Visual data modeling using erwin Data Modeler by Quest on the Databricks Lakehouse Platform
Data Modeling using erwin on Databricks

This is a collaborative post between Databricks and Quest Software. We thank Vani Mishra, Director of Product Management at Quest Software for her contributions.
Data Modeling using erwin Data Modeler
As customers modernize their data estate to Databricks, they are consolidating various data marts and EDWs into a single scalable lakehouse architecture which supports ETL, BI and AI. Usually one of the first steps of this journey starts with taking stock of the existing data models of the legacy systems and rationalizing and converting them into Bronze, Silver and Gold zones of the Databricks Lakehouse architecture. A robust data modeling tool that can visualize, design, deploy and standardize the lakehouse data assets greatly simplifies the lakehouse design and migration journey as well as accelerates the data governance aspects.
We are pleased to announce our partnership and integration of erwin Data Modeler by Quest with the Databricks Lakehouse Platform to serve these needs. Data modelers can now model and visualize lakehouse data structures with erwin Data Modeler to build Logical and Physical data models to fast-track migration to Databricks. Data Modelers and architects can quickly re-engineer or reconstruct databases and their underlying tables and views on Databricks. You can now easily access erwin Data Modeler from Databricks Partner Connect!
Here are some of the key reasons why data modeling tools like erwin Data Modeler are important:
- Improved understanding of data: Data modeling tools provide a visual representation of complex data structures, making it easier for stakeholders to understand the relationships between different data elements.
- Increased accuracy and consistency: Data modeling tools can help ensure that databases are designed with accuracy and consistency in mind, reducing the risk of errors and inconsistencies in data.
- Facilitate collaboration: With data modeling tools, multiple stakeholders can collaborate on the design of a database, ensuring that everyone is on the same page and that the resulting schema meets the needs of all stakeholders.
- Better database performance: Properly designed databases can improve the performance of applications that rely on them, leading to faster and more efficient data processing.
- Easier maintenance: With a well-designed database, maintenance tasks like adding new data elements or modifying existing ones become easier and less error-prone.
- Enhanced data governance, data intelligence and metadata management.
In this blog, we will demonstrate three scenarios on how erwin Data Modeler can be used with Databricks:
- The first scenario is where a team wants to build a fresh Entity Relationship Diagram (ERD) based on documentation from the business team. The goal is to create an ER diagram for the logical model for a business unit to understand and apply relationships, definitions and business rules as applied in the system. Based on this logical model, we will also build a physical model for Databricks.
- In the second scenario, the business unit is building a visual data model by reverse engineering it from their current Databricks environment, to understand business definitions, relationships and governance perspectives, in order to collaborate with the reporting and governance team.
- In the third scenario, the Platform architect team is consolidating its various Enterprise Data Warehouse(EDW) and data marts such as Oracle, SQL Server, Teradata, MongoDB etc. into the Databricks Lakehouse platform and building a consolidated Master model.
Once ERD creation is complete, we will show you how to generate a DDL/SQL file for Databricks physical design team.
