Evolving Your SIEM Detection Rules: A Journey from Simple to Sophisticated
by David Wells
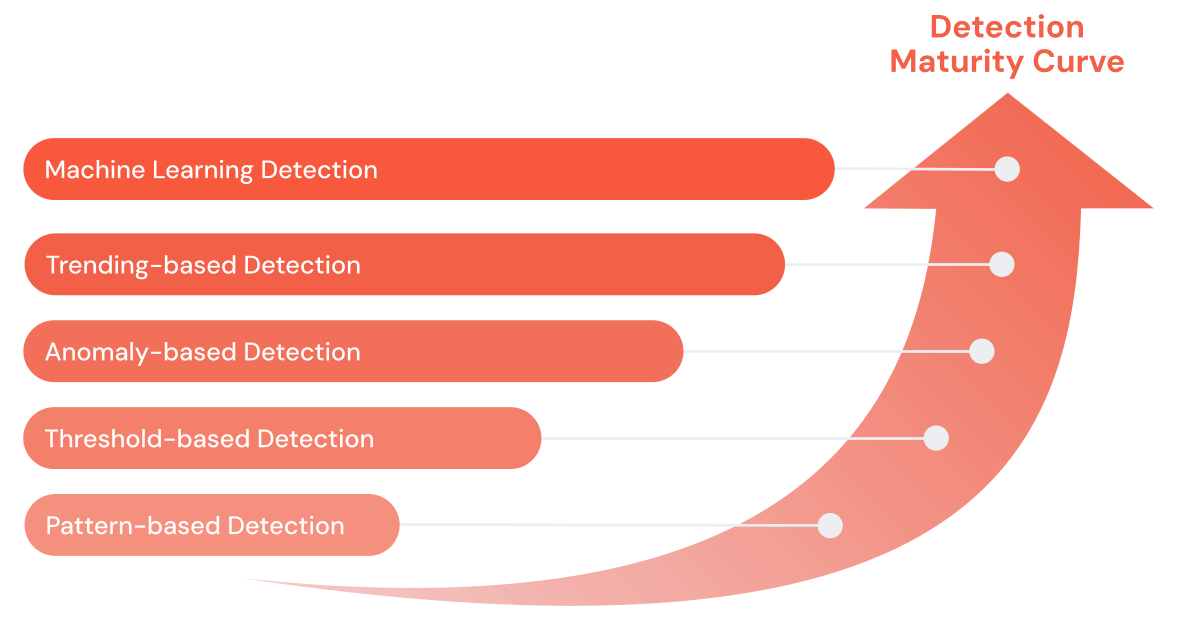
Cyber threats and the tools to combat them have become more sophisticated. SIEM is over 20 years old and has evolved significantly in that time. Initially reliant on pattern-matching and threshold-based rules, SIEMs have advanced their analytic abilities to tackle more sophisticated cyber threats. This evolution, termed the 'Detection Maturity Curve,' illustrates the shift security operations have taken from simple alert systems to advanced mechanisms capable of predictive threat analysis. Despite these advancements, modern SIEMs face challenges scaling for large data sets and long-term trending or machine learning detection, underscoring an organization's ability to detect and respond to increasingly complex threat actors.
This is where Databricks helps cybersecurity teams. Databricks' unified analytics, powered by Apache Spark™, MLflow, and Delta tables, cost-effectively scaling to meet enterprises' modern big data and machine learning needs.
This blog post will describe our journey of building evolving security detection rules transitioning from basic pattern matching to advanced techniques. We will detail each step and highlight how Databricks Data Intelligence Platform has been used to run these detections on over 100 terabytes of monthly event logs and 4 petabytes of historical data, beating the global world record for speed and cost.
Introduction
Our main objective is to demystify the detection patterns described in the detection maturity curve and explore their value, benefits, and limitations. To help, we have created a GitHub repository with this blog's source material and a helper library that contains repeatable PySpark code that can be used for your cyber analytics program. The examples in this guide are based on the sample logs generated by the Git repository.
