How We Performed ETL on One Billion Records For Under $1 With Delta Live Tables
Using a Dimensional Data Warehouse ETL Benchmark

Today, Databricks sets a new standard for ETL (Extract, Transform, Load) price and performance. While customers have been using Databricks for their ETL pipelines for over a decade, we have officially demonstrated best-in-class price and performance for ingesting data into an EDW (Enterprise Data Warehouse) dimensional model using conventional ETL techniques.
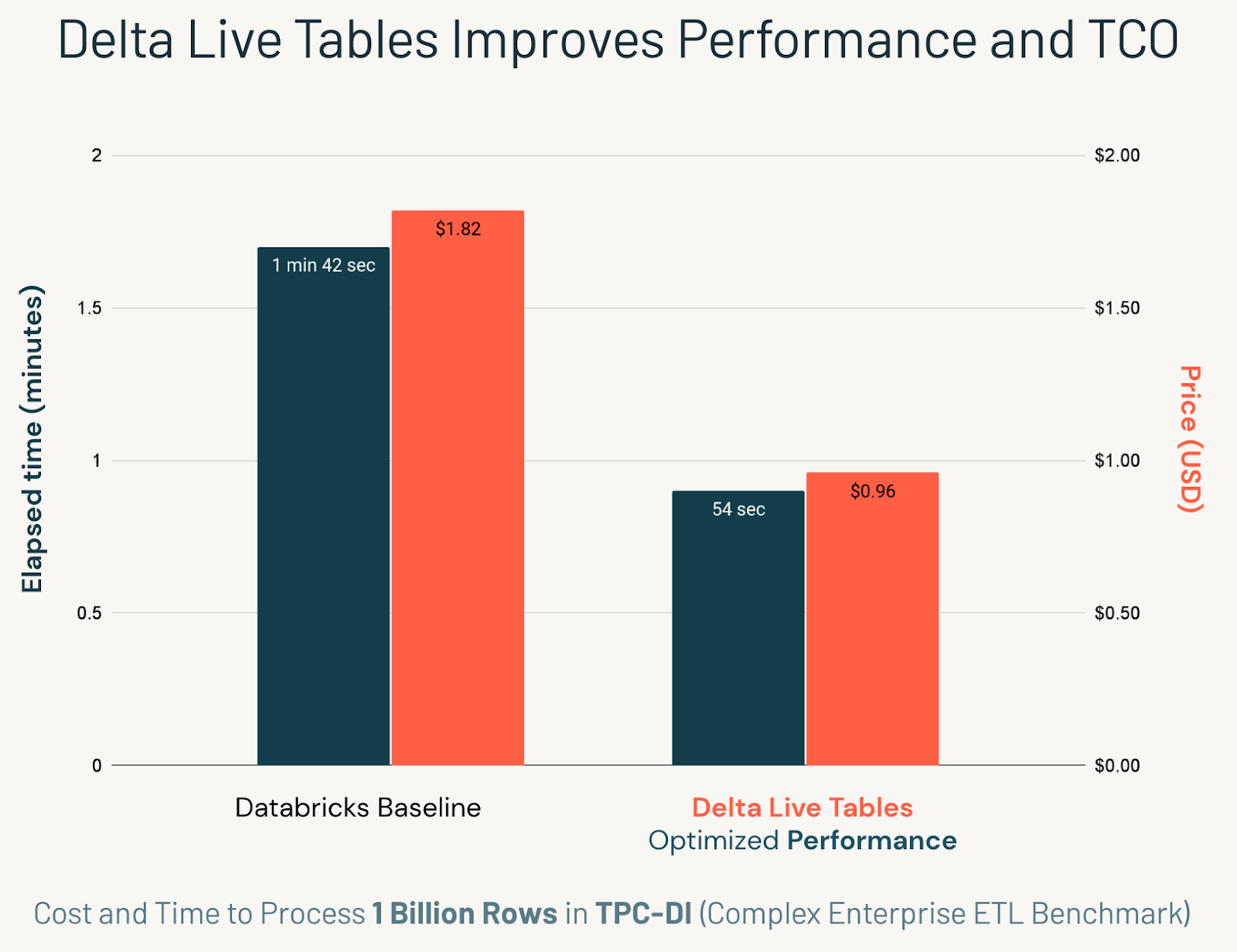
To do this, we used TPC-DI, the first industry-standard benchmark for Data Integration, or what we commonly call ETL. We illustrated that Databricks efficiently manages large-scale, complex EDW-style ETL pipelines with best-in-class performance. We also found that bringing the Delta Lake tables "to life" with Delta Live Tables (DLT) provided significant performance, cost, and simplicity improvements. Using DLT's automatic orchestration, we ingested one billion records into a dimensional data warehouse schema for less than $1 USD in total cost.
