Best Practices and Guidance for Cloud Engineers to Deploy Databricks on AWS: Part 2
A conversation on a standard Databricks on AWS deployment

This is part two of a three-part series in Best Practices and Guidance for Cloud Engineers to deploy Databricks on AWS. You can read part one of the series here.
As noted, this series's audience are cloud engineers responsible for the deployment and hardening of a Databricks deployment on Amazon Web Services (AWS). In this blog post, we will be stepping through a standard enterprise Databricks deployment, networking requirements, and commonly asked questions in more technical detail.
To make this blog easier to digest and not sound like additional documentation on networking, I'll be writing this post as if I, or any of our solution architects, were explaining best practices and answering questions from a fictitious customer, ACME's cloud engineering team.
While this conversation never took place, this is an accumulation of real customer conversations that we have on a near-daily basis.
One note before we continue, as we discuss the networking and deployment requirements in the next section, it might seem that Databricks is complex. However, we've always seen this openness as a form of architectural simplicity. You're aware of the compute that's being deployed, how it's reaching back to the Databricks control plane, and what activity is taking place within your environment using standard AWS tooling (VPC Flow Logs, CloudTrail, CloudWatch etc.).
As a lakehouse platform, Databricks' underlying compute will interact with a wide variety of resources from object stores, streaming systems, external databases, the public internet, and more. As your cloud engineering teams adopt these new use cases, our classic data plane gives a foundation to make sure these interactions are efficient and secure.
And of course, if you want Databricks to manage the underlying compute for you. We have our Databricks SQL serverless option.
Throughout the rest of the post, I'll denote myself speaking with "J" and my customer replying with a "C". Once the conversation concludes at the end of this blog, I'll discuss what we'll be talking about in part three, which will cover ways to deploy Databricks on AWS.
NOTE: If you haven't read part one of this series and are not familiar with Databricks, please read before continuing to the remaining part of this blog. In part one, I walk through, at a conceptual level, the architecture and workflow of Databricks on AWS.
The Conversation:
J: Welcome everyone, I appreciate you all joining today.
C: Not a problem. As you know, we're part of ACME's cloud engineering team and our data analytics lead told us about the Databricks proof of concept that just happened and how they now want to move into our production AWS ecosystem. However, we're unfamiliar with the platform and want to understand more about what it takes to deploy Databricks on AWS. So, it would be great if you walked through the requirements, recommendations, and best practices. We might have a few questions here and there as well.
J: Happy to step through the components of a standard Databricks deployment. As I go through this, please feel free to jump-in and interrupt me with any questions you may have.
J: Let's get started. I like to boil down the core requirements of a standard deployment to the following: customer-managed VPC, data plane to control plane connectivity, cross-account IAM role, and S3 root bucket. Throughout this call, I'll show a portion of our Databricks Account console where you can register this information. Of course, this can all be automated, but I want to give a visual anchor of what portion we're discussing. Let's start with our customer-managed VPC.
