FactSet: Implementing an Enterprise GenAI Platform with Databricks

"FactSet’s mission is to empower clients to make data-driven decisions and supercharge their workflows and productivity. To deliver AI-driven solutions across our entire platform, FactSet empowers developers at our firm and our customers’ firms to innovate efficiently and effectively. Databricks has been a key component to this innovation, enabling us to drive value using a flexible platform that enables developers to build solutions centered around data and AI." - Kate Stepp, CTO, FactSet
Who We Are and Our Key Initiatives
FactSet helps the financial community to see more, think bigger, and work smarter. Our digital platform and enterprise solutions deliver financial data, analytics, and open technology on a global scale. Clients across the buy-side and sell-side, as well as wealth managers, private equity firms, and corporations, achieve more every day with our comprehensive and connected content, flexible next-generation workflow solutions, and client-centric specialized support.
In 2024, our strategic focus is on leveraging advancements in technology to improve client workflows, particularly through the application of Artificial Intelligence (AI), to enhance our offerings in search and various client chatbot experiences. We aim to drive growth by integrating AI into various services, which will enable more personalized and efficient client experiences. These AI-driven enhancements are designed to automate and optimize various aspects of the financial workflow, from generating financial proposals to summarizing portfolio performances for FactSet Investors.
As a leading solutions and data provider and technology early adopter, FactSet has identified several opportunities to enhance customer experience and internal applications with generative AI (GenAI). Our FactSet Mercury initiative enhances the user experience within the FactSet workstation by offering an AI-driven experience for new and existing users. This initiative is powered by large language models (LLMs) that are customized for specific tasks, such as code generation and summarization of FactSet-provided data. However, while the vision for FactSet’s end-user experience was clear, there were several different approaches we could take to make this vision a reality.
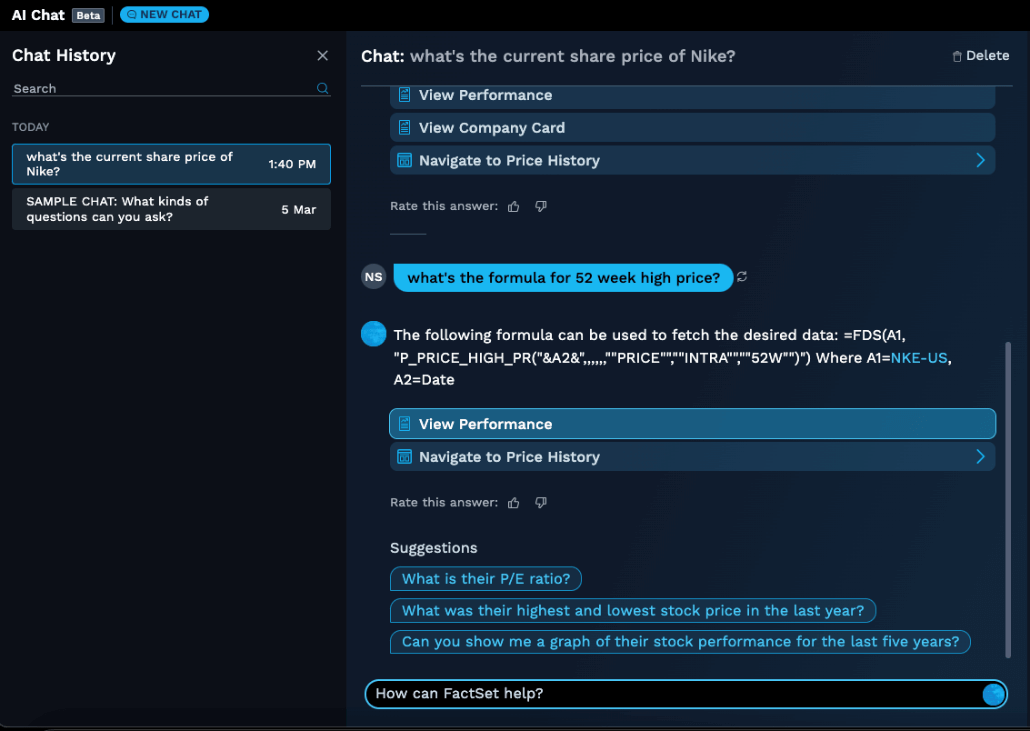
To empower our customers with an intelligent, AI-driven experience, FactSet began exploring various tools and frameworks to enable developers to innovate rapidly. This article describes our evolution from an early approach focused on commercial models to an end-to-end AI framework powered by Databricks that balances cost and flexibility.
