Databricks Power BI Connector Now Supports Native Query
by Moe Derakhshani, Can Efeoglu, Mahesh Prakriya and Bob Zhang
This is a collaborative post from Databricks and Microsoft. We thank Mahesh Prakriya (Director in Intelligence Platform, Microsoft) and Bob Zhang (Sr. Technical Program Manager, Microsoft) for their contributions.
We're excited to announce the availability of native queries in the Databricks Power BI Connector in the latest release of Power BI! Native query support has been one of the most frequently requested features for the connector since its launch. With this new capability, customers can now access data in Databricks SQL and build data models with increased flexibility and productivity. Customers can specify native SQL queries as part of setting up their data sources. Any query specified here will be executed natively against Databricks SQL before further steps in Power BI.
Why native SQL?
Flexibility with complex transformations
Native SQL also provides flexibility for users to pick and choose their ideal tool for a given transformation. DAX is expressive and powerful, but for more complex SQL queries or unsupported operations, using native SQL query enables a simpler workflow. This also provides a big benefit for cases where custom column definitions cannot be folded/pushed down – just build them in the native SQL.
Take better advantage of Databricks SQL compute scale
With native SQL support, customers can now perform larger operations and compute intensive preparation queries against a Databricks SQL Warehouse directly as part of setting up a data source. Especially for more complex transformations this could save a considerable amount of time. Also, analysts can self-service without having to create Views or other constructs within Databricks for simpler workflows.
Simpler migrations from other Power Query sources
For customers who already use custom/native SQL with other data sources in Power BI, migrating to Databricks SQL used to be cumbersome. The solution until now was to map this to Views in Databricks or attempt to do the logic in DAX. Now this is as simple as specifying the relevant native SQL query on Databricks Power BI connector.
How to get started?
You need the following to get started
- Power BI December 2022 Release (v2.112.603.0 or later)
- A Databricks account (sign up here if you do not already have an account)
Open Power BI Desktop and follow the instructions:
- Find "Azure Databricks" or "Databricks" datasource from Power BI "Get Data" menu.
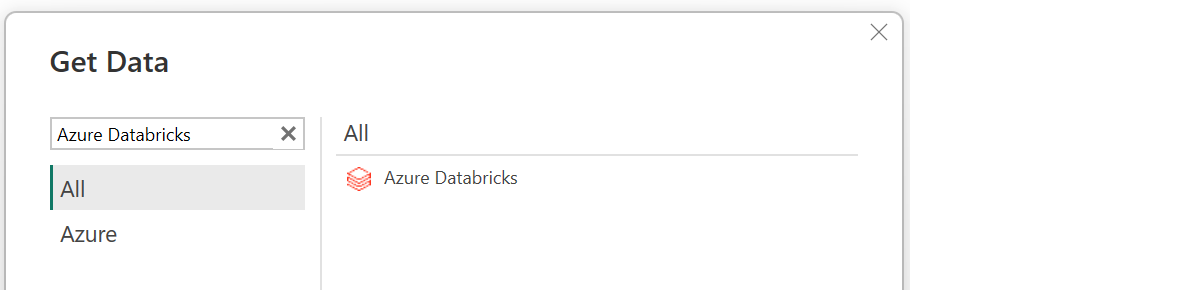
- Fill in Server and Catalog details in the connection dialog.
- Enter the native SQL query you'd like to submit. In this case:
Note that to use the native query feature, the catalog field is required and must be provided, and the native query has to be written to be relative to the provided catalog.