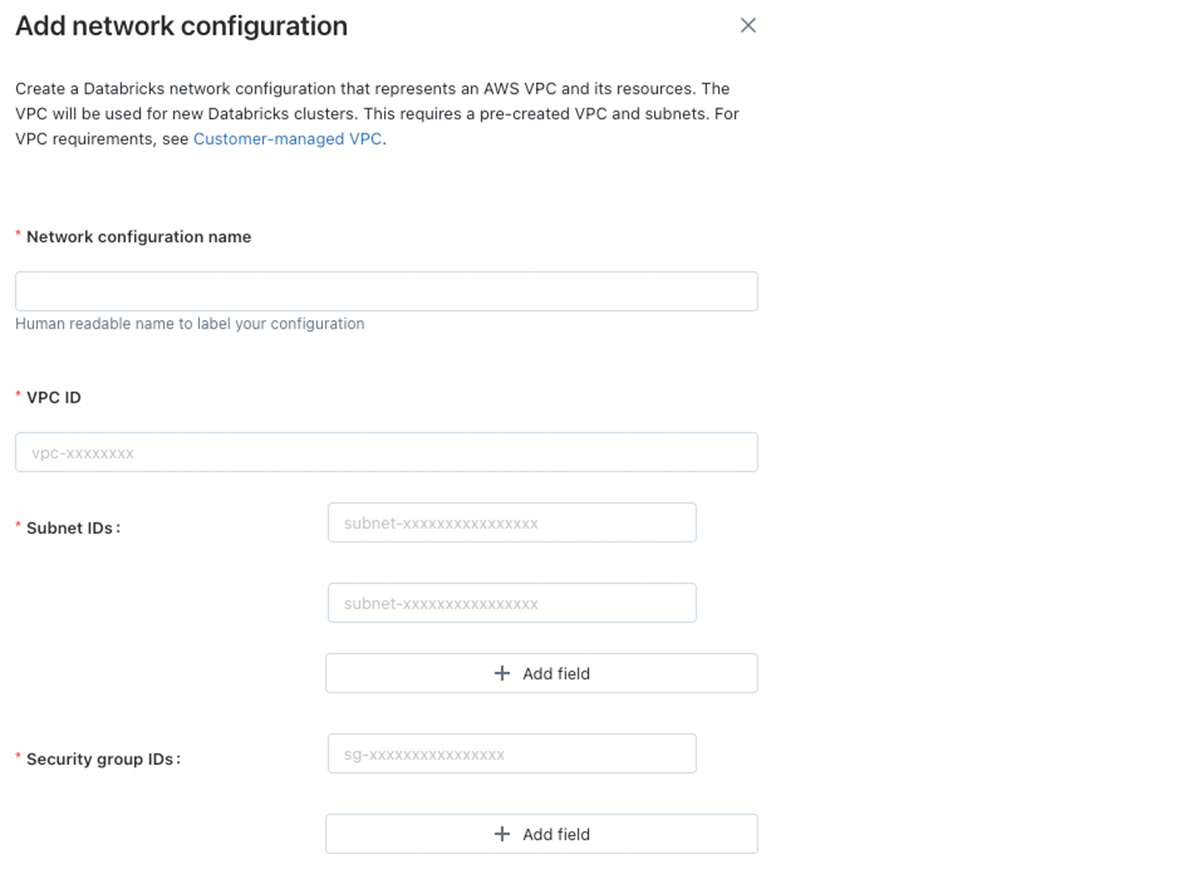
J: Customer-managed VPC come in various shapes and sizes based on various networking and security requirements. I prefer to start with a foundation of the baseline requirements and then build on-top any uniqueness that may exist within your environment. The VPC itself is fairly straightforward; it must be smaller than a /25 netmask and have DNS hostnames and DNS resolution enabled.
J: Now, onto the subnets. For each workspace there must be a minimum of two dedicated private subnets that each have a netmask of between /17 and /26 and are in separate availability zones. Subnets cannot be reused by other workspaces and it's highly recommended that no other AWS resources are placed in that subnet space.
C: A couple of questions on the workspace subnets. What size subnets do your customers typically use for their workspace? And why can't they be used by other workspaces or have other resources in the same subnet?
J: Great questions. Subnet sizing will depend from customer to customer.However, we can get an estimate by calculating the number of Apache Spark (™) nodes that might be needed for your lakehouse architecture. Each node requires two private IP addresses, one for managing traffic and the other for the Apache Spark (™) application. If you create two subnets with a netmask of /26 for your workspace, you would have a total of 64 IPs available within a single subnet, 59 after AWS takes the first four IPs and the last IP. That means the maximum number of nodes would be around 32. Ultimately, we can work backward from your use cases to properly size your subnets whether that is through more subnets that are smaller (e.g. six in US-EAST-1) or less subnets that are larger.
| VPC size (CIDR) | Subnets size (CIDR) | Maximum AWS Databricks cluster nodes per individual subnet |
|---|---|---|
| >= /16 | /17 | ~16384 |
| . . . | . . . | . . . |
| >= /20 | /21 | ~1024 |
| . . . | . . . | . . . |
| >= /25 | /26 | ~32 |
C: Thanks for that, if we want to dedicate a single VPC to various development workspaces, what would be your recommendation for breaking that down?
J: Sure, let's break down a VPC with an address space of 11.34.88.0/21 into five different workspaces. You then should allocate users into the appropriate workspace based on their usage. If a user needs a very large cluster to process hundreds of gigabytes of data, put them into the X-Large. If they are only doing interactive usage on a small subset of data? You can put them in the small workspace.
| T-Shirt Size | Max Cluster Nodes Per Workspace | Subnet CIDR #1 | Subnet CIDR #2 |
|---|---|---|---|
| X-Large | 500 Nodes | 11.34.88.0/23 | 11.34.90.0/23 |
| Large | 245 Nodes | 11.34.92.0/24 | 11.34.93.0/24 |
| Medium | 120 Nodes | 11.34.94.0/25 | 11.34.94.128/25 |
| #1 Small | 55 Nodes | 11.34.95.0/26 | 11.34.95.64/26 |
| #2 Small | 55 Nodes | 11.34.95.128/26 | 11.34.95.192/26 |
J: On your second question, since it's important that your end users aren't impacted by IP exhaustion when trying to deploy or re-size the cluster, we enforce that subnets are not overlapping at the account level. This is why, in enterprise deployments, we warn not to put other resources in the same subnet. To optimize the availability of IPs within a single workspace, we recommend using our automatic availability zone (auto-AZ) option for all clusters. This will place a cluster in the AZ with the most available space.
