Databricks on Databricks: Kicking off the Journey to Governance with Unity Catalog
We transformed the largest Databricks workspace into a governed lakehouse in 10 months, using Unity Catalog

As the Data Platform team at Databricks, we leverage our own platform to provide an intuitive, composable, and comprehensive Data and AI platform to internal data practitioners so that they can safely analyze usage and improve our product and business operations. As our company matures, we are especially motivated to establish data governance to enable secure, compliant and cost-effective data operations. With thousands of employees and hundreds of teams analyzing data, we have to frame and implement consistent standards to achieve data governance at scale and continued compliance. We identified Unity Catalog (UC), generally available as of August 2022, as the foundation for establishing standard governance practices and thus migrating 100% of our internal lakehouse to Unity Catalog became a top company priority.
Why migrate to Unity Catalog to achieve Data Governance?
Data migrations are HARD - and expensive. So we asked ourselves: Can we achieve our governance goals without migrating all the data to Unity Catalog?
We had been using the default Hive Metastore (HMS) in Databricks to manage all of our tables. Building our own data governance features from scratch on top of HMS would be a wasteful endeavor, setting us back multiple quarters. Unity Catalog, on the other hand, provided tremendous value out of the box:
- Any data on HMS was readable by anybody. UC securely supports fine-grained access.
- HMS does not provide lineage or audit logs. Lineage support is crucial to understanding data flows and empowering effective data lifecycle management. In combination with audit logs, this provides observability about data changes and propagation.
- With better integration with the in-product search feature, UC enables a better experience for users to annotate and discover high-quality data.
- Delta Sharing, query federation and catalog binding provide effective options to create cross-region data meshes without creating security or compliance risks.
Unity Catalog migration starts with a governance strategy
At a high level, we could go down one of two paths:
- Lift-and-shift: Copy all the schemas and tables as is from legacy HMS to a UC catalog while giving everybody read access to all data. This path is low level of effort in the short term. However, we risk bringing along outdated datasets and incoherent/bad practices motivated by HMS or organic growth. The probability of needing multiple large subsequent migrations to clean in place would be high.
- Transformational: Selectively migrate datasets while establishing a core structure for data organization in Unity Catalog. While this path requires more effort in the short term, it provides a vital course-correction opportunity. Subsequent rounds of incremental (smaller) clean-up may be necessary.
We chose the latter. It allowed us to lay the groundwork to introduce future governance policy while providing the requisite skeleton to build around. We built infrastructure to enable paved paths that ensured clear data ownership, naming conventions and intentional access, as opposed to opening access to all employees by default.
One such example is the catalog organization strategy we chose upfront:
| Catalog | Purpose | Governance |
|---|---|---|
| Users | Individual user spaces (schemas) |
|
| Team | Collaborative spaces for users who work together |
|
| Integration | Space for specific integration projects across teams |
|
| Main | Production environment. |
|
Challenges
Our internal data lake had become more of a "data swamp" over time, due to the previously highlighted lack of lineage and access controls in HMS. We did not have answers to 3 basic questions critical to any migration:
- Who owns table foo?
- Are all the tables upstream of foo already migrated to the new location?
- Who are all the downstream customers of table foo that need to be updated?
Now imagine that lack of visibility at the scale of our data lake:
Now imagine a four-person engineering team pulling this off without any dedicated program management support in 10 months.
Gartner®: Databricks Cloud Database Leader

Our Approach
The migration can practically be broken down into 4 phases.
Phase 1: Make a Plan, by Unlocking Lineage for HMS
We collaborated with the Unity Catalog and Discovery teams to build data a lineage pipeline for HMS on internal Databricks workspaces. This allowed us to ascertain the following:
A. Who updated a table and when?
B. Who reads from a table and when?
C. Whether the data was consumed via a dashboard, a query, a job or a notebook?
A allowed us to infer the most likely owners of the tables. B and C helped establish the "blast radius" of an imminent migration i.e., who are all the downstream consumers to notify and which ones are mission critical? Additionally, B allowed us to estimate how much "stale" data was lying around in the data lake that could be simply ignored (and eventually deleted) to simplify the migration.
This observability was critical in estimating the overall migration effort, creating a realistic timeline for the company and informing what tooling, automation and governance policies our team needed to invest in.
After proving its utility internally, we now provide our customers a path to enable HMS Lineage for a limited period of time to assist with the migration to Unity Catalog. Talk to your account representative to enable it.
