Easy Ingestion to Lakehouse With COPY INTO

A new data management architecture known as the data lakehouse emerged independently across many organizations and use cases to support AI and BI directly on vast amounts of data. One of the key success factors for using the data lakehouse for analytics and machine learning is the ability to quickly and easily ingest data of various types, including data from on-premises storage platforms (data warehouses, mainframes), real-time streaming data, and bulk data assets.
As data ingestion into the lakehouse is an ongoing process that feeds the proverbial ETL pipeline, you will need multiple options to ingest various formats, types and latency of data. For data stored in cloud object stores such as AWS S3, Google Cloud Storage and Azure Data Lake Storage, Databricks offers Auto Loader, a natively integrated feature, that allows data engineers to ingest millions of files from the cloud storage continuously. In other streaming cases (e.g., IoT sensor or clickstream data), Databricks provides native connectors for Apache Spark Structured Streaming to quickly ingest data from popular message queues, such as Apache Kafka, Azure Event Hubs or AWS Kinesis at low latencies. Furthermore, many customers can leverage popular ingestion tools that integrate with Databricks, such as Fivetran - to easily ingest data from enterprise applications, databases, mainframes and more into the lakehouse. Finally, analysts can use the simple "COPY INTO" command to pull new data into the lakehouse automatically, without the need to keep track of which files have already been processed.
This blog focuses on COPY INTO, a simple yet powerful SQL command that allows you to perform batch file ingestion into Delta Lake from cloud object stores. It's idempotent, which guarantees to ingest files with exactly-once semantics when executed multiple times, supporting incremental appends and simple transformations. It can be run once, in an ad hoc manner, and can be scheduled through Databricks Workflows. In recent Databricks Runtime releases, COPY INTO introduced new functionalities for data preview, validation, enhanced error handling, and a new way to copy into a schemaless Delta Lake table so that users can get started quickly, completing the end-to-end user journey to ingest from cloud object stores. Let's take a look at the popular COPY INTO use cases.
1. Ingesting data for the first time
COPY INTO requires a table to exist as it ingests the data into a target Delta table. However, you have no idea what your data looks like. You first create an empty Delta table.
Before you write out your data, you may want to preview it and ensure the data looks correct. The COPY INTO Validate mode is a new feature in Databricks runtime 10.3 and above, that allows you to preview and validate source data before ingesting many files from the cloud object stores. These validations include:
- if the data can be parsed
- the schema matches that of the target table or if the schema needs to be evolved
- all nullability and check constraints on the table are met
The default for data validation is to parse all the data in the source directory to ensure that there aren't any issues, but the rows returned for preview are limited. Optionally, you can provide the number of rows to preview after VALIDATE.
The COPY_OPTION "mergeSchema" specifies that it is okay to evolve the schema of your target Delta table. Schema evolution only allows the addition of new columns, and does not support data type changes for existing columns. In other use cases, you can omit this option if you intend to manage your table schema more strictly as your data pipeline may have strict schema requirements and may not want to evolve the schema at all times. However, our target Delta table in the example above is an empty, columnless table at the moment; therefore, we have to specify the COPY_OPTION "mergeSchema" here.
2. Configuring COPY INTO
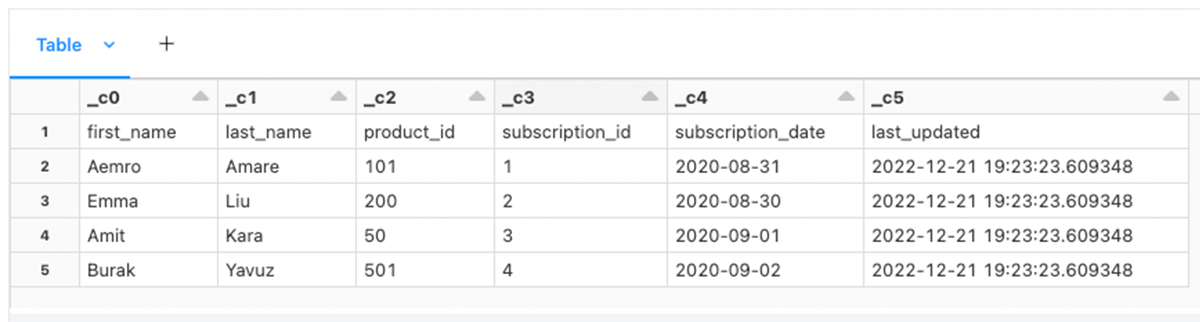
When looking over the results of VALIDATE (see Figure 1), you may notice that your data doesn't look like what you want. Aren't you glad you previewed your dataset first? The first thing you notice is the column names are not what is specified in the CSV header. What's worse, the header is shown as a row in your data. You can configure the CSV parser by specifying FORMAT_OPTIONS. Let's add those next.
When using the FORMAT OPTION, you can tell COPY INTO to infer the data types of the CSV file by specifying the inferSchema option; otherwise, all default data types are STRINGs. On the other hand, binary file formats like AVRO and PARQUET do not need this option since they define their own schema. Another option, "mergeSchema" states that the schema should be inferred over a comprehensive sample of CSV files rather than just one. The comprehensive list of format-specific options can be found in the documentation.