J: And remember, you can switch your underlying network configuration anytime with a customer-managed VPC if you want to move VPC, subnets, etc.
J: If there are no more questions on subnets, let's move on to another component that is logged when you're creating a Databricks workspace: security groups. The security group rules for the Databricks EC2 instances must allow all inbound (ingress) traffic from other resources in the same security group. This is to allow traffic between the Spark nodes. The outbound (egress) traffic rules are:
- All TCP and UDP access to the workspace security group (for internal traffic)
- 443: Databricks infrastructure, cloud data sources, and library repositories
- 3306: Default hive metastore
- 6666: Secure cluster connectivity relay for PrivateLink enabled workspaces
- Any other outbound traffic your applications require (e.g. 5409 for Amazon Redshift)
J: It's a common error that folks may run into is the failure to connect to Apache Kafka, Redshift, etc. because of a blocked connection. Be sure to check that your workspace security group allows that outbound port.
C: No issues right now with the security group rules. However, I took a look at your documentation - why does the Databricks deployment require ALLOW ALL on the inbound NACLs subnet rules?
J: We use a layered security model where default NACL rules are used on the subnets, but restrictive security group rules for the EC2 instances mitigate that. In addition, many customers add a network firewall to restrict any outbound access to the public internet. Here is a blog post on data exfiltration protection - on how to safeguard your data against malicious or unconscious actors.
J: OK, we have covered the requirements for VPCs, subnets, security groups, and NACLs. Now, let's talk about another requirement of the customer-managed VPC, the data plane to control plane connectivity. When the cross-account IAM role spins up an EC2 instance in your AWS account, one of the first activities the cluster will try is to call home to the Databricks AWS account or referred to as the control plane.