Phase 2: Stop the Bleeding, by Enforcing Data Retention
Lineage observability revealed two critical insights:
- There were a ton of "stale" tables in the data lake, that had not been consumed in a while, and were probably not worth migrating
- The new table creation rate on HMS was fairly high. This had to be brought down significantly (almost 0) for us to successfully cutover to Unity Catalog eventually and have a shot at a successful migration.
These insights led us to invest in data retention infrastructure upfront and roll out the following policies, which turbo-charged our effort.
- Garbage-Collect Stale Data: This policy, shipped right out of the gates, deleted any HMS table that wasn't updated for 30 days. We provided teams with a grace period to register exemptions. This greatly reduced the size of the "haystack" and allowed data practitioners to focus on data that actually mattered.
- No New Tables in HMS: A quarter after the migration was underway and there was company-wide awareness, we rolled out a policy to prevent the creation of any new HMS tables. While keeping the legacy metastore in check, this measure effectively placed a moratorium on data pipelines still on HMS as they could no longer be extended or modified to produce new tables.
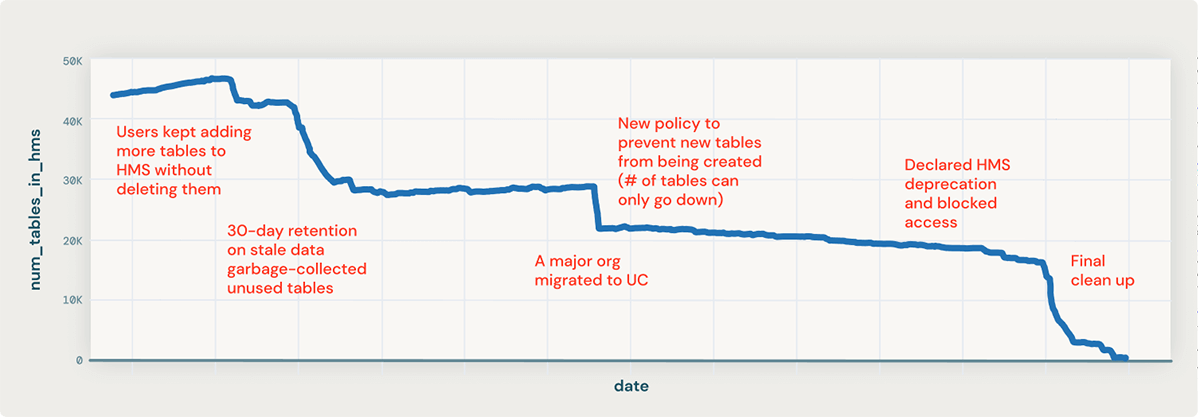
With these in place, we were no longer chasing a moving target.
Phase 3: Distribute the work, using Self-Serve Tracking Tools
Most organizations in the company have a different cadence for planning, different processes for tracking execution and different priorities and constraints. As a small data platform team, our goal was to minimize coordination and empower teams to confidently estimate, coordinate, and track their OWN dataset migration efforts. To this end, we turned the lineage observability data into executive-level dashboards, where each team could understand the outstanding work on their plate, both as data producers and consumers, ordered by importance. These allowed further drill-downs to the manager and individual contributor levels. These were updated on a daily cadence for progress-tracking purposes.
Additionally, the data was aggregated into a leaderboard, allowing leadership to have visibility and apply pressure when required. The global tracking dashboard also served the dual purpose of a lookup table where consumers could find the locations of new tables migrated to Unity Catalog.
The emphasis on managing the people and process dynamics of the Databricks organization was a crucial success driver. Every organization is different and tailoring your approach to your company is key to your success.
Phase 4: Tackle the Long Tail, using Automation
Effectively herding the long tail is make or break for a migration with 2.5K data consumers and over 50K consuming entities across every team of the company. Relying on data producers or our small platform team to track and chase down all these consumers to do their part by the deadline was a non-starter.
Under the moniker "Migration Wizard", we built a data platform that allowed data producers to register the tables to be deleted or migrated to a catalog in Unity Catalog. Along with the table paths (new and old), producers provided operational metadata like the end-of-life (EOL) date for the legacy table and how to contact with questions or concerns.
