Best Practices and Guidance for Cloud Engineers to Deploy Databricks on AWS: Part 1
The Databricks Architecture and Workflows for Cloud Engineers

As a cloud engineering team, it may seem like a daily occurrence that you get a request from a team to deploy a platform as a solution (PaaS) in your Amazon Web Services (AWS) environment. These requests might read something like, “we need to deploy Databricks in our development AWS account for a proof of concept. We’ve already reviewed it with security, they’ve OK’d it.”
When you get these requests, you may start by scheduling meetings for additional context with the requester, combing through the documentation on networking requirements and architecture examples on the PaaS vendor’s website, and tracking down any infrastructure as code (IaC) examples you can find.
In this blog post series, I want to help shorten your discovery process by breaking down Databricks on AWS from the lens of a cloud engineer. By the end of this blog series, the goal is for you to understand Databricks and the value it brings to your data team, the architecture of the platform and its implication to your AWS environment, and a path forward to deploy a workspace within your organization’s network topology.
I’ll break all this information down into a three-part blogs series:
- In this blog post, I’ll explain what the Databricks Lakehouse Platform enables your data teams to accomplish, break down the Databricks architecture and a common data engineering workflow, and the benefits the architecture brings from the perspective of your cloud engineering team.
- In the next blog I’ll cover the frequently asked questions from our customers around customer managed VPC requirements.
- In the last blog post, I’ll talk about common deployment methods we see customers using for Databricks workspaces from proof of concepts to production.
NOTE: Databricks offers a serverless SQL data warehouse where compute is hosted in the Databricks AWS account (Serverless data plane). In this series, we will cover the Databricks classic model where the cloud compute is hosted in the customer’s AWS account (Classic data plane). We will not be covering the Serverless data plane in this blog series.
Databricks Lakehouse Platform:
Before we jump into the architecture and workflow, let’s talk briefly about the Databricks Lakehouse Platform.
In short, Databricks combines the best elements of data lakes and data warehouses to create a unified approach that simplifies your modern data stack.
Instead of your data team maintaining an open-source Apache Spark(™) solution to process unstructured data, a proprietary cloud data warehouse to serve business intelligence use cases, and a machine learning platform to publish models, they can unify all three personas in your Databricks Lakehouse Platform.
Using Databricks your data engineers, data analysts, and data scientists will be able to work collaboratively while simplifying your organization's data processing, analysis, storage, governance, and serving.
What this means for a cloud engineer: This unification of data personas into a single solution reduces the number of products your team is managing permissions, networking, and security for. Instead of multiple tools requiring different security groups, identity and access management (IAM) permissions, and monitoring, that’s now narrowed down to just one platform.
Now that we have briefly covered the Databricks Lakehouse Platform and how your data teams use it, let’s go a level deeper and talk about Databricks architecture and an example data engineering workflow.
If you’re interested in learning more about the Lakehouse, please take a look at this blog post describing the architectural pattern in much greater detail.
NOTE: For the duration of this blog, when I refer to clusters or SQL data warehouses in the context of Databricks, you can assume I’m referring to Amazon Elastic Compute Cloud (EC2) instances with an attached Databricks Amazon Machine Image (AMI) that reside in a private subnet in your AWS account.
Databricks architecture for cloud engineers
The Databricks architecture is split into two main components: the control plane and data plane. The purpose of this structure is to enable secure cross-functional team collaboration while keeping a significant amount of backend services managed by Databricks, so your data teams can focus on data science, analytics, and engineering.
- The control plane consists of the backend services that Databricks manages within its AWS account. This includes notebook commands and many other workspace configurations that are all encrypted at rest.
- The data plane consists of compute resources for notebooks, jobs, and classic SQL data warehouses that are spun up within your AWS environment.
To provide a real-life example of how this architecture functions for your data team, suppose you have a data engineer who signs in to Databricks and writes code in a notebook that transforms raw data coming from Amazon Kinesis to be persisted on Amazon Simple Storage Service (S3).