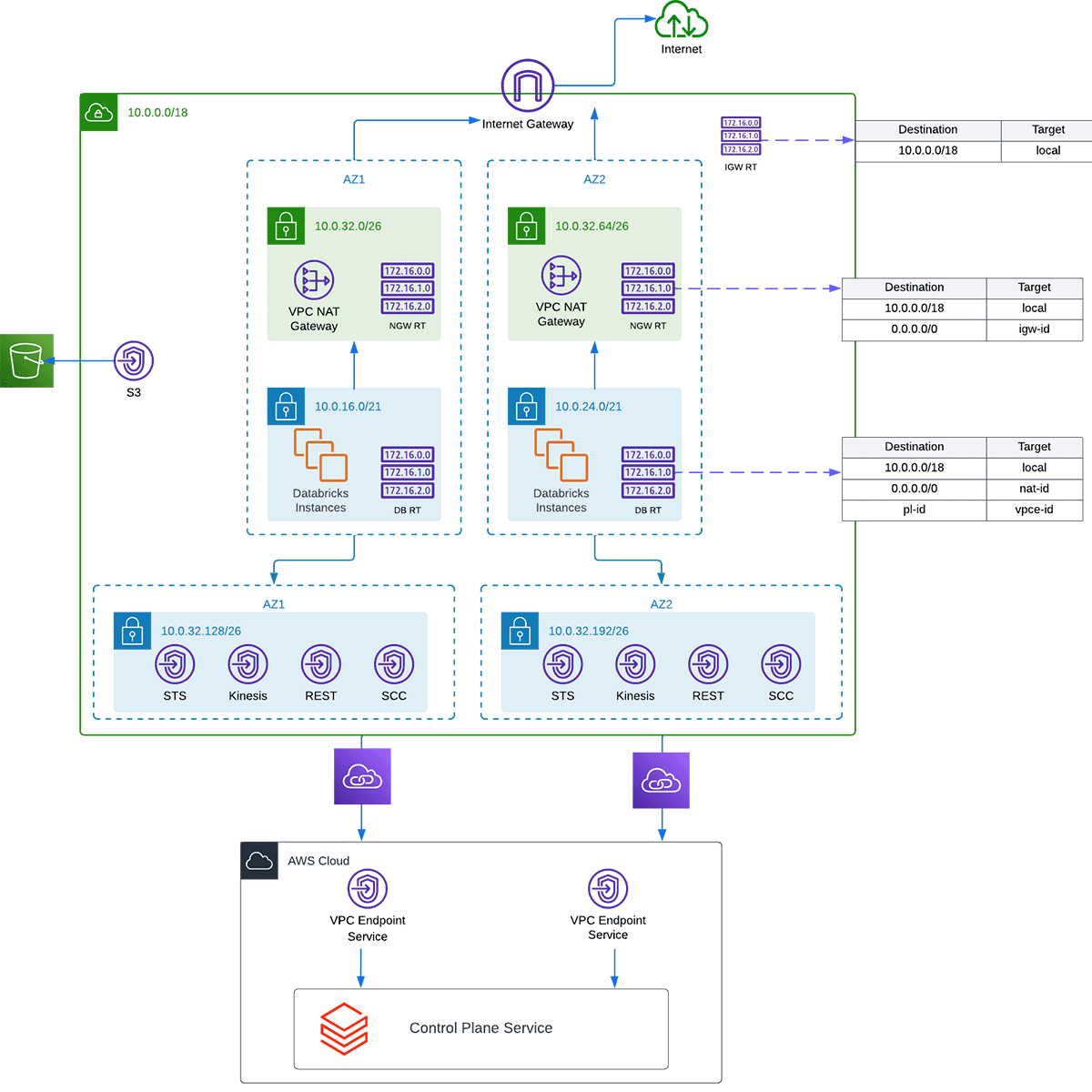
J: This process of calling home is called our secure cluster connectivity relay or SCC for short. This relay allows Databricks to have no public IPs or open ports on the EC2 instances within your environment and allows traffic to always be initiated from the data plane to the control plane. There are two options to route this outbound traffic. The first option is to route the SCC to the public internet through a NAT and internet gateway or other managed infrastructure. For standard enterprise deployment, we highly recommend using our AWS PrivateLink endpoints to route the SCC relay and the REST API traffic over the AWS backbone infrastructure, adding another layer of security.
C: Can PrivateLink be used for front-end connectivity as well? So that our users route through a transit VPC to the Databricks workspace in the control plane?
J: Yes. When creating your PrivateLink-enabled Databricks workspace, you'll need to create a Private Access Object or PAS. The PAS has an option if you'd like to enable or disable public access. While the URL to the workspace will be available on the internet, if a user does not route through the VPC endpoint while the PAS has the public access configured set to 'false' they'll see an error that they've accessed the workspace from the wrong network and will not be allowed to sign in. An alternative to our front-end PrivateLink connection that we see enterprise customers use is IP access lists.
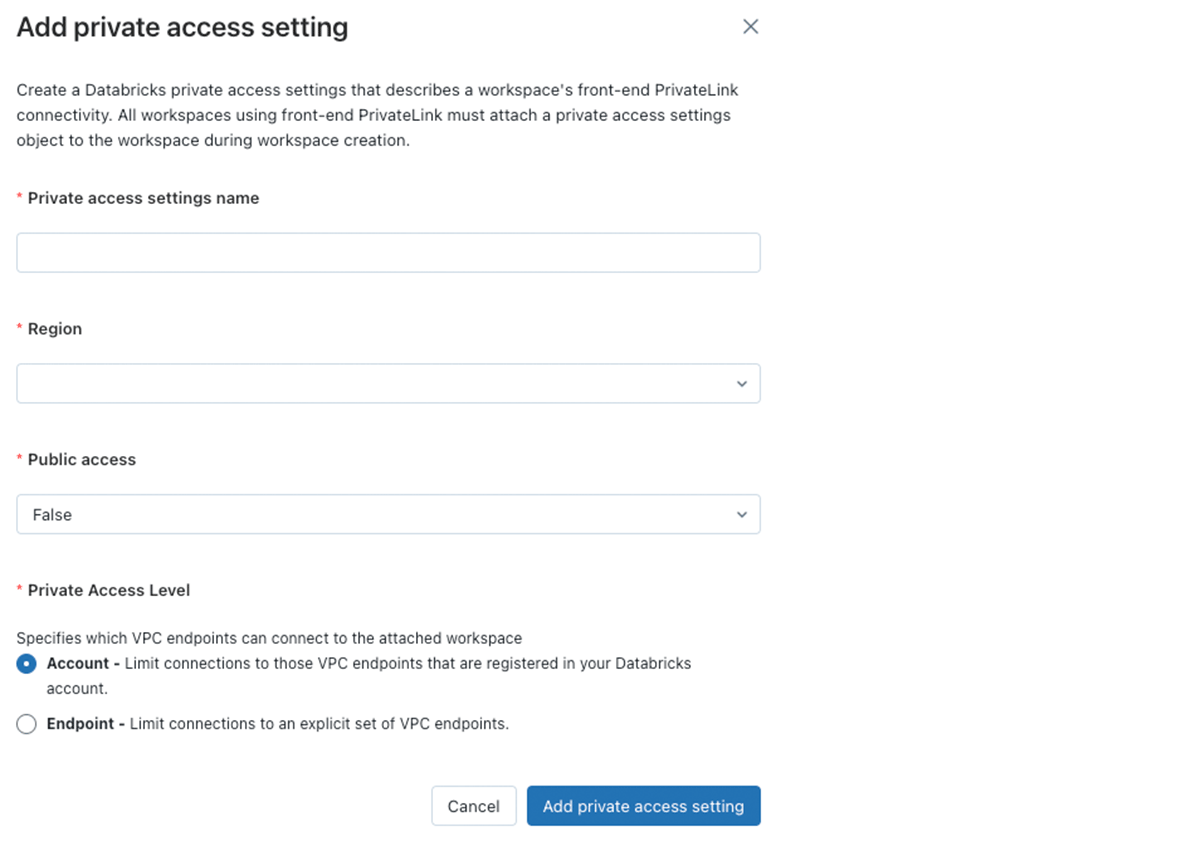
C: So with the appropriate PrivateLink settings, can we entirely lockdown the cluster if we route to the control plane through PrivateLink and have no internet gateway available for the EC2 instances to make their way to?
