Best Practices for Super Powering Your dbt Project on Databricks

dbt is a data transformation framework that enables data teams to collaboratively model, test and document data in data warehouses. Getting started with dbt and Databricks SQL is very simple with the native dbt-databricks adapter, support for running dbt in production in Databricks Workflows, and easy connectivity to dbt Cloud through Partner Connect. You can have your first dbt project running in production in no time at all!
However, as you start to deploy more complex dbt projects into production you will likely need to start using various advanced features like macros and hooks, dbt packages and third party tools to help improve your productivity and development workflow. In this blog post, we will share five best practices to supercharge your dbt project on Databricks.
- Monitor dbt projects using the dbt_artifacts package
- Load data from cloud storage using the databricks_copy_into macro
- Optimize performance of Delta tables using dbt post hooks
- Run the dbt-project-evaluator to ensure your project meets best practices
- Use SQLFluff to standardize SQL in dbt projects
Monitor dbt projects using the dbt_artifacts package
When invoking dbt commands for a dbt project, a lot of useful files and metadata, known as artifacts, are generated about the project and runs. Brooklyn Data have developed a dbt package, dbt_artifacts, that uploads all this metadata into Delta tables and then builds a star schema model on top that is used to power useful reports and dashboards for monitoring dbt projects on Databricks.
Using dbt_artifacts as part of your dbt project is very simple as shown by the following steps.
To begin, add the package to the packages.yml file in the dbt project’s root folder.
By default the package will upload the raw artifacts data and create the dbt_artifacts models in the default target catalog and schema defined in profiles.yml. However, as a recommendation for production, it can be better for this to be in a separate catalog or schema. This is controlled by updating the dbt_project.yml file with the desired catalog, which is called database in dbt, and schema locations.
To upload the artifacts to Delta tables add the following line to the same dbt_project.yml file. This will execute the upload_results macro after each dbt cli command has finished.
Install the package using dbt deps and then run all the jaffle_shop models and tests using dbt build. The following output sample shows that the artifacts models were built and the artifacts data was uploaded correctly.
It’s then possible to build insightful reports and charts that can be added to a dbt project monitoring dashboard such as showing the avg, min and max run time for each model.
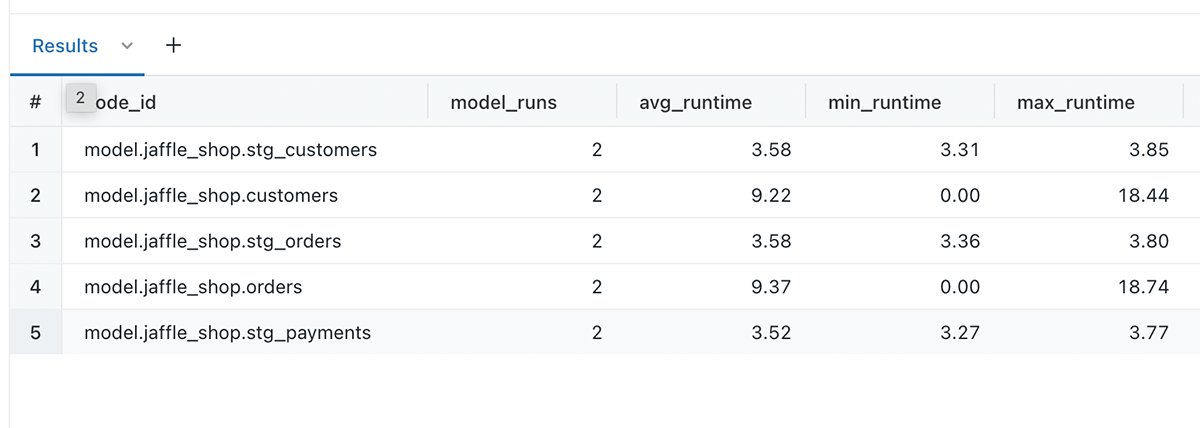
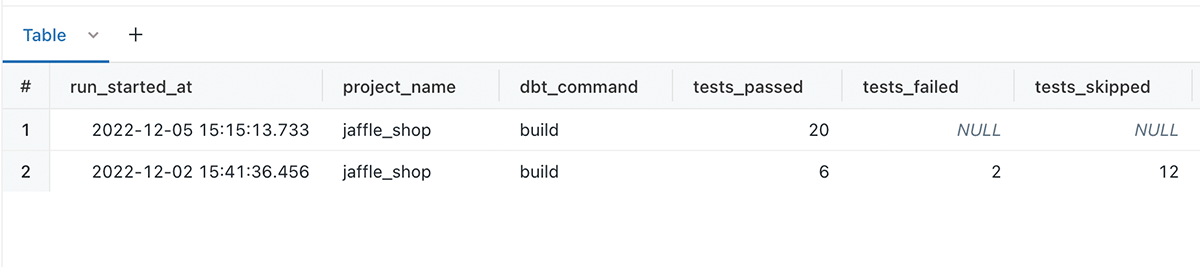
Along with showing the numbers of dbt tests that passed, failed or were skipped for each dbt invocation.
