Announcing Ray support on Databricks and Apache Spark Clusters

Ray is a prominent compute framework for running scalable AI and Python workloads, offering a variety of distributed machine learning tools, large-scale hyperparameter tuning capabilities, reinforcement learning algorithms, model serving, and more. Similarly, Apache Spark™ provides a wide variety of high-performance algorithms for distributed machine learning through Spark MLlib and deep integrations with machine learning frameworks including XGBoost, TensorFlow, and PyTorch. In order to build the best models, machine learning practitioners frequently need to explore multiple algorithms, often requiring the use of multiple platforms including both Ray and Spark. Today, with the release of Ray version 2.3.0, we are excited to announce that Ray workloads are now supported on Databricks and Spark standalone clusters, dramatically simplifying model development across both platforms.
Create a Ray cluster on Databricks or Spark
To start Ray on your Databricks or Spark cluster, simply install the latest version of Ray and call the ray.util.spark.setup_ray_cluster() function, specifying the number of Ray workers and the compute resource allocation. Any Databricks cluster with Databricks Runtime version 12.0 or above is supported, as well as any Spark cluster running version 3.3 or above. For example, the following code installs Ray in a Databricks notebook and initializes a Ray cluster with two worker nodes:
With just a few lines of code, you have created a Ray cluster and are ready to start training models.
Train models with Ray Train and Ray RLlib
Now that you've started a Ray cluster, it's time to harness the power of distributed machine learning to build a model. All Ray applications and Ray-integrated machine learning algorithms are supported on Databricks and Spark clusters without any modifications. For example, you can use the Ray Train API in your Databricks notebook to easily distribute your XGBoost model training, reducing training time and improving model accuracy:
Ray also provides native support for reinforcement learning. For example, you can run the following Ray RLlib code in your Databricks notebook to train a PPO reinforcement learning algorithm in the Taxi Gymnasium environment:
For additional model training information and examples, check out the Ray Train documentation and the Ray RLlib documentation.
Get started with ETL

Find optimal models with Ray Tune
To improve the quality of your models, you can also leverage Ray Tune to explore thousands of model parameter configurations in parallel at scale. For example, the following code uses Ray Tune to optimize a scikit-learn classification model:
More information and examples about model tuning on Ray, including the use of Ray with MLflow, is available in the Ray Tune documentation.
View the Ray dashboard
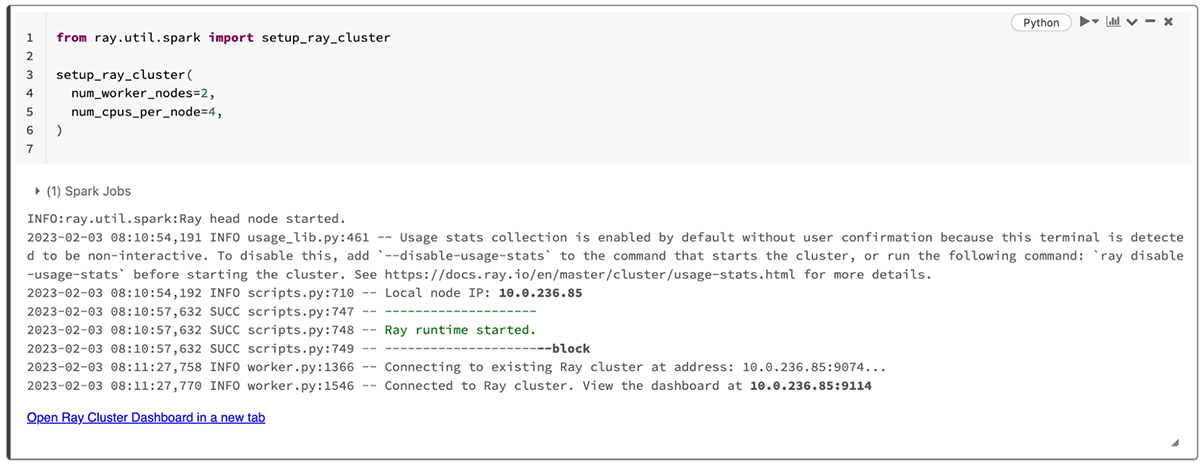
Throughout model development, you can monitor the progress of your Ray machine learning tasks and the health of your Ray nodes using the Ray dashboard. When you create your Ray cluster, the ray.util.spark.setup_ray_cluster() displays a link to the Ray dashboard.
