Memory Profiling in PySpark

Published: November 30, 2022
by Xinrong Meng, Takuya Ueshin and Allan Folting
There are many factors in a PySpark program's performance. PySpark supports various profiling tools to expose tight loops of your program and allow you to make performance improvement decisions, see more. However, memory, as one of the key factors of a program's performance, had been missing in PySpark profiling. A PySpark program on the Spark driver can be profiled with Memory Profiler as a normal Python process, but there was not an easy way to profile memory on Spark executors.
PySpark UDFs, one of the most popular Python APIs, are executed by Python worker subprocesses spawned by Spark executors. They are powerful because they enable users to run custom code on top of the Apache Spark™ engine. However, it is difficult to optimize UDFs without understanding memory consumption. To help optimize PySpark UDFs and reduce the likelihood of out-of-memory errors, the PySpark memory profiler provides information about total memory usage. It pinpoints which lines of code in a UDF attribute to the most memory usage.
Implementing memory profiling on executors is challenging. Because executors are distributed on the cluster, result memory profiles have to be collected from each executor and aggregated properly to show the total memory usage. Meanwhile, a mapping between the memory consumption and each source code line has to be provided for debugging and pruning purposes. In Databricks Runtime 12.0, PySpark overcame all those technical difficulties, and memory profiling was enabled on executors. In this blog, we provide an overview of user-defined functions (UDFs) and demonstrate how to use the memory profiler with UDFs.
User-defined Functions(UDFs) overview
There are two main categories of UDFs supported in PySpark: Python UDFs and Pandas UDFs.
- Python UDFs are user-defined scalar functions that take/return Python objects serialized/deserialized by Pickle and operate one-row-at-a-time
- Pandas UDFs (a.k.a. Vectorized UDFs) are UDFs that take/return pandas Series or DataFrame serialized/deserialized by Apache Arrow and operate block by block. Pandas UDFs have some variations categorized by usage, with specific input and output types:
Series to Series,Series to Scalar, andIterator to Iterator.
Based on Pandas UDFs implementation, there are also Pandas Function APIs: Map (i.e., mapInPandas) and (Co)Grouped Map (i.e., applyInPandas), as well as an Arrow Function API - mapInArrow. The memory profiler applies to all UDF types mentioned above unless the function takes in/outputs an iterator.
Big Book of Data Engineering

Enable Memory Profiling
To enable memory profiling on a cluster, we should install the Memory Profiler library and set the Spark config "spark.python.profile.memory" to "true" as shown below.
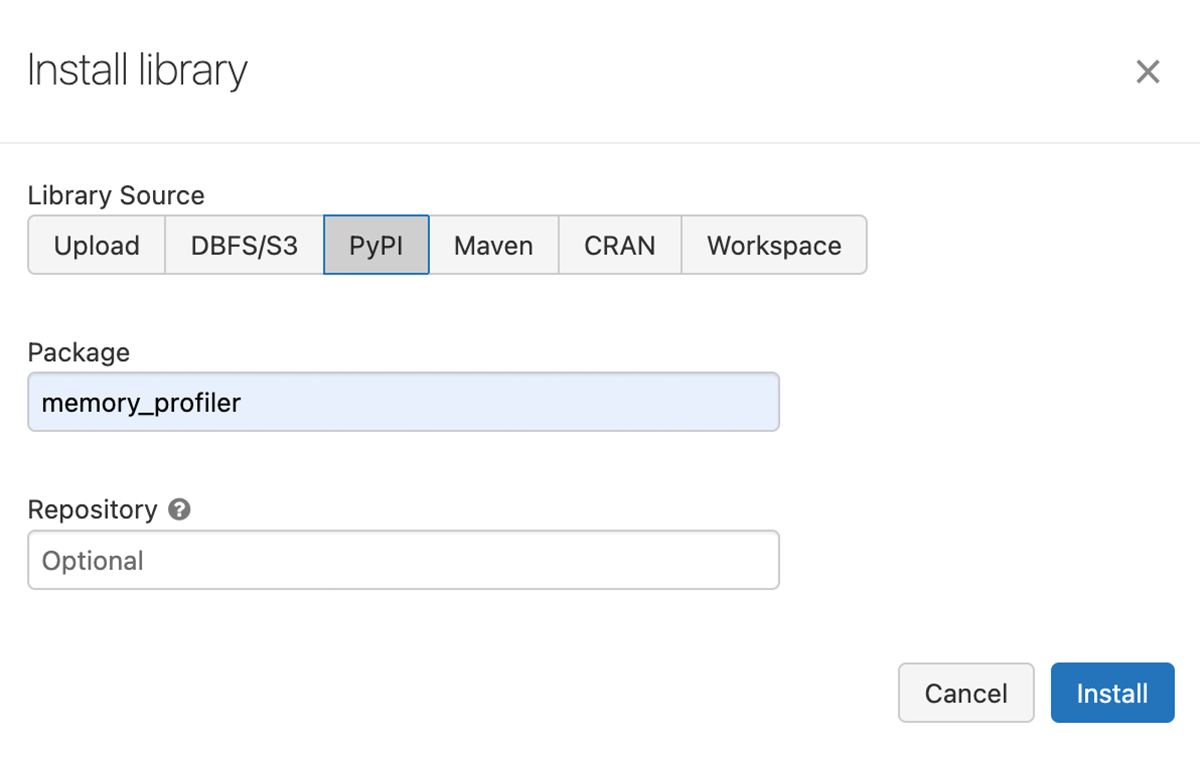
- Install the Memory Profiler library on the cluster.