The Migration Wizard would then:
- Leverage lineage to detect consumption and notify downstream teams. This targeted approach allowed teams to not have to repeatedly inundate everybody with data deprecation messages
- On EOL day, render a "soft deletion" via loss of access and purge the data a week later
- Auto-update DBSQL queries depending on the legacy data to read from the new location
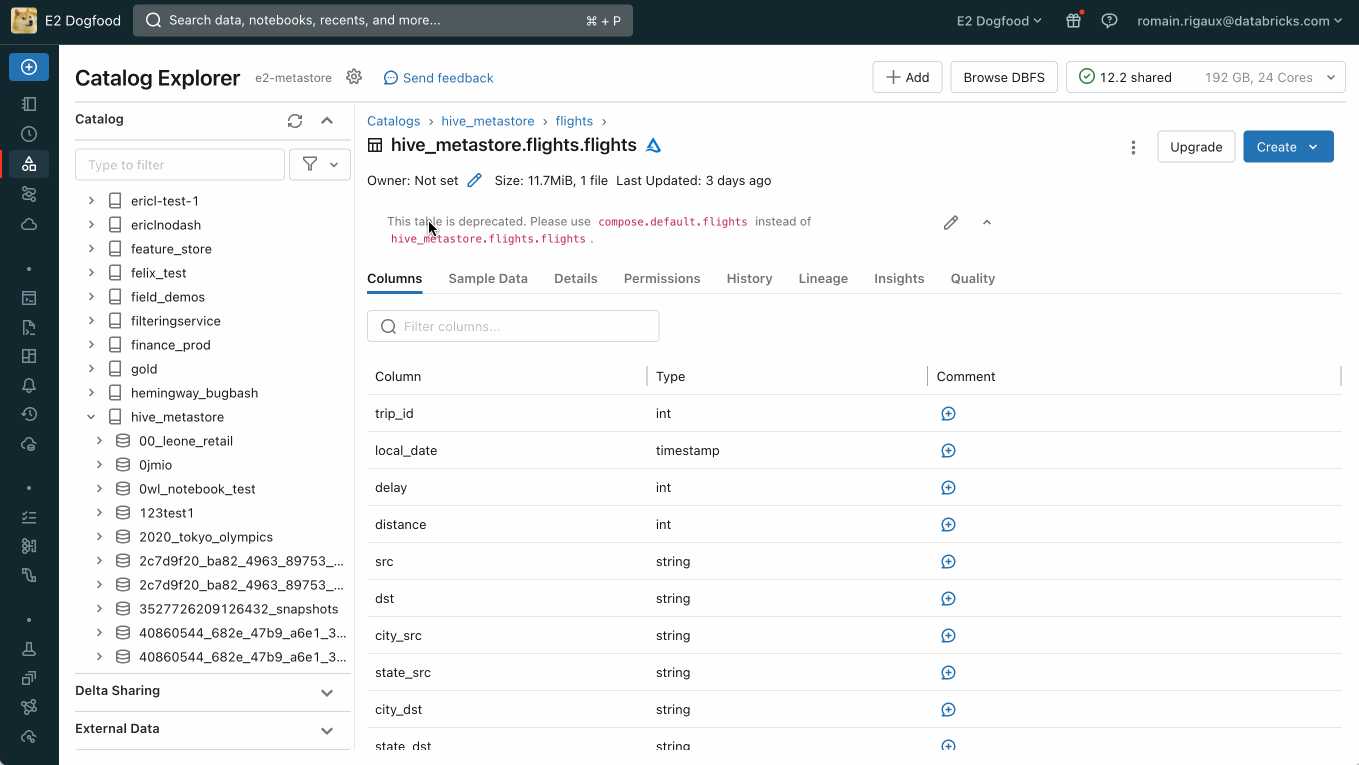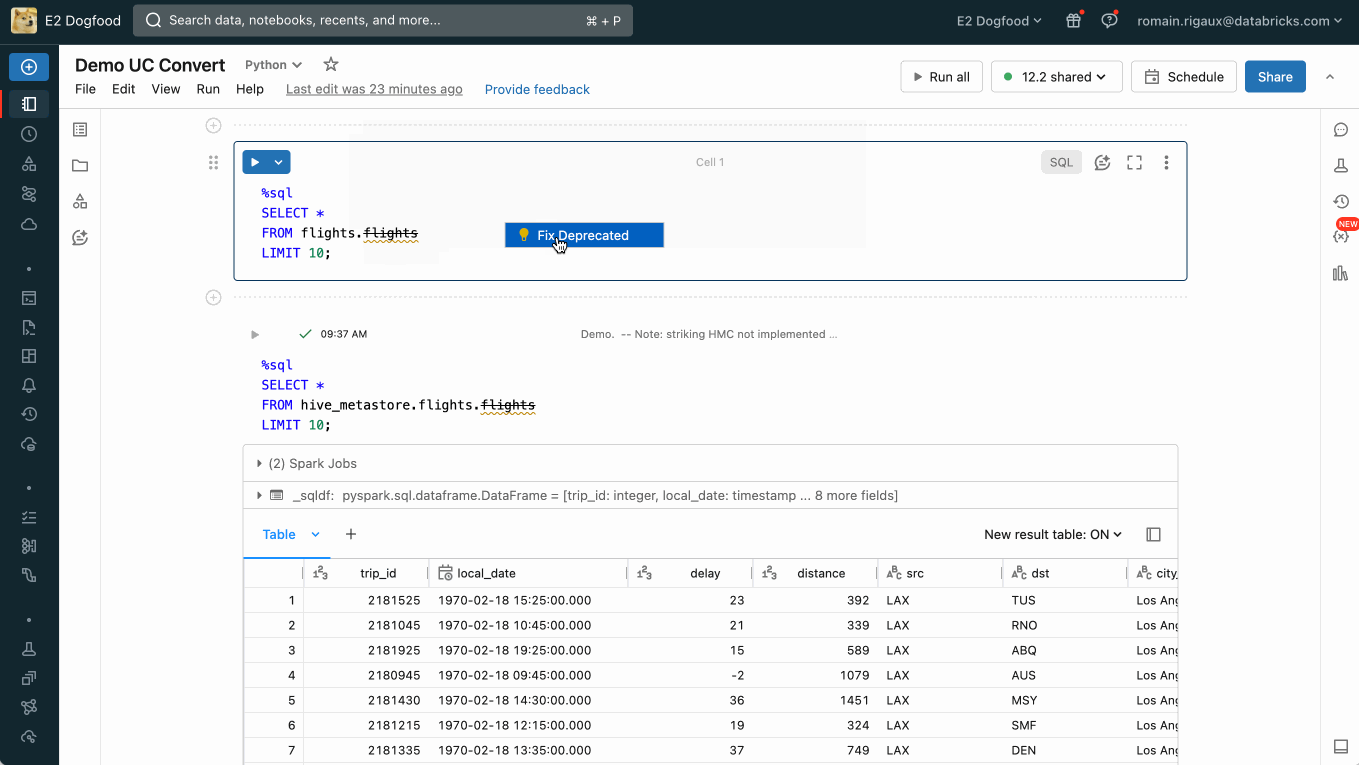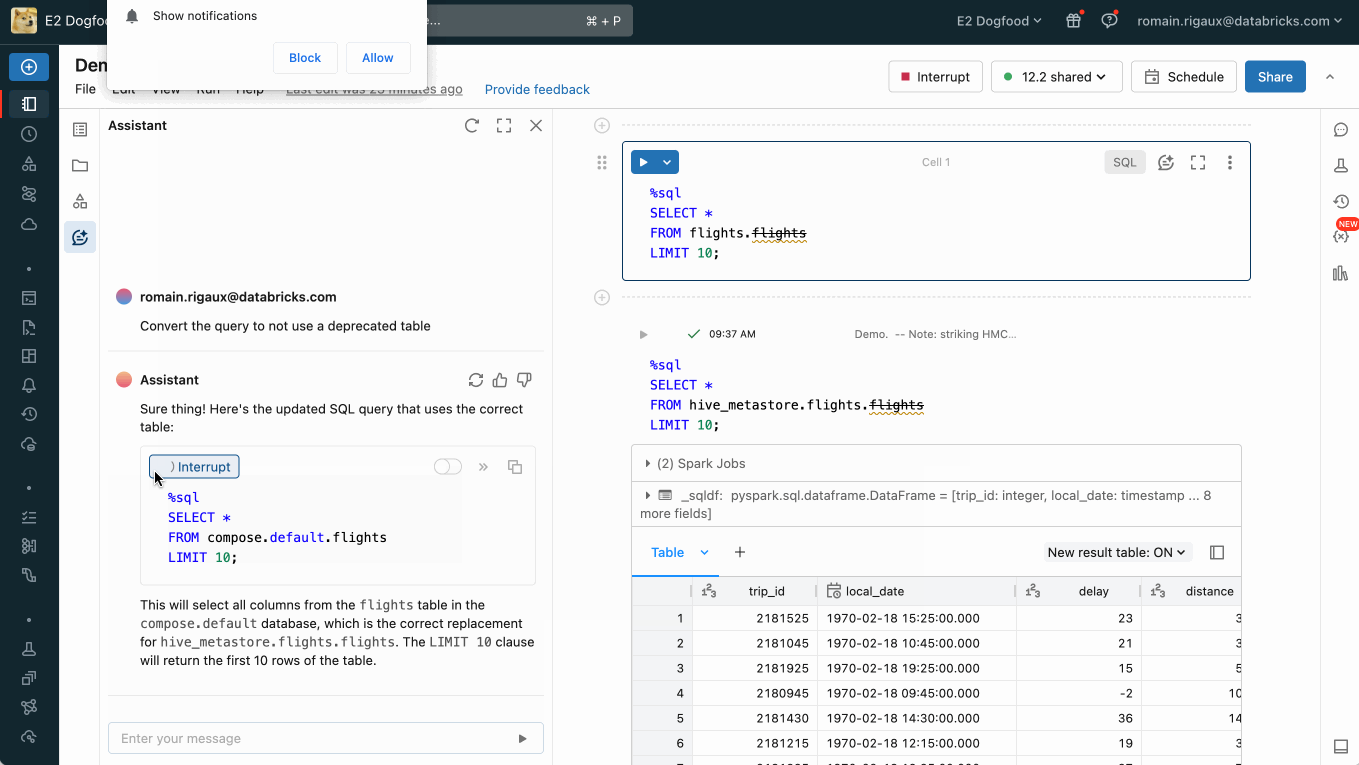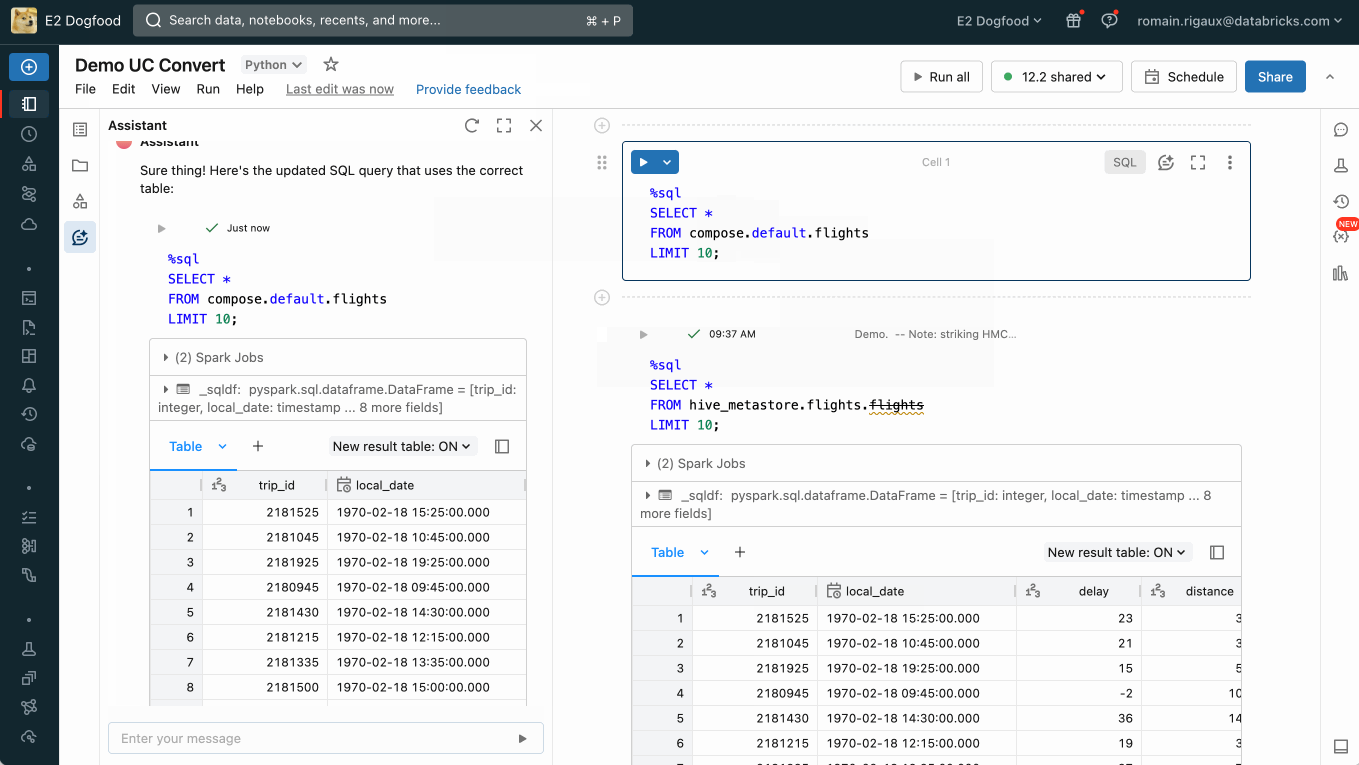
Thus with a few lines of config, the data producer was effectively and confidently decoupled from the migration effort without having to worry about downstream impact. Automation continued notifying customers and also provided a swift fix for query breakage discovered after the deprecation trigger was pulled.