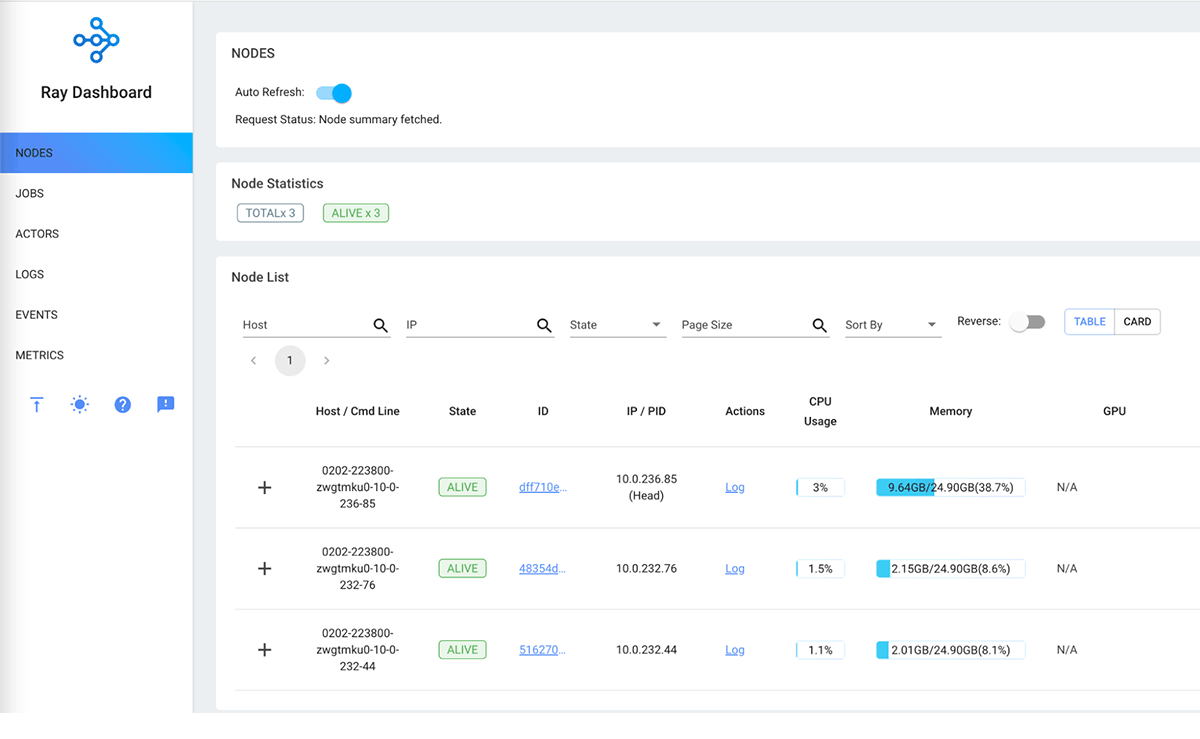
The Ray dashboard provides a comprehensive view of Ray cluster's nodes, actors, metrics, and event logs. You can easily view resource utilization metrics for individual nodes and aggregate metrics across all nodes. For more information about the Ray dashboard, visit the Ray dashboard documentation.
Get started with Ray on Databricks or Spark today
With the availability of Ray 2.3.0, you can start running Ray applications on your Databricks or Spark clusters today. If you're a Databricks customer, simply create a Databricks cluster with version 12.0 or higher of the Databricks Runtime and check out the Ray on Databricks documentation to get started. Finally, instructions for launching Ray on a standalone Spark cluster are provided in the Ray on Spark documentation, and you can visit https://docs.ray.io/en/latest/ to learn more about machine learning on Ray.
We are very excited about this step forward in interoperability for distributed machine learning and look forward to powering your Ray applications on Apache Spark™ and Databricks!