The Opportunity Cost of Developer Freedom: Tackling GenAI Tool Overload
Lack of a Standardized LLM Development Platform
In our early phases of GenAI adoption, we faced a significant challenge in the lack of a standardized LLM development platform. Engineers across different teams were using a wide array of tools and environments or leveraging bespoke solutions for particular use cases. This diversity included cloud-native commercial offerings, specialized services for fine-tuning models, and even on-premises solutions for model training and inference. The absence of a standardized platform led to several issues:
- Collaboration Barriers: Teams struggled to collaborate due to different tools and frameworks
- Duplicated Efforts: Similar models were often redeveloped in isolation, leading to inefficiencies
- Inconsistent Quality: Varied environments resulted in uneven model performance across applications
Lack of a Common LLMOps Framework
Another challenge was the fragmented approach to LLMOps within the organization. While some teams were experimenting with open source solutions like MLflow or utilizing native cloud capabilities, there was no cohesive framework in place. This fragmentation resulted in lifecycle challenges related to:
- Isolated Workflows: Teams had difficulty collaborating and were unable to share prompts, experiments, or models
- Rising Demand: The lack of standardization hindered scalability and efficiency as the demand for ML and LLM solutions grew
- Limited Reusability: Without a common framework, reusing models and assets across projects was challenging, leading to repeated efforts
Data Governance and Lineage Issues
Using multiple development environments for Generative AI posed significant data governance challenges:
- Data Silos: Different teams stored data in various locations, leading to multiple data copies and increased storage costs
- Lineage Tracking: It was hard to track data transformations, affecting our understanding of data usage across pipelines
- Fine-Grained Governance: Ensuring compliance and data integrity was difficult with scattered data, complicating governance
Model Governance + Serving
Lastly, managing and serving models in production effectively faced several obstacles:
- Multiple Serving Layers: Maintaining and governing models became cumbersome and time-consuming
- Endpoint Management: Managing various model serving endpoints increased complexity and impacted monitoring
- Centralized Oversight: The lack of oversight hindered consistent performance tracking and optimal model maintenance amid ever-increasing requirements like content moderation
Empowering Developers with a Framework, Not Fragments
Once our AI projects gained traction and moved toward production, we realized that offering our team unbridled platform flexibility inadvertently created challenges in managing the LLM lifecycle, especially for dozens of applications. In the second phase of GenAI implementation at FactSet, developers are empowered to choose the best model for their use case — with the guardrails of a centralized, end-to-end framework.
After a thorough evaluation based on specific business requirements, FactSet selected Databricks as their enterprise ML / AI platform in late 2023. After the existing challenges faced during the early adoption and development of different AI platforms and services, FactSet decided to standardize new development of LLM / AI applications on Databricks Mosaic AI and Databricks-managed MLflow for several reasons outlined below:
Data Preparation for Modeling + AI / ML Development
We found that Databricks Mosaic AI tools and managed MLflow enhanced efficiency and reduced the complexity of maintaining underlying cloud infrastructure for practitioners. By abstracting away the complexity of many cloud infrastructure tasks, developers could spend more time innovating new use cases with managed compute running on AWS and both serverless and non-serverless compute from Databricks. Without needing in-depth cloud expertise or specialized AI and ML experience, our product engineers were able to access abstracted compute and install libraries and any dependencies directly from their Databricks environment.
As an example, an application developer leveraging our enterprise deployment was able to easily create an end-to-end pipeline for a RAG application for earnings call summarization. They used Delta Live Tables to ingest and parse news data in an XML format, chunked the text by length and speaker, created embeddings and updated Vector Search indexes, and leveraged an open-source model of choice for RAG. Finally, Model Serving endpoints served responses into a front end application.

These frameworks provide an easy-to-use, collaborative development environment for practitioners to create reusable ingestion and transformation pipelines using the Databricks Data Intelligence Platform. Data is consolidated in S3 buckets maintained by FactSet.