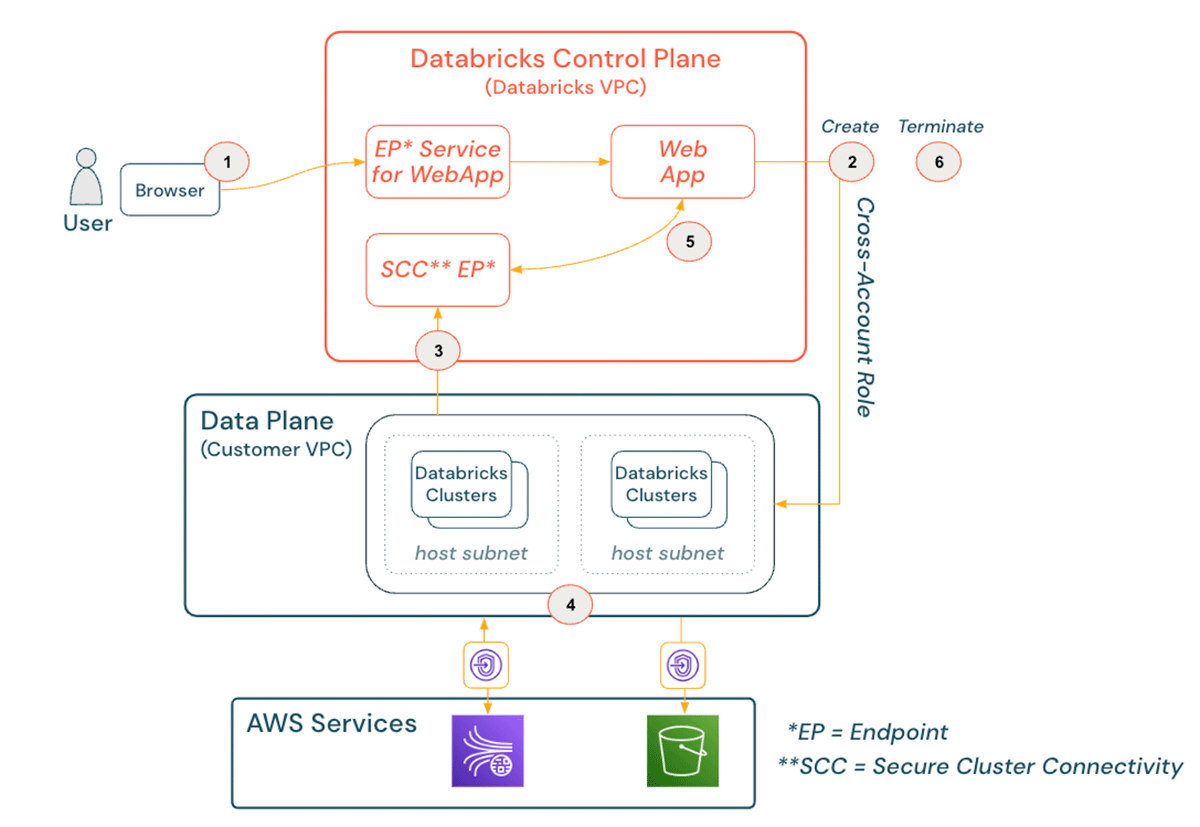
Here’s what this data engineering workflow looks like from a cloud engineering viewpoint:
- The data engineer authenticates, via single sign-on if desired, to the web UI in the control plane, hosted in the Databricks AWS account. For additional configuration options, a front-end PrivateLink connection and / or IP access lists can be implemented.
- The data engineer navigates to the compute tab where they click to create a cluster with a set of configurations (size, autoscaling, auto termination, etc.). On the backend, EC2 instance(s) with the latest Databricks AMI is spun up within the appropriate VPC, private subnet, and security group(s) using the cross-account role that was assigned during the workspace creation.
- Once the cluster is active, an outbound connection, called our secure cluster connectivity relay, to the control plane either over the public internet (NAT gateway to IGW) or on backbone infrastructure using AWS PrivateLink is attempted.
- Once the connection between the cluster and the control plane has been established, your data engineer is free to start writing code. As the data transformation code is being pushed to the cluster from the control plane, the cluster will pull data from Kinesis and then write it to S3.
- As the job is processing, the cluster reports status and any user outputs (data preview, metadata, etc.) back to the cluster manager in the control plane, giving the data engineer visibility into how the job is running.
- Once the job has wrapped up, the data engineer can either terminate the cluster manually in the Databricks’ UI or let it auto-terminate based on a predefined setting. Once the termination request is received the underlying AWS resources will soon be terminated in your environment.
While this is from the perspective of a cloud engineer, these backend processes are entirely obfuscated to the data team. In the web application, your data teams will see a cluster spinning up, then see a green check mark next to it once it’s running, and at that point they’re off to the hypothetical coding races.
