Deep Dive: How Row-level Concurrency Works Out of the Box
Use Liquid Clustering for automatic concurrent conflict resolution
Summary
- Databricks row-level concurrency provides out-of-the-box concurrency guarantees for customers with concurrent writes and maintenance operations.
- Traditional concurrency methods, such as retry loops and partitioning, are hard to use and can increase query times and cost.
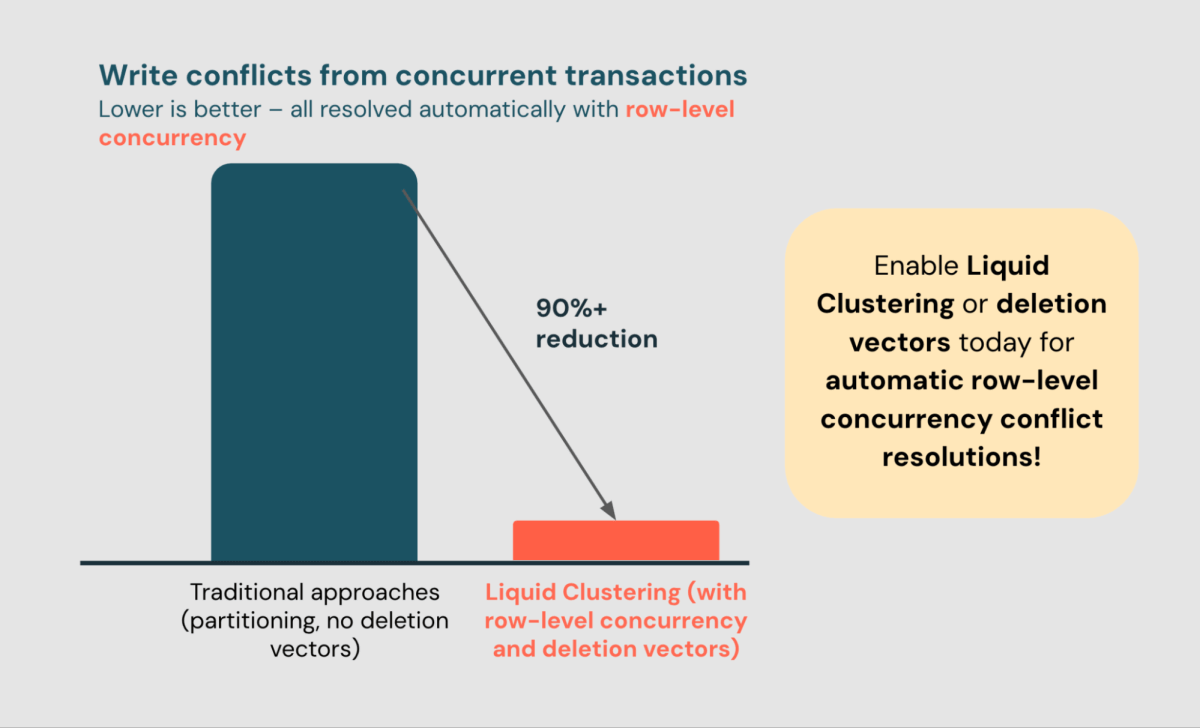
- Start benefiting from row-level concurrency today by using Liquid Clustering.
Liquid Clustering is an innovative data management technique that significantly simplifies your data layout-related decisions. You only have to choose clustering keys based on query access patterns. Thousands of customers have benefited from better query performance with Liquid Clustering, and we now have 3000+ active monthly customers writing 200+ PB data to Liquid-clustered tables per month.
If you are still using partitioning to manage multiple writers, you are missing out on a key feature of Liquid Clustering: row-level concurrency.
In this blog post, we’ll explain how Databricks delivers out-of-the-box concurrency guarantees for customers with concurrent modifications on their tables. Row-level concurrency lets you focus on extracting business insights by eliminating the need to design complex data layouts or coordinate workloads, simplifying your code and data pipelines.
Row-level concurrency is automatically enabled when you use Liquid Clustering. It is also enabled with deletion vectors when using Databricks Runtime 14.2+. If you have concurrent modifications that frequently fail with ConcurrentAppendException or ConcurrentUpdateException, enable Liquid Clustering or deletion vectors on your table today to have row-level conflict detection and reduce conflicts. Getting started is simple:
Read on for a deep dive into how row-level concurrency automatically handles concurrent writes modifying the same file.
Traditional approaches: hard to manage and error-prone
Concurrent writes occur when multiple processes, jobs, or users simultaneously write to the same table. These are common in scenarios such as continuous writes from multiple streams, different pipelines ingesting data into a table, or background operations like GDPR deletes. Managing concurrent writes is even more cumbersome when managing maintenance tasks – you have to schedule your OPTIMIZE around business workloads.