Governance, Lineage, Traceability
Unity Catalog helped resolve prior challenges such as data silos, multiple governance models, lack of data and model lineage, and lack of auditability by providing cataloging capabilities with a hierarchical structure and fine-grained governance of data, models, and additional assets. Additionally, Unity Catalog also enables isolation at both the metadata and physical storage levels in a shared environment with multiple users across different teams and reduces the need for individual user IAM role-based governance.
For example, FactSet has several lines of business and multiple teams working on specific use cases and applications. When a user from a team signs in to Databricks using their SSO credentials, that user sees an isolated, customized access view of governed data assets. The underlying data resides in FactSet’s S3 buckets that are specific to that user’s team and have been registered to Unity Catalog as external locations with an assigned storage credential. Unity Catalog enforces isolation and governance without requiring the user to have specific IAM permissions granted.
By consolidating ingestion and transformation and leveraging Unity Catalog as a consistent, standardized governance framework, we were able to capture table/column level lineage for all operations using Databricks compute. The ability to capture lineage is critical for monitoring underlying data and enables explainability of downstream GenAI applications. Unity Catalog’s lineage, combined with the auditability of underlying data, enables FactSet application owners to better understand the data lifecycle and downstream query patterns.
LLMOps + FactSet Self-Service Capabilities
In addition to building a cross-business unit enterprise deployment, we also integrated Databricks with our internal GenAI Hub which manages all ML and LLM resources for a given project. This integration enabled centralization of Databricks workspaces, the Model Catalog, and other essential meta-share that facilitates ML producer <> ML consumer collaborations and reusability of models across our firm. Significant integrations of MLflow and Databricks cost-attribution were included, streamlining our project hub and cost-attribution workflows by leveraging Databricks cost views to provide better per-project business transparency.
Perhaps the most critical driving factor for FactSet's platform evaluation was creating a comprehensive, standardized LLMOps framework and model deployment environment. During model development, MLflow makes it easy to compare model performance across different iterations. By having MLflow integrated into the Databricks UI, practitioners can easily take advantage of MLflow through point-and-click operations, while also having the flexibility to programmatically leverage MLflow capabilities. MLflow also enables a collaborative experience for teams to iterate on model versions, reduce siloed work, and enhance efficiency.
Big Book of MLOps

A key consideration during FactSet’s evaluation was Databricks' support for a wide range of open-source and commercial models. Our goal is to leverage commercial and open-source models that provide our clients with the best accuracy, performance, and cost. Mosaic AI enables serving multiple types of models from a single serving layer, including custom models (ex. Langchain, HuggingFace), open-source foundation models (ex. Llama 3, DBRX, Mistral), and even external models (ex. OpenAI, Anthropic). The MLflow Deployments Server enables simplified model serving for a variety of model types.
Our Product Outcomes
Fine-Tuning Open-Source Alternatives to Proprietary Frameworks in Mercury
An early adopter of the platform was a code generation component of Mercury that could generate boilerplate data frames based on client prompts to request data from existing data interfaces.