Load data from cloud storage using the databricks_copy_into macro
dbt is a great tool for the transform part of ELT, but there are times when you might also want to load data from cloud storage (e.g. AWS S3, Azure Data Lake Storage Gen 2 or Google Cloud Storage) into Databricks. To make this simple, dbt-databricks now provides the macro databricks_copy_into for loading many file formats, including Parquet, JSON and CSV, from cloud storage into Delta tables. Under the hood, the macro uses the COPY INTO SQL command.
Note: dbt natively provides a seeds command but this can only load local CSV files.
COPY INTO is a retriable and idempotent operation which means any files that have already been loaded will be skipped if the command is run again on the same files.
To use the macro, first set up temporary credentials to the cloud storage location and then run the databricks_copy_into macro using the CLI command below to load the data with the temporary credentials provided and any other required arguments for COPY INTO. The following example shows how to load CSVs including headers from an AWS S3 bucket with automatic schema inference:
Optimize performance of Delta tables using dbt post hooks
Databricks offers fast out of the box query performance for data stored in Delta format. To unlock reliably fast performance, we recommend running the following SQL statements to manage and optimize tables created as part of your dbt project:
- OPTIMIZE - Coalesce small files into larger ones to improve the speed of read queries.
- ZORDER - Colocate column information in the same set of files so that Delta Lake data-skipping algorithms reduce the amount of data that needs to be read for queries.
- ANALYZE TABLE … COMPUTE STATISTICS - collects statistics used by the Databricks SQL query optimizer to find a better query execution plan.
Continuing with the jaffle_shop example, you should run these SQL commands each time the customers table is updated with new data. The table is z-ordered on the customer_id column, a common column used for filtering or joins.
The easiest way to do this is a dbt project is to use post-hooks which can be added to the config block at the top of each model. The customers.sql model can be updated to have this config block and post hook:
Now each time the dbt project is run any dbt models with these post-hook configs will run the SQL statements after the table is created or updated, ensuring your tables are always fully optimized.
