Delivering cost-effective data in real time with dbt and Databricks
As businesses grow, data volumes scale from GBs to TBs (or more), and latency demands go from hours to minutes (or less), making it increasingly more expensive to provide fresh insights back to the business. Historically, Python and Scala data engineers have turned to streaming to meet these demands, efficiently processing new data in real-time, but analytics engineers who needed to scale SQL-based dbt pipelines didn't have this option.
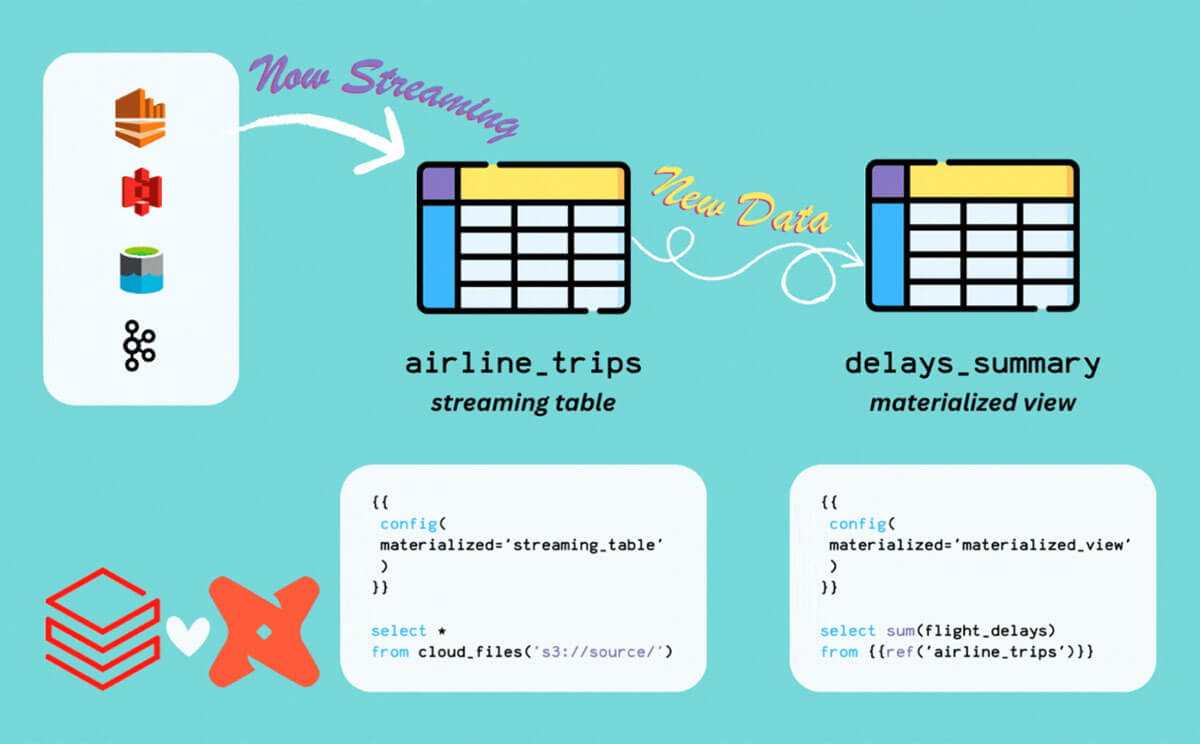
No longer! This blog seeks to illustrate how we can use the new Streaming Tables and Materialized Views on Databricks to deliver fresh, real-time insights to businesses with the simplicity of SQL and dbt.
Background
At the 2023 Data + AI Summit, we introduced Streaming Tables and Materialized Views into Databricks SQL. This awesome capability gave Databricks SQL users easy access to powerful new table materializations first introduced within Delta Live Tables, allowing them to incrementalize large queries, stream straight from event data sources and more.
In addition to natively using Streaming Tables and Materialized Views within a Databricks environment, they also work for dbt users on Databricks. dbt-databricks has become one of the most popular ways to build data models on Databricks, leveraging all of the powerful capabilities of Databricks SQL, including the Photon compute engine, instantly scaling Serverless SQL Warehouses and the Unity Catalog governance model, with the ubiquity of dbt's transformation framework.
What's changed in dbt-databricks?
As of dbt v1.6+, dbt-databricks has evolved in three key facets:
- New materializations: "streaming_table" and "materialized_view"
- New syntax to read directly from cloud data storage without staging your sources as a table
- Access to advanced streaming concepts such as window aggregations, watermarking and stream-stream joins
Note: Keep an eye out for the upcoming dbt v1.7.3 release which will further refine the above capabilities!
Let's take a look at how we can use these new features with the Airline Trips demo.
The Airline Trips demo
The Airline Trips demo was created to demonstrate how to incrementally ingest and transform live event data for up-to-date business insights on Databricks, be it a dashboard or an AI model. The dataset represents all airline trips being taken in the United States over time, capturing the delays to departures and arrivals for each trip.
An included helper notebook establishes a simulated stream from this dataset while the dbt project showcases a data model that takes these raw json events and transforms them via streaming ETL into a layer of Materialized Views, feature tables and more.
The repository is publicly available here, and leverages sample data packaged in all Databricks workspaces out-of-the-box. Feel free to follow along!

