Cluster Policy Onboarding Primer
Democratizing your data platform with cluster policies
by Anindita Mahapatra and Stephen Carman
Introduction
This blog is part of our Admin Essentials series, where we'll focus on topics important to those managing and maintaining Databricks environments. See our previous blogs on Workspace Organization, Workspace Administration, UC Onboarding, and Cost-Management best practices!
Data becomes useful only when it is converted to insights. Data democratization is the self-serve process of getting data into the hands of people that can add value to it without undue process bottlenecks and without expensive and embarrassing faux pas moments. There are innumerable instances of inadvertent mistakes such as a faulty query issued by a junior data analyst as a "SELECT * from <massive table here>" or maybe a data enrichment process that does not have appropriate join filters and keys. Governance is needed to avoid anarchy for users, ensuring correct access privileges not only to the data but also to the underlying compute needed to crunch the data. Governance of a data platform can be broken into 3 main areas - Governance of Users, Data & Compute.
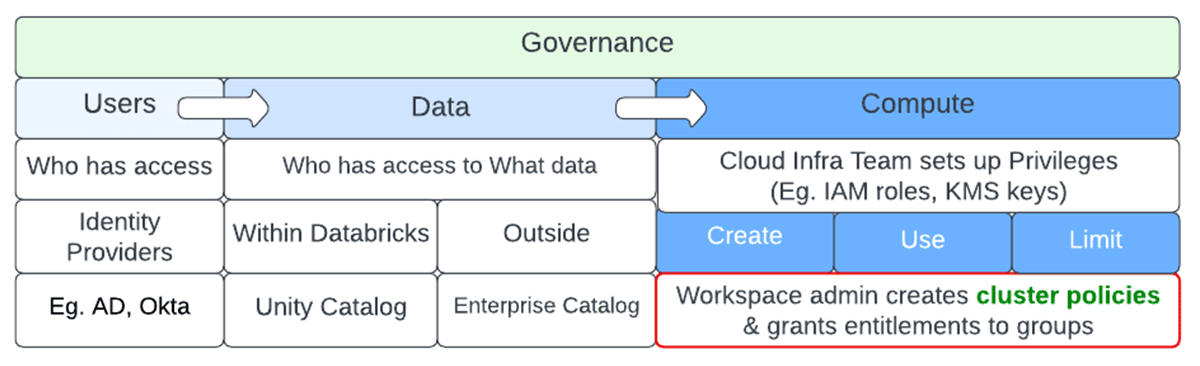
Governance of users ensures the right entities and groups have access to data and compute. Enterprise-level identity providers usually enforce this and this data is synced to Databricks. Governance of data determines who has access to what datasets at the row and column level. Enterprise catalogs and Unity Catalog help enforce that. The most expensive part of a data pipeline is the underlying compute. It usually requires the cloud infra team to set up privileges to facilitate access, after which Databricks admins can set up cluster policies to ensure the right principals have access to the needed compute controls. Please refer to the repo to follow along.
Benefits of Cluster Policies
Cluster Policies serve as a bridge between users and the cluster usage-related privileges that they have access to. Simplification of platform usage and effective cost control are the two main benefits of cluster policies. Users have fewer knobs to try leading to fewer inadvertent mistakes, especially around cluster sizing. This leads to better user experience, improved productivity, security, and administration aligned to corporate governance. Setting limits on max usage per user, per workload, per hour usage, and limiting access to resource types whose values contribute to cost helps to have predictable usage bills. Eg. restricted node type, DBR version with tagging and autoscaling. (AWS, Azure, GCP)
Cluster Policy Definition
On Databricks, there are several ways to bring up compute resources - from the Clusters UI, Jobs launching the specified compute resources, and via REST APIs, BI tools (e.g. PowerBI will self-start the cluster), Databricks SQL Dashboards, ad-hoc queries, and Serverless queries.
A Databricks admin is tasked with creating, deploying, and managing cluster policies to define rules that dictate conditions to create, use, and limit compute resources at the enterprise level. Typically, this is adapted and tweaked by the various Lines of Business (LOBs) to meet their requirements and align with enterprise-wide guidelines. There is a lot of flexibility in defining the policies as each control element offers several strategies for setting bounds. The various attributes are listed here.