Databricks has been rapidly developing data warehousing capabilities to realize the Lakehouse vision. Many of our recent public announcements focused on groundbreaking improvements to the serving layer to provide a best-in-class experience for serving business intelligence queries. But these benchmarks do not address ETL, the other significant component of a data warehouse. For this reason, we decided to prove our record-breaking speeds with TPC-DI: the industries first, and to our knowledge only, benchmark for conventional EDW ETL.
We will now discuss what we learned from implementing the TPC-DI benchmark on DLT. Not only did DLT significantly improve cost and performance, but we also found it reduced the development complexity and allowed us to catch many data quality bugs earlier in the process. Ultimately, DLT reduced our development time compared to the non-DLT baseline, allowing us to bring the pipeline to production faster with improvements to both productivity costs and cloud costs.
If you would like to follow along with the implementation or validate the benchmark yourself, you access all of our code at this repository.
Why TPC-DI Matters
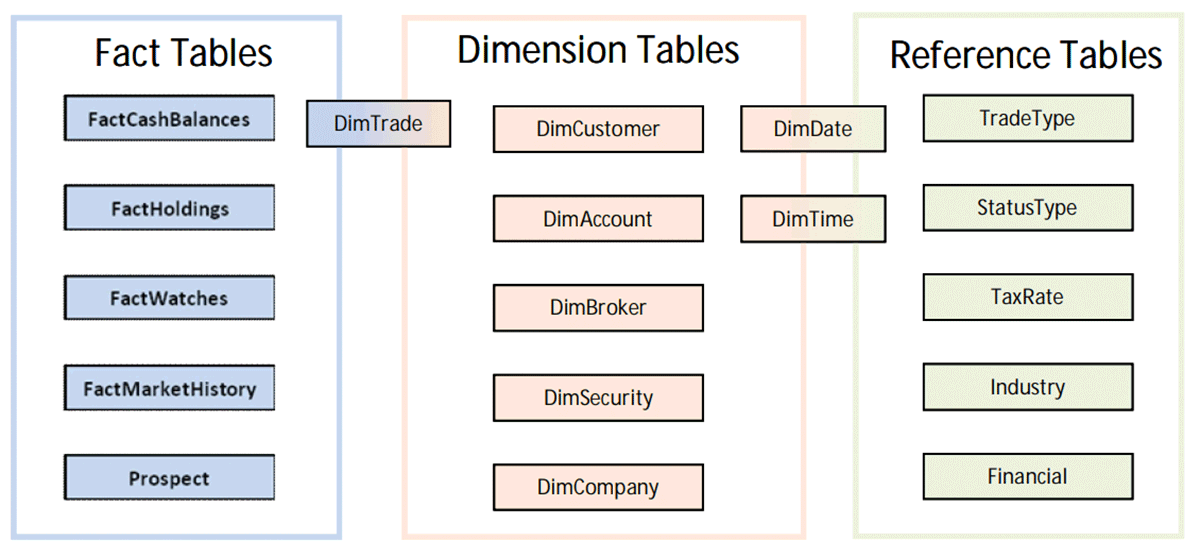
TPC-DI is the first industry-standard benchmark for typical data warehousing ETL. It thoroughly tests every operation standard to a complex dimensional schema. TPC uses a "factitious" schema, which means that even though the data is fake, the schema and data characteristics are very realistic to an actual retail brokerage firm's data warehouse, such as:
- Incrementally ingesting Change Data Capture data
- Slowly Changing Dimensions (CDC), including SCD Type II
- Ingesting different flat files, including complete data dumps, structured (CSV) and semi-structured (XML) and unstructured text
- Enriching a dimensional model (see diagram) while ensuring referential integrity
- Advanced transformations such as window calculations
- All transformations must be audit logged
- Terabyte scale data
TPC-DI doesn't only test the performance and cost of all these operations. It also requires the system to be reliable by performing consistency audits throughout the system under test. If a platform can pass TPC-DI, it can do all the ETL computations needed of an EDW. Databricks passed all audits by using Delta Lake's ACID properties and the fault-tolerance guarantees of Structured Streaming. These are the building blocks of Delta Live Tables (DLT).