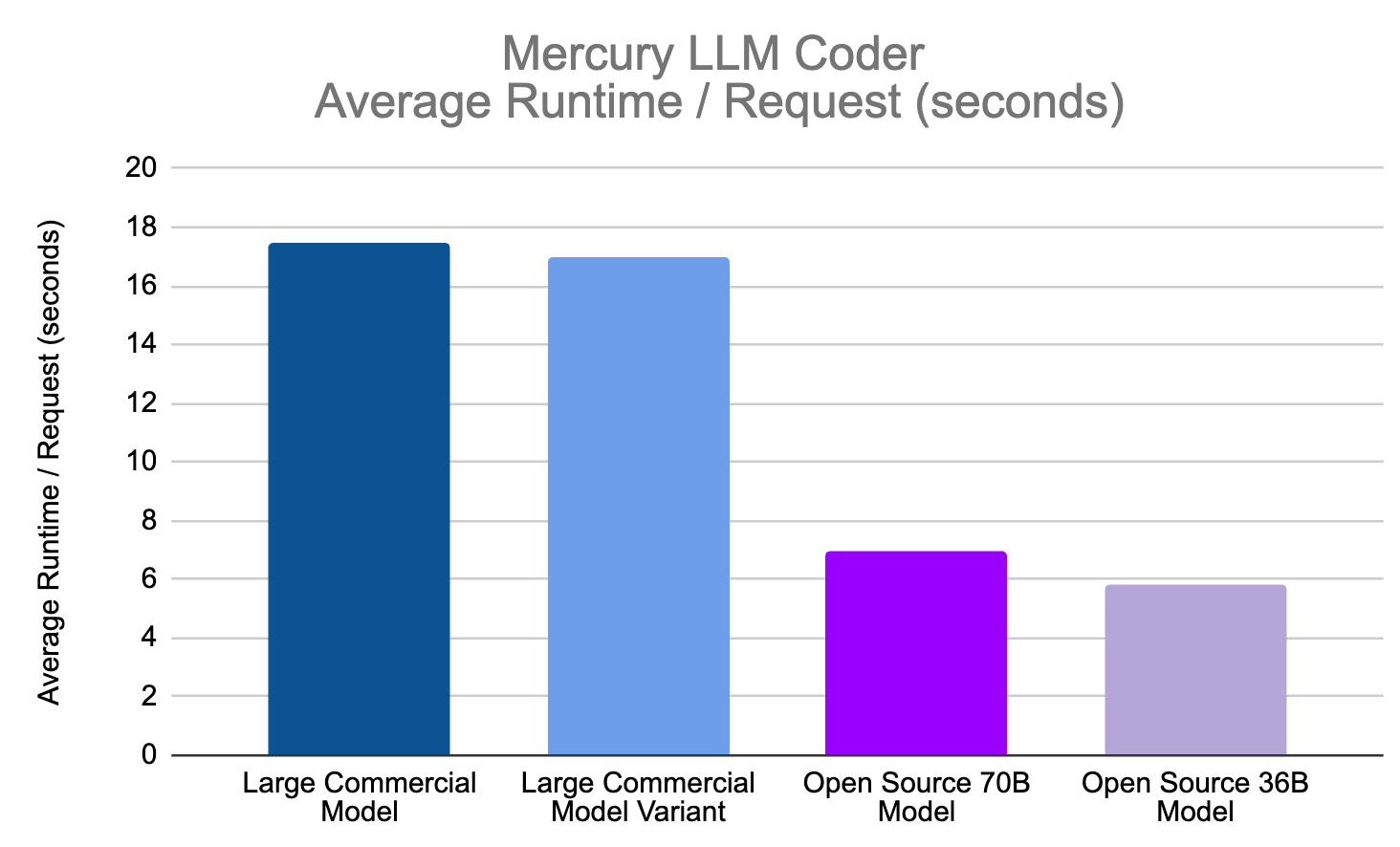
This application heavily leveraged a large commercial model, which provided the most consistent, high-quality results. However, early testers encountered over a minute in response time with the existing commercial model in the pipeline. Using Mosaic AI, we were able to fine-tune meta-llama-3-70b and, recently, Databricks DBRX to reduce average user request latency by over 70%.
This code generation project demonstrated the flexibility of Databricks Mosaic AI for testing and evaluating open-source models, which led to major performance improvements and added value to the end-user experience in FactSet workstations.
