Even Santa Claus has AI fever
How the North Pole embraced data + AI with Databricks

As CEO of the North Pole, Santa Claus oversees one of the world’s most complicated supply chain, manufacturing and logistics operations.
Every year, Santa, Chief Operating Officer Mrs. Claus, and their team of elves have to read millions of letters from children around the world, check them against the “naughty or nice” list, register the gifts they want and then build millions of presents that all must be delivered in just a single night. While Santa and his crew make it look easy, it’s an operational nightmare and one that remains a largely manual effort. That’s why, like most other business leaders, Santa was eager to see how AI could help. So he turned to Databricks for help.
Using Databricks tools like the Foundation Model APIs, along with techniques including synthetic data generation and named entity recognition, we created a model that could analyze the children’s letters to Santa to pull out the present each kid wants, alleviating the elves from having to read each one individually.
Below we walk through how we used the Databricks’ Data Intelligence Platform to create an AI model that can accomplish in minutes what previously took weeks of work. It’s a blueprint that every company can follow to use AI to help create personalized communications or improve customer support, among other applications.
What is synthetic data and why is it important?
Synthetic data is artificially generated data that is designed to mimic real-world data. And it will play a big role in AI’s future. In fact, by 2024, 60% of all training data will be synthetic, according to Gartner.
AI requires an immense amount of data. Like the North Pole, most organizations simply don’t have enough of their information to accomplish what they want with Generative AI; for example, fine-tuning an existing commercial large language model (LLM) or developing their own. Other organizations may not be able to obtain the necessary sensitive or domain-specific information – like financial or medical records – that they need. All companies want to ensure that they have enough diversity in their datasets. It’s why synthetic data will become increasingly vital.
Synthetic data has significant advantages, namely that it’s cheap and very organized, two characteristics that are harder to find in real-world data sets. It can also be more secure, as it enables enterprises to rely less on customer data, which is increasingly under attack by hackers. Additionally, synthetic data can be more diverse and help fill gaps that companies may have in their own sets, helping to make the end AI models more accurate and reliable.
However, there are some limitations. There are often nuances in real-world information that are hard to replicate with synthetic data, yet vital to the performance of the model. It’s like a self-driving car driving perfectly during a simulation, then making mistakes when subjected to actual human drivers.
How did we do it?
Utilizing the recently launched Foundation Models APIs in Databricks, we asked Meta’s Llama2 70B model with MosaicML Inference to generate the most popular children’s names in North America over the past 20 years, as well as 2023’s most popular gift themes for children ages 5-15. (For the latter, we had to put some parameters around the query to control for abnormal responses, like avoiding home decor or travel-related items – this is commonly referred to as prompt engineering.)
We then took the string output from Llama2, formatted it in Python, and created a Delta table that randomly paired a child’s name with one of the gift categories. That gave us the synthetic input data we needed to start creating the letters to Santa. Initially, we used a Pandas dataframe to serially query Llama2 to generate these letters. However, this process took over an hour to complete. Using the Databricks’ DI Platform, we were able to create 1000 letters in less than five minutes. That’s because, with Apache Spark, we could input multiple names and corresponding gift categories to the underlying foundational model simultaneously.
We then wanted to pull out information from each letter to help the elves build the right gifts, including specific items the children may have listed. Using a process called Named Entity Recognition (NER) we scanned all 1000 letters to pull out words like “coding kit” or “skateboard.” A branch of natural language processing, NER is a process to draw out information based on certain parameters like dates, objects or people’s names. This helps save immense time in summarizing large volumes of text, like user comments or product descriptions.
For the North Pole, we used Llama2 to identify the specific features that we wanted to draw out from the letters: a person’s name, location, date and specific gifts/products that each kid had requested. Here’s an example of a sample letter with NER.

That information was then stored in a Delta table making it easy for employees at the North Pole to quickly figure out what every kid wanted for a holiday present. Using the Lakeview Dashboard, the elves were also able to easily build reports to outline Santa's information including the top gift requests overall, as well as the top in each category.


