Building a Data Mesh Based on the Databricks Lakehouse, Part 2

In the last blog "Databricks Lakehouse and Data Mesh," we introduced the Data Mesh based on the Databricks Lakehouse. This blog will explore how the Databricks Lakehouse capabilities support Data Mesh from an architectural point of view.
Data Mesh is an architectural and organizational paradigm, not a technology or solution you buy. However, to implement a Data Mesh effectively, you need a flexible platform that ensures collaboration between data personas, delivers data quality, and facilitates interoperability and productivity across all data and AI workloads.
Let's look at how the capabilities of Databricks Lakehouse Platform address these needs.
The basic building block of a data mesh is the data domain, usually comprised of the following components:
- Source data (owned by the domain)
- Self-serve compute resources and orchestration (within Databricks Workspaces)
- Domain-oriented Data Products served to other teams and domains
- Insights ready for consumption by business users
- Adherence to federated computational governance policies
This is depicted in the figure below:
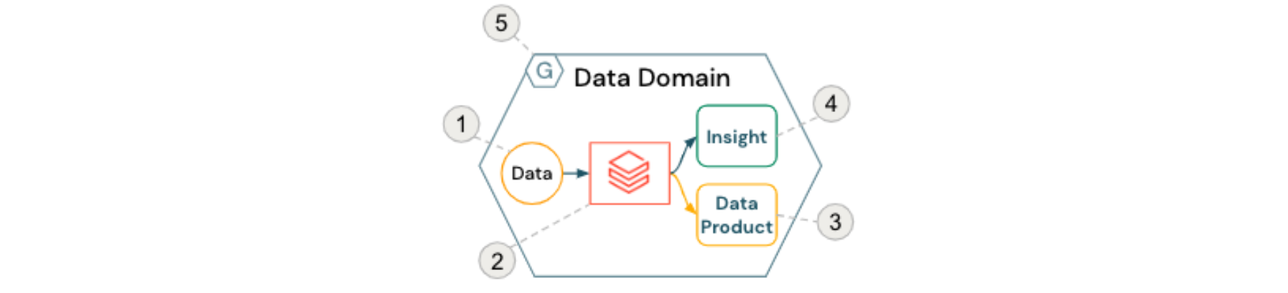
To facilitate cross-domain collaboration and self-service analytics, common services around access control mechanisms and data cataloging are often centrally provided. For example, Databricks Unity Catalog provides not only informational cataloging capabilities such as data discovery and lineage, but also the enforcement of fine-grained access controls and auditing desired by many organizations today.
Data Mesh can be deployed in a variety of topologies. Outside of modern digital-native companies, a highly decentralized Data Mesh with fully independent domains is usually not recommended as it leads to complexity and overhead in domain teams rather than allowing them to focus on business logic and high quality data. Two popular examples often seen in enterprises are the Harmonized Data Mesh and the Hub & Spoke Data Mesh.
1) Approach for a harmonized Data Mesh
A harmonized data mesh emphasizes autonomy within domains:
- Data domains create and publish domain-specific data products
- Data discovery is automatically enabled by Unity Catalog
- Data products are consumed in a peer-to-peer way
- Domain infrastructure is harmonized via
- platform blueprints, ensuring security and compliance
- self-serve platform services (domain provisioning automation, data cataloging, metadata publishing, policies on data and compute resources)
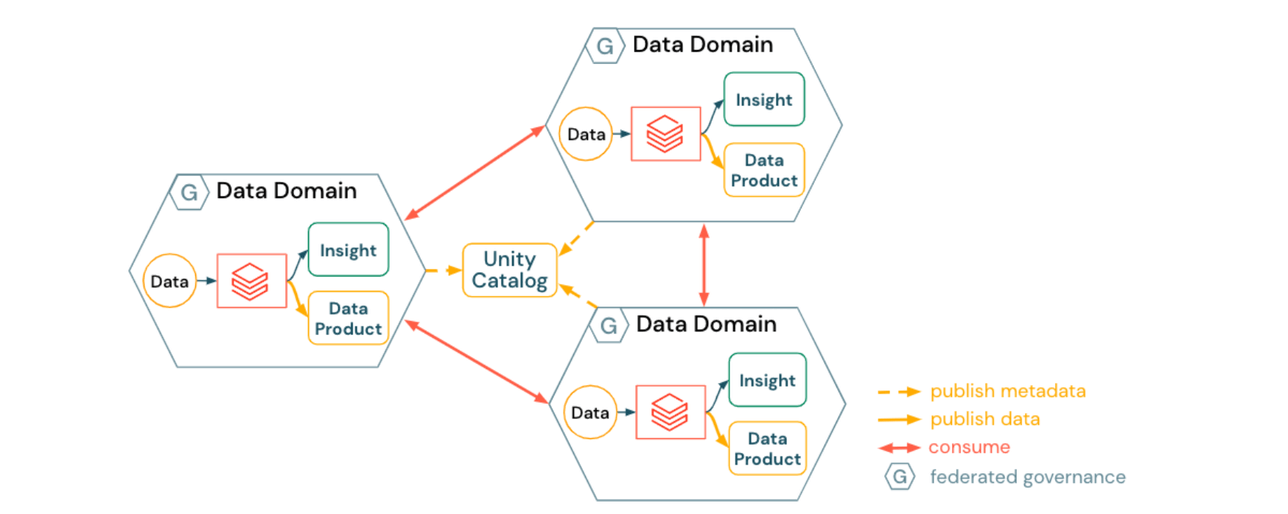
The implications of a harmonized approach may include:
- Data Domains each needing to adhere to standards and best practices for interoperability and infrastructure management
- Data Domains each independently spending more time and effort on topics such as access controls, underlying storage accounts, or even infrastructure (e.g. event brokers for streaming data products)
This approach may be challenging in global organizations where different teams have different breadth and depth in skills and may find it difficult to stay fully in sync with the latest practices and policies.
