Building and Customizing GenAI with Databricks: LLMs and Beyond

Generative AI has opened new worlds of possibilities for businesses and is being emphatically embraced across organizations. According to a recent MIT Tech Review report, all 600 CIOs surveyed stated they are increasing their investment in AI, and 71% are planning to build their own custom LLMs or other GenAI models. However, many organizations may lack the tools needed to effectively develop models trained on their own data.
Making the leap to Generative AI is not just about deploying a chatbot; it requires a reshaping of the foundational aspects of data management. Central to this transformation is the emergence of Data Lakehouses as the new “modern data stack.” These advanced data architectures are essential in harnessing the full potential of GenAI, enabling faster, more cost-effective, and wider democratization of data and AI technologies. As businesses increasingly rely on GenAI-powered tools and applications for competitive advantage, the underlying data infrastructure must evolve to support these advanced technologies effectively and securely.
The Databricks Data Intelligence Platform is an end-to-end platform that can support the entire AI lifecycle from ingestion of raw data, through model customization, and ultimately to production-ready applications. It gives organizations more control, engineering efficiency, and lower TCO: full control over models and data through more rigorous security and monitoring; easier ability to productionalize ML models with governance, lineage, and transparency; and lowered costs to train a company’s own models. Databricks stands out as the sole provider capable of offering these comprehensive services, including prompt engineering, RAG, fine-tuning, and pre-training, specifically tailored to develop a company's proprietary models from the ground up.
This blog explains why companies are using Databricks to build their own GenAI applications, why the Databricks Data Intelligence Platform is the best platform for enterprise AI, and how to get started. Excited? We are too! Topics include:
- How can my organization use LLMs trained on our own data to power GenAI applications — and smarter business decisions?
- How can we use the Databricks Data Intelligence Platform to fine-tune, govern, operationalize, and manage all of our data, models, and APIs on a unified platform, while maintaining compliance and transparency?
- How can my company leverage the Databricks Data Intelligence Platform as we progress along the AI maturity curve, while fully leveraging our proprietary data?
GenAI for Enterprises: Leveraging AI with Databricks Data Intelligence Platform
Why use a Data Intelligence Platform for GenAI?
Data Intelligence Platforms let you maintain industry leadership with differentiated applications built using GenAI tools. The benefits of using a Data Intelligence Platform include:

- Complete Control: Data Intelligence Platforms enable your organization to use your own unique enterprise data to build RAG or custom GenAI solutions. Your organization has complete ownership over both the models and the data. You also have security and access controls, guaranteeing that users who shouldn’t have access to data won’t get it.
- Production Ready: Data Intelligence Platforms have the ability to serve models at a massive scale, with governance, repeatability, and compliance built in.
- Cost Effective: Data Intelligence Platforms provide maximum efficiency for data streaming, allowing you to create or finetune LLMs custom-tailored to your domain, as well as leverage the most performant and cost-efficient LLM serving and training frameworks.
Thanks to Data Intelligence Platforms, your enterprise can take advantage of the following outcomes:
- Intelligent Data Insights: your business decisions are enriched through the use of ALL of your data assets: structured, semi-structured, unstructured, and streaming. According to the MIT Tech Review report, up to 90% of a company’s data is untapped. The more varied the data (think PDFs, Word docs, images, and social media) used to train a model, the more impactful the insights can be. Knowing what data is being accessed and how frequently elucidates what is most valuable, and what data remains untapped.
- Domain-specific customization: LLMs are built on your industry’s lingo and only on data you choose to ingest. This lets your LLM understand domain-specific terminology, which third party services won’t know. Even better: by using your own data, your IP is kept in-house.
- Simple governance, observability, and monitoring: By building or finetuning your own model, you’ll gain a better understanding of the outcomes. You’ll know how models were built, and on what versions of data. You’ll have a finger on the pulse to know how your models are performing, if incoming data is starting to drift, and if models might need to be retrained to improve accuracy.
“You don’t necessarily want to build off an existing model where the data that you’re putting in could be used by that company to compete against your own core products.” - Michael Carbin, MIT Professor and Mosaic AI Founding Advisor
STAGES OF EVOLUTION
Ready to jump in? Let’s look at the typical profile of an organization at each stage of the AI maturity curve when you should think about advancing to the next stage, and how Databricks’ Data Intelligence Platform can support you.