Benefits of the Databricks architecture for a cloud engineer
Now, we have an overview of the Databricks architecture. I’ll discuss three key benefits that this architecture provides you and your cloud engineering team.
Benefit #1 - Ease of use case adoption
After a Databricks workspace is deployed in your AWS account, I can assume the next ticket the data team will raise will be something along the lines of, “I need to get data from an on-premises Kafka instance and database”, “I need to query data from RDS”, or “I need to get data from this API.
A benefit of our architecture is when you get a ticket like this, all you’ll need to do is think of the problem from two perspectives:
- Does your cluster in your private subnet have connectivity to reach the destination?
- Does your cluster in your private subnet have permission to reach the destination?
Let’s look at some examples of this:
- If you want to connect to an Amazon Relational Database Service (RDS) instance in a different AWS account, you’d think about this from the perspective of, “how can my cluster reach that database?”. At that point, you’re now just thinking in standard networking architecture patterns. You could implement VPC peering between the VPCs or potentially use a transit gateway between the accounts. Once you’ve established the pattern you want to use to route the traffic from your cluster, your data team will now be able to query the database.
- In a similar situation, if the data team says they are getting a connection rejected when trying to read data from Amazon Redshift. You can narrow down the issue to either an IAM permission or a security group rule blocking traffic on the Redshift instance or the Databricks cluster.
It doesn’t matter if the source is streaming, batch, unstructured, or structured, Databricks will be able to access it, transform it, and persist it to a specified location for your data teams. And for you, as the cloud engineers, as long as the cluster can connect and has the required permissions, there’ll be little issue in onboarding the new source system.
Benefit #2 - Deployment flexibility
So far, I’ve discussed the Databricks architecture and talked about why it makes it easier to adopt new use cases. Now, I want to touch briefly on the flexibility you have to deploy a Databricks workspace within your AWS account.
There are two parts to a standard Databricks workspace deployment, the required AWS resources in your account and the API calls to register those resources with Databricks’ control plane. This openness puts your cloud engineering team in the driver seat on how you’d like to deploy your AWS resources and call the required APIs.
- Are you a Terraform shop? We have a published HashiCorp Terraform provider that can be used to deploy Workspaces.
- Do you prefer AWS CloudFormation? We have an open source CloudFormation template that you can adapt to your needs or even use an out-of-the-box AWS QuickStart.
- Just like using the console? Once you’ve deployed the required AWS resources for a customer managed VPC, then create the workspace by calling our REST APIs.
- Do you want nothing to do with deploying any networking resources? Use the Quick Start found in our account console to create a Databricks managed VPC, Databricks will deploy all the necessary resources to get your workspace deployed in just about ten minutes.
We work with customers to deploy Databricks in a variety of ways, because we understand that network topologies will vary from customer to customer. We want to meet you and your cloud engineering team where you’re currently at in your cloud journey.
Stay tuned for part three of this blog series where we’ll discuss each of these deployment options in more detail.
Benefit #3 - Opportunity for extensive cloud monitoring
The last benefit of the Databricks architecture I want to talk about is the ability for extensive cloud resource monitoring.
Whether it’s for charging business units for their spending, tracking network traffic from EC2 instances, or registering errant API calls, monitoring what’s happening in and around your AWS resources is crucial to maintain the integrity of your environment.
The Databricks architecture will fit right into your existing or soon to be implemented tracking methodologies. Whether that’s tagging clusters, monitoring billing data, inspecting VPC flow logs to see the accepted and rejected traffic from your underlying EC2 instance, or validating API calls made from the cross-account role, our platform strives to be open and transparent to how data is accessed and processed by your users.
If you’re looking to go deeper into monitoring the compute running in your environment and the status of your various clusters, you can monitor the status of it with commonly used products like Datadog or Amazon Cloudwatch.
What’s next?
This blog post provided you with an overview of the Databricks Lakehouse Platform with a cloud engineer persona in mind. I discussed some of the benefits the Databricks architecture provides to your team like ease of use case adoption, deployment flexibility, and opportunity for extensive cloud resource monitoring.
In my next blog post, I’m going to deep dive into what makes up the Classic data plane. We’ll step through the requirements and commonly asked questions I’ve received from customers around creating your own customer managed VPC.
Overall, I hope this first piece was helpful for cloud engineers getting acquainted with the Databricks Lakehouse Platform and I’ll talk to you all soon in part two. In the meantime, you can go ahead and get started with a free trial of Databricks today!
Never miss a Databricks post
What's next?


Product
November 21, 2024/3 min read