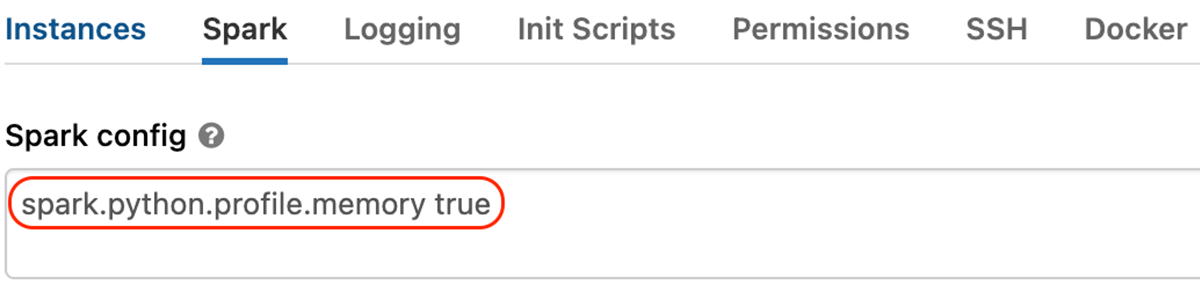
- Enable the "
spark.python.profile.memory" Spark configuration.
Then, we can profile the memory of a UDF. We will illustrate the memory profiler with GroupedData.applyInPandas.
Firstly, a PySpark DataFrame with 4,000,000 rows is generated, as shown below. Later, we will group by the id column, which results in 4 groups with 1,000,000 rows per group.
Then a function arith_op is defined and applied to sdf as shown below.
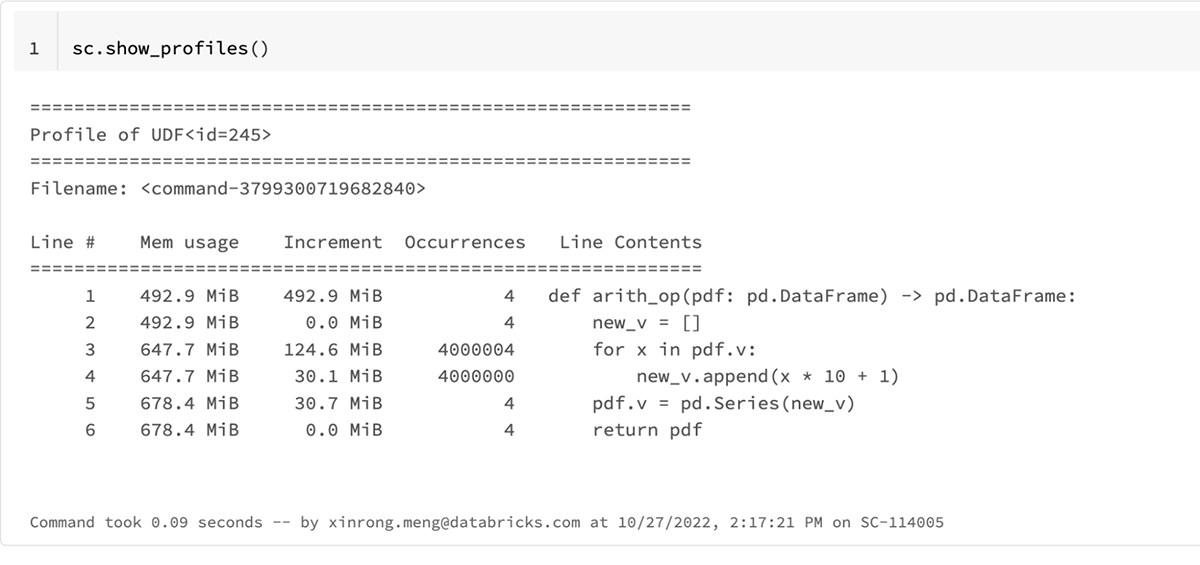
Executing the code above and running sc.show_profiles() prints the following result profile. The result profile can also be dumped to disk by sc.dump_profiles(path).