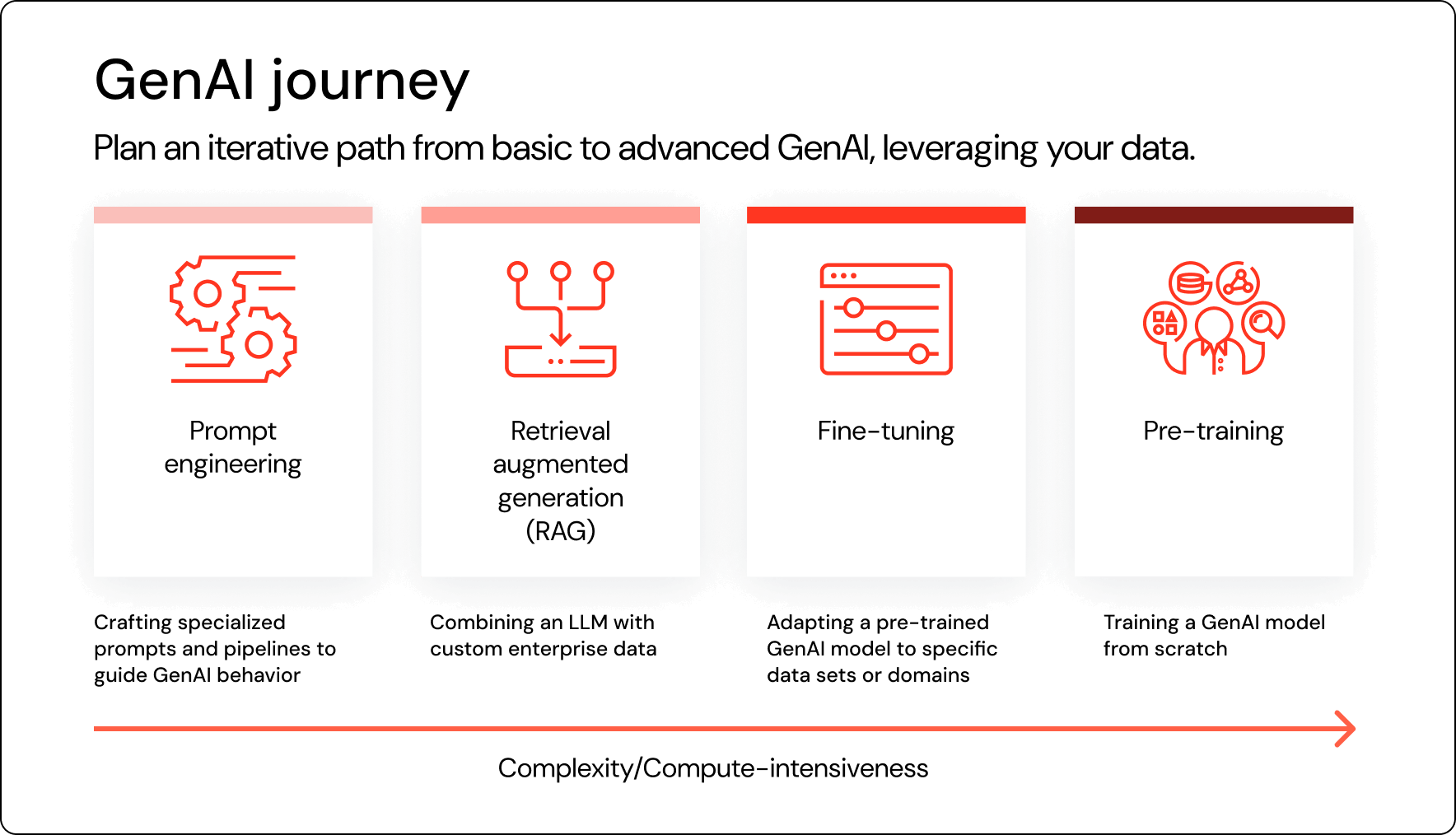
Pre-stage: Ingest, transform, and prepare data
The natural starting point for any AI adventure is always going to be with data. Companies often have vast amounts of data already collected, and the pace of new data increases at an immensely fast pace. Data can be a mix of all types: from structured transactional data that is collected in real-time to scanned PDFs that might have come in via the web.