Scenario #1: Create a new Logical and Physical Data Model to implement in Databricks
The first step will be selecting a Logical/Physical model as shown here:
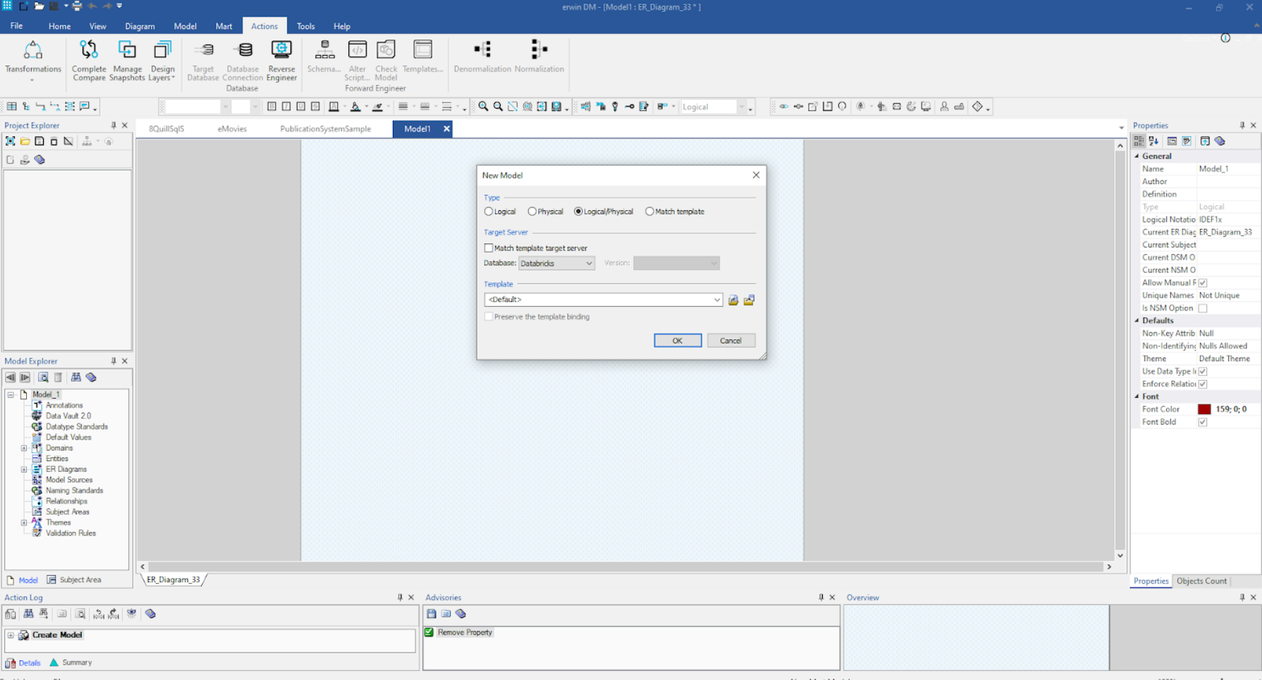
Once selected, you can start building your entities, attributes, relationships, definition, and other details in this model.
The screenshot below shows an example of an advanced model:
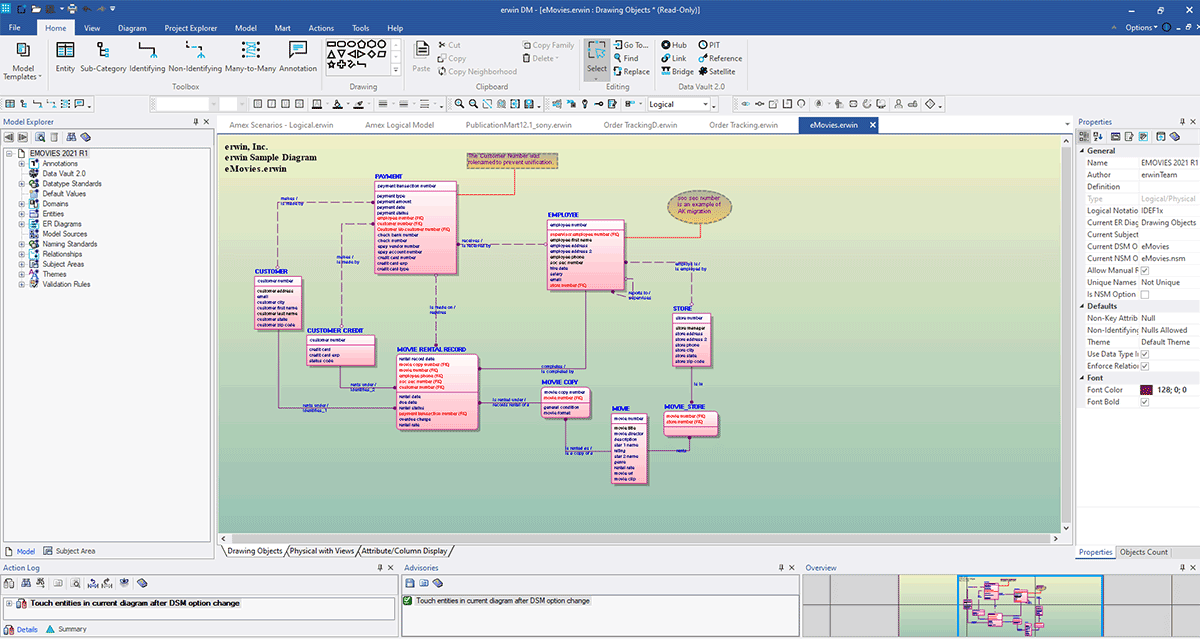
Here you can build your model and document the details as needed. To learn more about how to use erwin Data modeler, refer to their online help documentation.