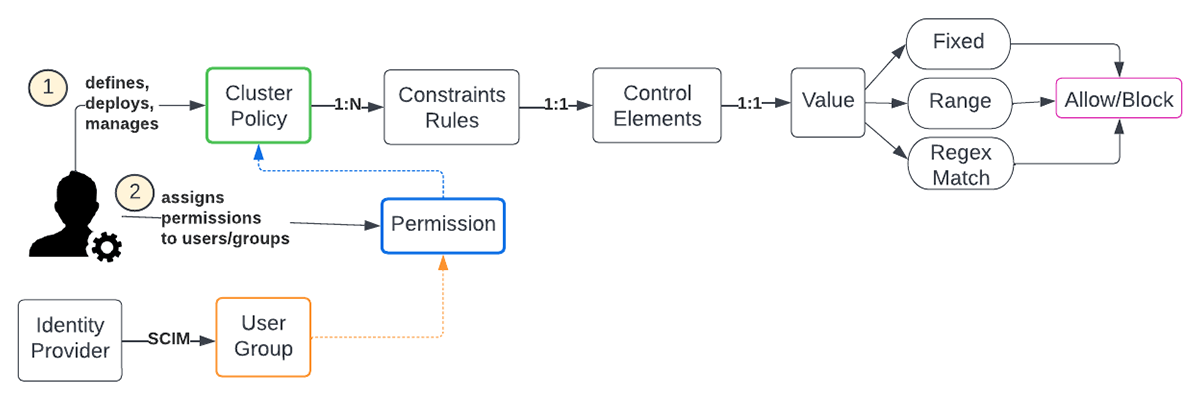
Workspace admins have permission to all policies. When creating a cluster, non-admins can only select policies for which they have been granted permission. If a user has cluster create permission, then they can also select the Unrestricted policy, allowing them to create fully-configurable clusters. The next question is how many cluster policies are considered sufficient and what is a good set, to begin with.
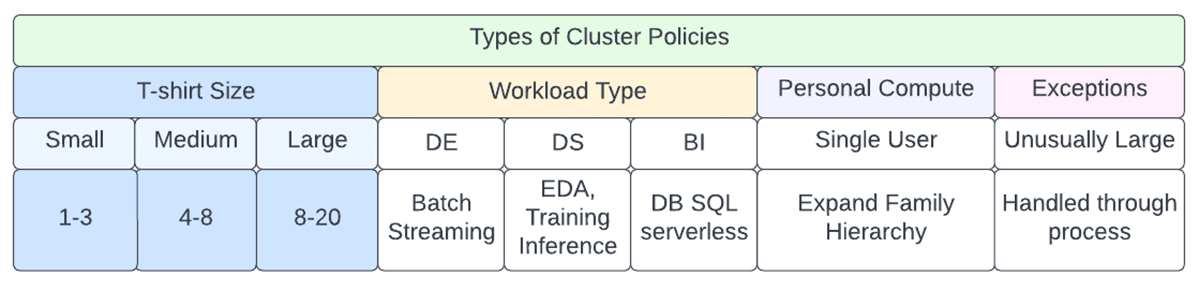
There are standard cluster policy families that are provided out of the box at the time of workspace deployment (These will eventually be moved to the account level) and it is strongly recommended to use them as a base template. When using a policy family, policy rules are inherited from the policy family. A policy may add additional rules or override inherited rules.
The ones that are currently offered include
- Personal Compute & Power User Compute (single user using all-purpose cluster)
- Shared Compute (multi-user, all-purpose cluster)
- Job Compute (job Compute)
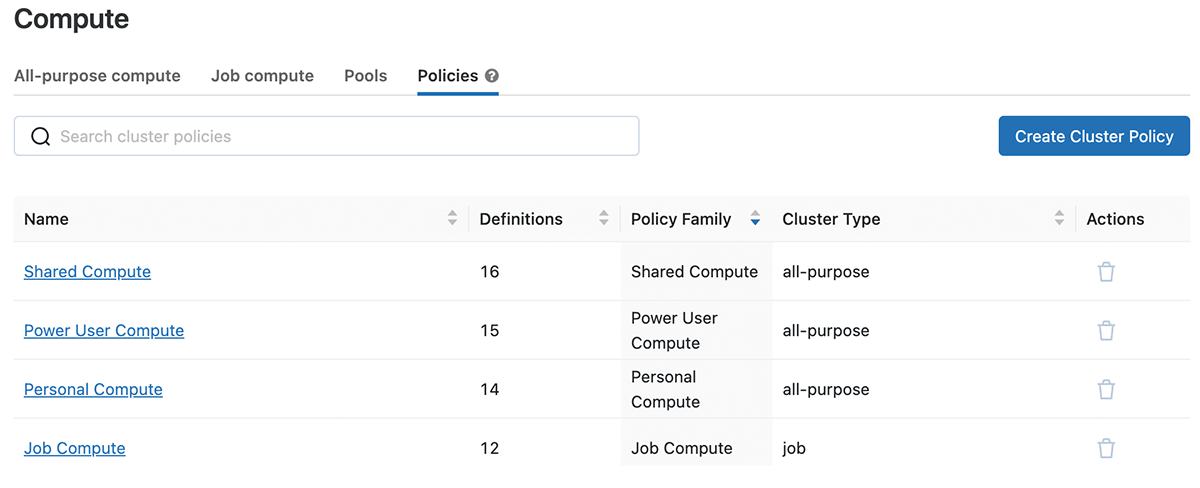
Clicking into one of the policy families, you can see the JSON definition and any overrides to the base, permissions, clusters & jobs with which it is associated.