J: Yes, you can. However, you will need an S3 gateway endpoint, Kinesis interface endpoint, and STS interface endpoint.I want to note that you will not have a connection to the Databricks default hive metastore nor be able to access repositories like PyPI, Maven, etc. Since you'd have no access to the default hive metastore, you'd need to use your own RDS instance or AWS Glue Catalog. Then for packages, you'd need to self-host the repositories in your environment. For these reasons is why we recommend an egress firewall to restrict what areas of the public internet your user's clusters can reach instead.
C: S3, Kinesis, and STS, why those three endpoints?
J: Sure, S3 endpoint will be needed not only for EC2 to reach the root bucket but also for S3 buckets that contain your data. It will save you money and add another layer of security by keeping traffic to S3 on the AWS backbone. Kinesis is for internal logs that are collected from the cluster, including important security information, auditing information, and more. STS is for temporary credentials that can be passed to the EC2 instance.
J: As a final note on networking, before we summarize what we've discussed so far. I encourage you to use the VPC Reachability Analyzer if you run into any issues connecting to various endpoints, data sources, or anything else within the region. You can spin up a cluster in the Databricks console, find it in your EC2 console under "workerenv", and then use that ID as the source and your target ID as the destination. This will give you a GUI view of where traffic is being routed or potentially blocked.
J: Now, to wrap up what we've covered so far. We discussed the VPC, subnets, security groups, PrivateLink, other endpoints, and how EC2 instances make outbound connections to the control plane. The last two parts of our deployment I'd like to talk about are the cross-account IAM role and workspace root bucket.
J: A required portion of the deployment, the cross-account IAM role is used when initially spinning up EC2 instances within your environment. Whether through APIs, user interface, or scheduled jobs, this is the role Databricks will assume to create the clusters. Then, when using Unity Catalog or directly adding instance profiles, Databricks will pass the necessary role to the EC2 instances.