Data warehousing in the lakehouse

Scenario #2: Reverse Engineer a Data Model from the Databricks Lakehouse Platform
A Data Model reverse engineering is creating a data model from an existing database or script. The modeling tool creates a graphical representation of the selected database objects and the relationships between the objects. This graphical representation can be a logical or a physical model.
We will connect to Databricks from erwin Data modeler via partner connect:
Connection Options:
| Parameter | Description | Additional Information |
|---|---|---|
| Connection Type | Specifies the type of connection you want to use. Select Use ODBC Data Source to connect using the ODBC data source you have defined. Select Use JDBC Connection to connect using JDBC. | |
| ODBC Data Source | Specifies the data source to which you want to connect. The drop-down list displays the data sources that are defined on your computer. | This option is available only when the Connection Type is set to Use ODBC Data Source. |
| Invoke ODBC Administrator. | Specifies whether you want to start the ODBC Administrator software and display the Select Data Source dialog. You can then select a previously defined data source or create a data source. | This option is available only when the Connection Type is set to Use ODBC Data Source. |
| Connection String | Specifies the connection string based on your JDBC instance in the following format: jdbc:spark://<server-hostname>:443/default;transportMode=http;ssl=1;httpPath=<http-path> | This option is available only when the Connection Type is set to Use JDBC Connection. For example: jdbc:spark://<url>.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/<workspaceid>/xxxx |
The below screenshot shows JDBC connectivity via erwin DataModeler to the Databricks SQL Warehouse.
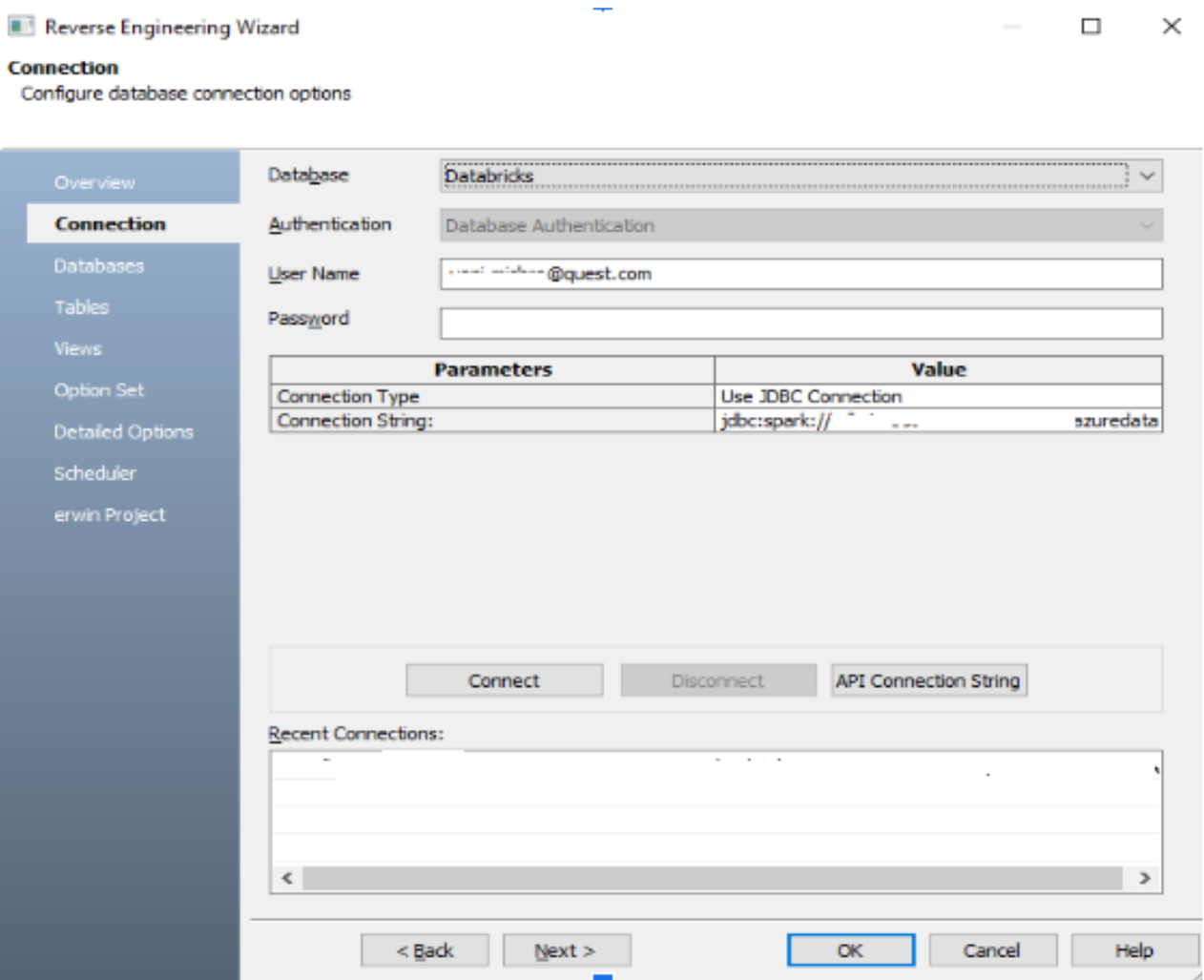
It allows us to view all of the available databases and select which database we want to build our ERD model in, as shown below.
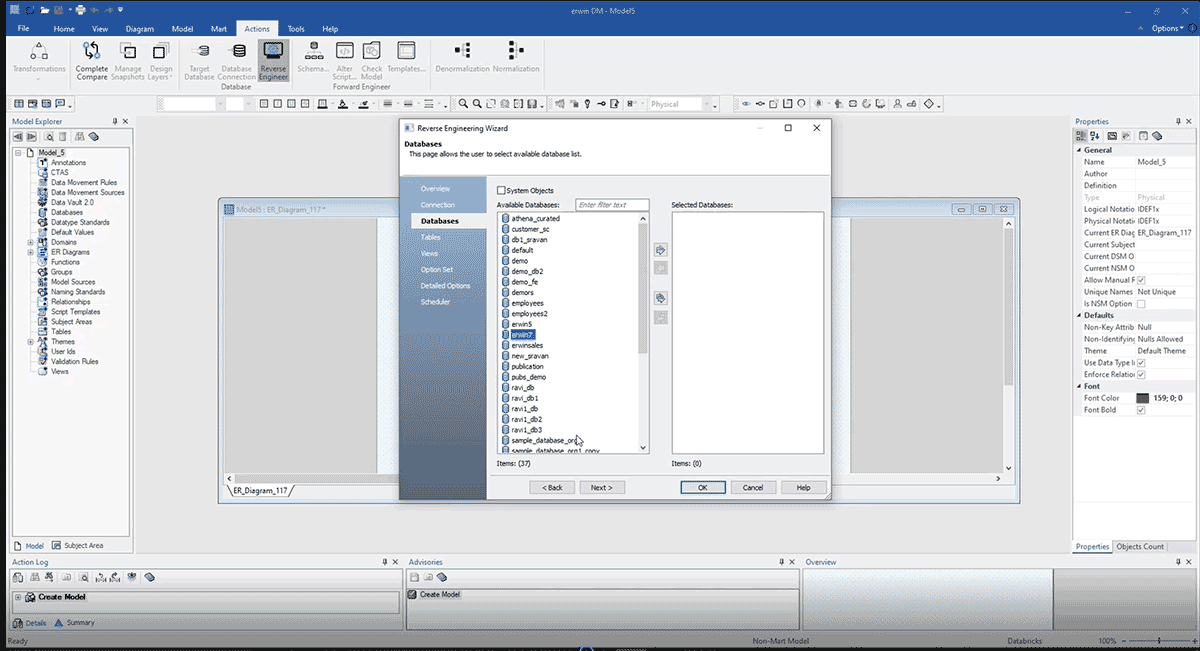
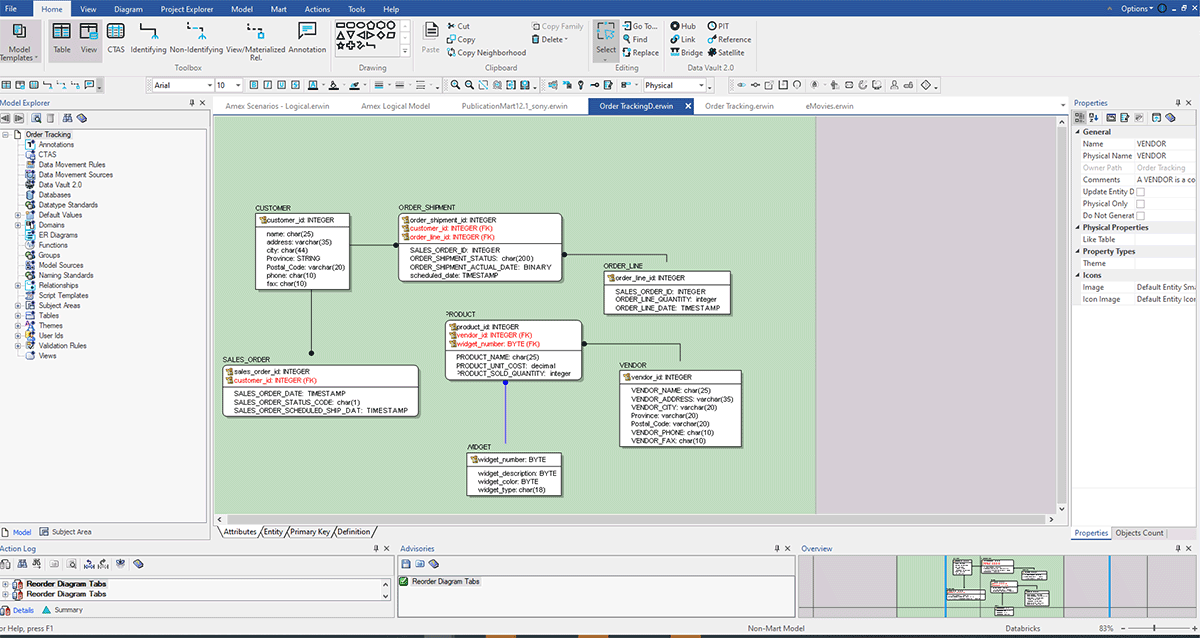
The above screenshot shows an ERD built after reverse engineering from Databricks with the above method. Here are some benefits of reverse engineering a data model:
- Improved understanding of existing systems: By reverse engineering an existing system, you can better understand how it works and how its various components interact. It helps you identify any potential issues or areas for improvement.
- Cost savings: Reverse engineering can help you identify inefficiencies in an existing system, leading to cost savings by optimizing processes or identifying areas of wasteful resources.
- Time savings: Reverse engineering can save time by allowing you to reuse existing code or data structures instead of starting from scratch.
- Better documentation: Reverse engineering can help you create accurate and up-to-date documentation for an existing system, which can be useful for maintenance and future development.
- Easier migration: Reverse engineering can help you understand the data structures and relationships in an existing system, making it easier to migrate data to a new system or database.
Overall, reverse engineering is valuable and a foundational step for data modeling. Reverse engineering enables a deeper understanding of an existing system and its components, controlled access to the enterprise design process, full transparency through modeling lifecycle, improvements in efficiency, time and cost savings, and better documentation which leads to better governance objectives.
Scenario #3: Migrate existing Data Models to Databricks.
The above scenarios assume you are working with a single data source, but most enterprises have different data marts and EDWs to support their reporting needs. Imagine your enterprise fits this description and is now embarking on creating a Databricks Lakehouse to consolidate its data platforms in the cloud in one unified platform for BI and AI. In that situation, it will be easy to utilize erwin Data Modeler to convert your existing data models from a legacy EDW to a Databricks data model. In the example below, a data model built for an EDW like SQL Server, Oracle or Teradata can now be implemented in Databricks by altering the target database to Databricks.