Text to Formula Advanced RAG With Open-Source Fine-Tuning Workflow
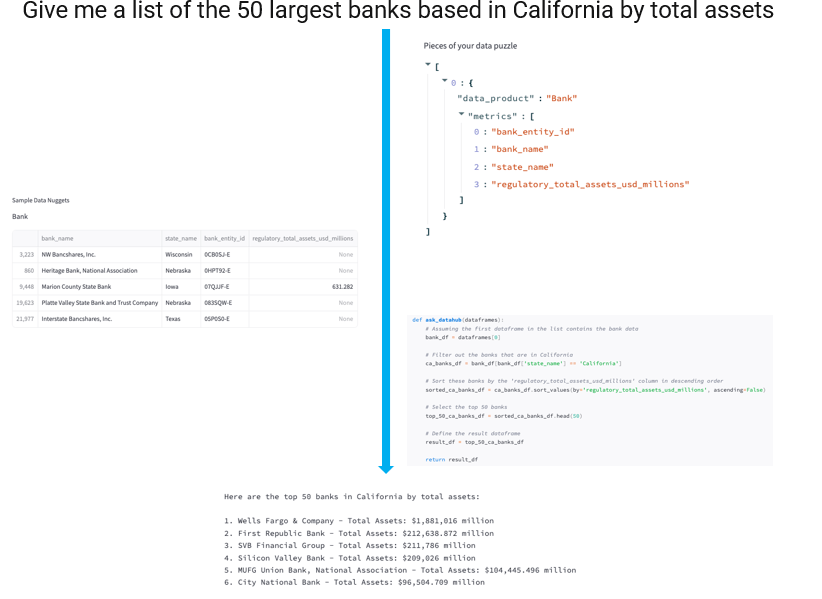
Another project which reaped benefits from our Databricks tooling was our Text-to-Formula initiative. The goal of this project is to accurately generate custom FactSet formulas using natural language queries. Here is an example of a query and respective formula:
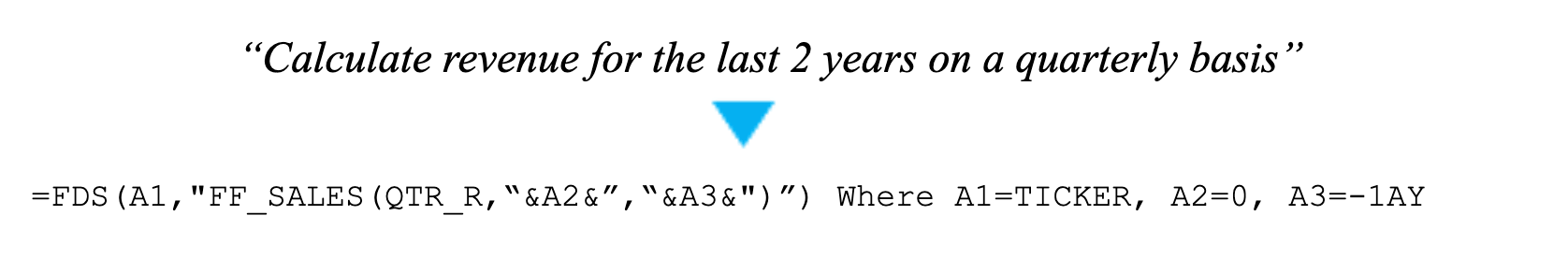
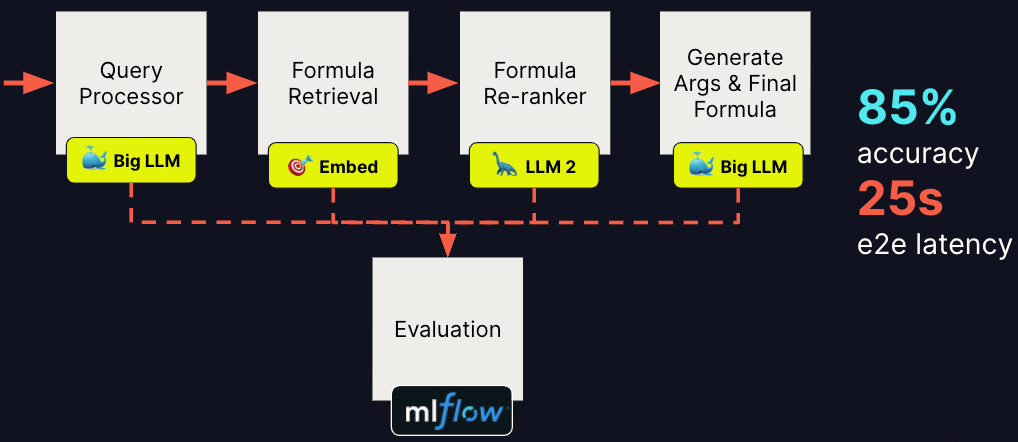
We started the project with a simple Retrieval-Augmented Generation (RAG) workflow but we quickly hit a ‘quality ceiling’ and were unable to scale up with more complex formulas. After extensive experimentation, we developed the below architecture and have achieved notable improvements in accuracy, but with high end-to-end (e2e) latency, as illustrated below. The image below reflects the architecture prior to using Mosaic AI.