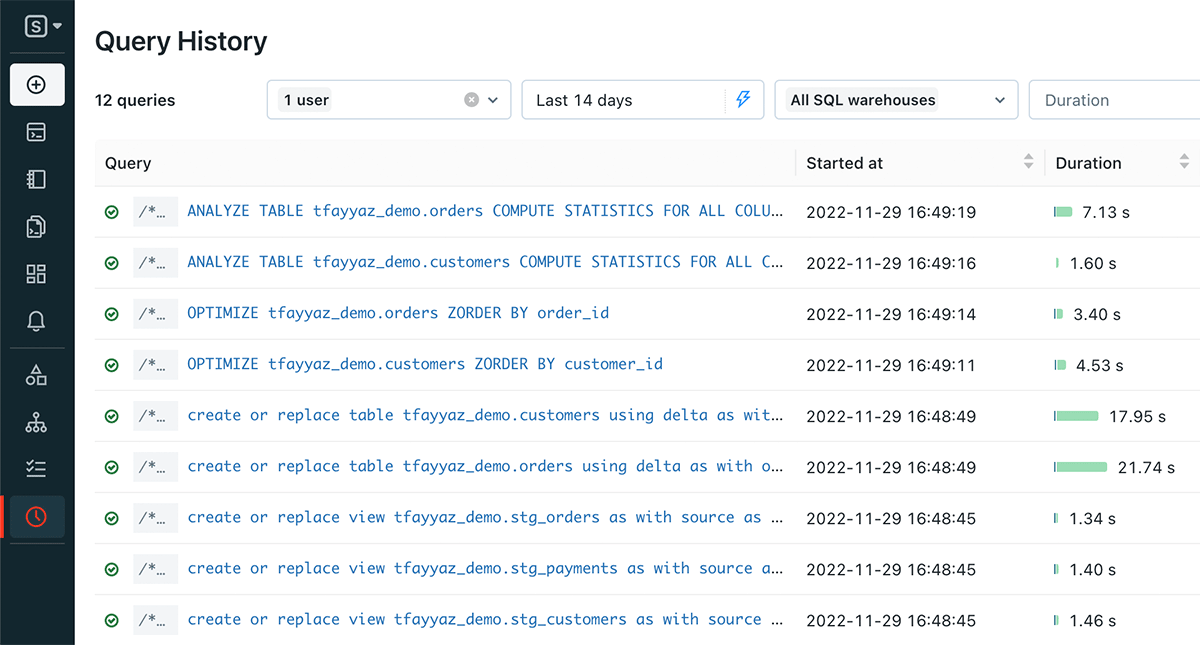
You can easily monitor all the SQL statements run by dbt using the Databricks SQL query history page, which shows OPTIMIZE and ANALYZE running after the tables are created.
Your compact guide to modern analytics

Run the dbt_project_evaluator to ensure your project meets best practices
dbt Labs provide prescriptive guidance and best practices on developing and structuring dbt projects in their documentation and popular community slack channel. However, it can be easy to fail to incorporate all of the best practices, especially as projects, models and teams grow. Luckily, dbt Labs have built a nifty package called dbt-project-evaluator that will parse your model directory and surface places where your project does not follow best practices.
To install the package via dbt hub just include the latest version of the package in your packages.yml file:
Next, add the following to the dbt_project.yml file to ensure all macros and dbt_utils methods work with Databricks:
To evaluate your project, install the packages using dbt deps and then run dbt build --select package:dbt_project_evaluator. The example below shows the guidance provided for the default jaffle_shop dbt project by the dbt_project_evaluator package
As the evaluator runs, it creates views and tables and then runs tests which provide the guidance for your project. The tables created hold the results to the tests allowing you easily see what needs to be resolved for your dbt project.
To break down the guidance provided for jaffle_shop let’s look at the 3 warnings provided and how you can resolve them.
- Warning in test dbt_utils_accepted_range_fct_documentation_coverage_documentation_coverage_pct___var_documentation_coverage_target_
- Warning in test is_empty_fct_model_naming_conventions_
- Warning in test is_empty_fct_undocumented_models_
For all of the tests, the fact tables (prefixed with fct_) they are run against are highlighted in bold and this is where you can then find the list of issues that need to be fixed.
Test 1 is giving a warning that the accepted range of documented coverage is less than 100% , which is the default value but can be customized.
Test 2 and 3 are giving warnings for violations for model naming conventions and for undocumented models.