1. Pattern-Based Rules
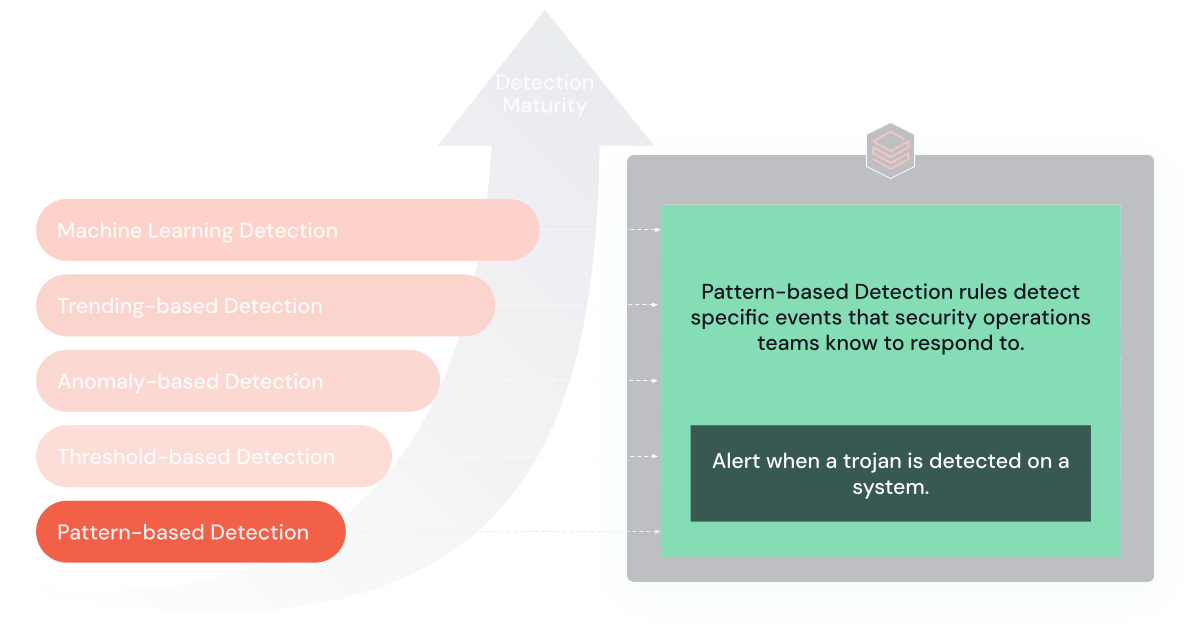
Pattern-based rules are the simplest form of SIEM detection, which triggers alerts upon recognizing specific patterns or signatures in data.
Purpose and Benefits: These rules are foundational for SIEM detection, offering simplicity and specificity. They are highly effective in quickly identifying and responding to known threats.
Limitations: Their primary drawback is their limited capacity to adapt to new and unknown threats, making them less effective against sophisticated cyber attacks.
When to Use: These rules are best suited for organizations in the early stages of their cybersecurity program or those primarily facing well-documented threats.