Delta Lake ensures data integrity during these operations using optimistic concurrency control, which provides transactional guarantees between writes. This means that if two writes conflict, only one will succeed, while the other will fail to commit.
Let’s consider this example: two writers from two different sources, e.g. sales in the US and the UK, attempt at the same time to merge into the global sales number table, that is partitioned by date – a common partitioning pattern we see from customers managing large datasets. Suppose that sales from the US are written to the table with streamA, while sales from the UK are written with streamB.
Here, if streamA stages its commits first and streamB tries to modify the same partition, Delta Lake will reject streamB's write at commit time with a concurrent modification exception, even when the two streams actually modify different rows. This is because with partitioned tables, conflicts are detected at the granularity of partitions. As a result, the writes from streamB are lost and a lot of compute was wasted.
To handle these conflicts, customers can redesign their workloads using retry loops, which attempt streamB’s write again. However, retry logic can lead to increased job duration response times and compute costs by repeatedly attempting the same write, until the commit is successful. Finding the right balance is tricky—too few retries risk failures, while too many cause inefficiency and high costs.
Another approach is more fine-grained partitioning, but managing more fine-grained table partitions to isolate writes is also difficult, especially when multiple teams write to the same table. Choosing the right partition key is challenging, and partitioning doesn’t work for all data patterns. Moreover, partitioning is inflexible – you have to rewrite the entire table when changing partitioning keys to adapt to evolving workloads.
In this example, customers could rewrite the table and partition by both date and country so that each stream writes on a separate partition, but this can cause small file issues. This happens when some countries generate a large amount of sales data while others produce very little—a data pattern that is very common.
Liquid Clustering avoids all these small files issues, while row-level concurrency gives you concurrency guarantees on the row level, which is even more granular and more flexible than partitioning. Let’s dive in to see how row-level concurrency works!
How row-level concurrency provides hands-free, automatic concurrent conflict resolutions
Row-level concurrency is an innovative technique in the Databricks Runtime that detects write conflicts at the row level. For Liquid-clustered tables, the capability automatically resolves conflicts between modification operations such as MERGE, UPDATE, and DELETE as long as the operations do not read or modify the same rows.
In addition, for all tables with deletion vectors enabled – including Liquid-clustered tables, it guarantees that maintenance operations like OPTIMIZE and REORG won't interfere with other write operations. You no longer have to worry about designing for concurrent write workloads, making your workloads on Databricks even simpler.
Using our example, with row-level concurrency, both streams can successfully commit their modifications to the sales data as long as they are not modifying the same row – even if the rows are stored in the same file.
Gartner®: Databricks Cloud Database Leader

Behind the Scenes of Row-level Concurrency: How it Works
How does this work? The Databricks Runtime automatically reconciles concurrent modifications during commit time. It uses deletion vectors (DV) and row tracking, features of Delta Lake, to keep track of changes performed in each transaction and reconcile modifications efficiently.
Using our example, when the new sales data is written to the table, the new data are inserted into a new data file, while the old rows are marked as deleted using deletion vectors without needing to rewrite the original file. Let’s zoom in to the file level, to see how row-level concurrency works with deletion vectors.
For example, we have a file A with four rows, row 0 through row 3. Transaction 1 (T1) from streamA tries to delete row 3 in file A. Instead of rewriting file A, the Databricks Runtime marks row 3 as deleted in the deletion vector for file A, denoted as DV for A.
Now transaction 2 (T2) comes in from streamB. Let’s say this transaction tries to delete row 0. With deletion vectors, File A remains unchanged. Instead, DV for A now tracks that row 0 is deleted. Without row-level concurrency, this would cause a conflict with transaction 1 because both are trying to modify the same file or deletion vector.
With row-level concurrency, conflict detection in the Databricks Runtime identifies that the two transactions affect different rows. Since there is no logical conflict, the Databricks Runtime can reconcile the concurrent modifications in the same files by combining the Deletion Vectors from both transactions.
With all these innovations, Databricks has the only lakehouse engine, across all formats, that offers row-level concurrency in the open Delta Lake format. Other engines adopt locking in their proprietary formats, which can result in queueing and slow write operations, or you have to rely on cumbersome partition-based concurrency methods for your concurrent writes.
In the past year, row-level concurrency has helped 6,500+ customers resolve 110B+ conflicts automatically, reducing write conflicts by 90%+ (the remaining conflicts are caused by touching the same row).
Get started today
Row-Level Concurrency is enabled automatically with Liquid Clustering in Databricks Runtime 13.3+ with no knobs! In Databricks Runtime 14.2+, it is also enabled by default with all unpartitioned tables that have deletion vectors enabled.
If your workloads are already using Liquid Clustering, you are all set! If not, adopt Liquid Clustering, or enable deletion vectors on your unpartitioned tables to unlock the benefits of row-level concurrency.