Best Practices and Guidance for Cloud Engineers to Deploy Databricks on AWS: Part 3
Automating your Databricks Deployments on AWS

For the final part of our Best Practices and Guidance for Cloud Engineers to Deploy Databricks on AWS series, we'll cover an important topic, automation. In this blog post, we'll break down the three endpoints used in a deployment, go through examples in common infrastructure as code (IaC) tools like CloudFormation and Terraform, and wrap with some general best practices for automation.
However, if you're now just joining us, we recommend that you read through part one where we outline the Databricks on AWS architecture and its benefits for a cloud engineer. As well as part two, where we walk through a deployment on AWS with best practices and recommendations.
The Backbone of Cloud Automation:
As cloud engineers, you'll be well aware that the backbone of cloud automation is application programming interfaces (APIs) to interact with various cloud services. In the modern cloud engineering stack, an organization may use hundreds of different endpoints for deploying and managing various external services, internal tools, and more. This common pattern of automating with API endpoints is no different for Databricks on AWS deployments.
Types of API Endpoints for Databricks on AWS Deployments:
A Databricks on AWS deployment can be summed up into three types of API endpoints:
- AWS: As discussed in part two of this blog series, several resources can be created with an AWS endpoint. These include S3 buckets, IAM roles, and networking resources like VPCs, subnets, and security groups.
- Databricks - Account: At the highest level of the Databricks organization hierarchy is the Databricks account. Using the account endpoint, we can create account-level objects such as configurations encapsulating cloud resources, workspace, identities, logs, etc.
- Databricks Workspace: The last type of endpoint used is the workspace endpoint. Once the workspace is created, you can use that host for everything related to that workspace. This includes creating, maintaining, and deleting clusters, secrets, repos, notebooks, jobs, etc.
Now that we've covered each type of endpoint in a Databricks on AWS deployment. Let's step through an example deployment process and call out each endpoint that will be interacted with.
Deployment Process:
In a standard deployment process, you'll interact with each endpoint listed above. I like to sort this from top to bottom.
- The first endpoint will be AWS. From the AWS endpoints you'll create the backbone infrastructure of the Databricks workspace, this includes the workspace root bucket, the cross-account IAM role, and networking resources like a VPC, subnets, and security group.
- Once those resources are created, we'll move down a layer to the Databricks account API, registering the AWS resources created as a series of configurations: credential, storage, and network. Once those objects are created, we use those configurations to create the workspace.
- Following the workspace creation, we'll use that endpoint to perform any workspace activities. This includes common activities like creating clusters and warehouses, assigning permissions, and more.
And that's it! A standard deployment process can be broken out into three distinct endpoints. However, we don't want to use PUT and GET calls out of the box, so let's talk about some of the common infrastructure as code (IaC) tools that customers use for deployments.
Gartner®: Databricks Cloud Database Leader

Commonly used IaC Tools:
As mentioned above, creating a Databricks workspace on AWS simply calls various endpoints. This means that while we're discussing two tools in this blog post, you are not limited to these.
For example, while we won't talk about AWS CDK in this blog post, the same concepts would apply in a Databricks on AWS deployment.
If you have any questions about whether your favorite IaC tool has pre-built resources, please contact your Databricks representative or post on our community forum.
HashiCorp Terraform:
Released in 2014, Terraform is currently one of the most popular IaC tools. Written in Go, Terraform offers a simple, flexible way to deploy, destroy, and manage infrastructure across your cloud environments.
With over 13.2 million installs, the Databricks provider allows you to seamlessly integrate with your existing Terraform infrastructure. To get you started, Databricks has released a series of example modules that can be used.
These include:
- Deploy Multiple AWS Databricks Workspaces with Customer-Managed Keys, VPC, PrivateLink, and IP Access Lists - Code
- Provisioning AWS Databricks with a Hub & Spoke Firewall for Data Exfiltration Protection - Code
- Deploy Databricks with Unity Catalog - Code: Part 1, Part 2
See a complete list of examples created by Databricks here.
We frequently get asked about best practices for Terraform code structure. For most cases, Terraform's best practices will align with what you use for your other resources. You can start with a simple main.tf file, then separate logically into various environments, and finally start incorporating various off-the-shelf modules used across each environment.
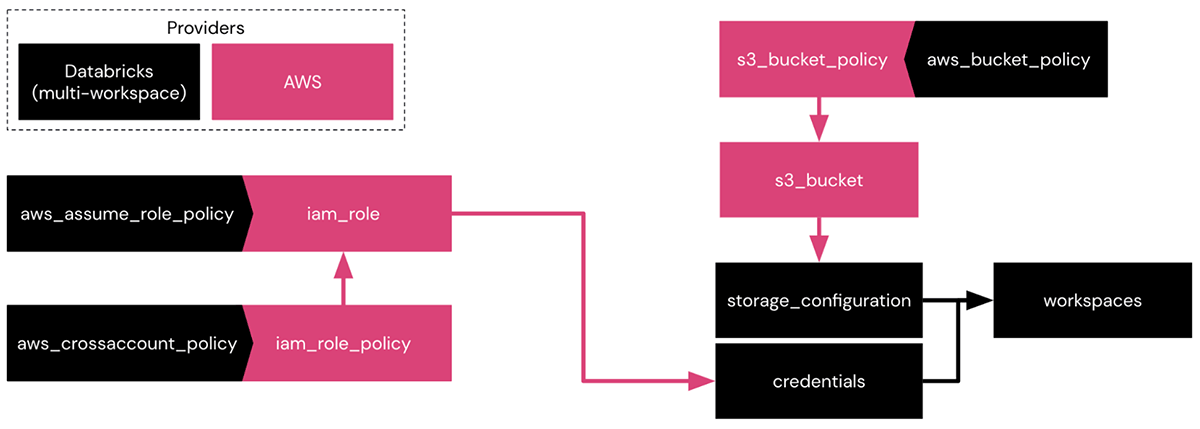
In the above image, we can see the interaction between the various resources found in both the Databricks and AWS providers when creating a workspace with a Databricks-managed VPC.