For instance, the following SQL pattern-based rule might look for specific malware signatures:
2. Threshold-Based Rules
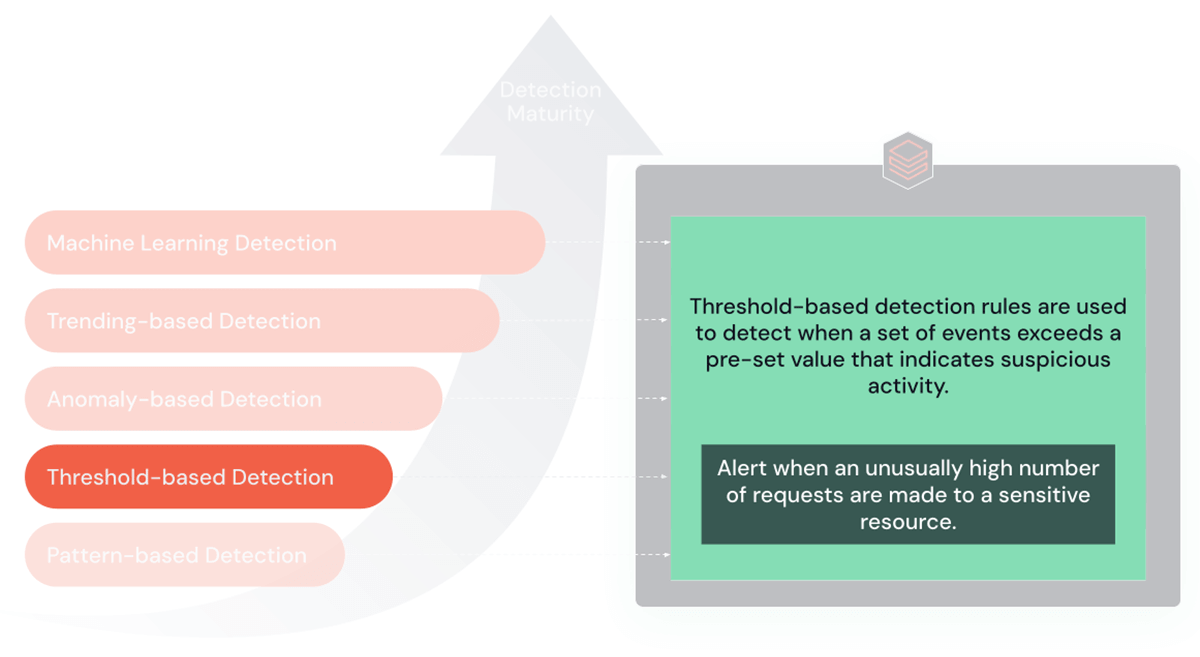
Threshold-based rules are designed to trigger alerts when events surpass predefined limits or thresholds. They are especially effective in scenarios like brute force or Denial of Service (DoS) attacks.
Purpose and Benefits: The primary strength of these rules lies in their ability to detect significant deviations from normal activity, such as unusually high network traffic or an abnormal number of login attempts. This makes them invaluable for identifying large-scale, conspicuous attacks.
Limitations: However, their effectiveness is lessened against slow, progressive attacks that don't immediately cross these set thresholds. They also struggle with static thresholds that, when set too low, cause false positives or, when set too high, costly false negatives.
When to Use: These rules are most effective in environments with established baseline activity levels, allowing for clear threshold settings. This includes scenarios like monitoring network traffic or tracking login attempts.
For instance, the following SQL trending-based rule demonstrates how to identify statistically significant deviations in user login attempts:
This SQL query will trigger an alert if there are more than 100 connections from an IP in 30 minutes.