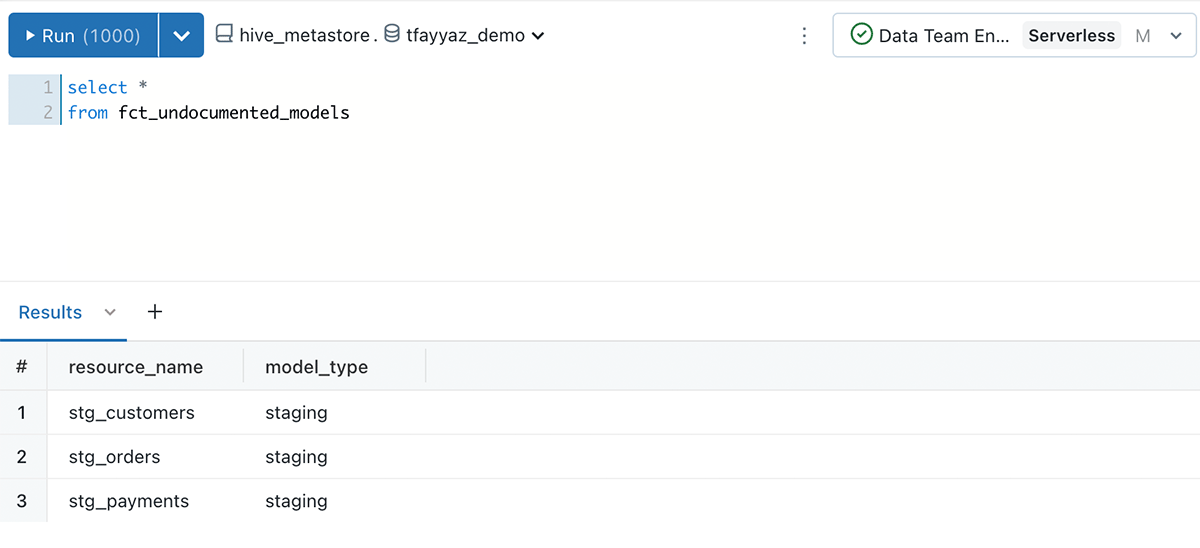
To learn more about each result you can search for the fct_ table names in the package rules documentation. Eg. Search for fct_undocumented_models.
You can then query the fct_undocumented_models table in Databricks SQL to see exactly what models need documentation to be added.
Use SQLFluff to standardize SQL in dbt projects
dbt is designed to help you better develop, structure, and version control your SQL transformations but it does not help with ensuring the SQL is easily readable, well formatted and compliant with SQL style guides your company might have. This is where SQLFluff, a modular SQL linter and auto-formatter, shines as it helps standardize SQL whilst developing models and can easily be deployed as part of any dbt project and workflow.
Install sqlfluff in the same environment as dbt:
Before using the sql linter, some configurations need to be set up for dbt and Databricks. Create a .sqlfluff file in the root folder of the dbt project that sets the templater as dbt and the dialect as sparksql, which also works for Databricks SQL.
To learn more about the possible options view .sqlfluff configurations docs and the dbt configurations docs.
To showcase what types of issues SQLFluff can detect, change the last line of the models/customers.sql file in the jaffle_shop dbt project to have an intentional linting error by mixing a capitalized SELECT with a lowercase from keyword.
Then in the terminal, run the following command to see a list of syntax issues:
Running this should give the output below, including the syntax issue rule L10 for the keyword, SELECT on Line 69, not being lowercase.
Next, a user could manually fix the issues in an IDE or automatically fix them using sqlfluff directly. For example, the command below will attempt to automatically fix syntax issues in the models/customers.sql file showing what was successful.
Any rules, such as L027, that were not fixed can be added the excluded_rules list in the .sqlfluff file. It’s also possible to define policies for each rule such as setting the capitalisation_policy to lower for L10.
SQLFluff is very powerful and flexible so it’s recommended to look at the full list of SQLFluff rules and configurations to ensure it’s set-up in a way to meet your team’s requirements.
Next steps
dbt and Databricks offer you the ability to solve many different data, analytics and AI use cases and using the superpowers above is just a small fraction of what is possible to help you take projects and data pipelines to the next level of optimization. To see what else is possible follow the links below:
- Watch the dbt and Databricks best practices and future roadmap webinar
- Visit the dbt package hub,
- Read the advanced dbt-databricks guides
- Try the dbt with Databricks step-by-step training series or
- Join the #db-databricks-and-spark channel in the dbt slack community