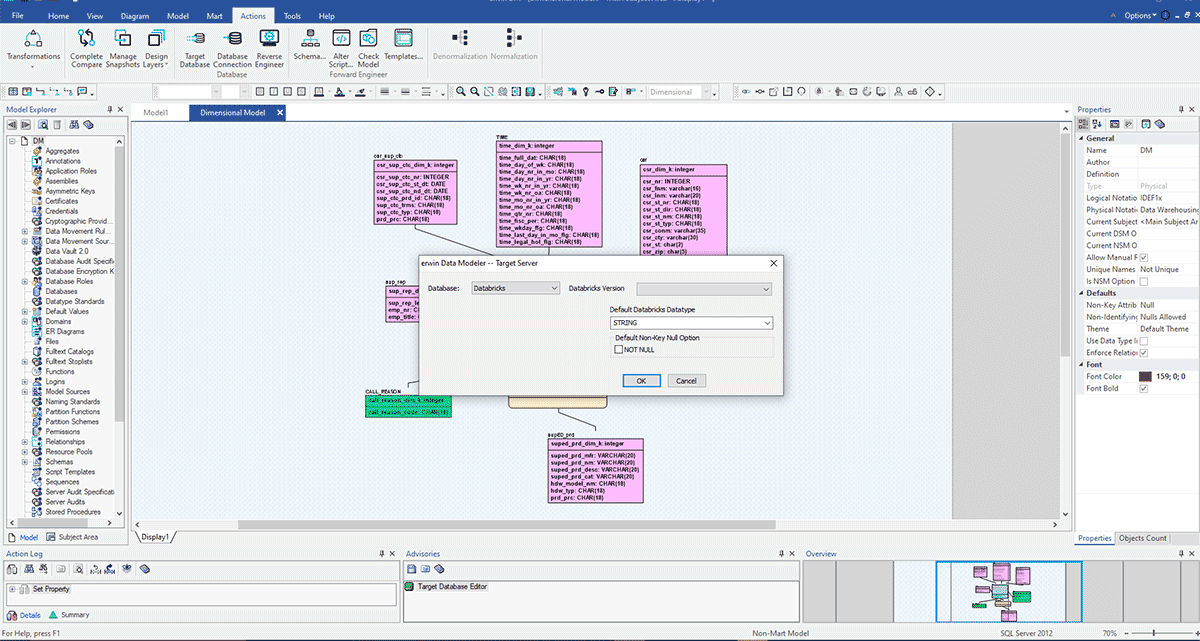
As you can see in the marked circle area, this model is built for SQL Server. Now we will convert this model and migrate its deployment to Databricks by changing the target server. This kind of easy conversion of your data models helps organizations quickly and safely migrate data models from legacy or on-prem databases to the cloud and govern those data sets throughout their lifecycle.
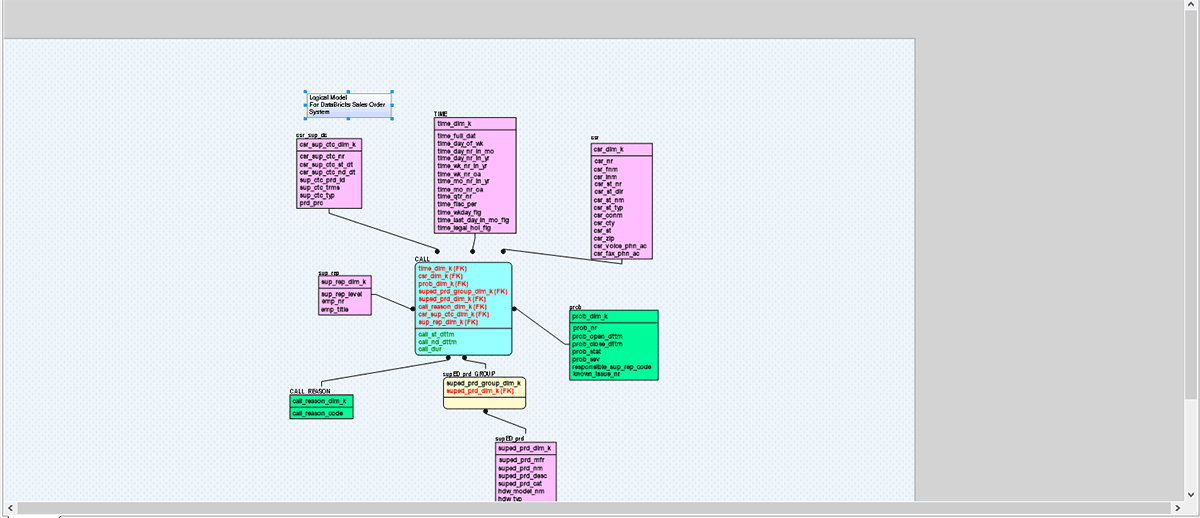
Above picture, we tried to convert a legacy SQL server-based data model to Databricks with a few simple steps. This kind of easy migration path allows and helps organizations to quickly and safely migrate their data and assets to Databricks, encourages remote collaboration, and enhances security.