3. Statistical Anomaly Detection
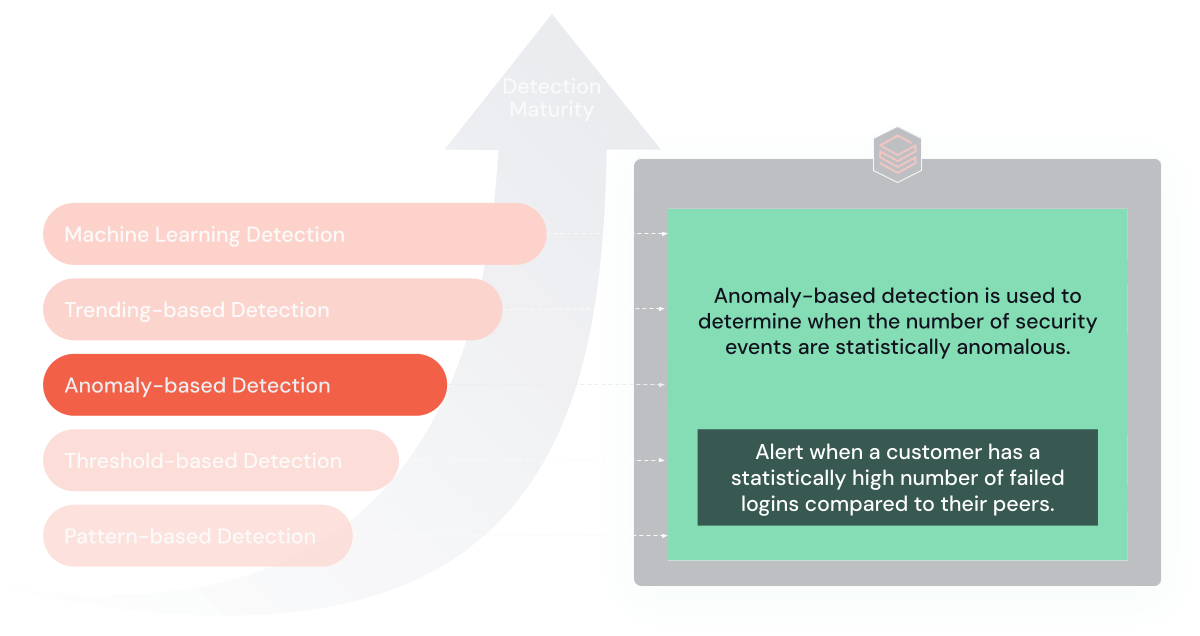
As your detection capabilities mature, you can incorporate techniques to detect statistical anomalies in your environment. These rules build a model of "normal" behavior based on historical data and then trigger an alert when there is a significant deviation from the norm.
Purpose and Benefits: These rules excel in spotting deviations from 'normal' behavior, offering a dynamic approach to threat detection.
Limitations: Requires substantial historical data and might generate false positives if incorrectly calibrated. Tracking many entities can require significant computation, causing performance issues or missing results when hitting internal limits with traditional SIEMs.
When to Use: Ideal for mature cybersecurity environments with extensive historical data.
For instance, the following SQL anomaly-based rule detects when a user's activities deviate statistically from the peer group's:
This query will trigger an alert if a user's failed logins are three times the standard deviation above their peer's mean failed logins.
4. Trending-Based Rules
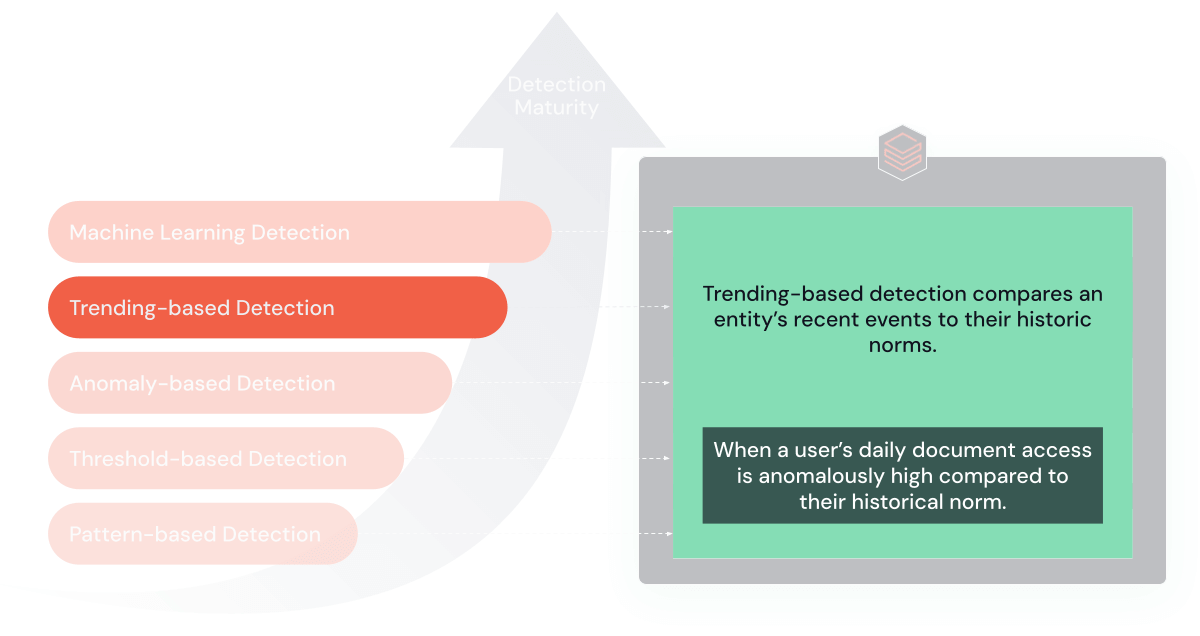
Trending-based rules are designed to identify anomalies or significant changes in an entity's behavior over time. These rules compare current activities against an individual's historical norm to effectively reduce false positives.
Purpose and Benefits: These rules are adept at uncovering subtle, evolving threats. By analyzing data trends over time, they provide insights into changes in behavior that may indicate a security threat.
Limitations: One of the main challenges with trending-based rules is that they can be resource-intensive and require ongoing analysis of large volumes of data.
When to Use: They are most effective when long-term data monitoring is practical, the detection engine can scale, and threats may develop gradually. Traditional SIEMs are not typically used for trend analysis due to their complexity.
Let's consider monitoring anomalous login attempts from the previous pattern. While a user may deviate from their peer group, this deviation might be typical for them. A trend-based rule can be deployed to alert when there is a significant increase in failed login attempts for a specific hostname compared to their historical pattern or, more importantly, not to alert when it doesn't.