How DLT Improves Cost and Management
Delta Live Tables, or DLT, is an ETL platform that dramatically simplifies the development of both batch and streaming pipelines. When developing with DLT, the user writes declarative statements in SQL or Python to perform incremental operations, including ingesting CDC data, generating SCD Type 2 output, and performing data quality guarantees on transformed data.
For the remainder of this blog, we'll discuss how we used DLT features to simplify the development of TPC-DI and how we significantly improved cost and performance compared to the non-DLT Databricks baseline.
Automatic Orchestration
TPC-DI was over 2x faster on DLT compared to the non-DLT Databricks baseline, because DLT is smarter at orchestrating tasks than humans.
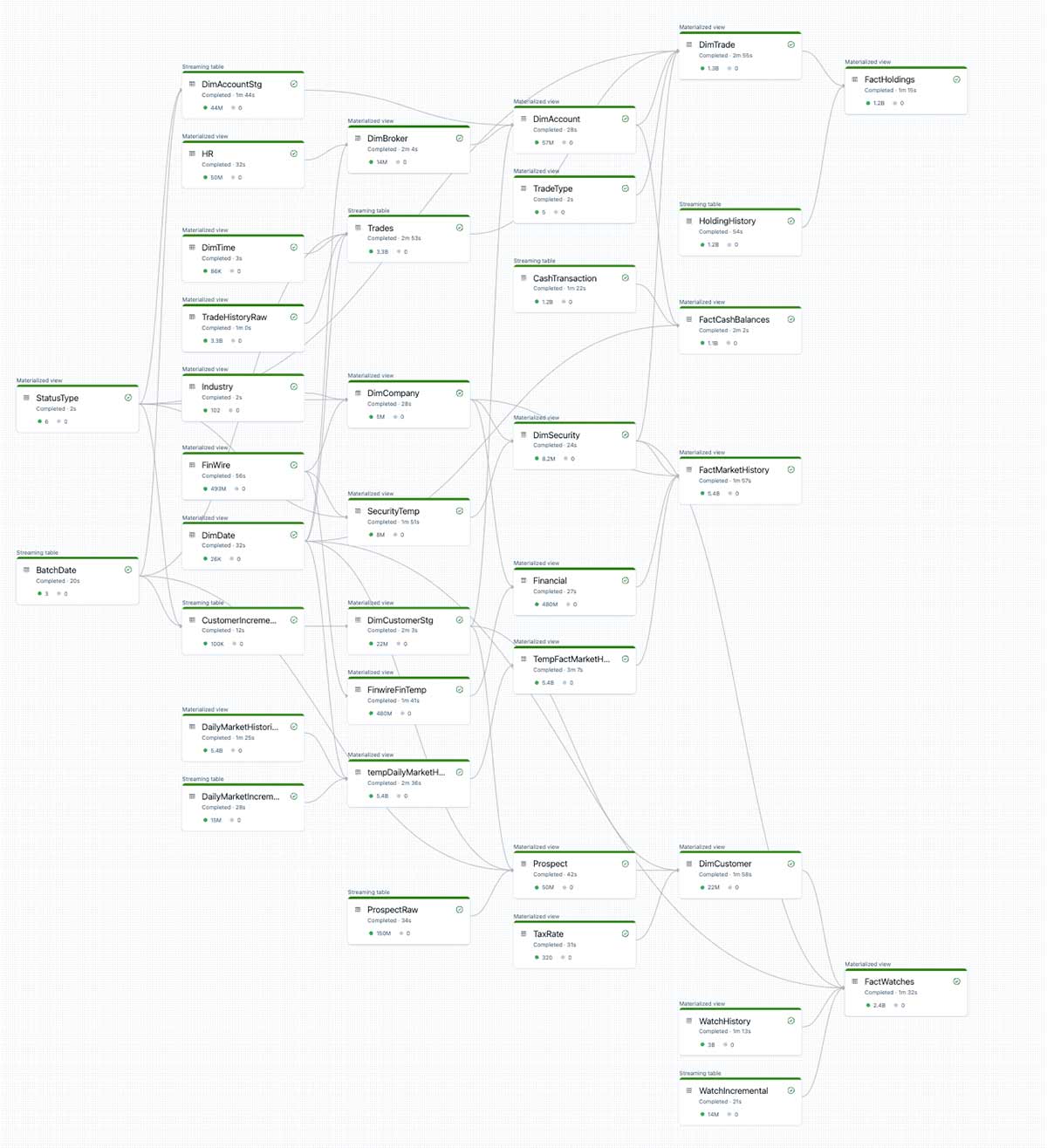
While complicated at first glance, the below DAG was auto-generated by the declarative SQL statements we used to define each layer of TPC-DI. We simply write SQL statements to follow the TPC-DI spec, and DLT handles all orchestration for us.