- Using the AWS provider, you'll create an IAM role, IAM policy, S3 bucket, and S3 bucket policy.
- Using the Databricks provider, you'll call data sources for the IAM role, IAM policy, and the S3 bucket policy.
- Once those resources are created, you log the bucket and IAM role as a storage and credential configuration for the workspace with the Databricks provider.
This is a simple example of how the two providers interact with each other and how these interactions can grow with the addition of new AWS and Databricks resources.
Last, for existing workspaces that you'd like to Terraform, the Databricks provider has an Experimental Exporter that can be used to generate Terraform code for you.
Databricks Terraform Experimental Exporter:
The Databricks Terraform Experimental Exporter is a valuable tool for extracting various components of a Databricks workspace into Terraform. What sets this tool apart is its ability to provide insights into structuring your Terraform code for the workspace, allowing you to use it as is or make minimal modifications. The exported artifacts can then be utilized to set up objects or configurations in other Databricks environments quickly.
These workspaces may serve as lower environments for testing or staging purposes, or they can be utilized to create new workspaces in different regions, enabling high availability and facilitating disaster recovery scenarios.
To demonstrate the functionality of the exporter, we've provided an example GitHub Actions workflow YAML file. This workflow utilizes the experimental exporter to extract specific objects from a workspace and automatically pushes these artifacts to a new branch within a designated GitHub repository each time the workflow is executed. The workflow can be further customized to trigger source repository pushes or scheduled to run at specific intervals using the cronjob functionality within GitHub Actions.
With the designated GitHub repository, where exports are differentiated by branch, you can choose the specific branch you wish to import into an existing or new Databricks workspace. This allows you to easily select and incorporate the desired configurations and objects from the exported artifacts into your workspace setup. Whether setting up a fresh workspace or updating an existing one, this feature simplifies the process by enabling you to leverage the specific branch containing the necessary exports, ensuring a smooth and efficient import into Databricks.
This is one example of utilizing the Databricks Terraform Experimental Exporter. If you have additional questions, please reach out to your Databricks representative.
Summary: Terraform is a great choice for deployment if you have familiarity with it, are already using it with pre-existing pipelines, looking to make your deployment process more robust, or managing a multi-cloud set-up.
AWS CloudFormation:
First announced in 2011, AWS CloudFormation is a way to manage your AWS resources as if they were cooking recipes.
Databricks and AWS worked together to publish our AWS Quick Start leveraging CloudFormation. In this open source code, AWS resources are created using native functions, then a Lambda function will execute various API calls to the Databricks' account and workspace endpoints.
For customers using CloudFormation, we recommend using the open source code from the Quick Start as a baseline and customizing it according to your team's specific requirements.
Summary: For teams with little DevOps experience, CloudFormation is a great GUI-based choice to get Databricks workspaces quickly spun up given a set of parameters.
Best Practices:
To wrap up this blog, let's talk about best practices for using IaC, regardless of the tool you're using.
- Iterate and Iterate: As the old saying goes, "don't let perfect be the enemy of good". The process of deployment and refining code from proof of concept to production will take time and that's entirely fine! This applies even if you deploy your first workspace through the console, the most important part is just getting started.
- Modules not Monoliths: As you continue down the path of IaC, it's recommended that you break out your various resources into individual modules. For example, if you know that you'll use the same cluster configuration in three different environments with complete parity, create a module of this and call it into each new environment. Creating and maintaining multiple identical resources can become burdensome to maintain.
- Scale IaC Usage in Higher Environments: IaC is not always uniformly used across development, QA, and production environments. You may have common modules used everywhere, like creating a shared cluster, but you may allow your development users to create manual jobs while in production they're fully automated. A common trend is to allow users to work freely within development then as they pass into production-ready, use an IaC tool to package it up and push it to higher environments like QA and production. This keeps a level of standardization, but gives your users the freedom to explore the platform.
- Proper Provider Authentication: As you adopt IaC for your Databricks on AWS deployments, you should always use service principals for the account and workspace authentication. This allows you to avoid hard-coded user credentials and manage service principals per environment.
- Centralized Version Control: As mentioned before, integrating IaC is an iterative process. This applies for code maintenance and centralization as well. Initially, you may run your code from your local machine, but as you continue to develop, it's important to move this code into a central repository such as GitHub, GitLab, BitBucket, etc. These repositories and backend Terraform configurations can allow your entire team to update your Databricks workspaces.
In conclusion, automation is crucial to any successful cloud deployment, and Databricks on AWS is no exception. You can ensure a smooth and efficient deployment process by utilizing the three endpoints discussed in this blog post and implementing best practices for automation. So, suppose you're a cloud engineer looking to deploy Databricks on AWS, in this case, we encourage you to incorporate these tips into your deployment strategy and take advantage of the benefits that this powerful platform has to offer.