Announcing Public Preview of Volumes in Databricks Unity Catalog
Discover, govern, and query any non-tabular data

At the Data and AI Summit 2023, we introduced Volumes in Databricks Unity Catalog. This feature enables users to discover, govern, process, and track lineage for any non-tabular data, including unstructured, semi-structured, and structured data, along with the tabular data in Unity Catalog. Today we are excited to announce the public preview of Volumes, which is available on AWS, Azure, and GCP.
In this blog, we discuss common use cases related to non-tabular data, provide an overview of the key capabilities with Volumes in Unity Catalog, showcase a working example demonstrating a practical application of Volumes, and provide details on how to get started with Volumes.
Common uses cases associated with the governance and access to non-tabular data
Databricks Lakehouse Platform can store and process large amounts of data in a variety of formats. While much of this data is governed through tables, there are many use cases, particularly for machine learning and data science workloads, which require access to non-tabular data, such as text, image, audio, video, PDF, or XML files.
Common use cases we have heard from our customers include but are not limited to:
- Running machine learning on large collections of unstructured data such as image, audio, video, or PDF files.
- Persisting and sharing training, test, and validation data sets used for model training and defining locations for operational data such as logging and checkpointing directories.
- Uploading and querying non-tabular data files in data exploration stages in data science.
- Working with tools that don't natively support Cloud object storage APIs and instead expect files in the local file system on cluster machines.
- Storing and providing secure access across workspaces to libraries, certificates, and other configuration files of arbitrary formats, such as .whl or .txt, before they are used to configure cluster libraries, notebook-scoped libraries, or job dependencies.
- Staging and pre-processing raw data files in the early stages of an ingestion pipeline before they are loaded into tables, e.g., using Auto Loader or COPY INTO.
- Sharing large collections of files with other users within or across workspaces, regions, clouds, and data platforms.
With Volumes, you can build scalable file-based applications that read and process large collections of non-tabular data irrespective of its format at Cloud-storage performance.
What are Volumes, and how can you use them?
Volumes are a new type of object that catalog collections of directories and files in Unity Catalog. A Volume represents a logical volume of storage in a Cloud object storage location and provides capabilities for accessing, storing, and