Databricks Lakehouse processes your data workloads to reduce both operating costs and headaches. Central to this ecosystem is the Unity Catalog, a foundational layer that governs all your data and AI assets, ensuring seamless integration and management of internal and external data sources, including Snowflake and MySQL and more. This enhances the richness and diversity of your data ecosystem.
You can bring in near real-time streaming data through Delta Live Tables to be able to take action on events as soon as possible. ETL workflows can be set up to run on the right cadence, ensuring that your pipelines have healthy data going through from all sources, while also providing timely alerts as soon as anything is amiss. This comprehensive approach to data management will be crucial later, as having the highest quality data, including external datasets, will directly affect the performance of any AI being used on top of this data.
Once you have your data confidently wrangled, it’s time to dip your toes into the world of Generative AI and see how you can create their first proof of concept.
Stage 1: Prompt Engineering
Many companies still remain in the foundational stages of adopting Generative AI technology: they have no overarching AI strategy in place, no clear use cases to pursue, and no access to a team of data scientists and other professionals who can help guide the company’s AI adoption journey.
If this is like your business, a good starting point is an off-the-shelf LLM. While these LLMs lack the domain-specific expertise of custom AI models, experimentation can help you plot out your next steps. Your employees can craft specialized prompts and workflows to guide their usage. Your leaders can get a better understanding of the strengths and weaknesses of these tools, as well as a clearer vision of what early success in AI might look like. Your organization can start to figure out where to invest in more powerful AI tools and systems that drive more significant operational gain.
If you are ready to experiment with external models, Model Serving provides a unified platform to manage all models in one place and query them with a single API.
Below is an example prompt and response for a POC:

Stage 2: Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) lets you bring in supplemental knowledge resources to make an off-the-shelf AI system smarter. RAG won’t change the underlying behavior of the model, but it will improve the relevancy and accuracy of the responses.
However, at this point, your business should not be uploading its “mission-critical” data. Instead, the RAG process typically involves smaller amounts of non-sensitive information.
For example, plugging in an employee handbook can enable your workers to start asking the underlying model questions about the organization’s vacation policy. Uploading instruction manuals can help power a service chatbot. With the ability to query support tickets using AI, support agents can get answers quicker; however, inputting confidential financial data so employees can inquire about the company’s performance is likely a step too far.
To get started, your team should first consolidate and cleanse the data you intend to use. With RAG, it’s vital that your company stores the data in sizes that will be appropriate for the downstream models. Often, that requires users to splice it into smaller segments.
Then, you should seek out a tool like Databricks Vector Search, which enables users to quickly set up their own vector database. And because it’s governed by Unity Catalog, granular controls can be put into place to make sure employees are only accessing the datasets for which they have credentials.
Finally, you can then plug that endpoint into a commercial LLM. A tool like Databricks MLflow helps to centralize the management of those APIs.