The UDF id in the above result profile, 245, matches that in the following Spark plan for res which can be shown by calling res.explain().
In the body of the result profile of sc.show_profiles(), the column heading includes
Line #, line number of the code that has been profiled,Mem usage, the memory usage of the Python interpreter after that line has been executedIncrement, the difference in memory of the current line with respect to the last oneOccurrences, the number of times this line has been executedLine Contents, the code that has been profiled
We can tell from the result profile that Line 3 ("for x in pdf.v") consumes the most memory: ~125 MiB; and the total memory usage of the function is ~185 MiB.
We can optimize the function to be more memory-efficient by removing the iteration of pdf.v as shown below.
The updated result profile is as shown below.
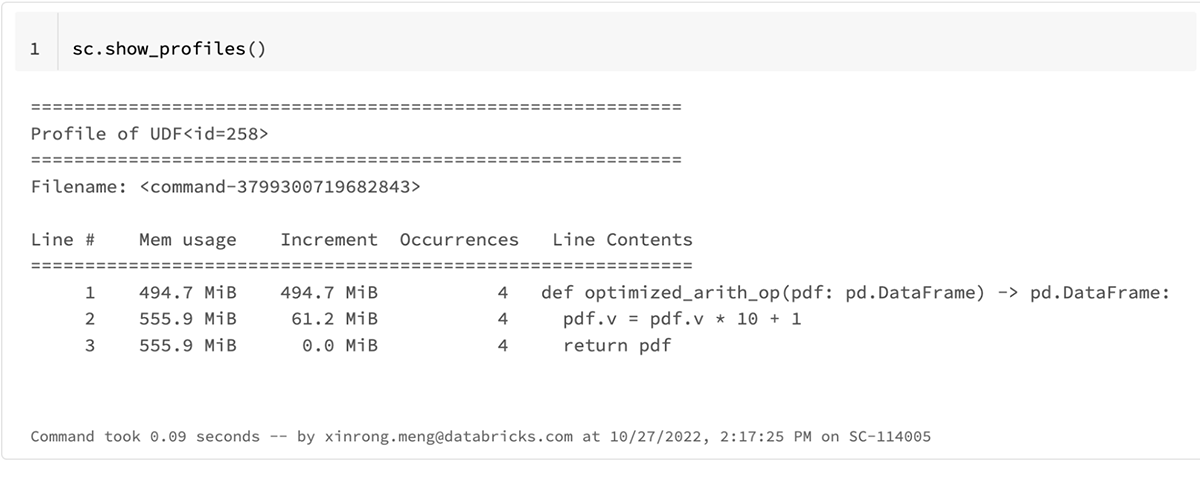
The total memory usage for the optimized_arith_op is reduced to ~61 MiB which uses 2x less memory.
The example above demonstrates how the memory profiler helps deeply understand the memory consumption of the UDF, identify the memory bottleneck, and make the function more memory-efficient.
Conclusion
PySpark memory profiler is implemented based on Memory Profiler. Spark Accumulators also play an important role when collecting result profiles from Python workers. The memory profiler calculates the total memory usage of a UDF and pinpoints which lines of code attribute to the most memory usage. It is easy to use and available starting from Databricks Runtime 12.0.
In addition, we have open sourced PySpark memory profiler to the Apache Spark™ community. The memory profiler will be available starting from Spark 3.4; see SPARK-40281 for more information.