Generate More Insight By Connecting GameAnalytics to Databricks
by Randy Akerman and Huntting Buckley
We’re excited to announce a joint effort between Databricks for Games and GameAnalytics. This blog and associated code will help our mutual customers ingest data from GameAnalytics into their Databricks Lakehouse. This enables you to perform additional analysis, machine learning and data integration leveraging data from GameAnalytics, internal systems and other third party data providers. This data integration is critical to get a full understanding of your player, your game, your marketing efforts, in fact most every aspect of your business.
For those of you not familiar, GameAnalytics is a top provider of analytics and market intelligence for mobile, Roblox, PC, and VR games, offering powerful tools that deliver deep insights into player behavior and external market dynamics. With over 13 years of industry expertise, their data-driven tools have helped developers optimize acquisition, monetization, and engagement strategies. From real-time analytics and performance reporting to LiveOps capabilities and market insights, GameAnalytics supports every stage of development - whether you’re building, growing your audience, or optimizing your portfolio at scale.
For this solution we start with a pattern that will work for any data source that lands in S3 for customers using Databricks on AWS. We then leverage Delta Live Tables (DLT) as our processing engine as it includes features that will make our life easier across ingestion, transformation and quality validation. The data payload is a JSON package that we explode and split across a series of tables. From there we leverage data quality checking features within DLT to enforce standards and expectations from the data. Finally we show a few ways to make this data useful within the platform.
This solution compliments our similar releases for the AWS Game Backend Framework and PlayFab. If you have a critical games specific data provider you’d like us to integrate with please reach out through your account team. We’d love to collaborate with you, your team and your partners further.
Getting Data From GameAnalytics into Databricks
We’re going to start by using the GameAnalytics Data Export notebook. In this notebook we create a storage credential so you can access your cloud storage. We’ll then create an external location in Unity Catalog and finally grant access permissions to your users. Once this is done your data applications will be able to easily read and write to your Databricks environment.
In the DLT UI: Scheduling. While in Development mode it’ll keep the clusters up for you so that you have a better interactive experience. Once done you migrate the pipeline into Production by clicking the production button which will cause clusters to spin up when needed and down when not. The second step for productionalizing this will be to set a schedule. While you could schedule this pipeline via an S3 listener the fact that it is batch and arrives every 15 minutes makes that overkill. Instead we’d schedule it via cron at that interval to get the latest data. Databricks makes scheduling really easy for you, see below screenshot.
Splitting the Data Apart
Now that we have a place for our data to land we’ll leverage DLT to produce a medallion architecture for our datasets. If you aren’t familiar with the medallion architecture it moves progressively from Bronze (Raw) to Silver (cleaned and conforming) to Gold (Curated, business-level datasets for reporting) and is the general best practice for data ingestion pipelines. By leveraging this architecture we can ensure improved data quality, scalability of your pipelines and query performance. To learn more about the medallion architecture, see here.
We start the process by loading your data from S3 without any transformations enabling auditing, debugging and reprocessing if needed. We augment this layer with additional metadata such as timestamps, original file path and filenames so that data engineering can track data to its source, troubleshoot issues and efficiently process in subsequent stages. The notebook shows how you add this metadata and the schema we suggest here. Of particular note is just how easy it is to load data into Databricks. By leveraging DLT and our Auto-loader functionality the code is quite straightforward.

GameAnalytics provides schemas for each event type that we’ll have to translate into our pipeline. By using these resources to validate incoming data we can enforce the schema during the data ingestion process, ensure data consistency, confirm data quality and resolve issues early in the data pipeline. Finally by enforcing standardized data formats we can better facilitate data governance and compliance requirements.
Data Quality Enforcement
Now that we have all the data into Bronze it’s time to build out our silver layer. This is the bulk of the code within the notebook as it defines the schema, adds metadata for the fields within the table and converts the JSON into tables. You now have datasets that you could use for Machine Learning efforts, GenAI or to create your gold layer to support specific teams, business requirements and reporting. Now that these datasets are in Databricks you can easily connect whatever visualization tool that you’re using, or AI/BI Dashboards. You can also take advantage of advanced features within Databricks like AutoML, AI/BI Genie Spaces. Your team is now in the driver’s seat for insight generation and are able to uncover unique linkages for your company that a tool, even a best of breed one like GameAnalytics, might not have built-in.