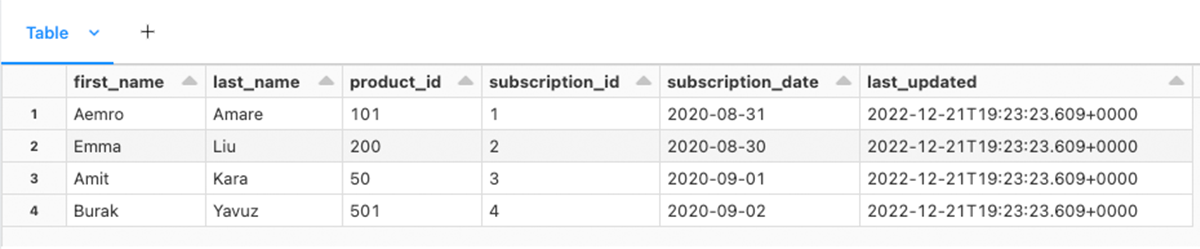
Figure 2 shows the validate output that the header is properly parsed.
3. Appending data to a Delta table
Now that the preview looks good, we can remove the VALIDATE keyword and execute the COPY INTO command.
COPY INTO keeps track of the state of files that have been ingested. Unlike commands like INSERT INTO, users get idempotency with COPY INTO, which means users won't get duplicate data in the target table when running COPY INTO multiple times from the same source data.
COPY INTO can be run once, in an ad hoc manner, and can be scheduled with Databricks Workflows. While COPY INTO does not support low latencies for ingesting natively, you can trigger COPY INTO through orchestrators like Apache Airflow.
4. Secure data access with COPY INTO
COPY INTO supports secure access in several ways. In this section, we want to highlight two new options you can use in both Databricks SQL and notebooks from recent releases:
Unity Catalog
With the general availability of Databrick Unity Catalog, you can use COPY INTO to ingest data to Unity Catalog managed or external tables from any source and file format supported by COPY INTO. Unity Catalog also adds new options for configuring secure access to raw data, allowing you to use Unity Catalog external locations or storage credentials to access data in cloud object storage. Learn more about how to use COPY INTO with Unity Catalog.
Temporary Credentials
What if you have not configured Unity Catalog or instance profile? How about data from a trusted third party bucket? Here is a convenient COPY INTO feature that allows you to ingest data with inline temporary credentials to handle the ad hoc bulk ingestion use case.
Gartner®: Databricks Cloud Database Leader

5. Filtering files for ingestion
What about ingesting a subset of files where the filenames match a pattern? You can apply glob patterns - a glob pattern that identifies the files to load from the source directory. For example, let's filter and ingest files which contain the word `raw_data` in the filename below.
6. Ingest files in a time period
In data engineering, it is frequently necessary to ingest files that have been modified before or after a specific timestamp. Data between two timestamps may also be of interest. The 'modifiedAfter' and 'modifiedBefore' format options offered by COPY INTO allow users to ingest data from a chosen time window into a Delta table.
7. Correcting data with the force option
Because COPY INTO is by default idempotent, running the same query against the same source files more than once has no effect on the destination table after the initial execution. You must propagate changes to the target table because, in real-world circumstances, source data files in cloud object storage may be altered for correction at a later time. In such a case, it is possible to first erase the data from the target table before ingesting the more recent data files from the source. For this operation you only need to set the copy option 'force' to 'true'.
8. Applying simple transformations
What if you want to rename columns? Or the source data has changed and a previous column has been renamed to something else. You don't want to ingest that data as two separate columns, but as a single column. We can leverage the SELECT statement in COPY INTO perform simple transformations.
9. Error handling and observability with COPY INTO
Error handling:
How about ingesting data with file corruption issues? Common examples of file corruption are:
- Files with an incorrect file format
- Failure to decompress
- Unreadable files (e.g. invalid Parquet)
COPY INTO's format option ignoreCorruptFiles helps skip those files while processing. The result of the COPY INTO command returns the number of files skipped in the num_skipped_corrupt_files column. In addition, these corrupt files aren't tracked by the ingestion state in COPY INTO, therefore they can be reloaded in a subsequent execution once the corruption is fixed. This option is available in Databricks Runtime 11.0+.
You can see which files have been detected as corrupt by running COPY INTO in VALIDATE mode.
Observability:
In Databricks Runtime 10.5, file metadata column was introduced to provide input file metadata information, which allows users to monitor and get key properties of the ingested files like path, name, size and modification time, by querying a hidden STRUCT column called _metadata. To include this information in the destination, you must explicitly reference the _metadata column in your query in COPY INTO.
How does it compare to Auto Loader?
COPY INTO is a simple and powerful command to use when your source directory contains a small number of files (i.e., thousands of files or less), and if you prefer SQL. In addition, COPY INTO can be used over JDBC to push data into Delta Lake at your convenience, a common pattern by many ingestion partners. To ingest a larger number of files both in streaming and batch we recommend using Auto Loader. In addition, for a modern data pipeline based on medallion architecture, we recommend using Auto Loader in Delta Live Table pipelines, leveraging advanced capabilities of automatic error handling, quality control, data lineage and setting expectations in a declarative approach.
How to get started?
To get started, you can go to Databricks SQL query editor, update and run the example SQL commands to ingest from your cloud object stores. Check out the options in No. 4 to establish secure access to your data for querying it in Databricks SQL. To get familiar with COPY INTO in Databricks SQL, you can also follow this quickstart tutorial.
As an alternative, you can use this notebook in Data Science & Engineering and Machine Learning workspaces to learn most of the COPY INTO features in this blog, where source data and target Delta tables are generated in DBFS.
More tutorials for COPY INTO can be found here.