managing data in any format, including structured, semi-structured, and unstructured data. This enables you to govern, manage and track lineage for non-tabular data along with the tabular data and models in Unity Catalog, providing a unified discovery and governance experience.
Running image classification on an image dataset stored in a Volume
To gain a better understanding of Volumes and their practical applications, let's explore an example. Suppose we want to utilize machine learning (ML) for image classification using a dataset consisting of cat and dog images. Our first step is to download these images onto our local machine. Our objective is to incorporate these images into Databricks for data science purposes.
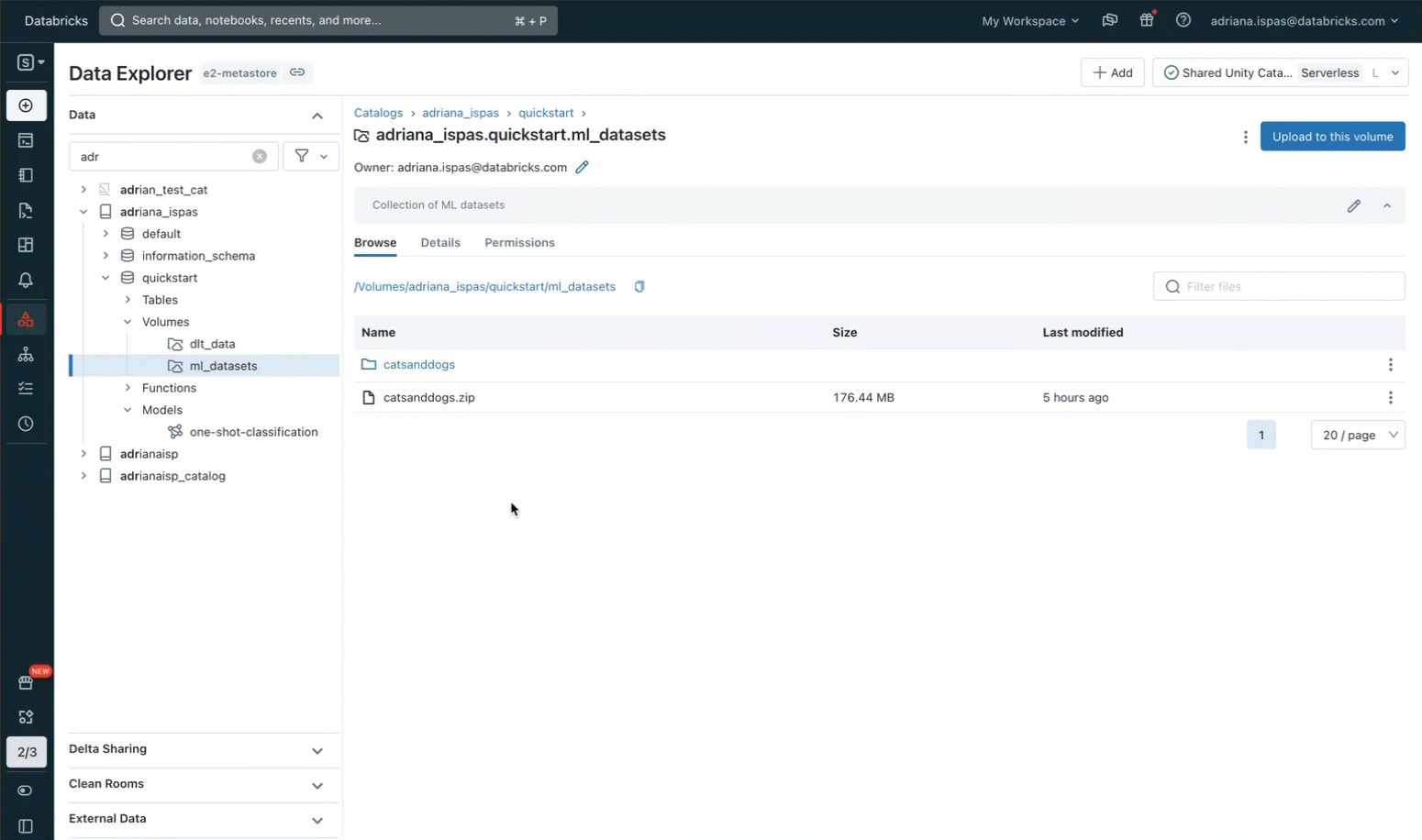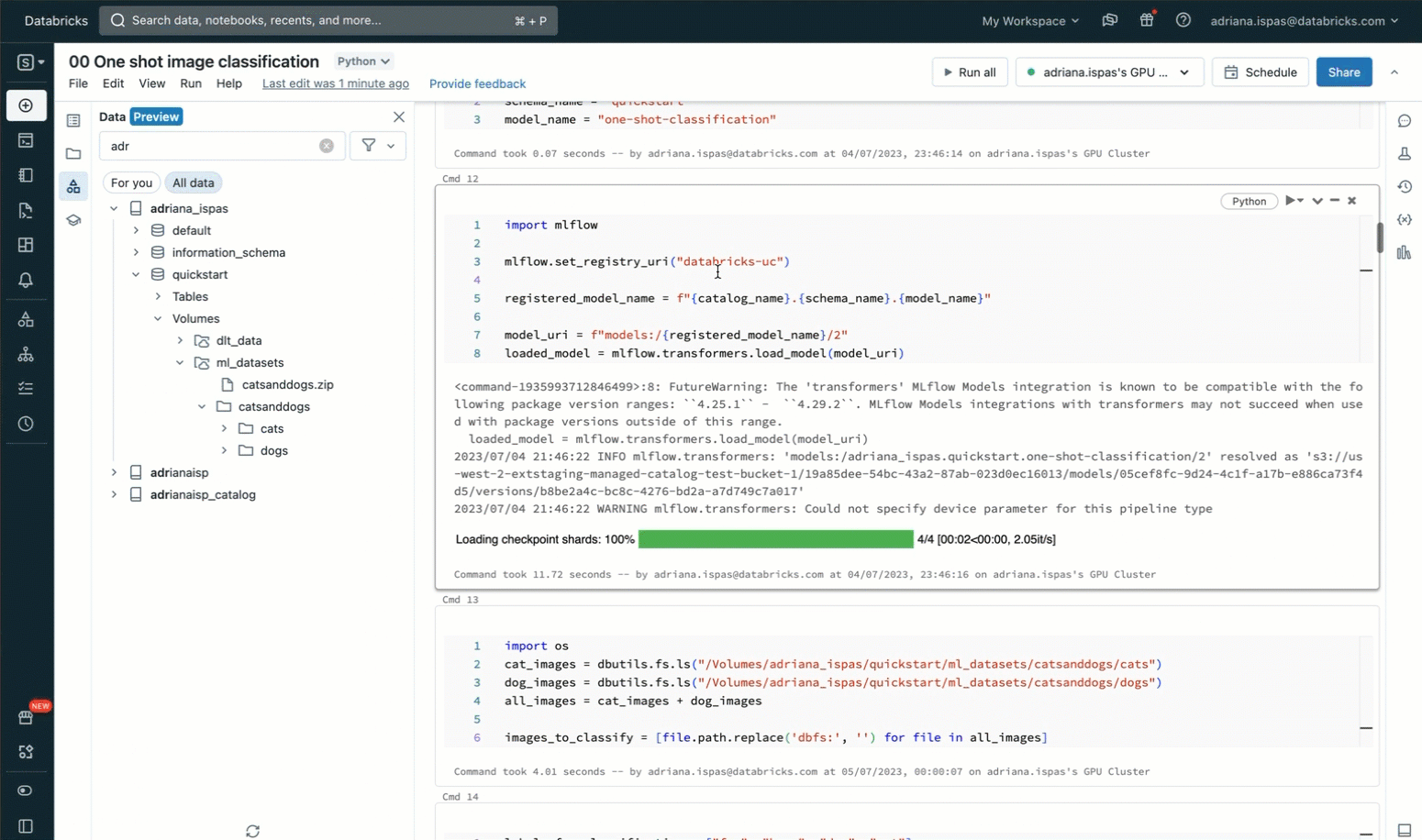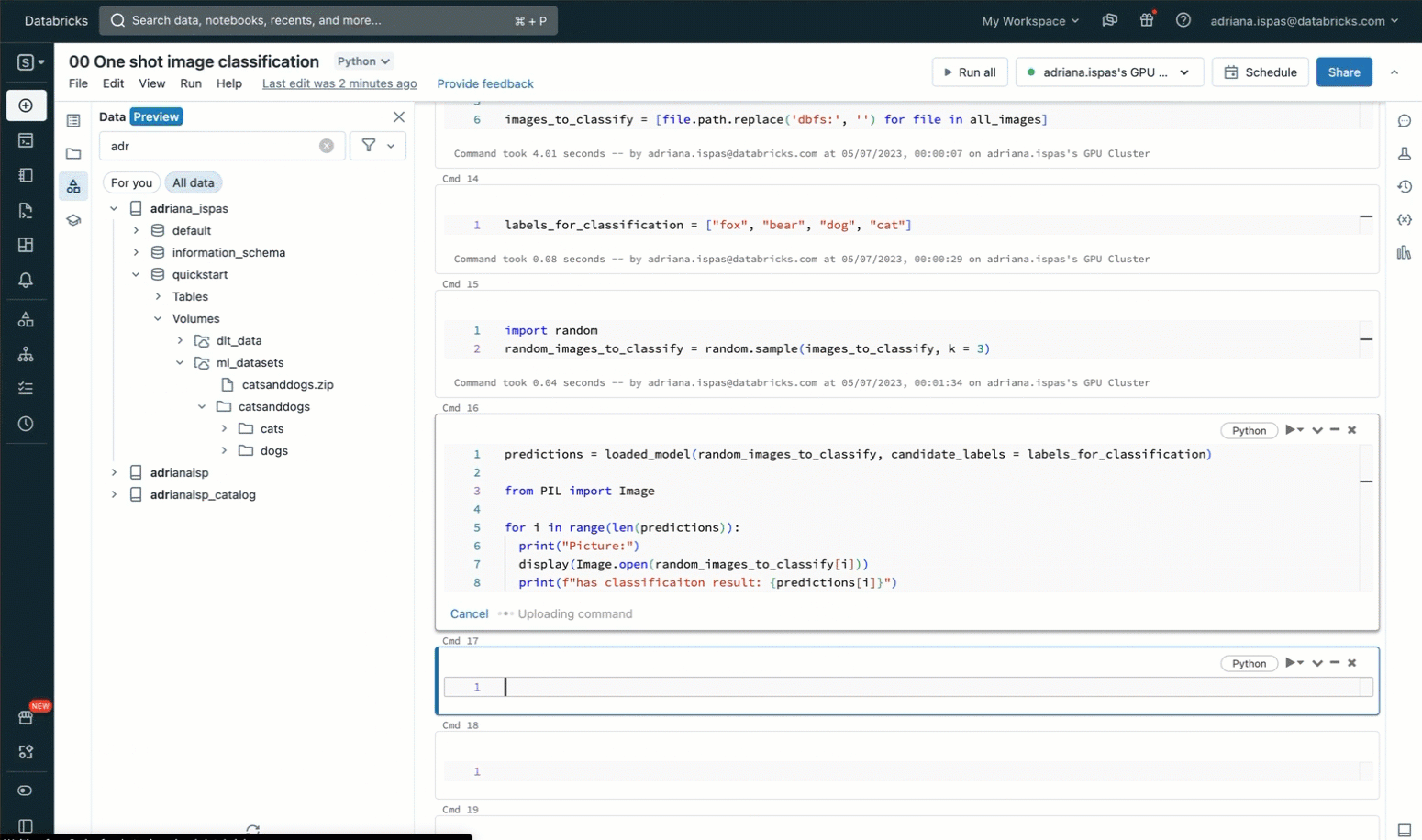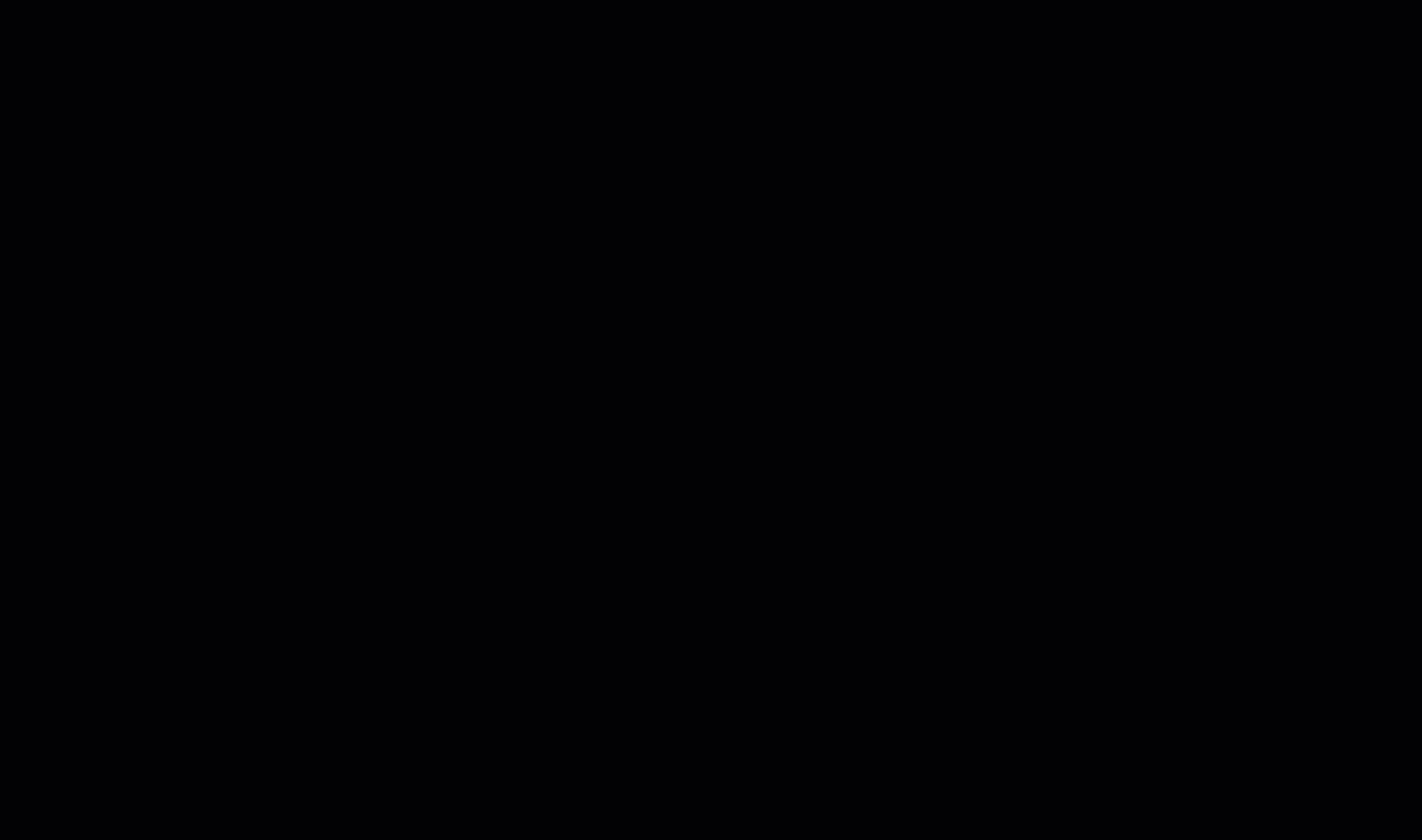
To accomplish this, we'll leverage the Data Explorer user interface. We'll create a new Volume within a Unity Catalog schema, with us being the owner. Afterward, we'll grant access permissions to our collaborators and upload an archive containing the image files. It's important to note that we also have the option to upload the files to an existing Volume where we have write permissions. Alternatively, we can create our own Volume and manage its permissions using SQL commands within a notebook or the SQL editor.