For the purpose of this accelerator we haven’t taken it all the way to Gold Tables as those are generally specific to your organization and something that you would build out with your lines of business. Over time we’ll evolve this solution accelerator to show how it can address specific use cases and team requirements. For the remainder of this blog we’ll show how, even stopping at Silver, you can leverage Databricks to glean insight and value from your GameAnalytics Dataset. GameAnalytics have provided us with dummy datasets we could use to visualize our silver tables across a series of use cases. Keep in mind that the data is generated so the output is indicative, but not real.
Example Use Case: Campaign Impact
Take the case of an ads supported game. In this Lakeview visualization we see the number of ads impressions for the title over time broken out by marketing campaigns. As a generated dataset we see a very consistent view across all the campaigns. We see a healthy growth curve but a sudden drop off. We aren’t really able to tell which of these campaigns are performing better than others from a financial perspective, however.
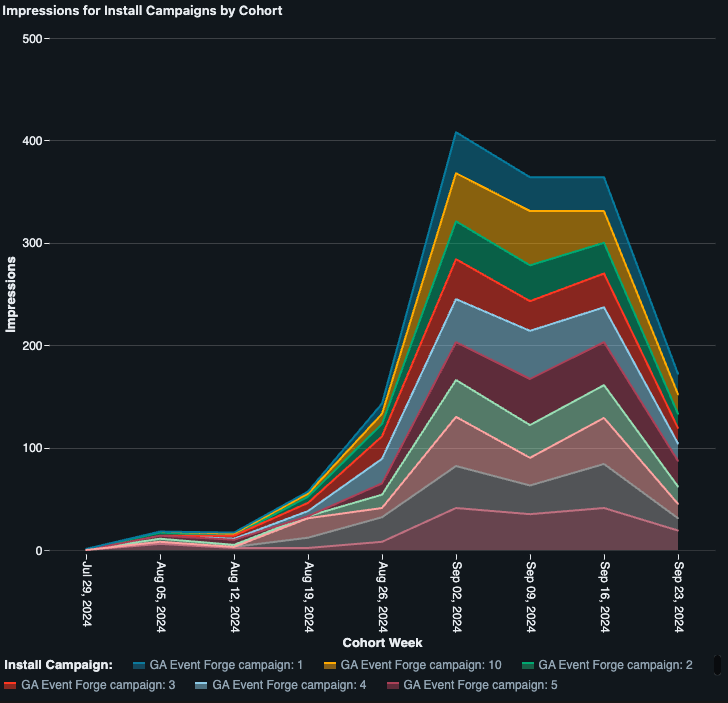
Since we have the datasets themselves we can easily create a different visualization to help us solve the question of “which campaigns are most impactful” but if that weren’t the case we would look for campaigns that brought in high performing, and low performing, users and reflect on the campaigns and sources that led to their installing the game. This would help us to understand the impact of our ads spend and realign our spending for future User Acquisition (UA) efforts.
While the above visualization is great for understanding how your game is performing as a whole it isn’t very helpful with understanding the performance of specific campaigns and their cohorts. In this case we leverage how Lakeview makes it easy to change up your visualizations on the fly using the same dataset and have created this bar graph instead.
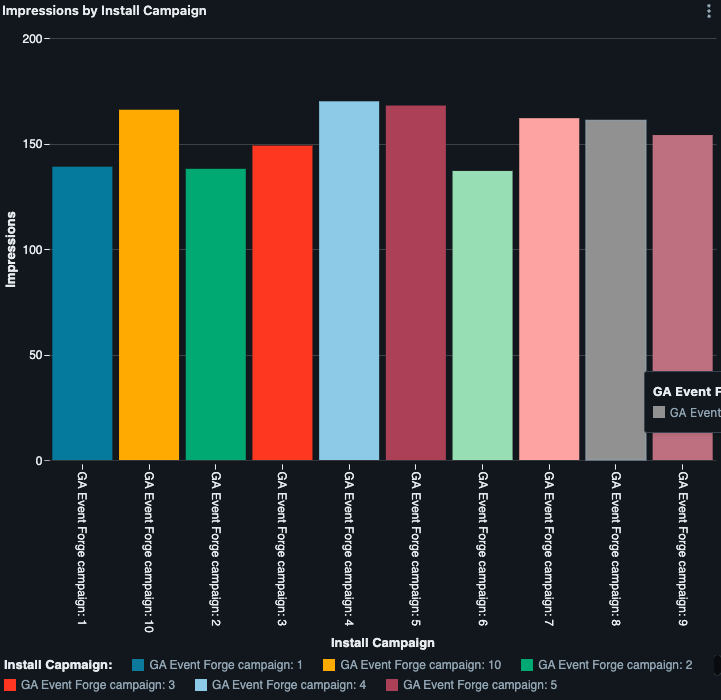
From here we might take advantage of AI/BI Genie spaces to dig into understanding more deeply the why behind what we see here. Why did Campaign 1, 2 and 6 perform poorly? Were they through a specific ads provider, did they use different creatives, did we have releases around that same time. This type of Q&A for your data is made easy with Genie Spaces.