Now let's move on to our final part; once ER Model is ready and approved by the data architecture team, you can quickly generate a .sql file from erwin DM or connect to Databricks and forward engineer this model to Databricks directly.
Follow the screenshots below, which explain the step-by-step process to create a DDL file or a database model for Databricks.
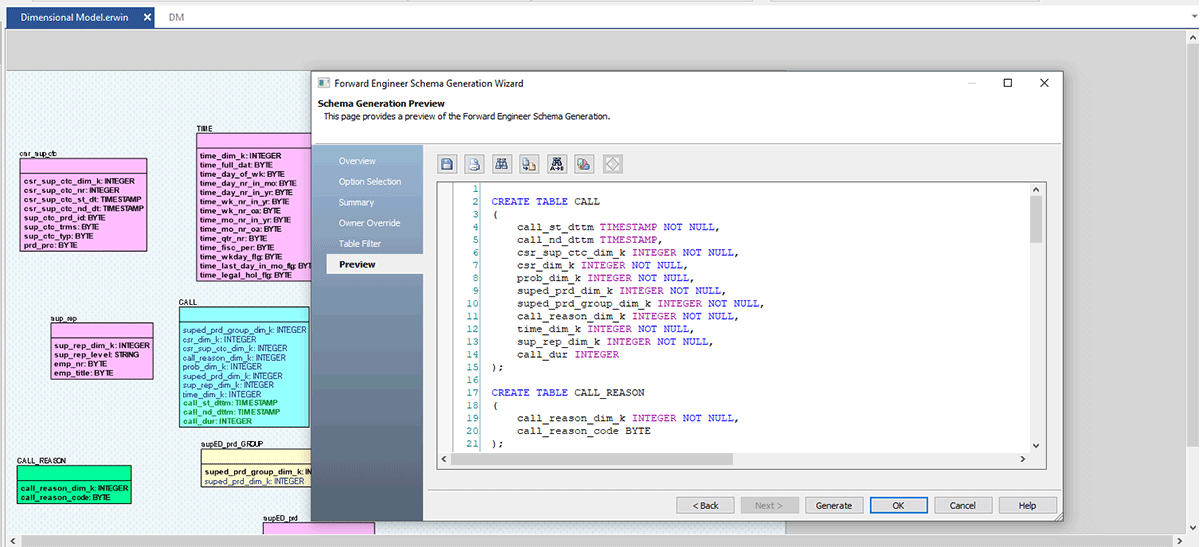
erwin Data Modeler Mart also supports GitHub. This support enables your DevOps team's requirement to control your scripts to your choice of enterprise source control repositories. Now with Git support, you can easily collaborate with developers and follow version control workflows.
Conclusion
In this blog, we demonstrated how easy it is to create, reverse engineer or forward engineer data models using erwin Data Modeler and create visual data models for migrating your table definitions to Databricks and reverse engineer data models for Data Governance and Semantic layer creation.
This kind of data modeling practice is the key element to add value to your:
- Data governance practice
- Cutting costs and achieving faster time to value for your data and metadata
- Understand and improve the business outcomes and their associated metadata
- Reduce complexities and risk
- Improve collaboration between the IT team and business stakeholders
- Better documentation
- Finally, an easy path to migrate from legacy databases to Databricks platform
Get started with using erwin from Databricks Partner Connect.
Try Databricks free for 14 days.
Try erwin Data modeler
** erwin DM 12.5 is coming with Databricks Unity Catalog support where you will be able to visualize your primary & foreign keys.