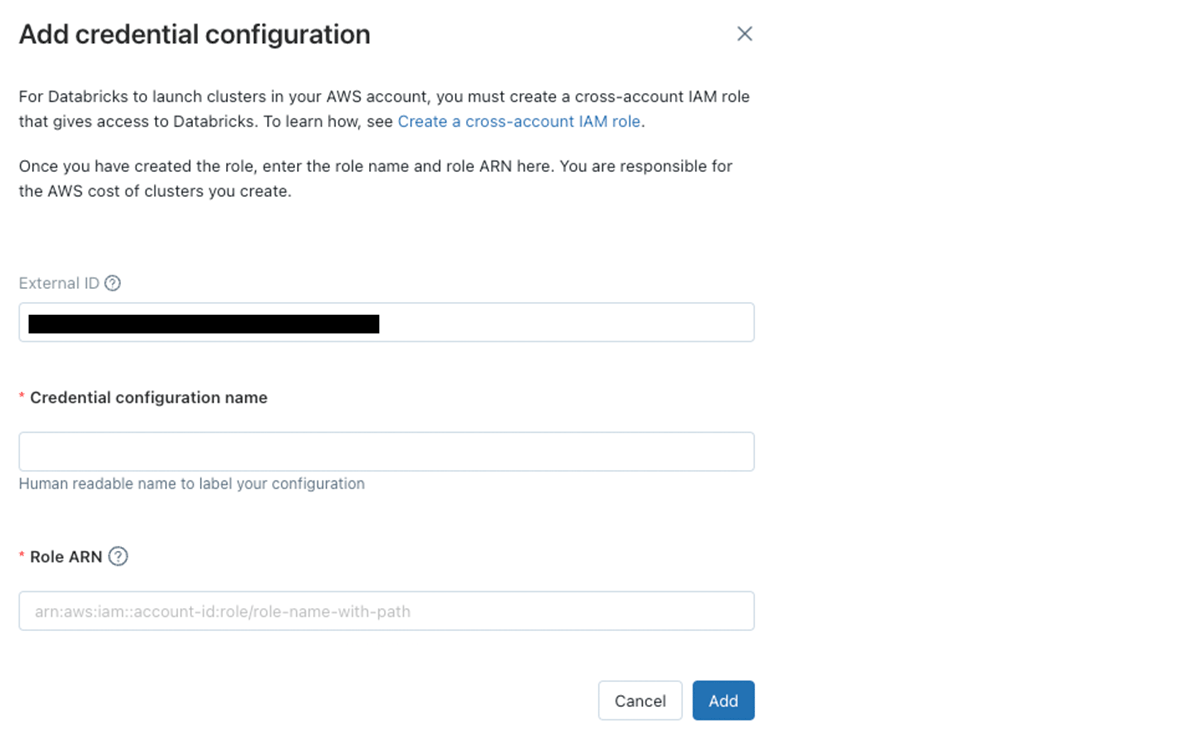
C: Cross-account roles are standard for our PaaS solutions in our environment, no problem there. However, do you have an example of a scoped down cross-account role that restricts to a VPC, subnet, etc.?
J: Of course. It's recommended to restrict your cross-account role to only the necessary resources. You can find the policy in our documentation. An additional restriction you can use is to restrict where the EC2 AMIs are sourced from, which is found on the same documentation page. As a quick note, in our documentation, you can find the proper IAM roles for both Unity Catalog and Serverless.
J: For the last required portion of the deployment, the workspace root bucket. This S3 bucket is used to store workspace objects like cluster logs, notebook revisions, job results and libraries. It has a specific bucket policy allowing the Databricks control plane to write to it. It's a best practice that this bucket is not used for customer data or multiple workspaces. You can track events in these buckets through CloudTrail, like normal buckets.
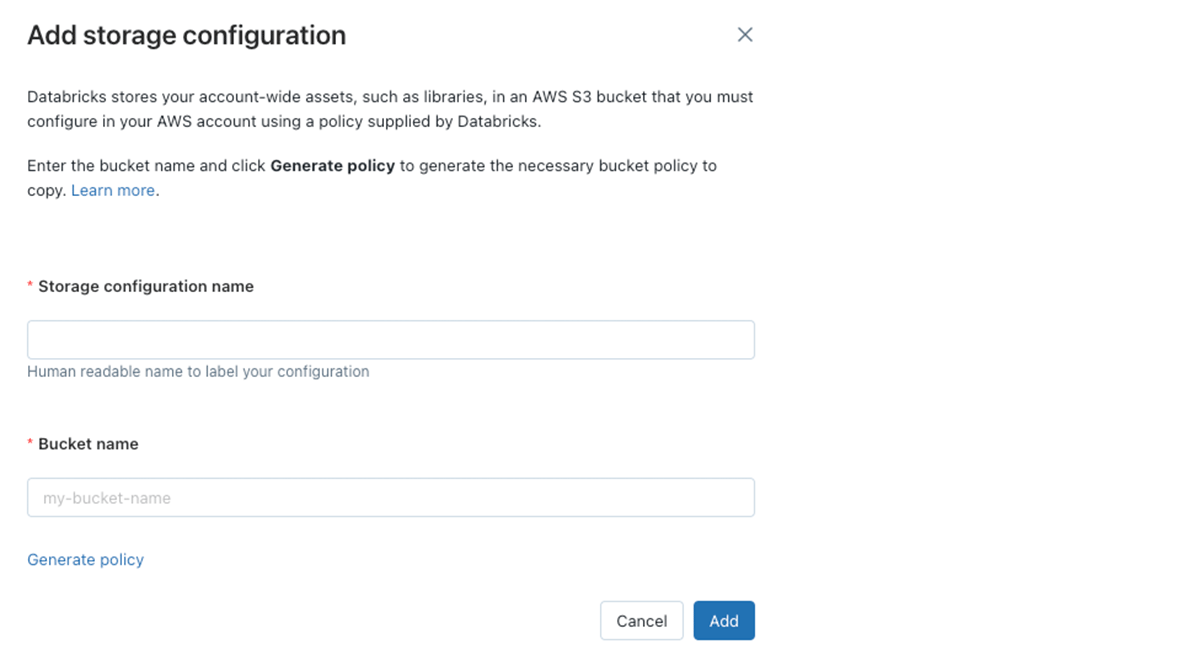
C: We have an encryption requirement for all of our S3 buckets in our AWS account Can this root bucket be encrypted using a customer managed key?