The Databricks Mosaic AI platform offers an array of functionalities, including detailed fine-tuning metrics that allow us to rigorously monitor training progress. Additionally, the platform supports model versioning, facilitating the deployment and management of specific model versions in a native serverless environment.
Implementing such a cohesive and seamless workflow is paramount. It not only enhances the end-to-end experience for the engineering, ML DevOps, and Cloud teams but also ensures efficient synchronization and collaboration across these domains. This streamlined approach significantly accelerates the development and deployment pipeline, thereby optimizing productivity and ensuring that our models adhere to the highest standards of performance and compliance. Now is the time to step back, transcend our initial requirements, and devise a strategy to enhance ‘Functional’ Key Indicators, ultimately rendering our product self-service capable. Achieving this vision necessitates an enterprise-level LLMOps platform.
The following workflow diagram describes the integration of a RAG process designed to systematically gather data, incorporate subject matter expert (SME) evaluations, and generate supplementary examples that comply with FactSet’s governance and compliance policies. This curated dataset is subsequently stored within the Unity Catalog’s project schema, enabling us to develop fine-tuned models leveraging Databricks Foundation Model APIs or models from the Hugging-Face Models Hub.
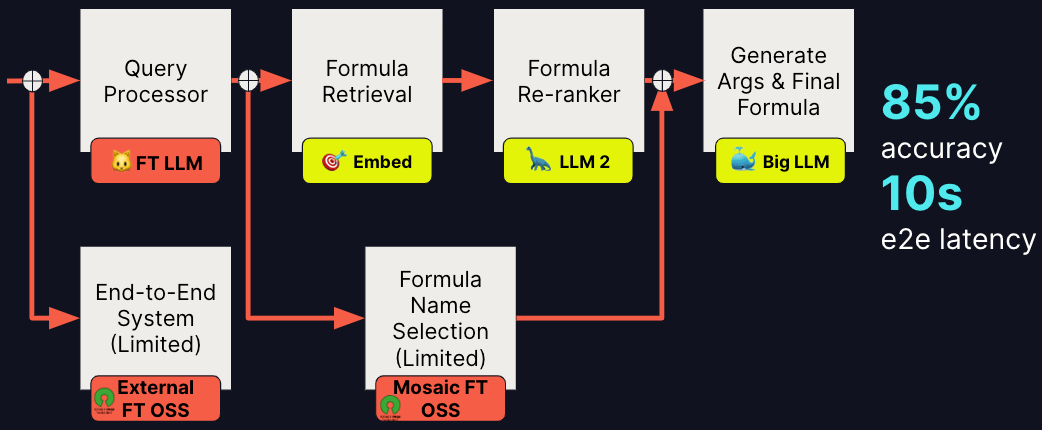
Crucial ‘Functional’ Key Indicators for us include ‘Accuracy’ and ‘Latency,’ both of which can be optimized by incorporating fine-tuned (FT) models, leveraging both proprietary systems and open-source solutions. Because of our investment in fine-tuning efforts, we were able to significantly reduce end-to-end latency by about 60%. Most of these fine-tuned models are from open-source LLM models, as depicted in the figure above.
Why This Matters to our GenAI Strategy
With Databricks integrated into FactSet workflows, there is now a centralized, unified set of tools across the LLM project lifecycle. This allows different teams and even business units to share models and data, reducing isolation and increasing LLM-related collaboration. Ultimately, this democratized many advanced AI workflows that were traditionally gated behind traditional AI engineers due to complexity.