2) Approach for a Hub & Spoke Data Mesh
A Hub & Spoke Data Mesh incorporates a centralized location for managing shareable data assets and data that does not sit logically within any single domain:
- Data domains (spokes) create domain specific data products
- Data products are published to the data hub, which owns and manages a majority of assets registered in Unity Catalog
- The data hub provides generic services platform operations for data domains such as:
- self-service data publishing to managed locations
- data cataloging, lineage, audit, and access control via Unity Catalog
- data management services such as time travel and GDPR processes across domains (e.g. right to be forgotten requests)
- The data hub can also act as a data domain. For example, pipelines or tools for generic or externally acquired datasets such as weather, market research, or standard macroeconomic data.
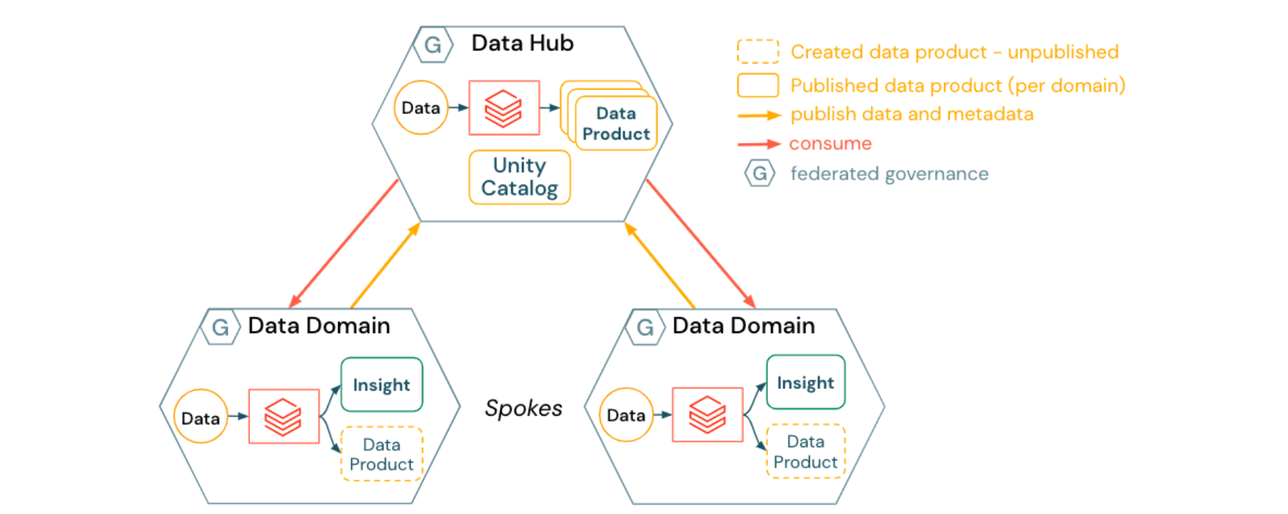
The implications for a Hub and Spoke Data Mesh include:
- Data domains can benefit from centrally developed and deployed data services, allowing them to focus more on business and data transformation logic
- Infrastructure automation and self-service compute can help prevent the data hub team from becoming a bottleneck for data product publishing
In both of these approaches, domains may also have common and repeatable needs such as:
- Data ingestion tools and connectors
- MLOps frameworks, templates, or best practices
- Pipelines for CI/CD, data quality, and monitoring
Having a centralized pool of skills and expertise, such as a center of excellence, can be beneficial both for repeatable activities common across domains as well as for infrequent activities requiring niche expertise that may not be available in each domain.
It is also perfectly feasible to have some variation between a fully harmonized data mesh and a hub-and-spoke model. For example, having a minimal global data hub to only host data assets that do not logically sit in a single domain and to manage externally acquired data that is used across multiple domains. Unity Catalog plays the pivotal role of providing authenticated data discovery wherever data is managed within a Databricks deployment.