For instance, the following SQL trending-based rule detects when a user's logins are statistically significant from their historical trends:
In this example, we calculate the average daily number of failed login attempts from each hostname over the past week and the number of failed attempts from each host in the past 24 hours. We then join these two result sets on hostnames and filter for hosts where the number of failed attempts in the past 24 hours exceeds the average daily number of attempts over the past 90 days.
5. Machine Learning-Based Rules
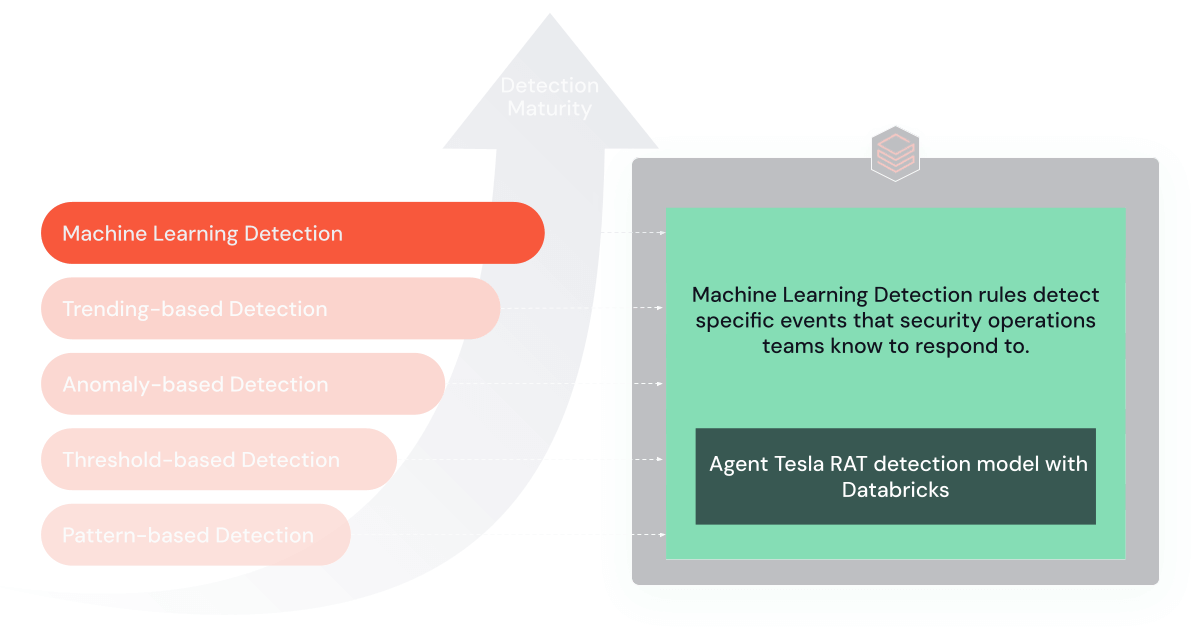
The most advanced detection rules continually use machine learning algorithms to adapt to threats. These algorithms can learn from historical data to predict and detect future threats, often catching attacks that more deterministic rules might miss. Implementing and operationalizing machine learning models requires significant investment in data science and machine learning expertise and platforms. The Databricks Data Intelligence Platform facilitates comprehensive management of the entire machine learning lifecycle, encompassing initial model development, deployment, and even the eventual sunsetting phase.
Unsupervised learning models, trained using algorithms such as clustering (e.g., K-means, hierarchical clustering) and anomaly detection (e.g., Isolation Forests, One-Class SVM), are crucial in identifying novel, previously unknown cyber threats. These models work by learning the 'normal' behavior patterns in the data and then flagging deviations from this norm as potential anomalies or attacks. Unsupervised learning is particularly valuable in cybersecurity because it can help detect new, emerging threats for which labeled data does not yet exist.
Conversely, SOCs employ supervised learning models to classify and detect known types of attacks based on labeled data. Examples of these models include logistic regression, decision trees, random forests, and support vector machines (SVM). These models are trained using datasets where the attack instances are identified and labeled, enabling them to learn the patterns associated with different types of attacks and subsequently predict the labels of new, unseen data.