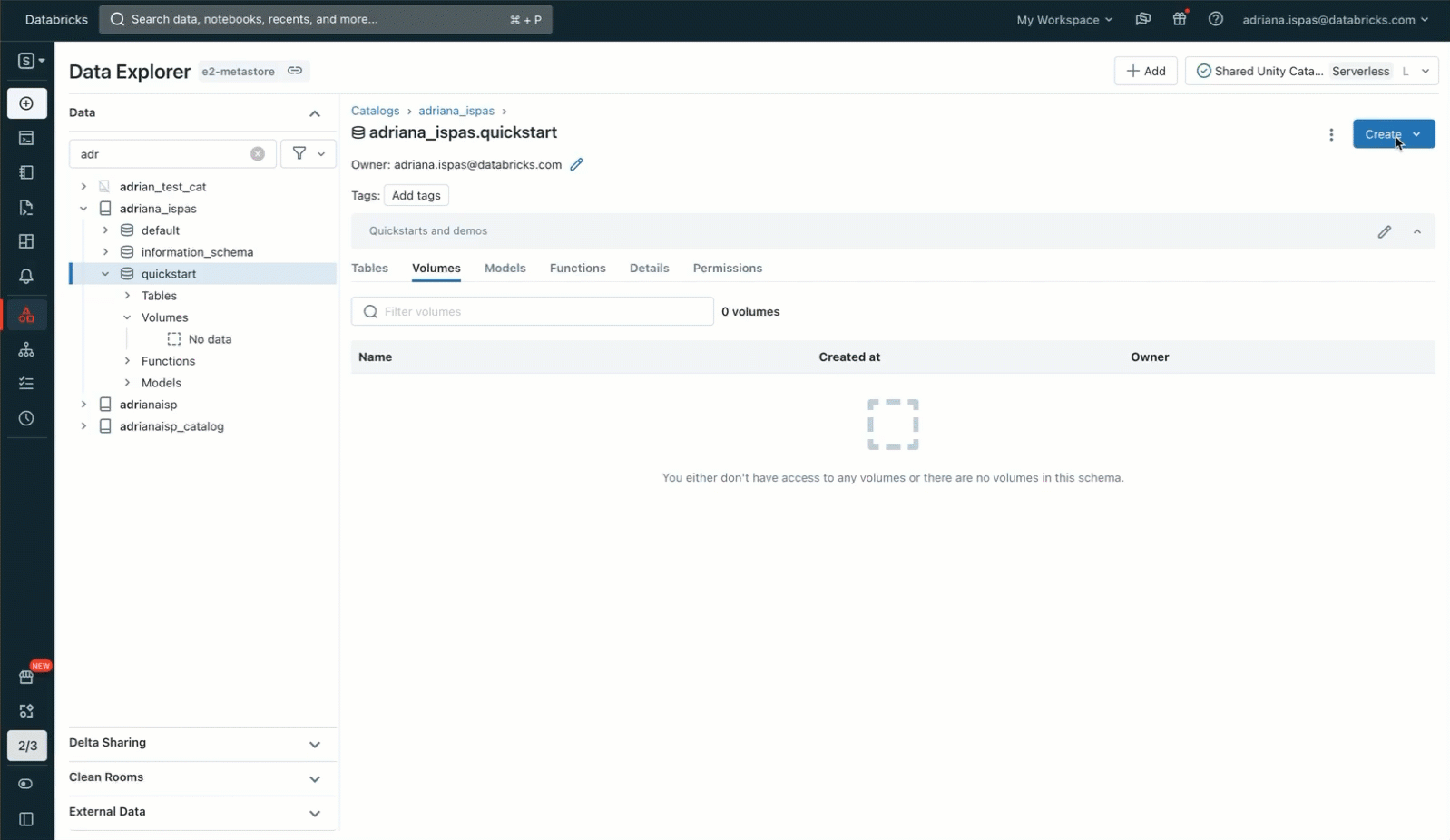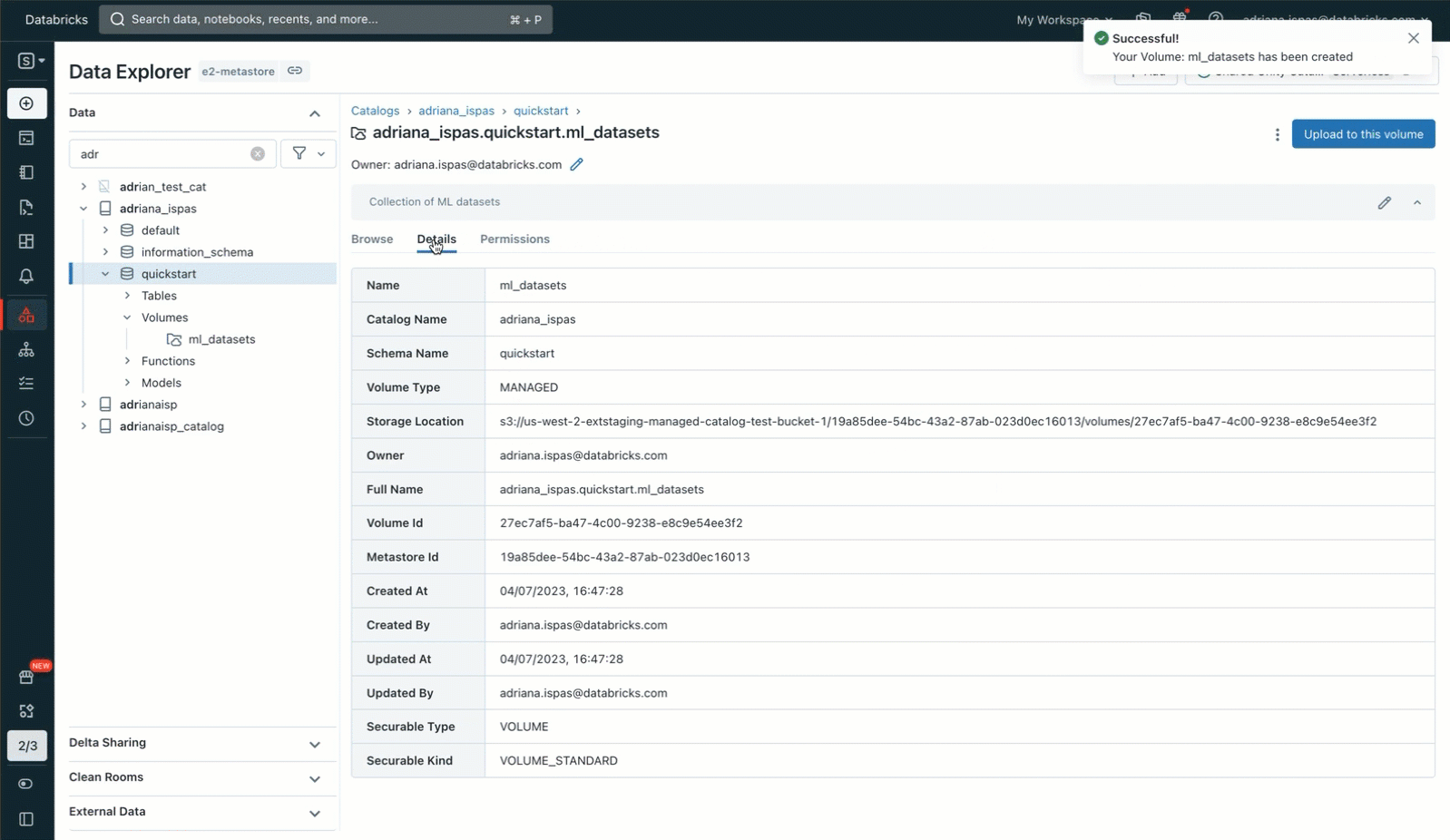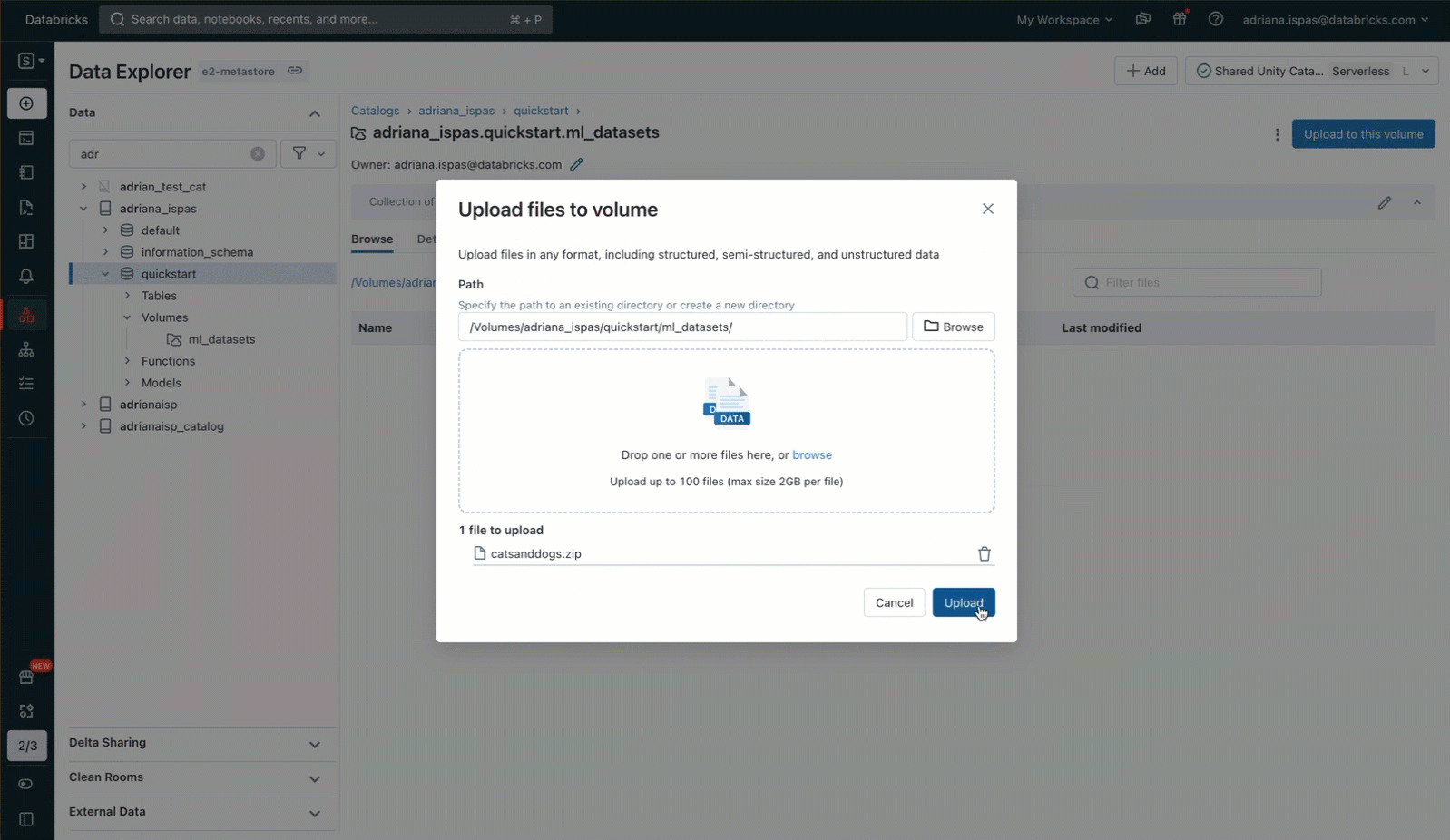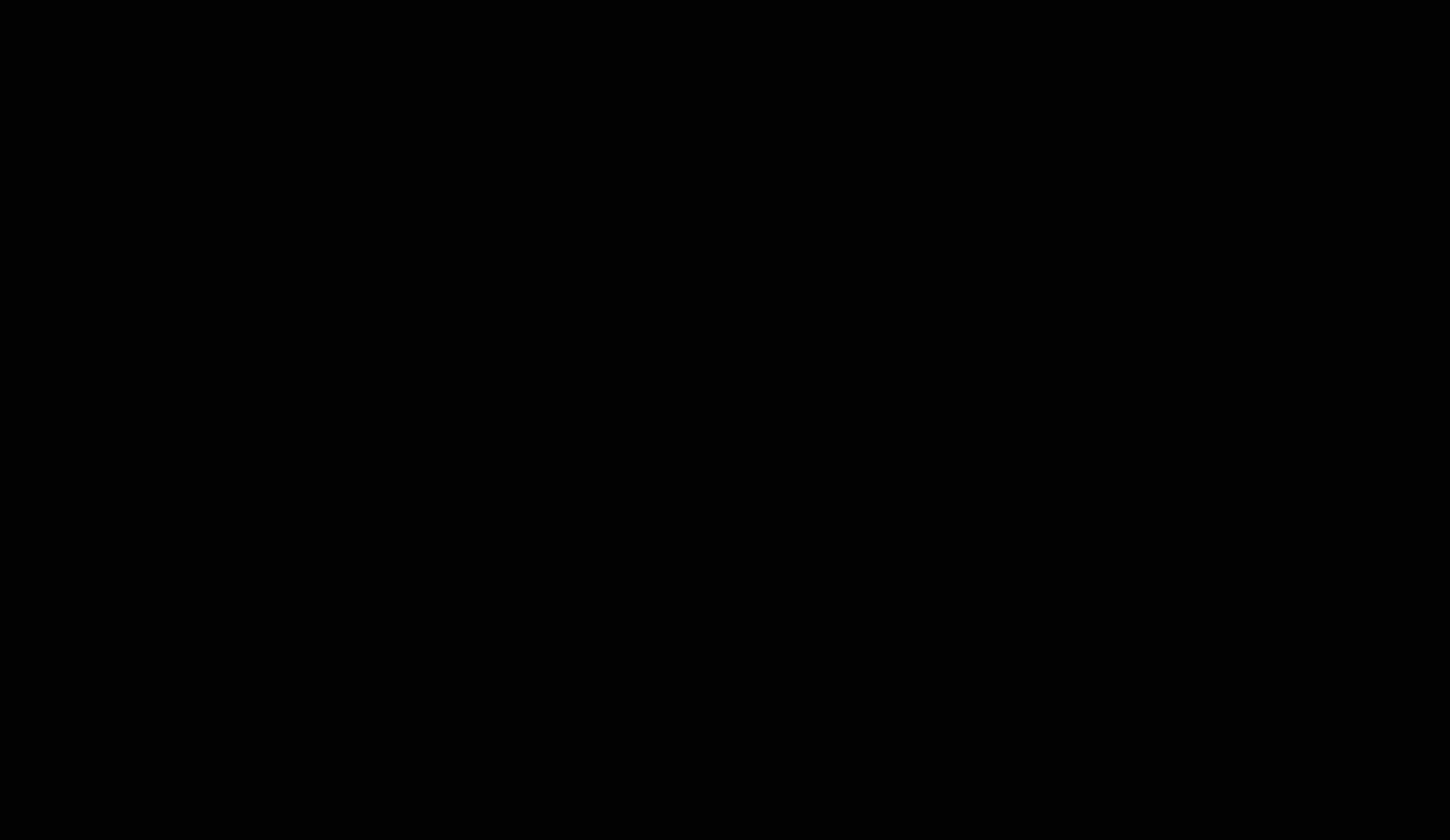