GameAnalytics provides you the opportunity to create custom fields as no two games are fully the same. In this dataset one of the custom fields is the character type of the player: Archer, Mage and Warrior. We were curious if there were any patterns we could find related to the campaigns and which character type was selected. Did the creative used for, or the timing of, the campaign resonate more with a specific archetype? As a first step we took revenue by install campaign and created a Pivot Table that showed the breakdown by the character field.
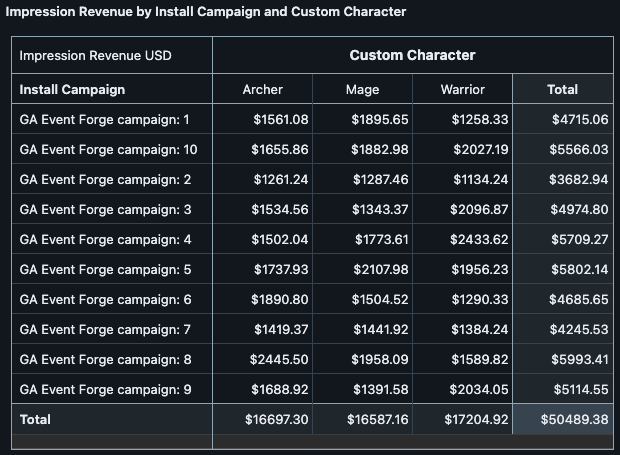
We had identified Campaign 1, 2 and 6 as low performing. Looking at it through this lens we see that Campaign 1 brought in higher value Mages, though not as high value as 5. We also see that Campaign 2 was poor across the board, we should see what made it different and try to avoid that again. Finally in Campaign 6 we brought in the second highest grossing Archer group: What was true across this campaign and #8 that we can potentially leverage the next time we do a content drop heavily Archer focused?
Having a conversation with your new datasets
Now that this data is in Databricks you have all of the platform’s capabilities available to you. This includes advanced machine learning, statistical analysis and other data applications. As we continue to evolve the platform a focus of ours is to put the power of insight generation in the hands of the business owner. While we don’t wish to disintermediate the data team, we want to help the conversation between data teams and their business partners. We also wish to minimize low value and repetitive tasks for the data teams.
One such way we are evolving is through our AI/BI capabilities. If you haven’t read our blog on AI/BI Genie Spaces, check it out. GameAnalytics provides you with a wide variety of data points that are useful across your business. Knowing, upfront, which dashboards, which KPIs, which joins and what questions your business teams are going to ask is not feasible. By taking advantage of AI/BI you can create a chat interface into the datapoints GameAnalytics provides and other related first party datasets. We will further explore the value of doing so in this section. Let’s create a genie space with what we’ve gotten from GameAnalytics.
You’ve created an AI/BI Genie Space, you’ve given it to your business team and said “now you can ask questions of your data! Congratulations.” (please don’t do that!) While your business team understands their business context, the potential data, they don’t know what’s in this space or necessarily what each column means. So they start their journey asking Genie to describe the data in this space.
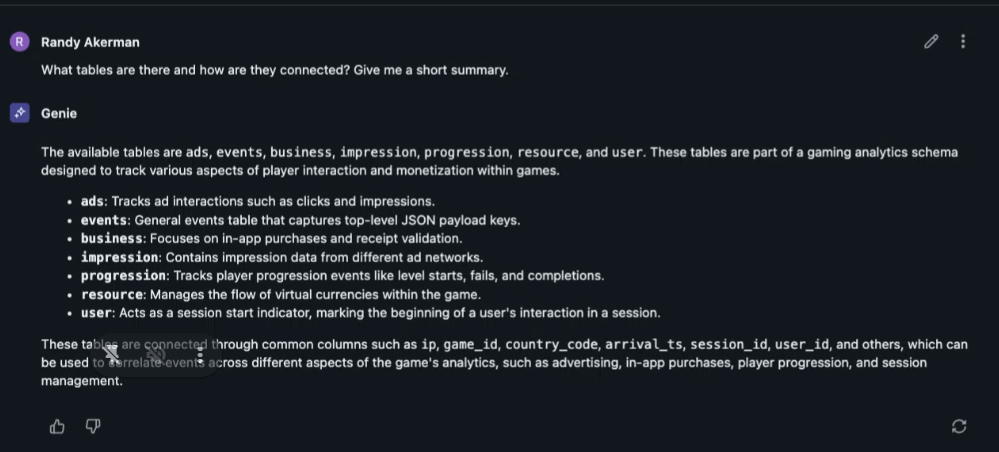
We see that there’s information about ads, monetization, progression and details about user sessions. For a business leader that understands datasets as a whole, this will all make sense to them. They’ll be able to jump in and ask interesting questions within the context of their role. This isn’t always the case, however, and provides us another example of how AI/BI can help unlock insight. We’re going to ask the room for example questions “what questions can I ask of these datasets.”