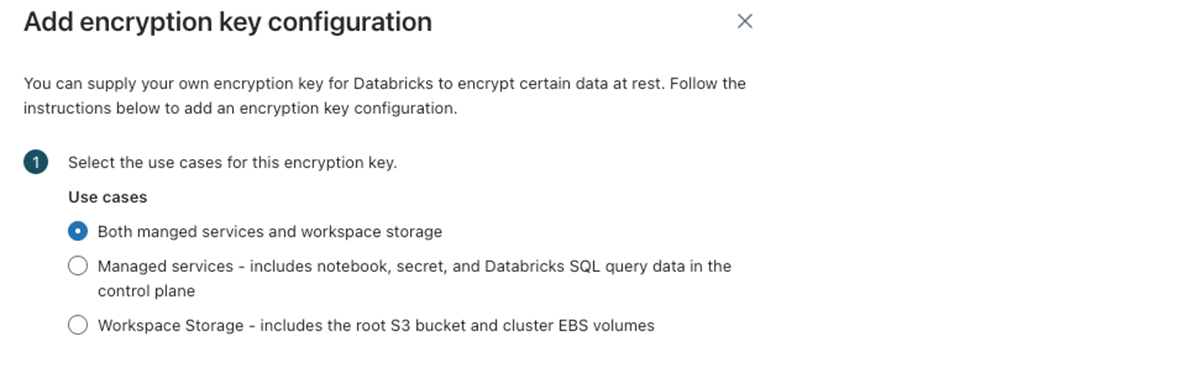
J: Yes, you can, thanks for bringing this up. An optional part of the deployment, or something that can be added later, is adding a customer managed key for either managed storage or workspace storage.
- Workspace storage: the root bucket I mentioned before, EBS volumes, job results, Delta Live Tables, etc.
- Managed storage: notebook source metadata, personal access tokens, Databricks SQL queries.
J: I'll be sure to send the documentation with all the information after this call as well.