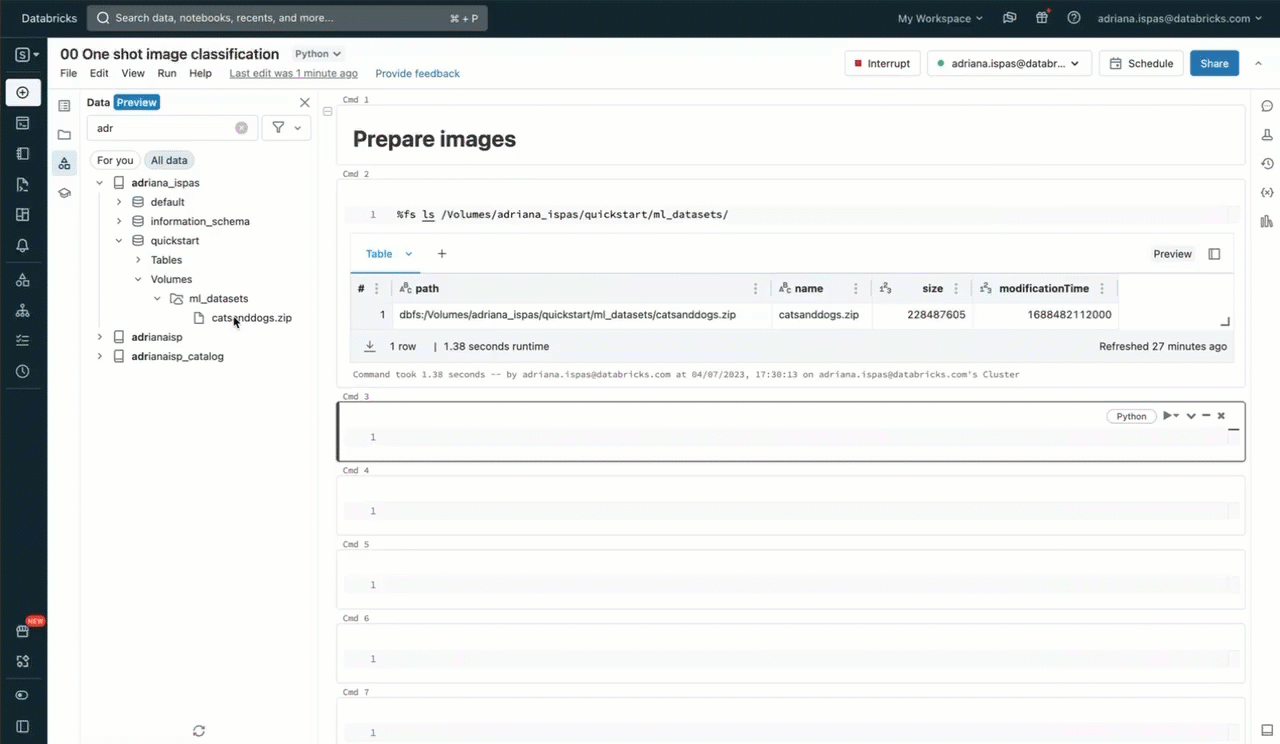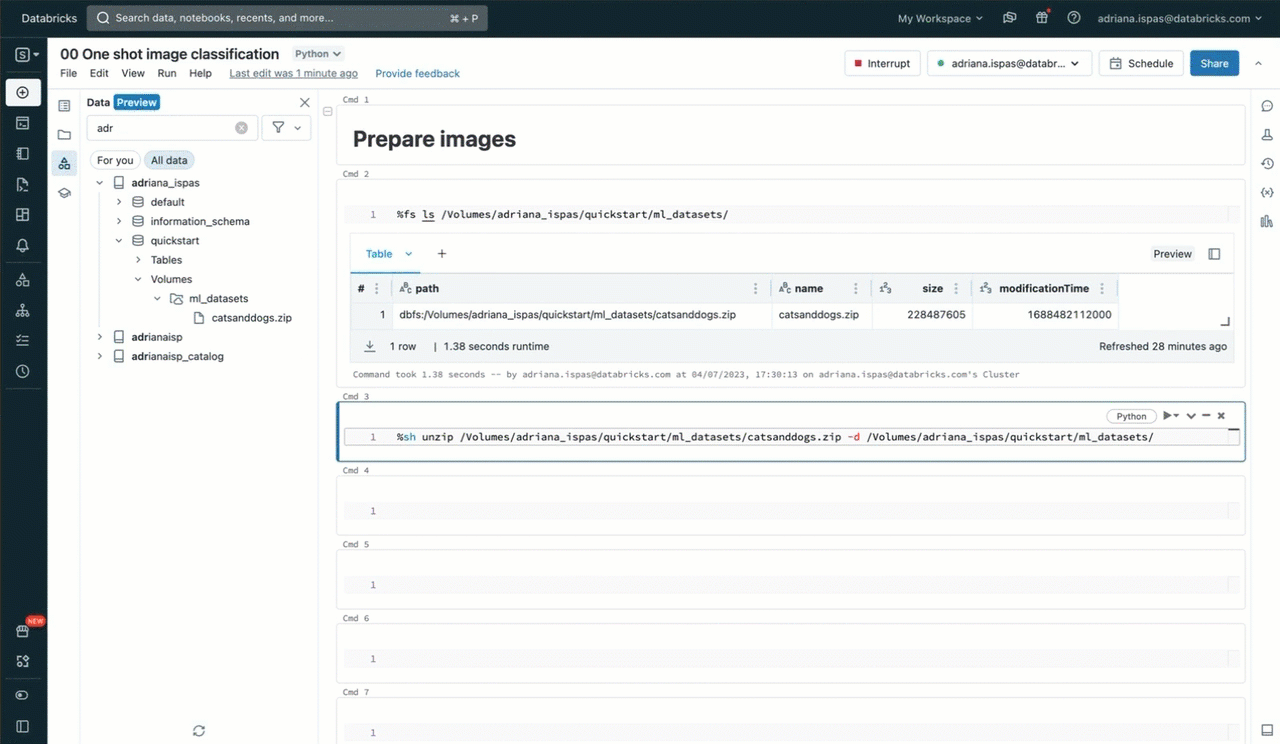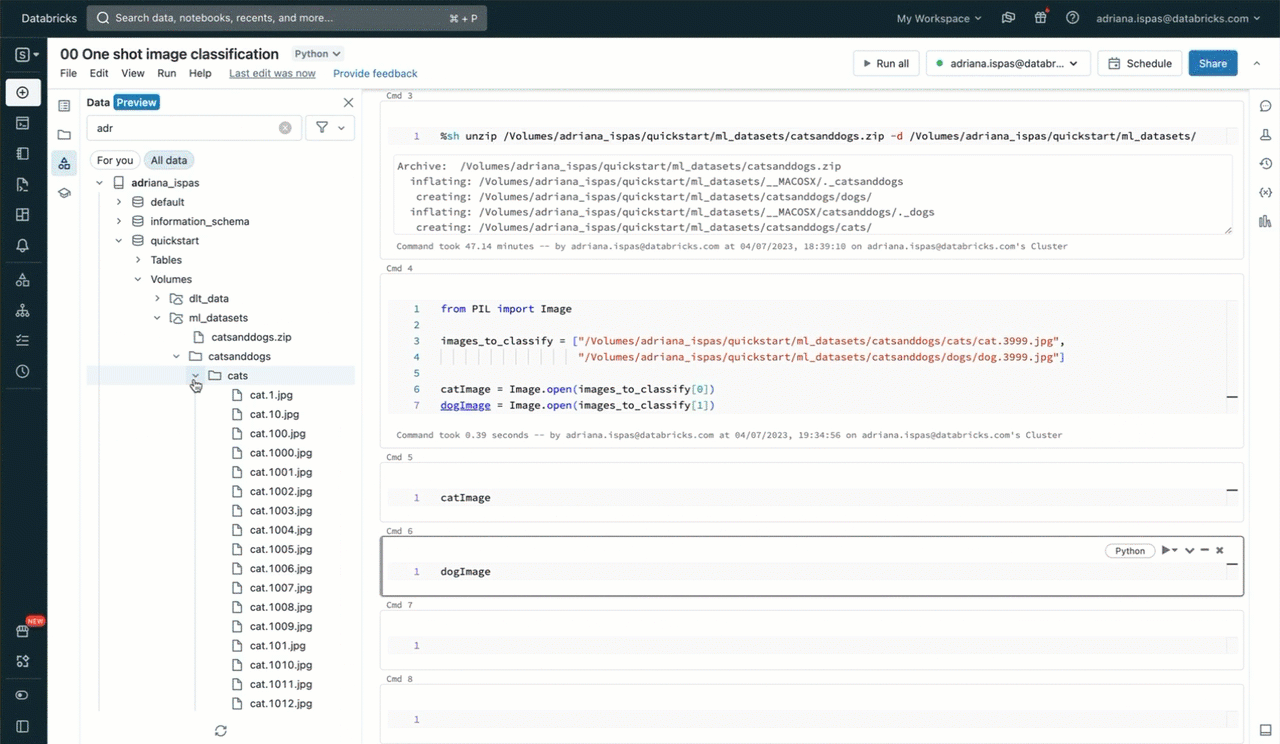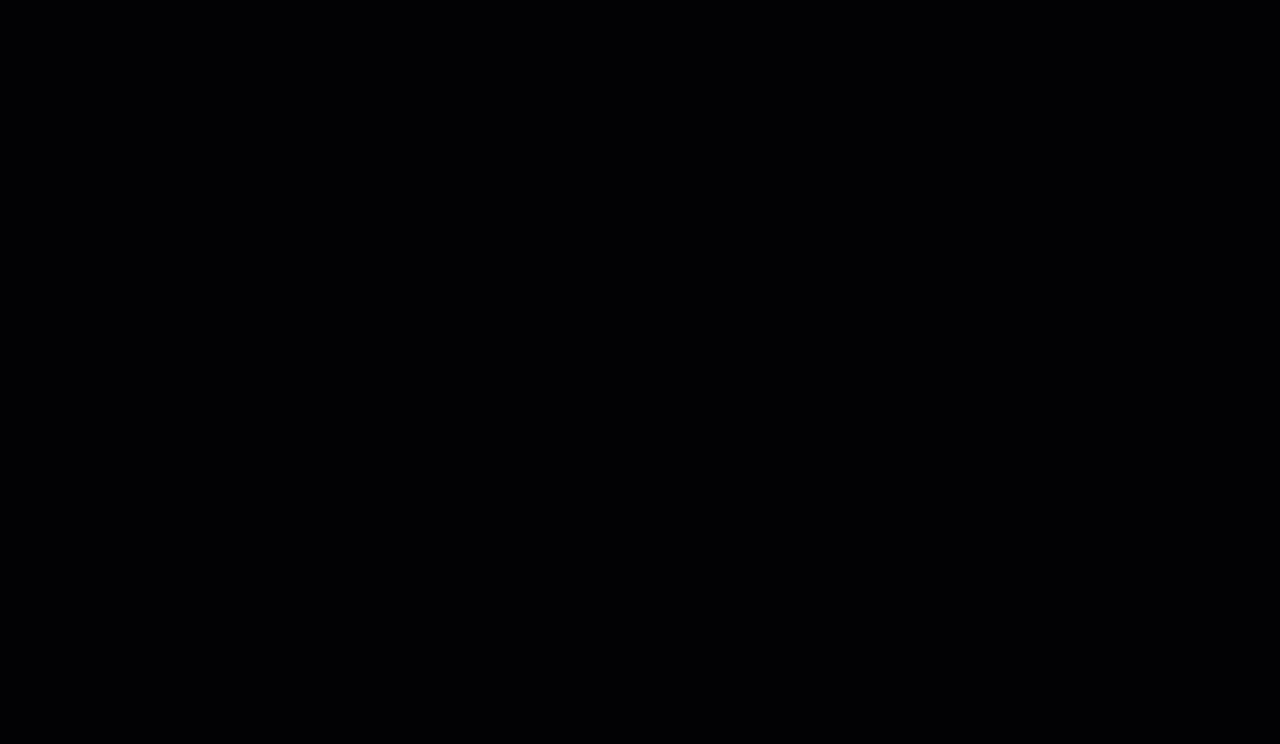
Now, we can proceed to extract the image archive using the commonly used unzip utility. It's worth noting that the command includes a path that specifically pertains to our Volume. This path corresponds to the Unity Catalog resource hierarchy and respects the permissions defined in Unity Catalog.
