Announcing the Public Preview of Predictive I/O for Updates
Up to 10x Performance Gains for MERGE, UPDATE, and DELETE

Previously, we’ve shown you how a new technology called Predictive I/O could improve selective reads by up to 35x for CDW customers without any knobs. Today, we are excited to announce the public preview of another innovative leap, Predictive I/O for Updates, providing you with up to 10x faster MERGE, UPDATE, and DELETE query performance.
Databricks customers process over 1 exabyte of data daily, with more than 50% of tables utilizing Data Manipulation Language (DML) operations like MERGE, UPDATE, and DELETE. In this blog, we explain how Predictive I/O achieved this massive performance improvement using machine learning. But, if you want to skip to the good part and opt-in your tables to Predictive I/O for Updates, refer to our documentation.
Challenges with updating data lakes
Today, when users run a MERGE, UPDATE, or DELETE operation in the Lakehouse, the queries are processed by the query engine in the following manner:
- Find the files that contain the rows needing modification.
- Copy and rewrite all unmodified rows to a new file while filtering out deleted rows and adding updated ones.
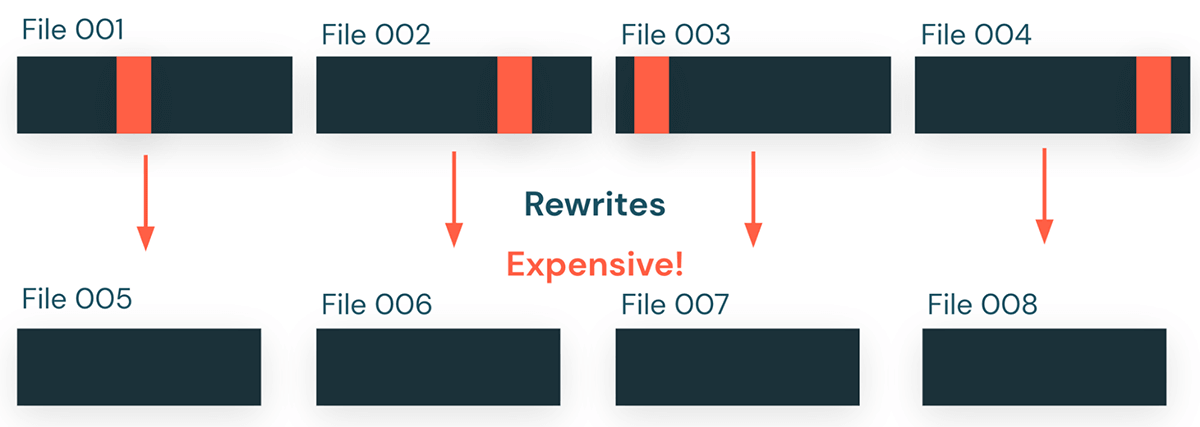
This process, especially the rewrite step, can get particularly expensive when operations make small updates distributed across many files in the table. For example, a single product ID gets updated across an entire orders table. In the illustrated example below, a table is stored as four files with a million rows each, and a user runs an UPDATE query against this table, only updating a single row in each file. Without Predictive I/O, the update query rewrites all four files, copying all four million unmodified rows to a new file to update four rows in the table. This unnecessary rewriting of old data can become expensive and slow for medium to large tables.
Introducing Predictive I/O for Updates
To address these challenges, we are introducing Predictive I/O for Updates.
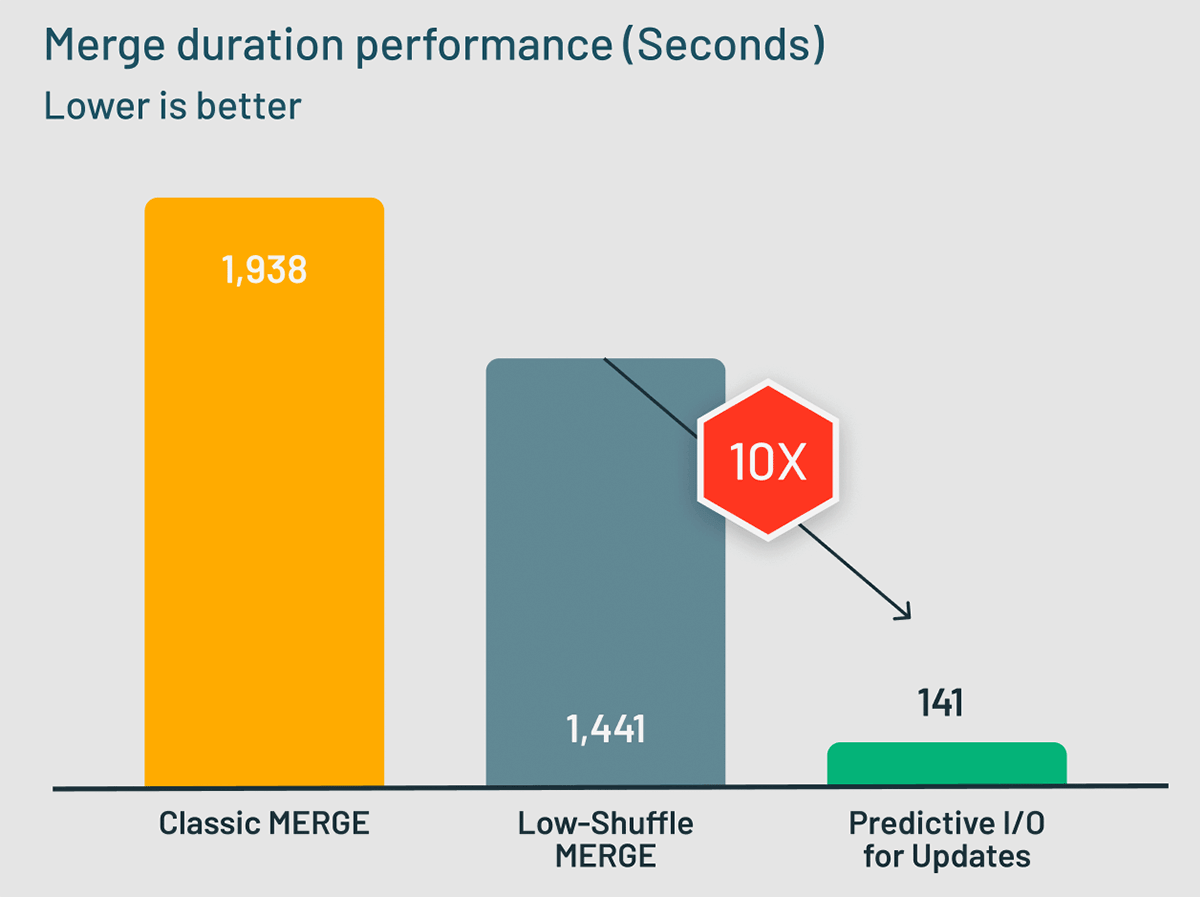