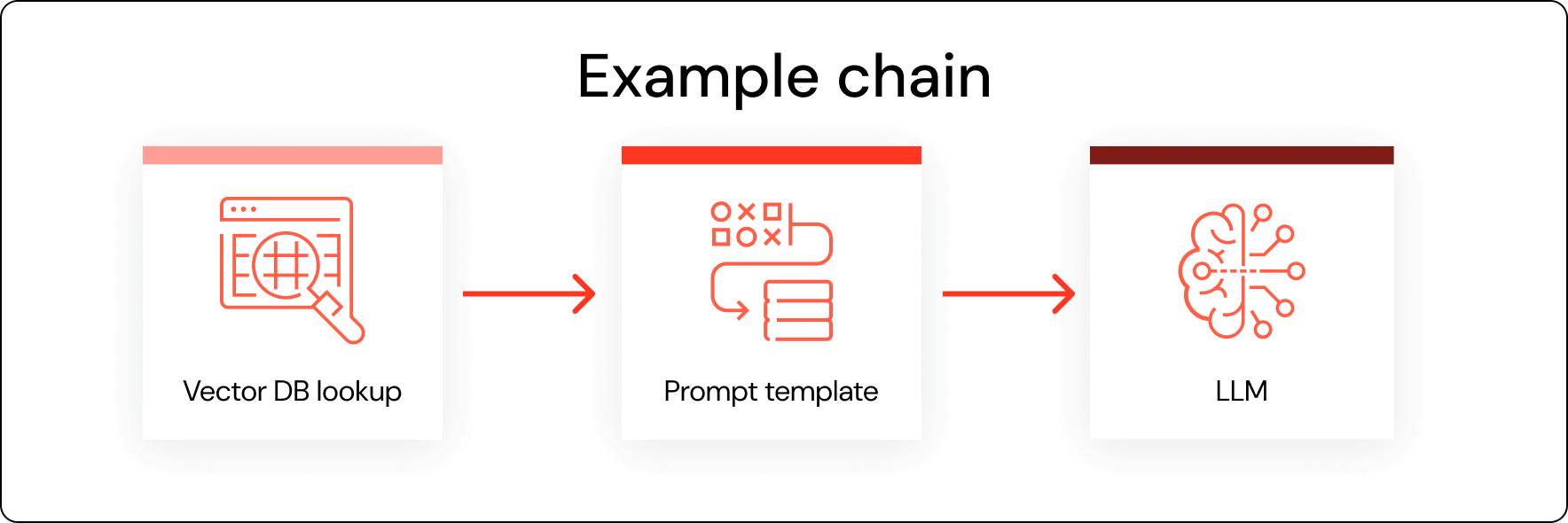
Among the benefits of RAG are reduced hallucinations, more up-to-date and accurate responses, and better domain-specific intelligence. RAG-assisted models are also a more cost-effective approach for most organizations.
While RAG will help improve the results from commercial models, there are still many limitations to the use of RAG. If your business is unable to get the results it wants, it’s time to move on to heavier-weight solutions, but moving beyond RAG-supported models often requires a much deeper commitment. The additional customization costs more and requires a lot more data.
That’s why it’s key that organizations first build a core understanding of how to use LLMs. By reaching the performance limitations of off-the-shelf models before moving on, you and your leadership can further hone in on where to allocate resources.
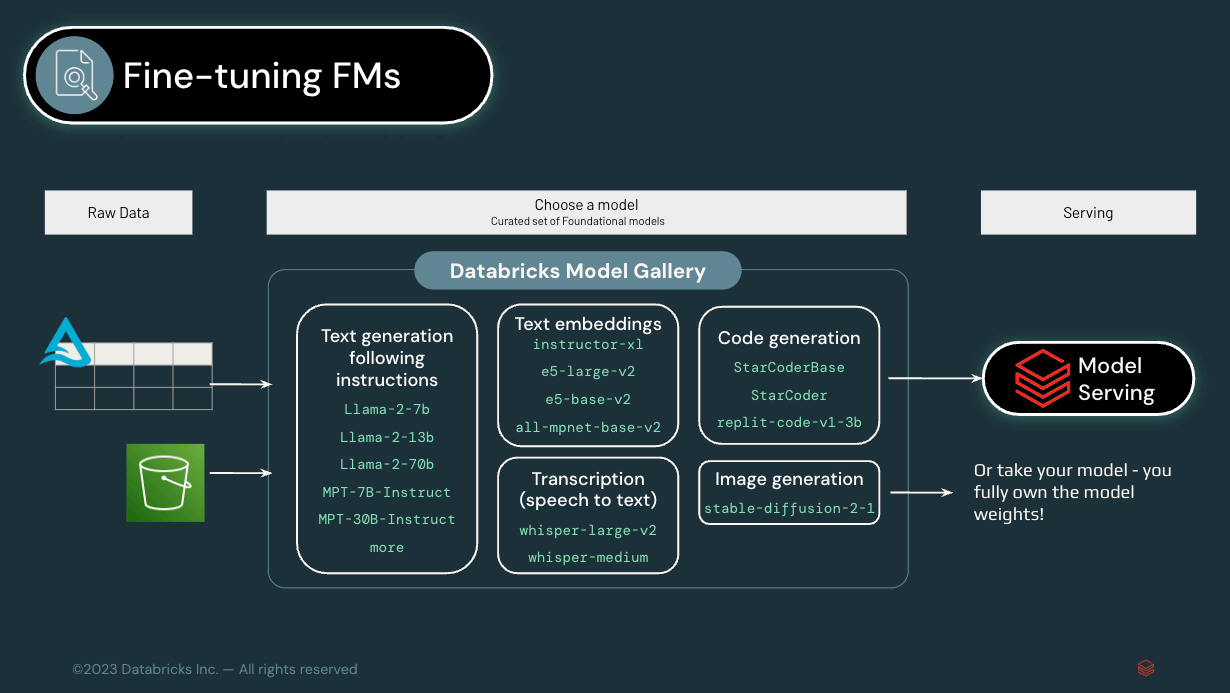
Stage 3: Fine-tuning a Foundation Model
Moving beyond RAG to model fine-tuning lets you start building models that are much more deeply personalized to the business. If you have already been experimenting with commercial models across your operations, you are likely ready to advance to this stage. There’s a clear understanding at the executive level of the value of Generative AI, as well as an understanding of the limitations of publicly available LLMs. Specific use cases have been established. And now, you and your enterprise are ready to go deeper.