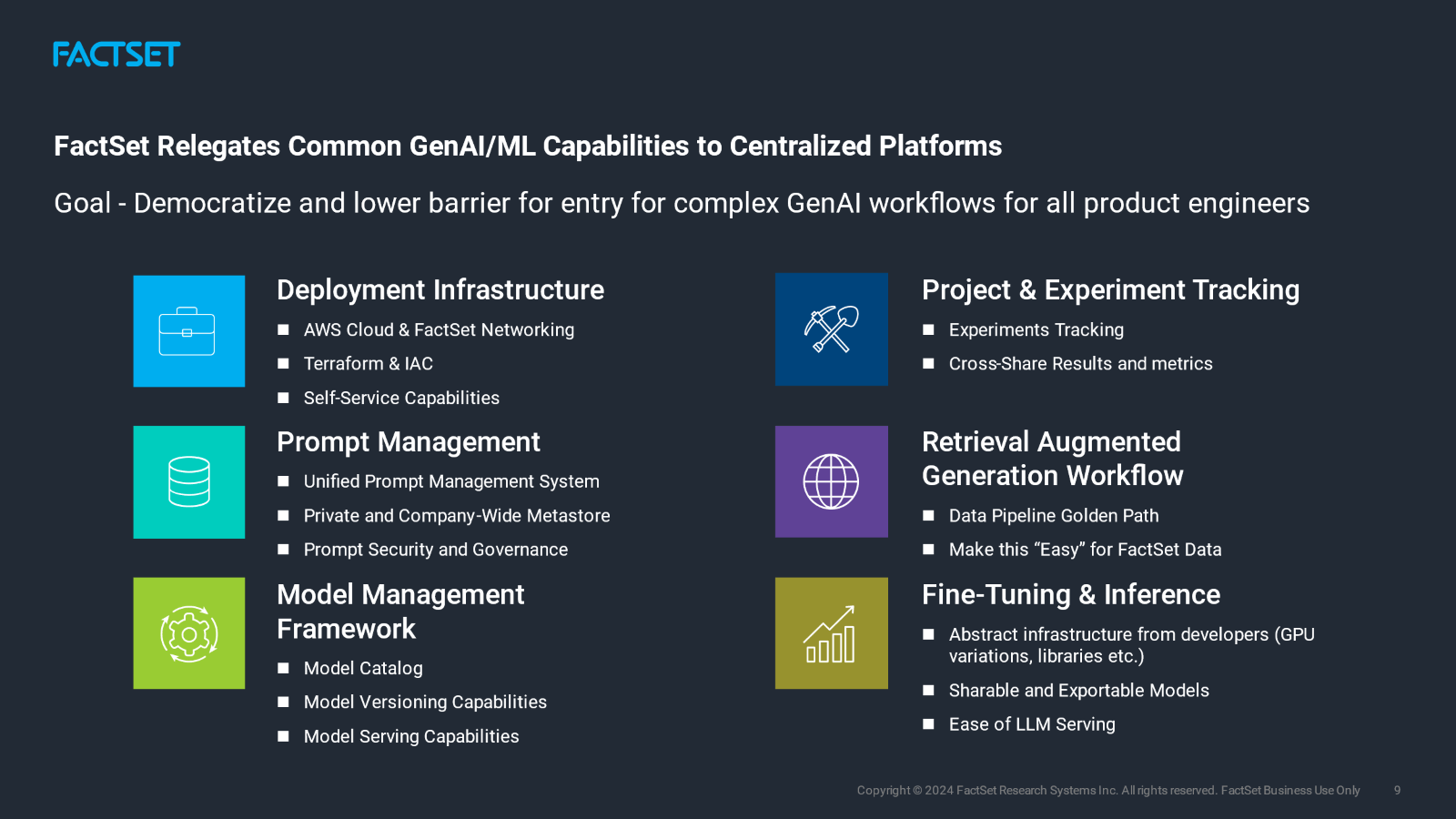
Like many technology firms, FactSet’s initial experimentation with GenAI heavily leveraged commercial LLMs because of their ease of use and fast time to market. As our ML platform evolved, we realized the importance of governance and model management when building a GenAI strategy. Databricks MLflow allowed us to enforce best practice standards for LLMOps, experiment with open models, and evaluate across all model types, offering a great deal of flexibility.