DLT automatically determines all table dependencies and manages them on its own. When we implemented the benchmark without DLT, we had to create this complex DAG from scratch in our orchestrator to ensure each ETL step commits in the proper order.
Gartner®: Databricks Cloud Database Leader

Not only does this automatic orchestration reduce human time spent on DAG management. Automatic orchestration also significantly improves resource management, ensuring work is parallelized flawlessly across the cluster. This efficiency is primarily responsible for the 2x speedup we observe with DLT.
The below Ganglia Monitoring screenshot shows server load distribution across the 36 worker nodes used in our TPC-DI run on DLT. It shows that DLT's automatic orchestration allowed it to parallelize work across all compute resources nearly perfectly when snapshotted at the same time during the pipeline run:

SCD Type 2
Slowly changing dimensions (SCD) are a common yet challenging aspect of many dimensional data warehouses. While batch SCD Type 1 can often be implemented with a single MERGE, performing this in streaming requires a lot of repetitive, error-prone coding. SCD Type 2 is much more complicated, even in batch, because it requires the developer to create complex, customized logic to determine the proper sequencing of out-of-order updates. Handling all SCD Type 2 edge cases in a performant manner typically requires hundreds of lines of code and may be extremely hard to tune. This "low-value heavy lifting" frequently distracts EDW teams from more valuable business logic or tuning, making it more costly to deliver data at the right time to consumers.
Delta Live Tables introduces a method, "Apply Changes," which automatically handles both SCD Type 1 and Type 2 in real-time with guaranteed fault tolerance. DLT provides this capability without additional tuning or configuration. Apply Changes dramatically reduces the time it took for us to implement and optimize SCD Type 2, one of the key requirements of the TPC-DI benchmark.
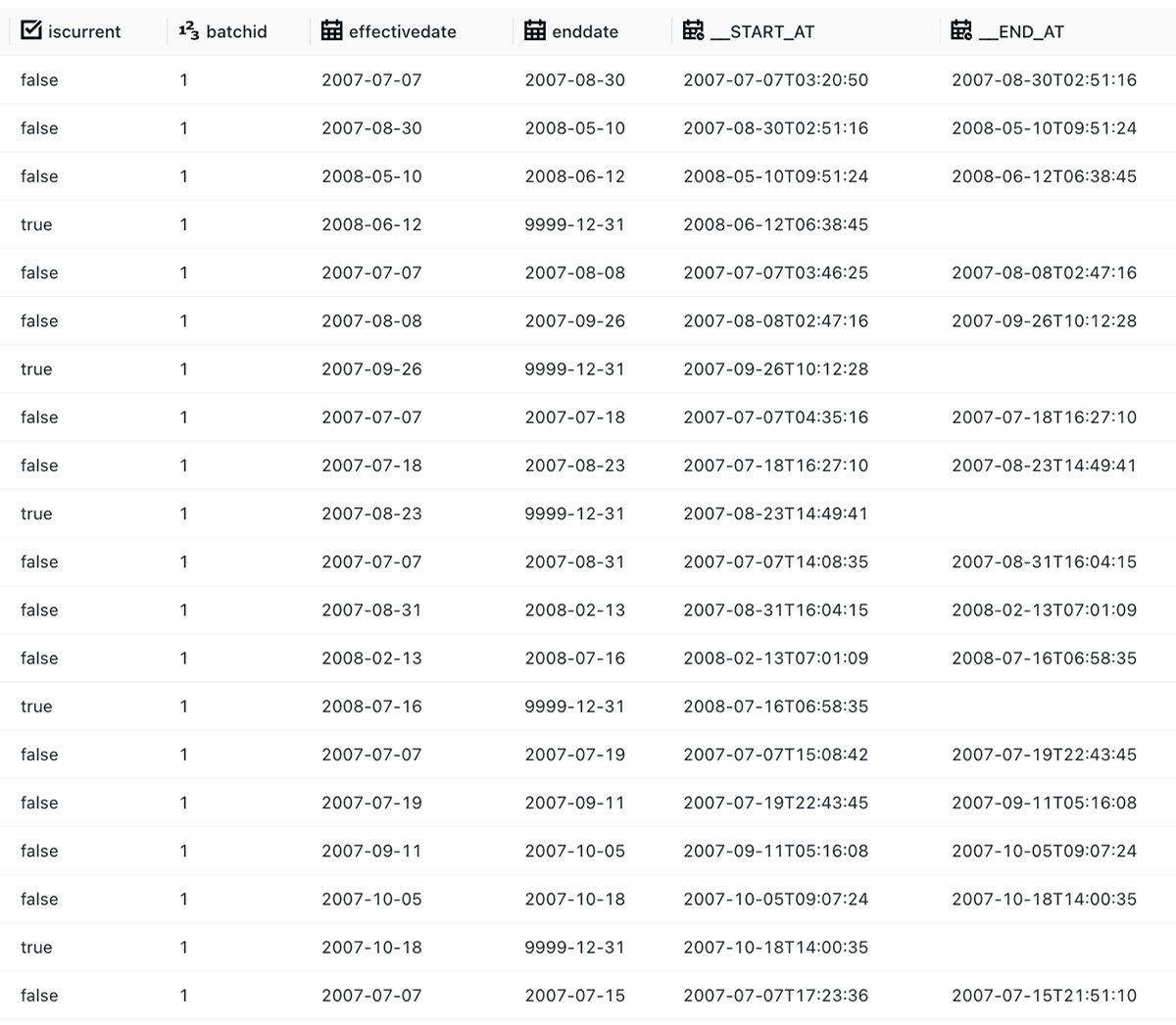