Last year, we announced Low-Shuffle MERGE, a Photon feature that speeds up typical MERGE workloads by 1.5x. Low-Shuffle MERGE is enabled by default for all MERGEs in Databricks Runtime 10.4+ and Databricks SQL. Now let's see how Predictive I/O for Updates stacks up against Low-Shuffle MERGE. Using a MERGE UPSERT workload that updates a 3 TB TPC-DS dataset, we measured the classic Photon MERGE implementation, Low-Shuffle MERGE, and Predictive I/O for Updates in a benchmark. The results were amazing! Predictive I/O for Updates took just over 141 seconds to complete the MERGE workload, 10x faster than Low-Shuffle MERGE, which took over 1441 seconds to complete the same operation.
That's amazing! How does Predictive I/O for Updates work?
Predictive I/O for Updates makes use of Deletion Vectors to track deleted rows using compressed bitmap files. Tracking deleted files, rather than removing them on write, adds some overhead when reading the table, as attaining an accurate table representation requires filtering deleted rows at read time. This is where Predictive I/O's intelligence comes into play. Predictive I/O uses various forms of learning and heuristics to intelligently apply Deletion Vectors as needed to your MERGE, UPDATE, and DELETE queries to minimize read overhead while optimizing write performance. This intelligence, paired with the optimized nature of Deletion Vector files gives you the best write performance without any compromises on read query performance.
Getting Started with Predictive I/O for Updates
Are your ETL pipelines or CDC ingestion jobs taking a long time to execute? Do you have updates spread across your data? Predictive I/O can now significantly speed up those MERGE, UPDATE, and DELETE queries and is available today in public preview for Databricks SQL Pro and Serverless!
We want your feedback as part of this public preview. Check out the Predictive I/O for Updates documentation to learn how to speed up your MERGE, UPDATE, and DELETE queries.
Never miss a Databricks post
What's next?

Data Warehousing
July 24, 2024/7 min read
Primary Key and Foreign Key constraints are GA and now enable faster queries

Product
September 12, 2024/7 min read