For machine learning, I will reference the excellent project Detecting AgentTeslaRAT through DNS Analytics with Databricks (Github here), which walks through training and serves the ML model for cybersecurity use cases.
Bonus: Risk-based Alerting
Risk-based alerting is a powerful strategy that complements detection patterns. Risk-based alerting quantifies "risky" actions (e.g., failed logins, off-hour actions) to entities (e.g., IP addresses, users, etc.). It often includes helpful metadata, such as the risk category, kill-chain stage, etc., allowing detection engineers to build rules based on a broader range of events.
Building a risk-based detection process requires the extra step of risk-scoring events. This can be accomplished by adding a new risk-score column in a table, but a risk table that incorporates risk events from multiple sources is commonly created.

Organizations adopting risk-based detection strategies can exploit the detection patterns mentioned above. For example, suppose a user has a high-risk score. In that case, organizations can use the trending detection pattern to verify if this is unique for the user to avoid alerting when admins regularly perform late-night upgrades during a change window.
Repeatable Code
The GitHub repository contains notebook helper methods with standard cyber functions for collection, filtering, and detection. Databricks also has a project to help simplify this lifecycle. If you are interested in learning more, please contact your account manager.
Conclusion
In the ever-evolving world of cyber threats, upgrading SIEM detection from basic pattern matching to advanced machine learning is essential. This shift is a strategic necessity for effectively addressing complex cyber threats. While evolving detection methods enhance our ability to uncover and respond to subtle security incidents, the challenge lies in integrating these sophisticated techniques without overburdening our teams. Ultimately, the goal is to develop a resilient, adaptable cybersecurity program capable of facing both current threats and future challenges with efficiency and agility.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.