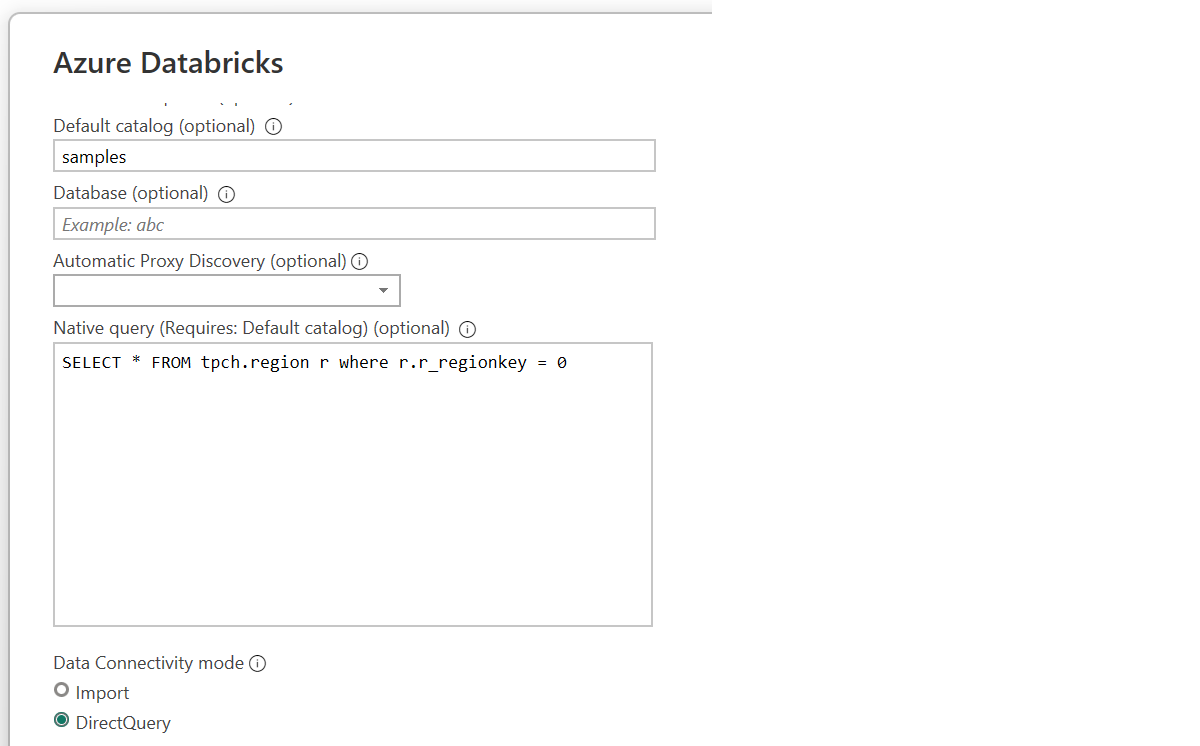
- Once you authenticate, you are ready to query! Both Direct Query or Import modes are supported.
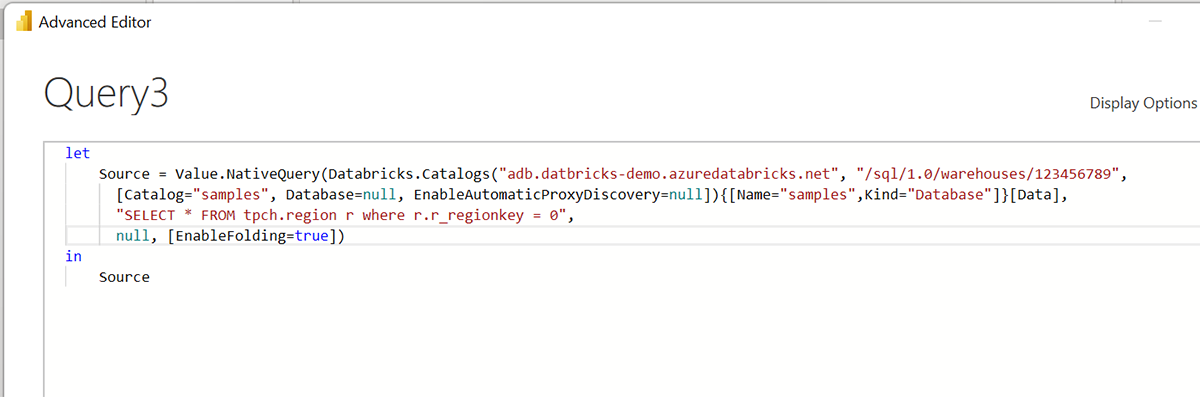
- (Optional) Open the query using Power BI Advanced Query Editor, so you can see the native query and if you like you can modify the query from here and save it.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.