Subsequently, the ability to auto-update DBSQL and notebook queries from legacy HMS tables to new UC alternatives has been added to the product to assist our customers in their journey to Unity Catalog.
Sticking the Landing
In February 2024, we removed access to Hive Metastore and started deleting all remaining legacy data. Given the amount of communication and coordination, this potentially disruptive change turned out to be smooth. Our changes did not trigger any incidents, and we were able to declare "Success" soon after.
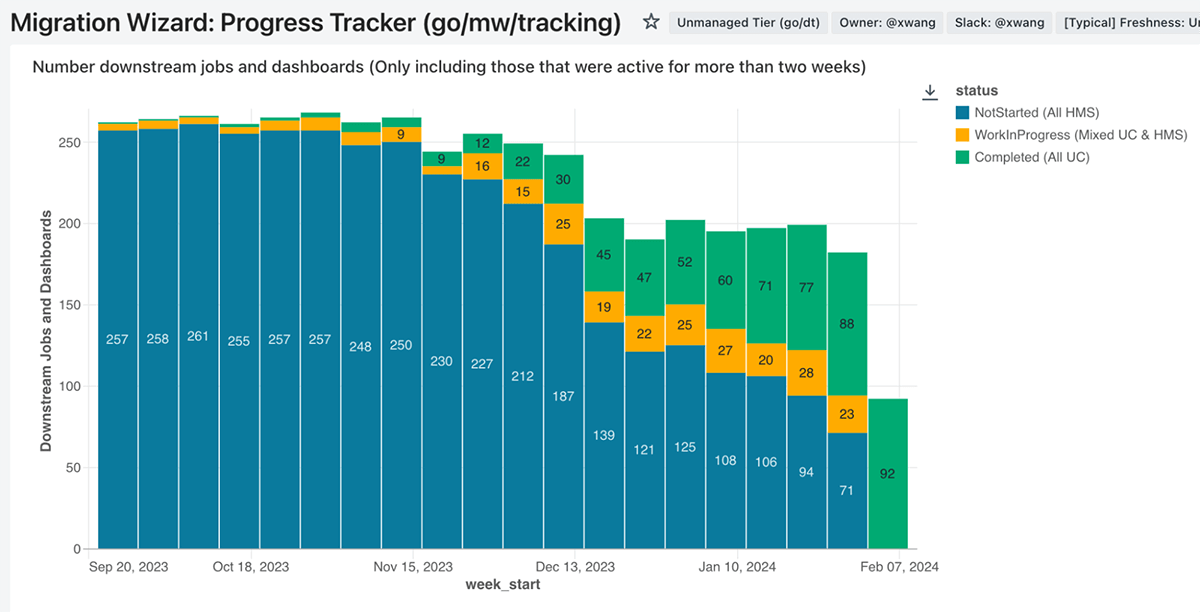
We saw immediate cost benefits as unowned jobs that failed due to the changes could now be turned off. Dashboards silently deprecated now failed while incurring marginal compute cost and could be similarly sunsetted.
A critical objective was to identify features to make migration to Unity Catalog easier for Databricks customers. The Unity Catalog and other product teams gathered extensive actionable feedback for product improvements. The Data Platform team prototyped, proposed and architected various features that will be rolling out to customers shortly.
The Journey Continues
The move to Unity Catalog unshackled data practitioners, significantly reducing data sprawl and unlocking new features. For example, the Marketing Analytics team saw a 10x reduction in tables managed via a lineage-enabled identification (and deletion) of deprecated datasets. Access management improvements and lineage, on the other hand, have enabled powerful one-click access obtainment paths and access reduction automation.
For more on this, check out our talk on unified governance @ Data + AI Summit 2024. In future blogs in this series, we will also dive deeper into governance decisions. Stay tuned for more about our journey to Data Governance!
We would like to thank Vinod Marur, Sam Shah and Bruce Wong for their leadership and support and Product Engineering @ Databricks—especially Unity Catalog and Data Discovery—for their continued partnership in this journey.