There are 4 cluster families that come predefined that you can use as-is and supplement with others to suit the varied needs of your organization. Refer to the diagram below to plan the initial set of policies that need to be in place at an enterprise level taking into consideration workload type, size, and persona involved.
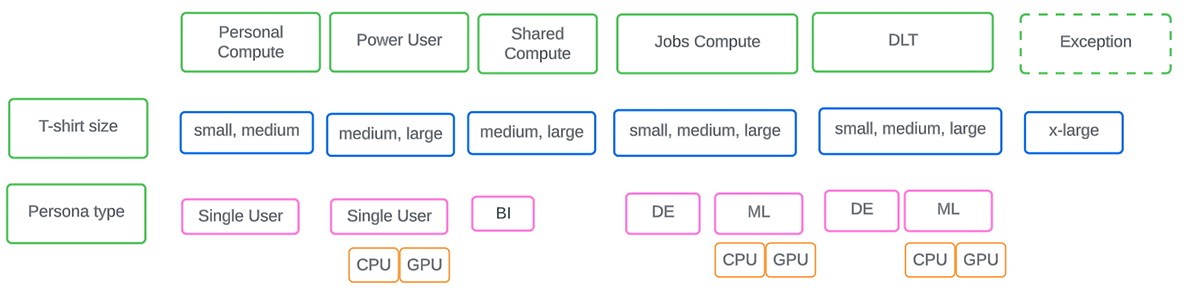
Rolling out Cluster Policies in an enterprise

- Planning: Articulate enterprise governance goals around controlling the budget, and usage attribution via tags so that cost centers get accurate chargebacks, runtime versions for compatibility and support requirements, and regulatory audit requirements.
- The 'unrestricted' cluster policy entitlement provides a backdoor route for bypassing the cluster policies and should be suppressed for non-admin users. This setting is provided in the workspace settings for users. In addition, consider providing only 'Can Restart' for interactive clusters for most users.
- The process should handle exception scenarios eg. requests for an unusually large cluster using a formal approval process. Key success metrics should be defined so that the effectiveness of the cluster policies can be quantified.
- A good naming convention helps with self-describing and management needs so that a user instinctively knows which one to use and an admin recognizes which LOB it belongs to. For eg. mkt_prod_analyst_med denotes the LOB, environment, persona, and t-shirt size.
- Budget Tracking API (Private Preview) feature allows account administrators to configure periodic or one-off budgets for Databricks usage and receive email notifications when thresholds are exceeded.
- Defining: The first step is for a Databricks admin to enable Cluster Access Control for a premium or higher workspace. Admins should create a set of base cluster policies that are inherited by the LOBs and adapted.
- Deploying: Cluster Policies should be carefully considered prior to rollout. Frequent changes are not ideal as it confuses the end users and does not serve the intended purpose. There will be occasions to introduce a new policy or tweak an existing one and such changes are best done using automation. Once a cluster policy has been changed, it affects subsequently created compute. The "Clusters" and "Jobs" tabs list all clusters and jobs using a policy and can be used to identify clusters that may be out-of-sync.
- Evaluating: The success metrics defined in the planning phase should be evaluated on an ongoing basis to see if some tweaks are needed both at the policy and process levels.
- Monitoring: Periodic scans of clusters should be done to ensure that no cluster is being spun up without an associated cluster policy.
Cluster Policy Management & Automation
Cluster policies are defined in JSON using the Cluster Policies API 2.0 and Permissions API 2.0 (Cluster policy permissions) that manage which users can use which cluster policies. It supports all cluster attributes controlled with the Clusters API 2.0, additional synthetic attributes such as max DBU-hour, and a limit on the source that creates a cluster.