With fine-tuning, you can take a general-purpose model and train it on your own specific data. For example, data management provider Stardog relies on the Mosaic AI tools from Databricks to fine-tune the off-the-shelf LLMs it uses as a foundation for its Knowledge Graph Platform. This enables Stardog’s customers to query their own data across the different silos simply by using natural language.
It’s imperative that organizations at this stage have an underlying architecture in place that will help ensure the data supporting the models is secure and accurate. Fine-tuning an AI system requires an immense amount of proprietary information, and as your business advances on the AI maturity curve, the number of models running will only grow, increasing the demand for data access.
That’s why you need to have the right mechanisms in place to track data from the moment it's generated to when it's eventually used, and why Unity Catalog is such a popular feature among Databricks customers. With its data lineage capabilities, businesses always know where data is moving and who is accessing it.
Stage 4: Pre-training a model from scratch
If you are at the stage where you are ready to pre-train a custom model, you’ve reached the apex of the AI maturity curve. Success here depends on not just having the right data in the right place, but also having access to the necessary expertise and infrastructure. Large model training requires a massive amount of compute and an understanding of the hardware and software complexities of a “hero run.” And beyond infrastructure and data governance considerations, be sure your use case and outcomes are clearly defined.
Don’t be afraid: while these tools may take investment and time to develop, they can have a transformative effect on your business. Custom models are heavy-duty systems that become the backbone of operations or power a new product offering. For example, software provider Replit relied on the Mosaic AI platform to build its own LLM to automate code generation.
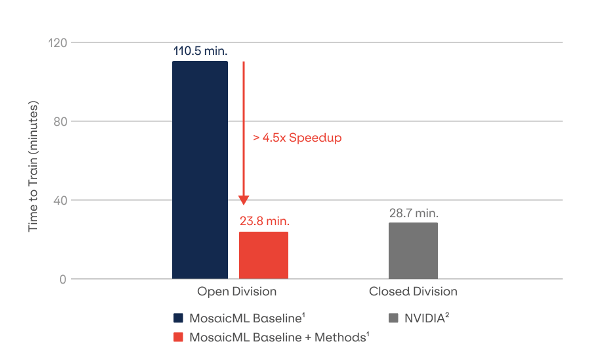
These pre-trained models perform significantly better than RAG-assisted or fine-tuned models. Stanford’s Center for Research on Foundation Models (working with Mosaic AI) built its own LLM specific to biomedicine. The custom model had an accuracy rate of 74.4%, much more accurate than the fine-tuned, off-the-shelf model accuracy of 65.2%.
Post-stage: Operationalizing and LLMOps
Congratulations! You have successfully implemented finetuned or pre-trained models, and now the final step is to productionalize it all: a concept referred to as LLMOps (or LLM Operations).
With LLMOps, contextual data is integrated nightly into vector databases, and AI models demonstrate exceptional accuracy, self-improving whenever performance drops. This stage also offers complete transparency across departments, providing deep insights into AI model health and functionality.