TPC-DI provides CDC Extract files with inserts, updates, and deletes. It gives a monotonically increasing sequence number we can use to resolve order, which usually would entail reasoning about challenging edge cases. Fortunately, we can use Apply Changes Into's built-in SEQUENCE BY functionality to automatically determine TPC-DI's out-of-order CDC data and ensure that the latest dimension is appropriately ordered at all times. The result of a single Apply Changes is shown below:
Data Quality
Gartner estimates that poor data quality costs organizations an average of $12.9M annually. They also predict that more than half of all data-driven organizations will focus heavily on data quality in the coming years.
As a best practice, we used DLT's Data Expectations to ensure fundamental data validity when ingesting all data into our bronze layer. In the case of TPC-DI, we created an Expectation to ensure all keys are valid:
DLT automatically provides real-time data quality metrics to accelerate debugging and improve the downstream consumer's trust in the data. When using DLT's built-in quality UI to audit TPC-DI's synthetic data, we were able to catch a bug in the TPC data generator that was causing an important surrogate key to be missing less than 0.1% of the time.
Interestingly, we never caught this bug when implementing the pipeline without DLT. Furthermore, no other TPC-DI implementation has ever noticed this bug in the eight years TPC-DI has existed! By following data quality best practices with DLT, we discovered bugs without even trying:

Without DLT Expectations, we would have allowed dangling references into the silver and gold layers, causing joins to potentially fail unnoticed until production. This normally would cost countless hours of debugging from scratch to track down corrupt records.
Conclusion
While the Databricks Lakehouse TPC-DI results are impressive, Delta Live Tables brought the tables to life through its automatic orchestration, SCD Type 2, and data quality constraints. The end result was significantly lower Total Cost of Ownership (TCO) and time to production. In addition to our TPC-DS (BI serving) results, we hope that this TPC-DI (traditional ETL) benchmark is a further testament to the Lakehouse vision, and we hope this walkthrough helps you in implementing your own ETL pipelines using DLT.
See here for a complete guide to getting started with DLT. And, for a deeper look at our tuning method used on TPC-DI, check out our recent Data + AI Summit talk, "So Fresh and So Clean."