Announcing Hybrid Search General Availability in Mosaic AI Vector Search
We're excited to announce the general availability of hybrid search in Mosaic AI Vector Search. Hybrid search is a powerful feature that combines the strengths of pre-trained embedding models with the flexibility of keyword search. In this blog post, we'll explain why hybrid search is important, how it works, and how you can use it to improve your search results.
Why Hybrid Search?
Pre-trained embedding models are a powerful way to represent unstructured data, capturing semantic meaning in a compressed and easily searchable format. However it was trained using external data and doesn’t have explicit knowledge of your data. Hybrid search adds a learned keyword search index on top of your vector search index. The keyword search index is trained on your data, and thus has knowledge of the names, product keys, and other identifiers that are important for your retrieval situation.
When to Choose Hybrid Search
Hybrid search can perform better when there are critical keywords in your dataset that would not be present in publicly available embedding model training datasets. For example, if the question refers to specific product codes or other terms that you want to match exactly, hybrid search may be the better choice. We encourage you to try both options to see what works best for your problem set.
Using Hybrid Search in Mosaic AI Vector Search
It is easy to get started with hybrid search. All indices have access to hybrid search now with no additional setup required.
The keyword index is trained on all text fields in your corpus, so it automatically has access to both the text chunk as well as all text metadata fields.
For fully-managed Delta Sync indices you can simply add `query_type=’hybrid’` to your similarity search queries. This also works for Direct Vector Access indices with a model serving endpoint attached.
For self-managed Delta Sync indices and Direct Vector Access indices without a model serving endpoint attach, you will need to make sure both `query_vector` and `query_text` are specified.
Quality Improvements
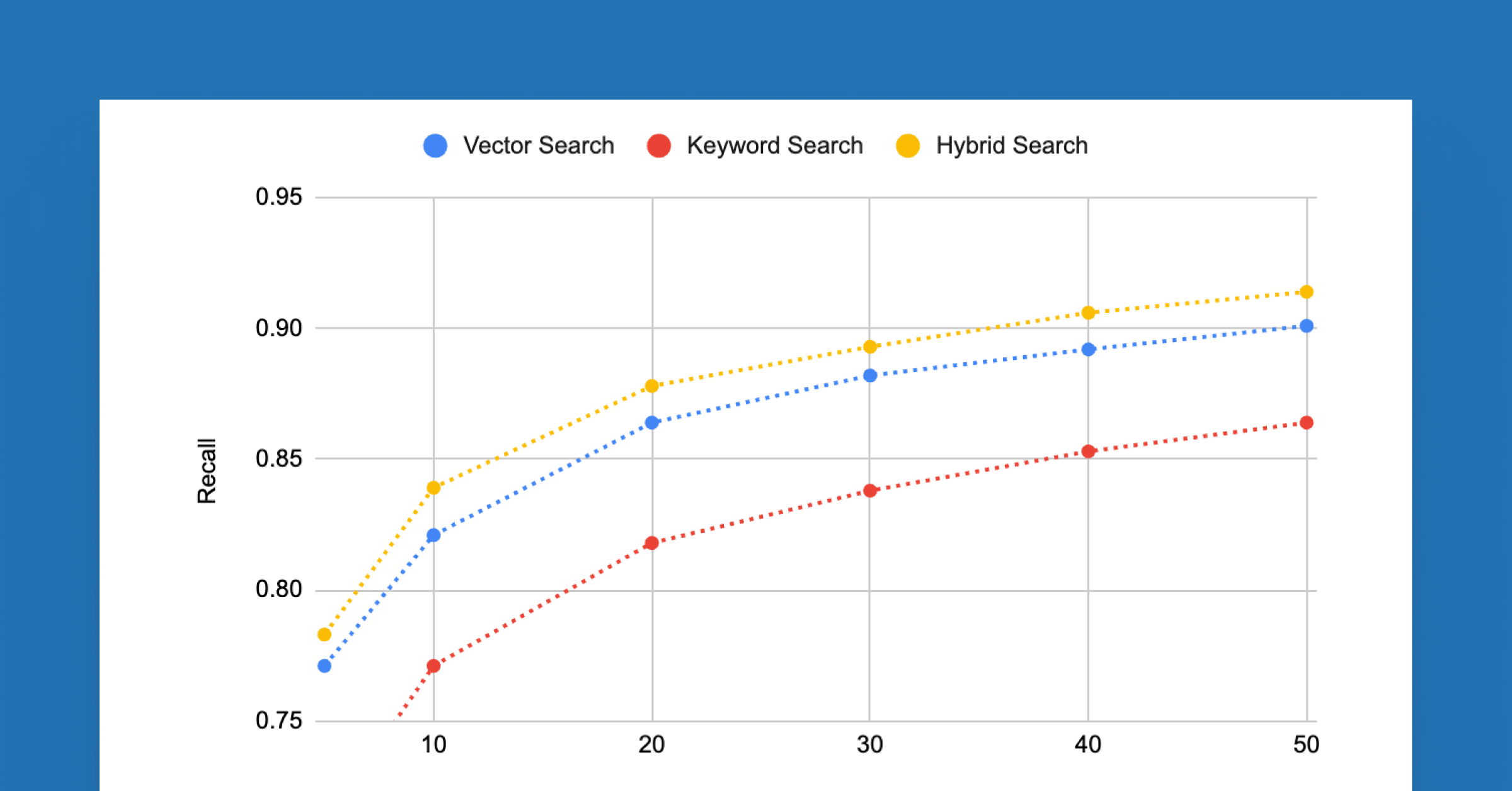
In Retrieval-Augmented Generator (RAG) applications, one critical metric is recall, the fraction of time we retrieve the chunk containing the answer to the input query in the top `num_results` retrieved chunks. We see that hybrid search is able to improve recall, and thus reduce the number of chunks needed to be processed by the LLM to answer the user’s question.
On an internal dataset designed to represent the types of datasets we see from our customers, we see significant improvements in recall. In particular, the number of documents needed to achieve a recall of 0.9 is 50 for pure dense retrieval and 40 for hybrid search, a 20% improvement. This reduces the latency and processing cost for RAG applications.
We include a plot below of recall at various values of the number of results retrieved. We see that hybrid search does as good or better than pure dense retrieval on all choices for the number of retrieved results.

Method Used
Our implementation of hybrid search is based on Rank Reciprocal Fusion (RRF) of the vector search and keyword search results. The parameters of RRF are tuned to values that should return high quality results for most datasets.
Scores are normalized so the highest score possible is 1.0. This makes it easy to identify when documents are believed to be high value by both the vector searcher and keyword searcher. Scores close to 1.0 mean that both retrievers found the document to be of high relevance. Scores close to 0.5 and below mean one or both of the retrievers believe the document has low relevance.
Next Steps
Get started today with hybrid search! For fully-managed Delta Sync (DSYNC) indices and direct vector access indices with a model serving endpoint:
For self-managed DSYNC indices and direct vector access indices without a model serving endpoint:
Note that the keyword index automatically uses all text fields in your index, so these need to be provided when constructing the index.
For more information, see our documentation on Hybrid Search:
Never miss a Databricks post
What's next?

Data Science and ML
June 12, 2024/8 min read
Mosaic AI: Build and Deploy Production-quality AI Agent Systems

Data Science and ML
October 1, 2024/5 min read