The role of LLMOps (Large Language Model Operations) is crucial throughout this journey, not just at the peak of AI sophistication. LLMOps should be integral from the early stages, not only at the end. While GenAI customers may not initially engage in complex model pre-training, LLMOps principles are universally relevant and advantageous. Implementing LLMOps at various stages ensures a strong, scalable, efficient AI operational framework, democratizing advanced AI benefits for any organization, whatever their AI maturity levels may be.
What does a successful LLMOps architecture look like?
The Databricks Data Intelligence Platform exists as the foundation to build your LLMOps processes on top of. It helps you manage, govern, evaluate, and monitor models and data easily. Here are some of the benefits it provides:
- Unified Governance: Unity Catalog allows for unified governance and security policies across data and models, streamlining MLOps management and enabling flexible, level-specific management in a single solution.
- Read Access to Production Assets: Data scientists get read-only access to production data and AI assets through Unity Catalog, facilitating model training, debugging, and comparison, thus enhancing development speed and quality.
- Model Deployment: Utilizing model aliases in Unity Catalog enables targeted deployment and workload management, optimizing model versioning and production traffic handling.
- Lineage: Unity Catalog's robust lineage tracking links model versions to their training data and downstream consumers, offering comprehensive impact analysis and detailed tracking via MLflow.
- Discoverability: Centralizing data and AI assets in Unity Catalog boosts their discoverability, aiding in efficient resource location and utilization for MLOps solutions.
To get a glimpse into what kind of architecture can bring forward this world, we’ve collected many of our thoughts and experiences into our Big Book of MLOps, which includes a large section on LLMs and covers everything we’ve spoken about here. If you want to reach this state of AI nirvana, we highly recommend taking a look.
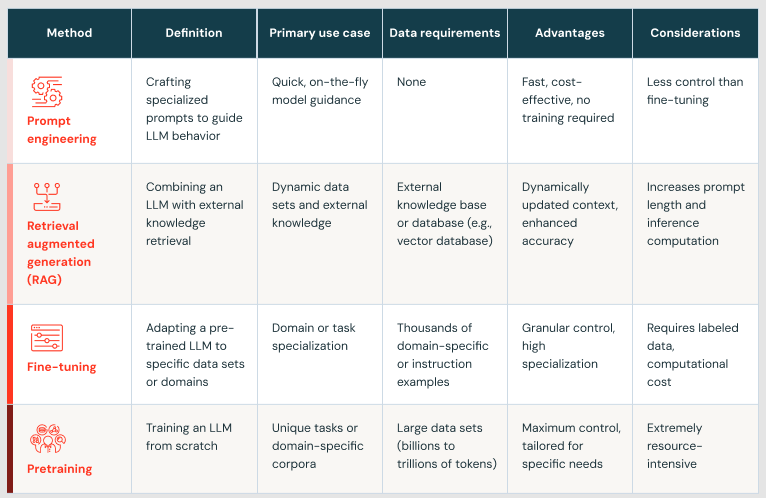
We learned in this blog about the multiple stages of maturity with companies implementing GenAI applications. The table below gives details:
Conclusion
Now that we’ve taken a journey along the Generative AI maturity curve and examined the techniques needed to make LLMs useful to your organization, let’s go back to where it all begins: a Data Intelligence Platform.
A powerful Data Intelligence Platform, such as Databricks, provides a backbone for customized AI-powered applications. It offers a data layer that’s both extremely performant at scale and also secure and governed to make sure only the right data gets used. Building on top of the data, a true Data Intelligence Platform will also understand semantics, which makes the use of AI assistants much more powerful as the models have access to your company’s unique data structures and terms.
Once your AI use cases start being built and put into production, you’ll also need a platform that provides exceptional observability and monitoring to make sure everything is performing optimally. This is where a true Data Intelligence platform shines, as it can understand what your “normal” profiles of data look like, and when issues may arise.
Ultimately, the most important goal of a Data Intelligence Platform is to bridge the gap between complex AI models and the diverse needs of users, making it possible for a wider range of individuals and organizations to leverage the power of LLMs (and Generative AI) to solve challenging problems using their own data.
The Databricks Data Intelligence Platform is the only end-to-end platform that can support enterprises from data ingestion and storage through AI model customization, and ultimately serve GenAI-powered AI applications.
Never miss a Databricks post
What's next?

Data Science and ML
June 12, 2024/8 min read