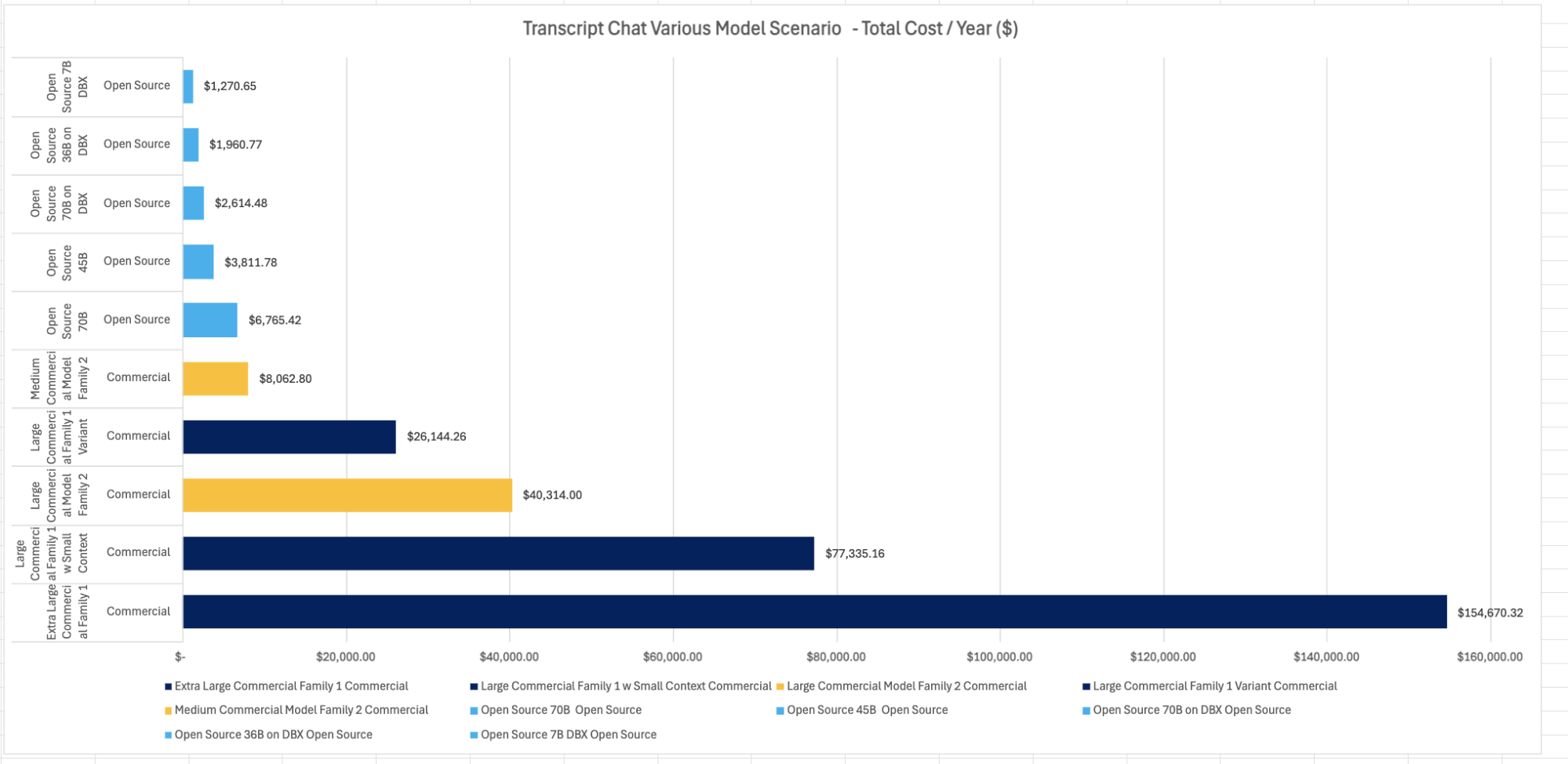
As our product teams continue to innovate and find new ways to adopt LLMs and ML, our technology goal is to enable model choice and adopt a culture that lets our teams use the right model for the job. This is consistent with our leadership principles, which support the adoption of new technologies to enhance client experiences. With the adoption of managed MLflow and Databricks, our GenAI strategy supports a unified experience that includes a range of more fine-tuned open-source models alongside commercial LLMs that are already embedded in our products.
This blog post was jointly authored by Wilson Tsai (FactSet), Michael Edelson (FactSet), Nikhil Hiriyur Sunderraj (FactSet), Yogendra Miraje (FactSet), Ricardo Portilla (Databricks), Keon Shahab (Databricks) and Patrick Putnam (Databricks).