To execute this command, we can use a notebook where we have the convenience of accessing the Volume's content through the sidebar. Additionally, we can make use of the "Copy path" function to expedite the process of typing file-related commands such as listing files or displaying images.
The screencast below demonstrates the full interaction flow.
In order to classify the images using labels from a predefined list, we utilize a zero-shot image classification model that has been registered in advance to the MLflow Model Registry within Unity Catalog. The code snippet provided below demonstrates how to load the model, perform the classification, and display the resulting predictions. The accompanying screencast shown below provides a visual representation of these interactions.
Essential Volume Capabilities in Unity Catalog
Govern Non-tabular data with Unity Catalog. Volumes are cataloged inside schemas in Unity Catalog alongside tables, models, and functions and follow the core principles of the Unity Catalog object model, meaning that data is secure by default. Data stewards with sufficient privileges can create Volumes, becoming the Volume's owner and the only principal able to access its content. They can then grant other users and groups permission to read and write the Volume's content. Files stored inside a Volume can be accessed across workspaces, with the option to restrict Volume access to specific workspaces by binding their parent catalog to the desired workspaces.
Flexible Storage Configuration with Managed or External Volumes. You have the option to configure either managed or external Volumes. Managed Volumes store files in the default storage location for the Unity Catalog schema and are a convenient solution when you want a governed location for files without the overhead of first configuring access to Cloud storage, e.g., for quick data explorations starting from files uploaded from your local machine. External Volumes store files in an external storage location referenced when creating the Volume and are helpful when files produced by other systems need to be staged for access from within Databricks. For example, you can provide direct access to a Cloud storage location where large collections of image and video data generated by IoT or medical devices are deposited.
Process Data at Cloud Storage Performance and Scale. Volumes are backed by Cloud object storage, hence benefiting from the durability, availability, scalability, and stability of Cloud storage. You can use Volumes to run high-traffic workloads at Cloud storage performance and process data at scale – petabytes or more.
Boost Productivity with State-of-the-Art User Interface: Volumes are seamlessly integrated across the Databricks Platform experience, including the Data Explorer, notebooks, Lineage, the Add Data, or the cluster library configuration user interfaces. You can use the user interface for a wide range of actions: manage Volume permissions and ownership; manage a Volume's lifecycle through actions such as creating, renaming, or deleting Volume entities; manage a Volume's content, including browsing, uploading, or downloading files; browse Volumes and their content alongside notebooks; inspect lineage; configure the source for cluster or job libraries; and many more.
Leverage Familiar Tools for Working with Files. Volumes introduce a dedicated path format to access files that reflects the Unity Catalog hierarchy and respects defined permissions when used across Databricks:
You can use the path to reference files inside Apache Spark™ and SQL commands, REST APIs, Databricks file system utilities (dbutils.fs), the Databricks CLI, Terraform, or when using various operating system libraries and file utilities. Below is a non-exhaustive list with usage examples.
| Usage | Example |
|---|---|
| Databricks file system utilities | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/") |
| Apache Spark™ APIs | spark.read.text("/Volumes/my_catalog/my_schema/my_volume/data.txt").show() |
| Apache Spark™ SQL / DBSQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv` |
| Pandas | import pandas as pd |
| Shell commands via %sh | %sh curl http://<address>/text.zip > /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| Library installs using %pip | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Operating system file utilities | import os |
Unlock New Processing Capabilities for Data Managed by Unity Catalog. Volumes provide an abstraction over Cloud-specific APIs and Hadoop connectors, such as s3a://, abfss://, or gs://, which makes it easier to work with Cloud-stored data files in Apache Spark™ Spark applications, as well as tools that don't natively support object storage APIs. Using the dedicated Volume file paths, you can access, traverse and process a Volume's content as if files were local to the cluster nodes while file operations map to underlying Cloud storage operations. This is particularly useful for working with various data science and ML libraries, such as Pandas, scikit-learn, TensorFlow keras, and many more.
Getting started with Volumes in Unity Catalog
Unity Catalog Volumes are now available in the Databricks Enterprise and Pro tiers, starting from Databricks Runtime 13.2 and above. To help you get started with Volumes, we have prepared a comprehensive step-by-step guide. If you already have a Databricks account, you can follow our documentation, which provides detailed instructions on creating your first Volume (AWS | Azure | GCP). Once you've created a Volume, you can leverage the Data Explorer (AWS | Azure | GCP) to explore its contents or learn the SQL syntax for Volume management (AWS | Azure | GCP). We also encourage you to review our best practices (AWS | Azure | GCP) to make the most out of your Volumes. If you're new to Databricks and don't have an account yet, you can sign up for a free trial to experience the benefits of Volumes in Unity Catalog firsthand.
Stay tuned for an array of exciting Volumes features, including the ability to share Volumes using Delta Sharing and a REST API for file management operations like uploading, downloading, and deleting files.
You can also watch the Data and AI Summit Sessions on What's new with Unity Catalog, deep dive session for best implementation practices and Everything You Need to Know to Manage LLMs.
Never miss a Databricks post
What's next?


Product
November 21, 2024/3 min read