Gartner®: Databricks Cloud Database Leader

Ingesting data from cloud data storage
One of the simplest ways to start leveraging Streaming Tables is for data ingestion from cloud data storage, like S3 for AWS or ADLS for Azure. You may have an upstream data source generating event data at a high volume, and a process to land these as raw files into a storage location, typically json, csv, parquet or avro.
In our demo, imagine we receive a live feed of every airline trip taken in the United States from an external party, and we want to ingest this incrementally as it comes.
Instead of staging the files as an external table, or using a 3rd party tool to materialize a Delta Table for the data source, we can simply use Streaming Tables to solve this. Take the model below for our bronze airline trips feed:
The two key points to note are:
- The materialization strategy is set to 'streaming_table'
- This will run a CREATE OR REFRESH STREAMING TABLE command in Databricks
- The syntax to read from cloud storage leverages Auto Loader under the hood
- read_files() will list out new json files in the specified folder and start processing them. Since we're using dbt, we've taken advantage of the var() function in dbt to pass an s3 folder path dynamically (of the form "s3://…")
- The STREAM keyword indicates to stream from this location. Alternatively, without it we can still use read_files() with materialized='table' to do a batch read straight from the specified folder
As an aside, while Auto Loader requires the least setup, you can also stream straight from an event streaming platform like Kafka, Kinesis or Event Hubs for even lower latency using very similar syntax. See here for more details.
Incrementally enriching data for the silver layer
Streaming does not have to stop at the ingestion step. If we want to perform some joins downstream or add a surrogate key, but want to restrict it to new data only to save on compute, we can continue to use the Streaming Table materialization. For example, take the snippet from our next model for the silver, enriched airlines trips feed, where we join mapping tables for airport codes into the raw data set:
Once again, we've made use of the Streaming Table materialization, and have been able to leverage standard dbt functionality for all of our logic. This includes:
- Leveraging the dbt_utils package for handy shortcuts like generating a surrogate key
- Using the ref() statement to maintain full lineage
The only real change to our SQL was the addition of the STREAM() keyword around the ref() statement for airline_trips_bronze, to indicate that this table is being read incrementally, while the airport_codes table being joined is a mapping table that is read in full. This is called a stream-static join.
Crafting a compute-efficient gold layer with Materialized Views
With our enriched silver tables ready, we can now think about how we want to serve up aggregated insights to our end business consumers. Typically if we use a table materialization, we would have to recompute all historical results every time.
To take advantage of the Streaming Tables upstream that only process new data in each run, we turn instead to Materialized Views for the task!
The good news in Databricks is that a model that builds a Materialized View looks no different than a model that builds a table! Take our example for a gold layer Materialized View to calculate the percentage of delayed flights each day:
All we changed was the materialization config!
Remember, Materialized Views can be incrementally refreshed when there are changes to the base tables. In the above scenario, as we stream new data, the Materialized View determines which groups require re-calculation and only computes these, leaving unchanged aggregations as-is and reducing overall compute costs. This is easier to visualize in the example as we aggregate over ArrDate, the arrival date of flights, meaning new days of data will naturally fall into new groups and existing groups will remain unchanged.
Analyzing the event logs of the Materialized View (pictured below) after several runs of the model, we can see the incrementalization at work. The first run is a full computation like any table, but a second run to update the aggregations with new data leverages a row-wise incremental refresh. A final run of the model recognised that no new data had been ingested upstream and simply did nothing.

What else can I expect in the demo repository?
We've covered the basics of getting data straight from the event source all the way to a BI-ready Materialized View, but the demo repository contains so much more.
Included in the repository are examples of how to monitor logs for Streaming Tables and Materialized Views to understand how data is being processed, as well as an advanced example not covered in this blog of how to join two streams together in a stream-stream join just with SQL!
Clone in the repo to your Databricks environment to get started, or connect up dbt Cloud to Databricks at no additional cost with partner connect. You can also learn more with the documentation for Materialized Views and Streaming Tables.