more BI tools, with over a third using four or more. On top of BI users, data scientists have their own range of preferences as do application developers.
These tools work in different ways and speak different query languages. Conflicting analytics outputs are almost guaranteed when multiple business units make decisions by resorting to different siloed data copies or conventional OLAP cubing solutions like Tableau Hyper Extracts, Power BI Premium Imports, or Microsoft SQL Server Analysis Services (SSAS) for Excel users.
Keeping data in different data marts and data warehouses, extracts in various databases and externally cached data in reporting tools doesn't give a single version of truth for the enterprise and increases data movement, ETL, security and complexity. It becomes a data governance nightmare and it also means that the organizations are running their businesses on potentially stale data from different data silos in the BI layers and not leveraging the full power of the Databricks Lakehouse.
The need for a universal semantic layer
The AtScale semantic layer sits between all your analytics consumption tools and your Databricks Lakehouse. By abstracting the physical form and location of data, the semantic layer makes data stored in the Delta Lake analysis ready and easily consumable by the business users' tool of choice. Consumption tools can connect to AtScale via one of the following protocols:
- For SQL, the AtScale engine appears as a Hive SQL warehouse.
- For MDX or DAX, AtScale appears as a SQL Server Analysis Services (SSAS) cube.
- For REST or Python applications, AtScale appears as a web service.
Rather than processing data locally, AtScale pushes inbound queries down to Databricks as optimized SQL. This means that users' queries run directly against Delta Lake using Databricks SQL for compute, scale, and performance.
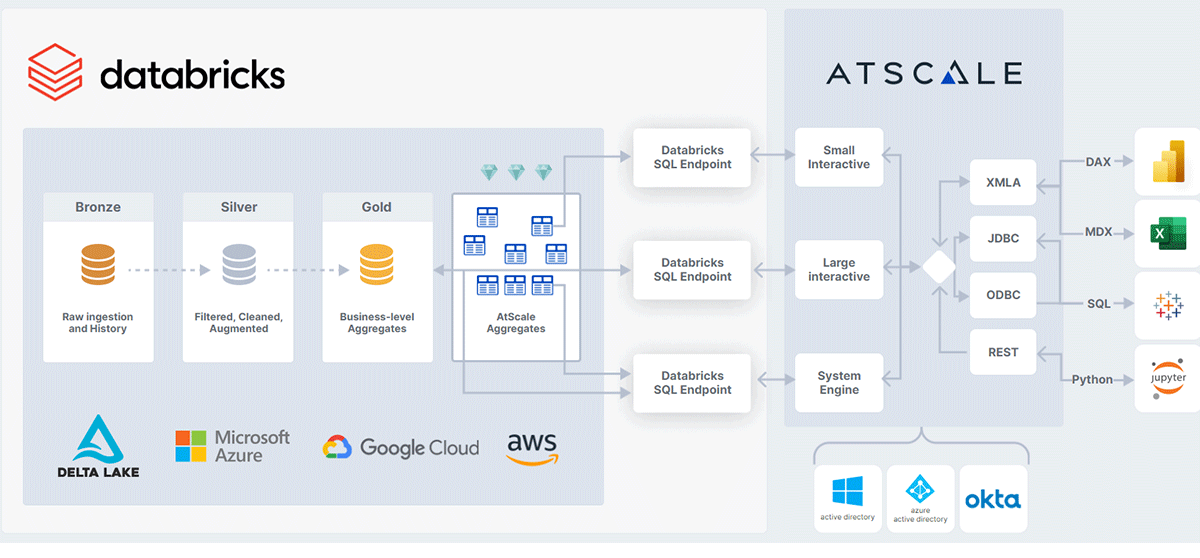
The added benefit of using a Universal Semantic Layer is that AtScale's autonomous performance optimization technology identifies user query patterns to automatically orchestrate the creation and maintenance of aggregates, just like the data engineering team would do. Now no one has to spend the development time and effort to create and maintain these aggregates, as they are auto-created and managed by Atscale for optimal performance. These aggregates are created in the Delta Lake as physical Delta Tables and can be thought of as a "Diamond Layer". These aggregates are fully managed by AtScale and improve the scale and performance of your BI Reports on the Databricks Lakehouse while radically simplifying analytics data pipelines and associated data engineering.
Creating a tool-agnostic semantic lakehouse
The vision of the Databricks Lakehouse Platform is a single unified platform to support all your data, analytics and AI workloads. Kyle's description of the "Semantic Lakehouse" is a nice model for a simplified BI stack.
AtScale extends this idea of a Semantic Lakehouse by supporting BI workloads and AI/ML use cases through our tool-agnostic Semantic Layer. The combination of AtScale and Databricks means that the semantic Lakehouse architecture is extended to any presentation layer - doesn't matter if it is Tableau, Power BI , Excel or Looker. They all can use the same semantic layer in AtScale.

With the advent of the lakehouse, organizations no longer have their BI and AI/ML teams working in isolation. AtScale's Universal Semantic Layer helps organizations get consistent access to all of their enterprise data, regardless if it's a business user in Excel or a data scientist using a Notebook, while leveraging the full power of their Databricks Lakehouse Platform.
Additional resources
Watch our panel discussion with Franco Patano, lead product specialist at Databricks for more information and to find out more about how these tools can help you to create an agile, scalable analytics platform.
If you have any questions regarding AtScale or how to modernize and migrate your legacy EDW, BI and reporting stack to Databricks and AtScale - feel free to reach out to [email protected] or contact Databricks.
Never miss a Databricks post
What's next?


Product
November 21, 2024/3 min read