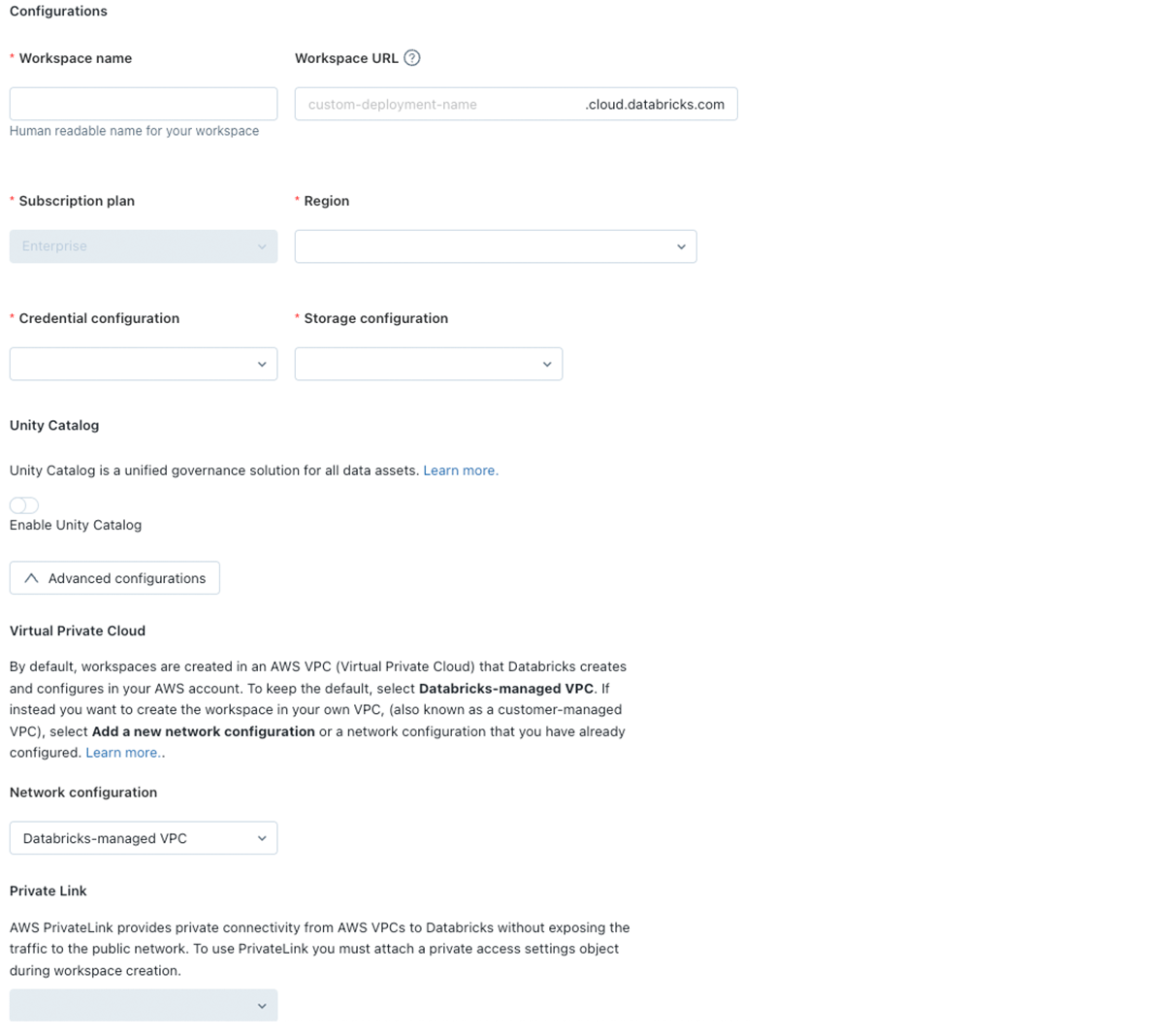
J: It looks like we're approaching time here. So, I just want to summarize the recommendations we discussed today. As I mentioned, there are three required parts and one optional for a Databricks on AWS deployment: Network configuration, storage configuration, and the credential configuration.
- Network configuration: You must size the VPC and subnets for the appropriate use case and users. In the configuration, back-end PrivateLink is our de facto recommendation. Consider front-end PrivateLink or IP access lists to restrict user access. When deploying clusters, be sure to use auto-AZ to deploy to the subnet with the highest availability of IP space. Last, whether you're using PrivateLink or not, please be sure to add in endpoints for STS, Kinesis, and S3 at a minimum. Not only do these add an extra layer of security by keeping traffic over the AWS backbone, it can also drastically reduce cost.
- Storage configuration: After you create your workspace root bucket, do not use this for any customer data nor share this with any other workspaces.
- Credential configuration: Scope down the cross-account role policy based on our documentation that I discussed before.
- Encryption key configuration: Plan to implement encryption on your workspace storage, EBS volumes, and managed objects. As a reminder, you can do this after the workspace is deployed, but for workspace storage objects only net-new objects will be encrypted.
C: Thanks for going through this. One last question, do you have any automated ways to deploy all of this? We're a Terraform shop, but will work with whatever at this point.
J: Of course. We have our Terraform Provider that I can send over after this call. In addition, we also have an AWS QuickStart, which is a CloudFormation template that you can use for your proof of concept as you get your Terraform scripts integrated.
J: Anyway, I appreciate the time today and again, if you have any questions, please feel free to reach out!
I hope the conversation style blog posted helped digest the requirements, recommendations, and best practices when deploying your Databricks Lakehouse Platform on AWS.
In our next blog post, I'll discuss automating this deployment with APIs, CloudFormation, and Terraform with some best practices from customers that we work with.
Until next time!