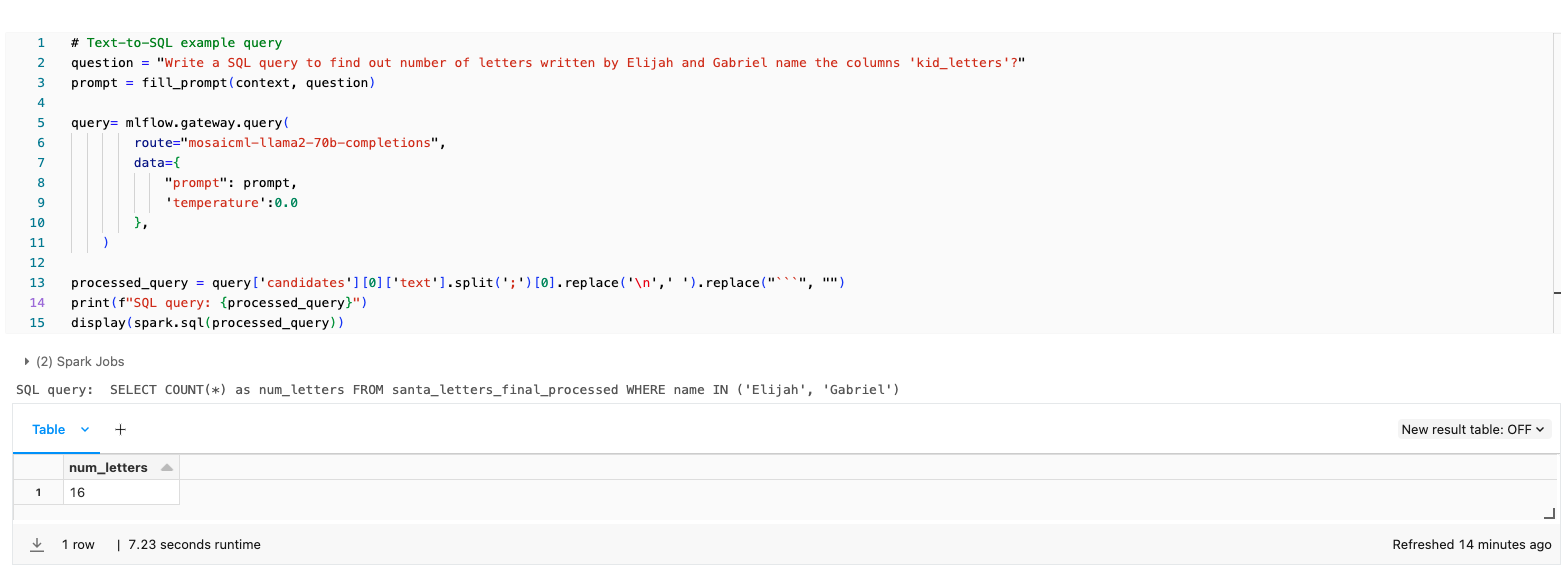
Lastly, we wanted to make it simple for the elves to extract insights from the data set. Using a text-to-SQL engine, engineers at the North Pole can now pose a natural language query to get the syntax needed to run a SQL job. For example, Santa may want to know what present every girl named Emily and Gabriel is going to get. All the elves have to do is type that request into the engine and they’ll get back the SQL statement they need to run to get the answer.
What did we learn?
There were many ways we could have accomplished the above. However, we knew that Santa was eager to scale these AI initiatives across the enterprise. And that meant we had to prepare for wide adoption across the North Pole. The map below shows a summary of the most popular gift categories per state (we randomly assigned different U.S. states to all the generated letters).

Foundational models like Llama2 and MPT-7B are vital, but they can be difficult and expensive to scale. Using the Databricks Data Intelligence Platform, we were able to do it much easier, faster and cheaper. For example, instead of sending over workloads to the foundational model one by one, a process that could take weeks or longer for large datasets, we were able to run a bulk job that finished in minutes using Spark. When looking to expand AI initiatives across the enterprise, that type of convenience and speed is mandatory.
Relying on a platform like Databricks to interface with commercial models via Foundation Models (in the Databricks Marketplace) means that companies like North Pole, Inc. don’t have to move their data out of the Lakehouse. Not only does that alleviate in-house engineers from building and managing complex data pipelines, but it also helps enterprises secure their data and manage access down to the individual user.
For example, imagine it was actual customer data, not synthetic data, that we were using to generate letters. That would require much more stringent security controls, as well as a governance framework that would account for all the different regulations on storing and using consumer information.
What are some applications of this exercise?
We realize the North Pole is a vastly different organization than most other businesses. However, this exercise has broad applications that nearly every company could benefit from.
For example, the marketing team might want to create personalized holiday greeting cards for each of their customers. The business might want to get their top sales prospects year-end presents. Or maybe retailers that want to better track the post-holiday return cycle are eager to draw insights from the thousands of customer service calls that will come in. These use cases would all rely on the same approach that we used with the North Pole.
Here’s some sample code that we used in this blog to generate the letter. To learn more about how Databricks can help you train and build generative AI solutions, watch our on-demand webinar: Disrupt your industry with generative AI.