The rollout of cluster policies should be properly tested in lower environments before rolling to prod and communicated to the teams in advance to avoid inadvertent job failures on account of inadequate cluster-create privileges. Older clusters running with prior versions need a cluster edit and restart to adopt the newer policies either through the UI or REST APIs. A soft rollout is recommended for production, wherein in the first phase only the tagging part is enforced, once all groups give the green signal, move to the next stage. Eventually, remove access to unrestricted policies for restricted users to ensure there is no backdoor to bypass cluster policy governance. The following diagram shows a phased rollout process:

Automation of cluster policy rollout ensures there are fewer human errors and the figure below is a recommended flow using Terraform and Github
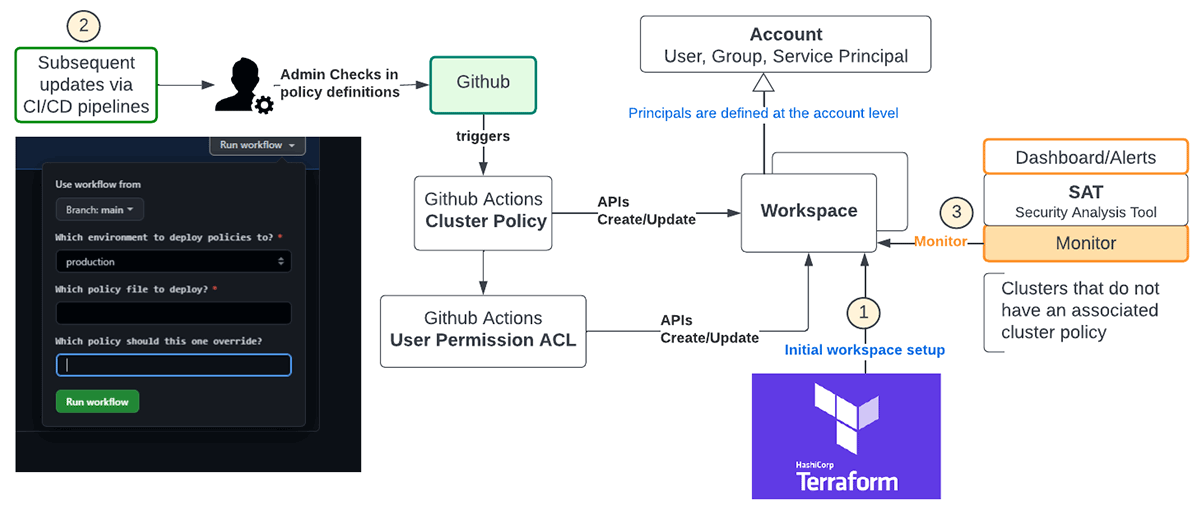
- Terraform is a multi-cloud standard and should be used for deploying new workspaces and their associated configurations. For example, this is the template for instantiating these policies with Terraform, which has the added benefit of maintaining state for cluster policies.
- Subsequent updates to policy definitions across workspaces should be managed by admin personas using CI/CD pipelines. The diagram above shows Github workflows managed via Github actions to deploy policy definitions and the associated user permissions into the chosen workspaces.
- REST APIs can be leveraged to monitor clusters in the workspace either explicitly or implicitly using the SAT tool to ensure enterprise-wide compliance.
Delta Live Tables (DLT)
DLT simplifies the ETL processes on Databricks. It is recommended to apply a single policy to both the default and maintenance DLT clusters. To configure a cluster policy for a pipeline, create a policy with the cluster_type field set to dlt as shown here.
External Metastore
If there is a need to attach to an admin-defined external metastore, the following template can be used.
Serverless
In the absence of a serverless architecture, cluster policies are managed by admins to expose control knobs to create, manage and limit compute resources. Serverless will likely alleviate this responsibility off the admins to a certain extent. Regardless, these knobs are necessary to provide flexibility in the creation of compute to match the specific needs and profile of the workload.
Summary
To summarize, Cluster Policies have enterprise-wide visibility and enable administrators to:
- Limit costs by controlling the configuration of clusters for end users
- Streamline cluster creation for end users
- Enforce tagging across their workspace for cost management
CoE/Platform teams should plan to roll these out as they have the potential of bringing in much-needed governance, and yet if not done properly, they can be completely ineffective. This isn't just about cost savings but about guardrails that are important for any data platform.
Here are our recommendations to ensure effective implementation:
- Start out with the preconfigured cluster policies for three popular use cases: personal use, shared use, and jobs, and extend those by t-shirt size and persona type to address workload needs.
- Clearly define the naming and tagging conventions so that LOB teams can inherit and modify the base policies to suit their scenarios.
- Establish the change management process to allow new ones to be added or older ones to be tweaked.
Please refer to the repo for examples to get started and deploy Cluster Policies
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.