Gartner®: Databricks Cloud Database Leader

Scaling and evolving the Data Mesh
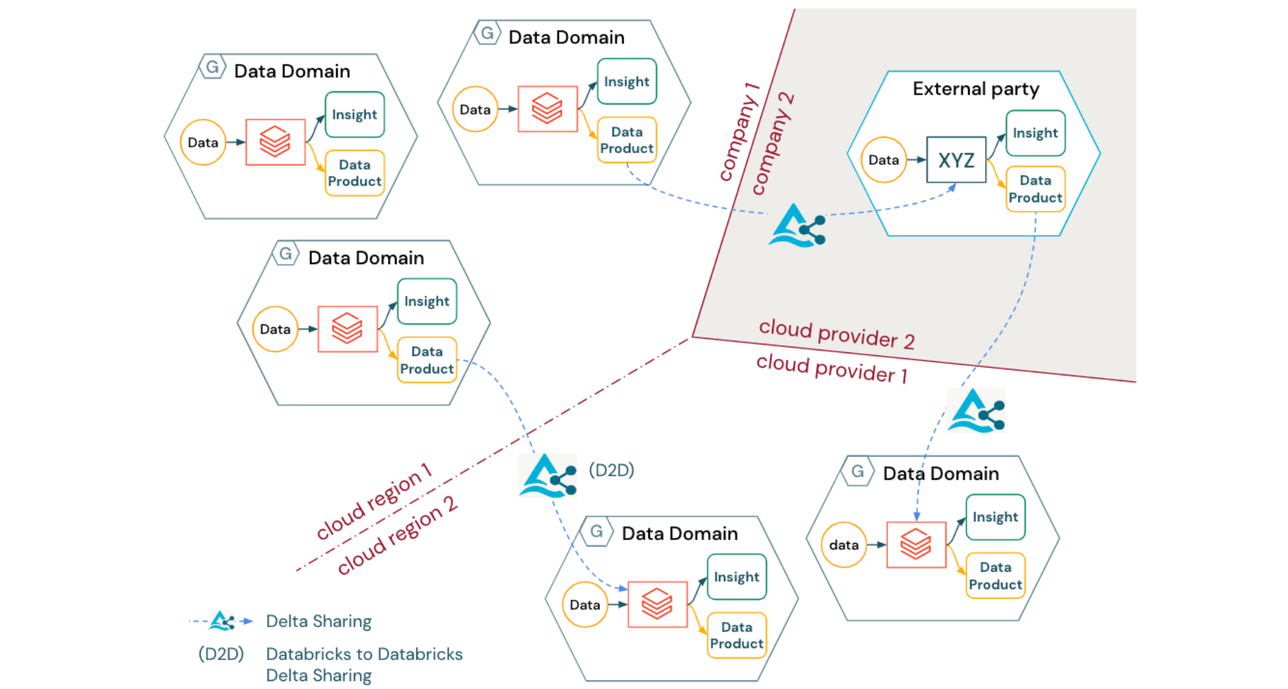
Independent of the type of Data Mesh logical architecture deployed, many organizations will face the challenge of creating an operating model that spans cloud regions, cloud providers, and even legal entities. Furthermore, as organizations evolve towards the productization (and potentially even monetization) of data assets, enterprise-grade interoperable data sharing remains paramount for collaboration not only between internal domains but also across companies.
Delta Sharing offers a solution to this problem with the following benefits:
- Delta Sharing is an open protocol to securely share data products between domains across organizational, regional, and technical boundaries
- The Delta Sharing protocol is vendor agnostic (including a broad ecosystem of clients), providing a bridge between different domains or even different companies without requiring them to use the same technology stack or cloud provider
Concluding remarks
Data Mesh and Lakehouse both arose due to common pain points and shortcomings of enterprise data warehouses and traditional data lakes[1][2]. Data Mesh comprehensively articulates the business vision and needs for improving productivity and value from data, whereas the Databricks Lakehouse provides an open and scalable foundation to meet those needs with maximum interoperability, cost-effectiveness, and simplicity.
In this article, we emphasized two example capabilities of the Databricks Lakehouse platform that improve collaboration and productivity while supporting federated governance, namely:
- Unity Catalog as the enabler for independent data publishing, central data discovery, and federated computational governance in the Data Mesh
- Delta Sharing for large, globally distributed organizations that have deployments across clouds and regions. Delta Sharing efficiently and securely shares fresh, up-to-date data between domains in different organizational boundaries without duplication
However, there are a plethora of other Databricks features that serve as great enablers in the Data Mesh journey for different personas. For example:
- Workflows and Delta Live Tables for high quality self-service data pipelines supporting both batch and streaming workloads
- Databricks SQL allowing performant BI & SQL queries directly on the lake, reducing the need for domain teams to maintain multiple copies/data stores for their data products
- Databricks Feature Store that promotes sharing and reuse between Data Science & Machine Learning teams
To find out more about Lakehouse for Data Mesh: