Four Steps to Migrate a SAS Data Warehouse to the Lakehouse
by Mike Perlov and Satish Garla
Although SAS is known as the analytical platform, it is quite often that an organization uses it for data engineering and even for full-scale data warehouses. For these types of use cases, SAS has a product, bundled with many solutions, SAS Data Integration Studio (or just SAS DI). It is a powerful, low-code, visual ETL/ELT tool based on the legacy SAS 9.4 platform. While SAS was a decent choice ten years ago for data management and ETL, with the rise of cloud-native open platforms such as Lakehouse many organizations are modernizing their architecture. The Lakehouse architecture supports diverse data and AI workloads on a single copy of data, is cheaper, since it leverages low cost storage, and is performant, as it leverages in-memory and distributed compute engines. For more details on why you should modernize, check out the evolution of the Lakehouse here.
So you've made a decision or are considering a migration to Lakehouse. You've talked to your data team and realized there are hundreds, if not thousands, of jobs and manual migration is just too costly. You may be tempted to try converting the code that SAS DI generates. While this will lead to some acceleration, there is a much better and robust way using the job metadata. Like any other enterprise ETL products, such as Informatica, SAS DI stores all of your jobs as structured metadata. This means higher automation potential and produces cleaner, more flexible output with less effort.
Let's walk through the migration steps together using a sample SAS DI job to see how its metadata driven structure helps along the way and what unique benefits it brings.
What we are migrating today
A typical data warehouse using SAS would consist of an underlying RDBMS (or SAS files) and scheduled ETL flows consisting of jobs creating various layers, eventually building the data marts (consumption layer). To demonstrate this process, the T1A team created a SAS DI job for COVID vaccine impact analysis based on Our World in Data datasets. It represents a typical consumption layer job, joining, filtering and preparing a report-friendly datamart. Here is how it looks:


By the end of this article, you'll see it auto-converted to Databricks Delta Live Tables (DLT) pipeline automatically.
DLT is a new cloud-native managed service that provides,
- a reliable ETL framework to develop, test and operationalize data pipelines at scale
- a simple way to track and conform to data quality expectations
- continuous, always-on processing enabling fast data updates to the target tables without having to know complex stream processing
- pipeline visibility tracking end-to-end pipeline health for performance, quality, status, latency and more.
Here is our demo job auto-converted into DLT:

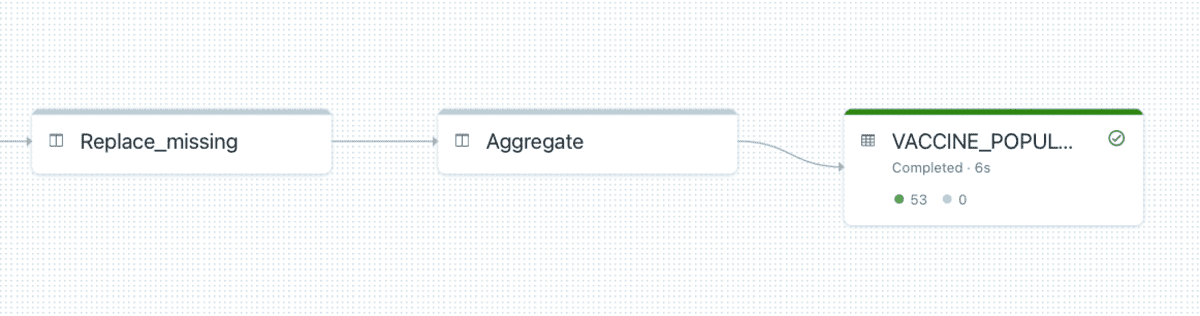
The conversion is performed using T1A's Alchemist, an automated SAS to Databricks migration tool. It was used to analyze and convert this job. The code samples, analysis output examples and templates shown in this blog are from Alchemist.
The migration steps
The blog walks through four steps that are expected in a typical migration project.
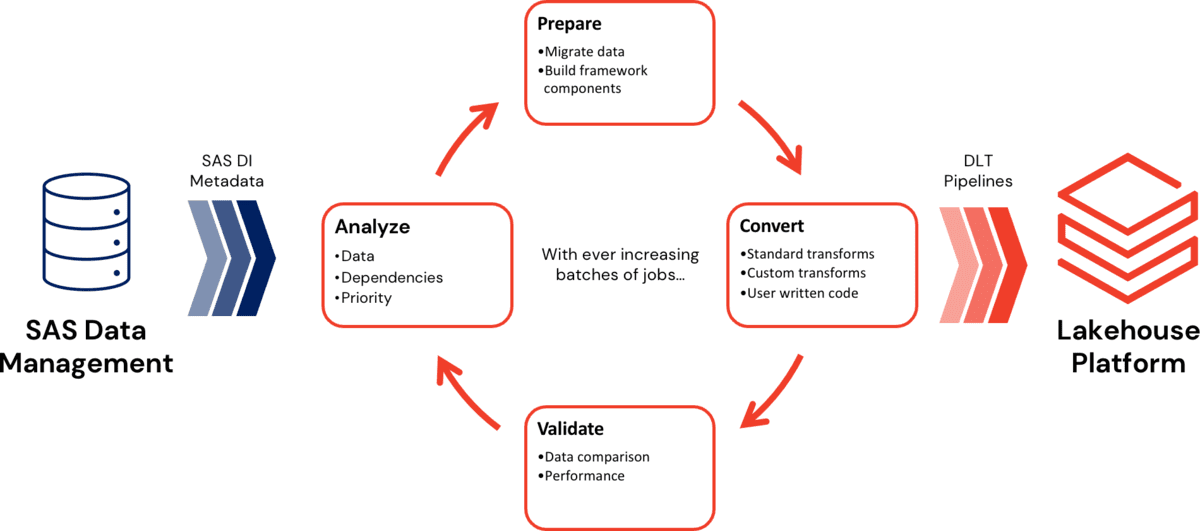
Step 1: Analyze
Before starting the migration, you should assess the scope and identify dependencies and priorities. SAS provides a Content Assessment tool that gives a great high-level overview of what's inside your environment. And it is a great place to start the analysis. However, it doesn't provide all required details such as number of lines of user written code, columns and their metadata and other metrics that are critical in understanding the complexity.
Here are some of the things you'd want to know about your jobs:
- How many are there and how complex are they?
- Which datasets do they use? Or, if your cloud data governance dictates column level restrictions, such as for PII data - which specific columns are in use?
- Which types of custom transformations are in use? How much code is it?
- How many user-written transformations exist, and which ones are unique?
- What are the dependencies between the jobs?
Benefit #1: Using the job and table metadata with Alchemist, we can get answers to all of these questions automatically.
We suggest creating a spreadsheet and a dashboard, like this one:
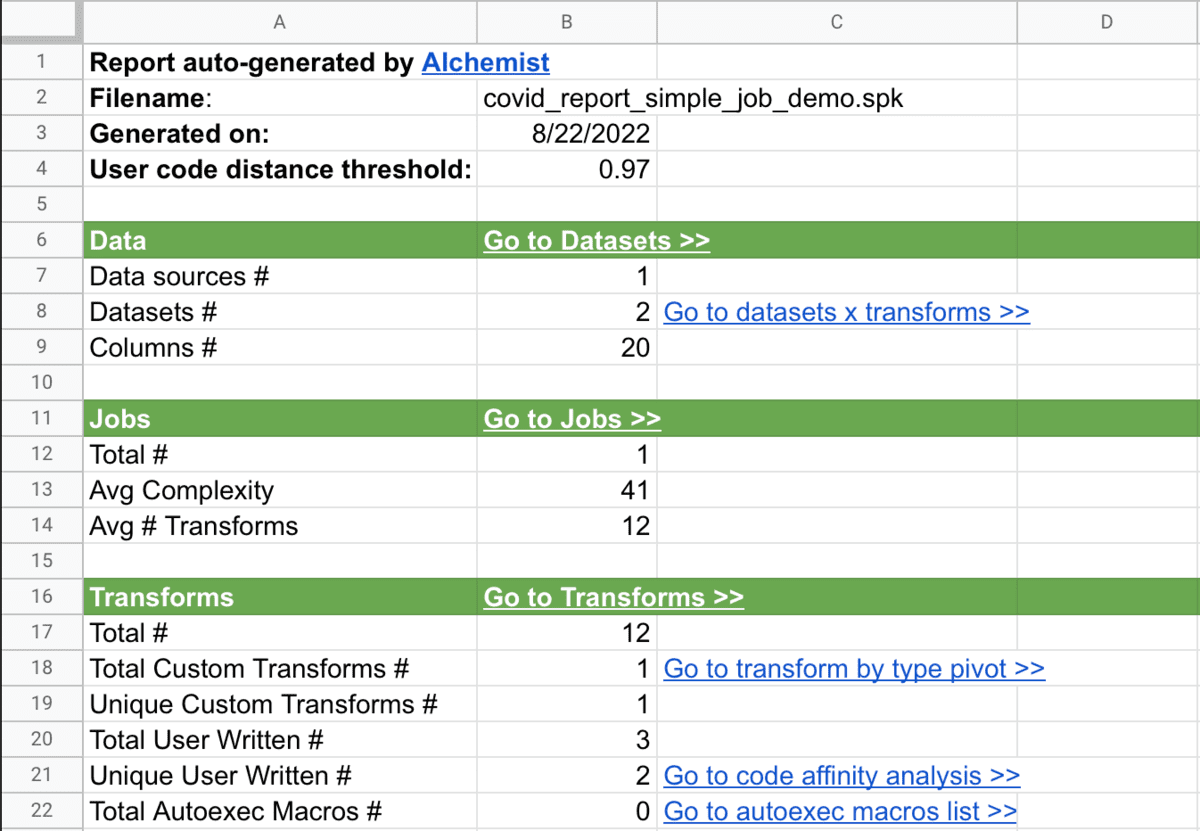
Now, armed with an understanding of what datasets we'll need to bring to the cloud, the jobs and the user written SAS code to convert, as well as what pieces of your inhouse data warehouse framework are used, we can move on to the next step.
Step 2: Prepare
To modernize by moving to a Lakehouse, you need two crucial pieces: your data in the cloud and a framework that your data engineers will use to build data pipelines.
Data
There have been a lot of great articles on how to migrate your data. Databricks Partner Connect is the perfect place to start if you are looking for quick and easy-to-use tools to help with that.
However, understanding what datasets and columns you need can help accelerate the process. Instead of flying blind or waiting for all of your data sources to be available in Delta Lake, Alchemist enables you to go agile. And as you'll see in the conversion step - this is a best practice to migrate in stages.
Framework
So what do we mean by the framework? The framework comprises your modern ETL toolkit and helper libraries/functions. First, you need to choose a primary data engineering tool. Databricks already provides built-in Databricks Workflows and Delta Live Tables, which are an excellent option for many use cases. In addition, you can leverage Databricks Partner Connect, which offers many tightly integrated options, among them: dbt or low-code solutions like Prophecy and Matillion.
Your engineering team also likely has a lot of reusable scripts that they utilize within their SAS DI jobs for efficiency. It may be a parametrized SCD2 loader, a custom PII encryption transform, a control flow construct or a custom loader for an obscure data source.
Some of these framework components become obsolete as you migrate, thanks to the power of scalable cloud computing and technologies like DLT. For example, a DLT pipeline automatically recovers from failures, including mid-job, so you won't need that custom "retry" transform you've built.
Some framework components will need to be refactored (e.g. a dynamic rule set macro becoming a python UDF), and some new ones will definitely be needed. But instead of sifting through piles of SAS files, or clicking through each and every custom transform to figure out what needs to be refactored or deprecated, once again, you can tap into the job metadata.
Benefit #2: Using job metadata, you can quickly identify and quantify the usage of the framework components, most often custom transforms or calls to SAS macros loaded via autoexecs. This information dramatically increases the efficiency of your framework development team.
Let's see what the analysis shows for our job:
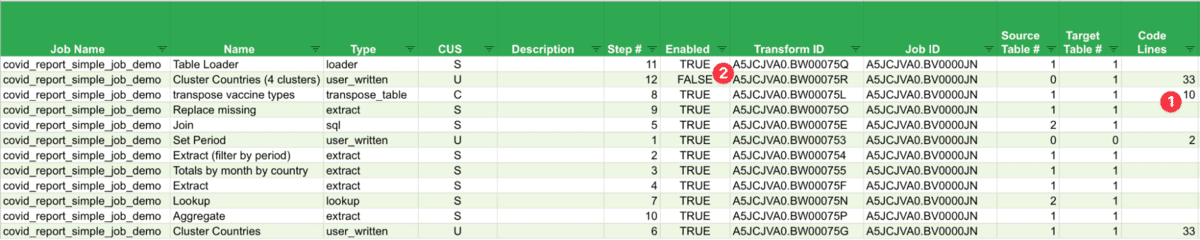
(1) There is one custom transform. We can immediately see that the code is minimal (just 10 lines), and we can drill down further to explore the actual code. Depending on the code, we may decide to re-factor it for the Lakehouse (develop a UDF or a python library), or we can create a custom conversion template for all custom transforms of that type. For our example, we will go with the latter option. (2) We can also see that one of the user written transforms was disabled, so we can probably skip it. Text analysis can further help, showing 99% code matches with another one, indicating it is an older version of another enabled transform.
That's it for the framework step, let's dive into the actual conversion.
Step 3: Convert
When doing the conversion, the primary goal should always be to stick to auto-conversion for as long as you can. As things will change mid-way, your data will evolve, your legacy jobs, target environment or framework may change, this strategy will allow you to re-convert everything from scratch without losing all (or at least most) of the progress made so far.
Typically, data warehousing in SAS ranges in size from hundreds to thousands of jobs, and many thousands transforms (also known as nodes) within those jobs. SAS DI has almost a hundred different built-in transform types. We can break them into four categories by typical usage frequency:
- Standard loaders, transforms, and control flow - 70-90% of all nodes
- Custom transforms - 5-15% of all nodes
- User Written transforms - 5-15% of all nodes
- Special data loaders (e.g. Oracle Bulk Table Loader) and other nodes - <5% of all nodes
The high-level process is iterative and looks like this:
- Pick a new batch of jobs. Small at first, but exponentially growing with each iteration. The goal is to add new types of transformations and new data sources gradually (see Step 2 about agile data onboarding)
- Analyze and create templates for custom and user written transforms
- Auto-convert, test, and adjust templates if necessary
- Repeat
Let's explore conversion of each transform type category in more detail.
Standard loaders, transforms and control flow
The most popular category by far includes such notorious transforms as Extract, Loader, Join, etc. Luckily, most of these can be expressed as clean and readable SQL or have corresponding components in a target low-code tool. Thus, they not only can be auto-converted but also the output of automatic conversion will already be optimized, clean, and follow the target toolset best practices.
Here is an example of a Lookup transform template for the DLT target side by side with the resulting auto-converted code:
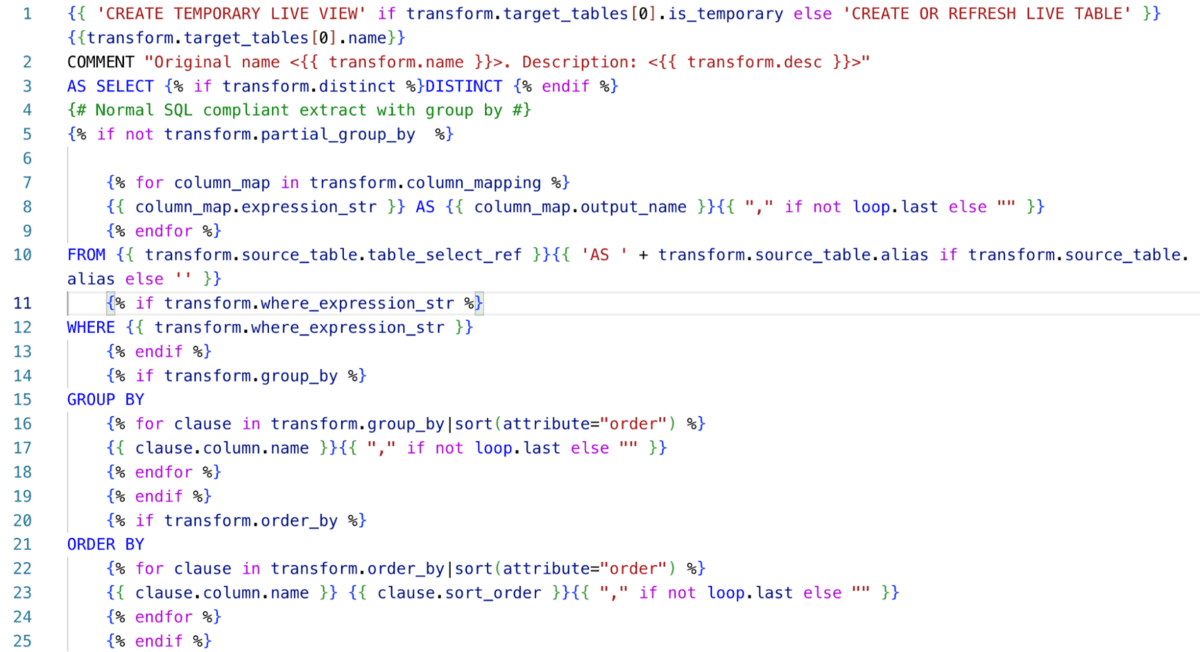

Thanks to DLT's full support of SQL, the output of conversion is clean, readable and optimal code. But that's not all - templates can be extended further. For example, if you are using SAS lookup exceptions, you can translate them into DLT data quality expectations.
Despite SAS having many quirks that can trip up conversion, understanding the transform's metadata helps generate quality code and avoid pitfalls. Things like correctly casting a type of unmapped column, handling SAS SQL non-ANSI group by behavior, arithmetic calculations on date formatted columns - such things are hard to spot without knowing dataset schemas. Some strategies are used to infer it, but in the end, they demand manual "integration". However, in the context of SAS DI (and other metadata-based sources like SAS Enterprise Guide) and armed with conversion based on templates, it can be easily handled.
Benefit #3: SAS metadata gives you a precise understanding of column types and formats, which in turn allows correct auto-conversion and type casting not possible when using other approaches.
Custom transforms
What's great about these is that they are, by definition, repeatable. However, one crucial thing to keep in mind is that custom transforms are usually parametrized, so the template used by convert should support that.
For example, Alchemist allows "plugins" that extend a template's capabilities. They enable running arbitrary preprocessing code in python that can affect rendering of templates. Here is an example from our sample job:

This code extracts custom transform properties that then are feeded into the template:
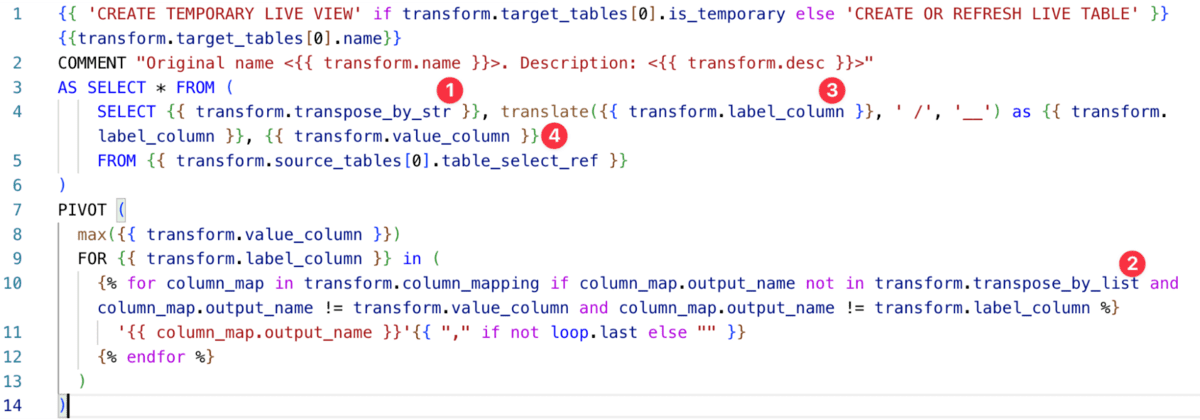
So now, we can handle any occurrence of this transform. And we only had to create a single template instead of converting the similar but slightly different materialized code with specific parameter values. In real life, you'll find these custom transforms in hundreds of ETL processes, so we are talking two orders of magnitude of acceleration!
Benefit #4: Using flexible, dynamic templates for custom transforms delivers tremendous acceleration while making the whole process less error-prone and more efficient.
User written transforms
Unlike everything else, this can be a pretty arbitrary code, so the overall conversion approach is similar to any other code. Depending on the size and complexity of it, you can either do a manual conversion or use SAS code-conversion tools.
However, even for User Written transforms, understanding of metadata yields significant benefits:
- Your output datasets are "mapped", so you can hint the output schema to code conversion (in Alchemist, we output a properly type casted schema template to help conversion for this very reason, see the screenshot below)
- This also helps basic testing since you can immediately run an auto-converted job even before the user written code is done (it won't allow for data comparison, but you can see if the job is technically valid)
- It is quite often for the same code to be used over and over. Unlike Custom Transforms, there is no indication of that in metadata. However, you can do text analysis and identify the same or similar code, which allows you to apply the same templated approach as with custom transforms (the code affinity is one of the analysis outputs of Alchemist)

Benefit #5: the metadata-based approach allows you to isolate user-written code snippets and efficiently run text analysis on top of if, which dramatically reduces the conversion volume and enables template usage.
Special data loaders
These include Hadoop, Oracle, Microsoft, SOAP, and other specialized nodes. Most of them become obsolete, since by the time of conversion, your data should already be onboarded and available in your data lake (see Step 2 above). For those cases when you still need them, multiple options exist:
- Integrated Reverse ETL tool from Databricks Partner Connect
- A new framework component
Whatever you use, a dedicated template for such nodes would allow this to be fully auto-converted. And when the transform is obsolete - well, you can filter it out. And if you use DLTs, which automatically creates job DAG, you do not even need to bother about maintaining dependencies after filtering nodes.
There are other benefits, such as the ability to do auto-refactoring (e.g. change naming conventions), clever handling of comments, and others. But we had to stop somewhere.
Step 4: Validate
First of all notice that we've omitted the Integration step. Although nothing can be 100% automated, and you'll face edge-cases where you need to integrate the result manually, the size of this step is significantly smaller and thus we decided to skip over it.
However, you still need to do extensive validation. The process itself is not different from a manual migration, as you'll need some toolkit and approach to compare the outputs of the original jobs with the new migrated ones. We will not dive into it here, but you can watch a recent webinar on SAS migration from this webinar series where we've discussed this topic in more detail.
The silver lining is that the automated template-based approach makes this process easier and faster. Your migration team is free to re-convert anytime they find a bug as often as they need since the conversion is almost instantaneous. This is another reason why manual integration should be a measure of last resort, as it will have to be reapplied and will slow down the process.
Final result
Let's summarize what all of these benefits bring:
- High level of automation
- Flexibility and resilience to project changes, especially important in large-scale projects
- Ability to generate output that follows your specific coding guidelines
- Ability to migrate to plain notebooks, DLT or even integrated low-code tools available in Databricks Partner Connect like Prophecy or Matillion
- Job execution speed improvements anywhere between 3x to 30x and up-to 10x lower TCO (based on multiple reference projects)
Once again, here are our jobs in SAS DI & Databricks DLT side-by-side. All generated automatically end-to-end:


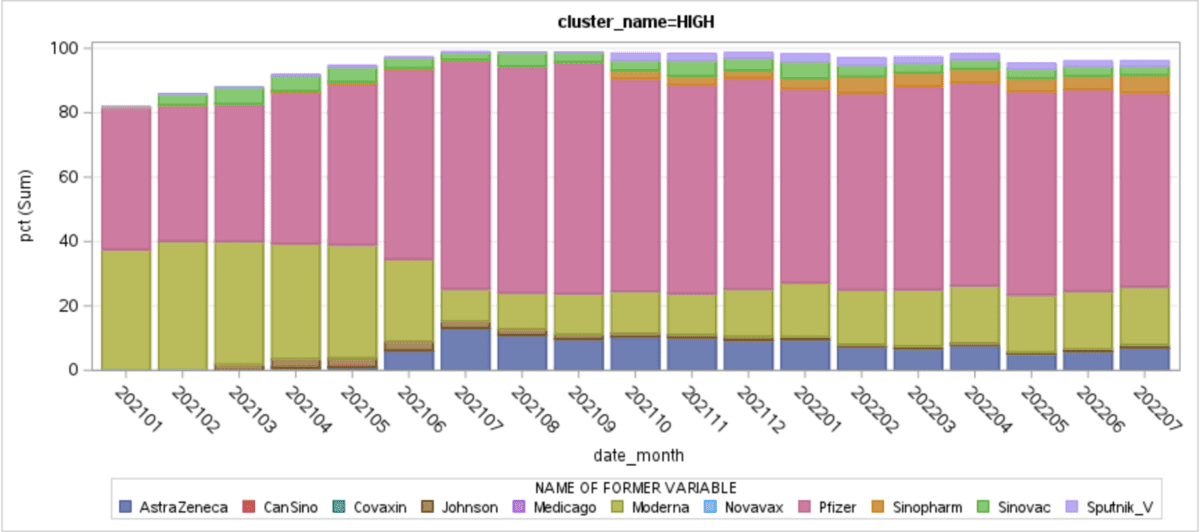
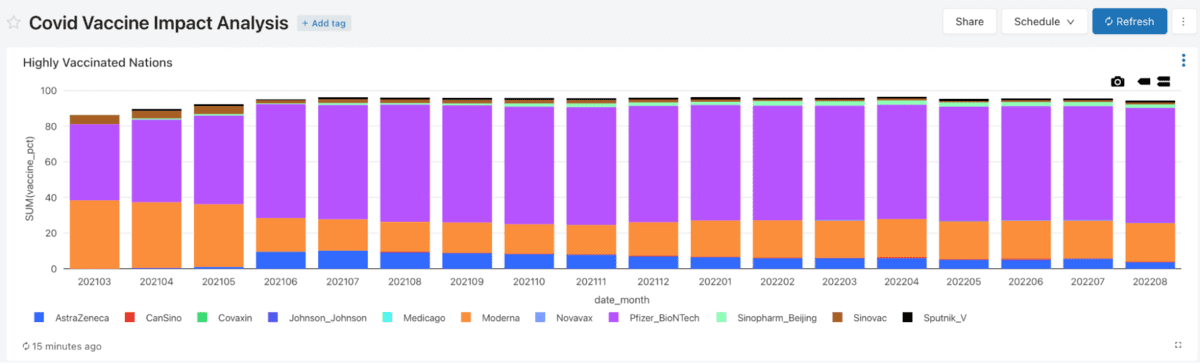
The resulting report shows how vaccine popularity changed through the pandemic for various clusters (by overall vaccine adoption) of countries. Compare the SAS Studio version with Databricks SQL:
Next steps
As you are planning your SAS data warehouse modernization and move to the Lakehouse architecture, here are the ways Databricks & T1A teams can help you accelerate and make the process painless:
- Databricks migrations team is always available to share best practices and support you along your journey. Feel free to reach out to us at Databricks
- Get a free analysis of your SAS jobs & code using Alchemist from T1A - just send a request to databricks@t1a.com
Remember that you're not alone, as many of your peers are either far down the same path or have already completed the migration. These projects have already yielded repeatable best practices, saving organization's time, money, resources and reducing overall stress.
SAS® and all other SAS Institute Inc. product or service names are registered trademarks or trademarks of SAS Institute Inc. in the USA and other countries. ® indicates USA registration.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.