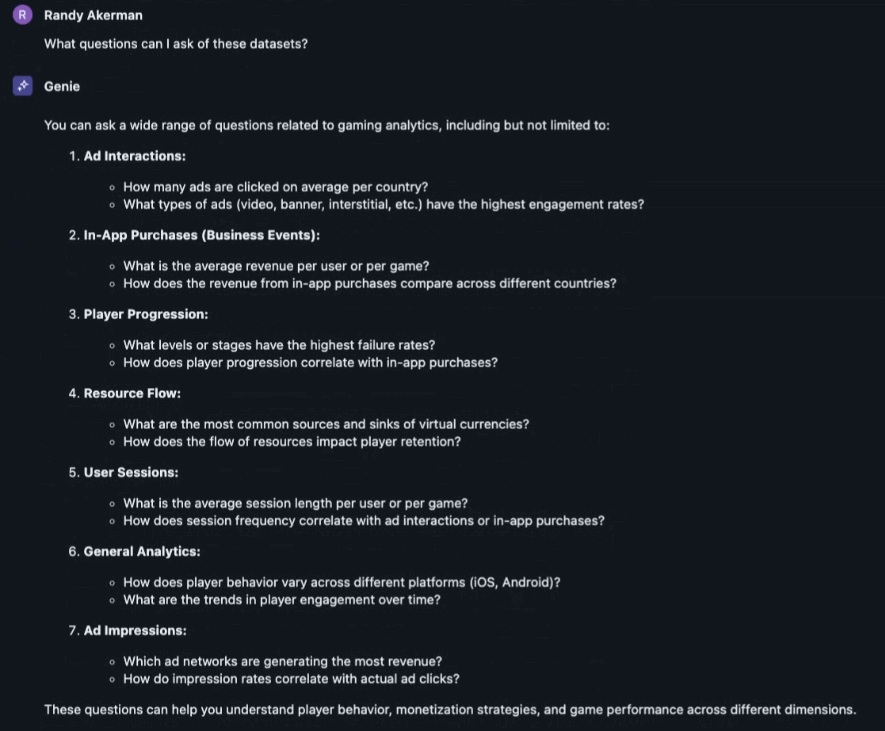
The model looks at the data and comes up with a series of really helpful questions on its own. When creating the space you can add your own questions to help your users get into the right mindset.
This isn’t magic, iteration improves outcomes
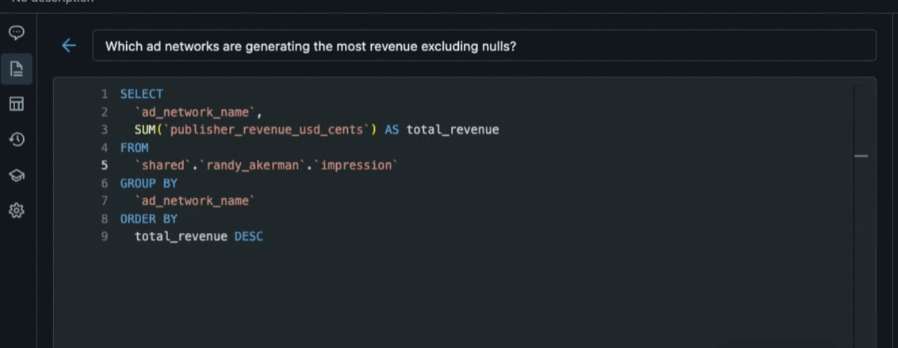
Based on the questions proposed we decided to dig into revenue by advertising network. When we ask the system to show us which ad networks are generating the most revenue, excluding (null) networks we get an answer, but obviously something is wrong here. Your end user would come back to the data team and ask for help. That team would be able to see the history of the conversation, infer the desired outcome and help debug what’s going on. This exemplifies why the tool has a drop down to show you the generated code.
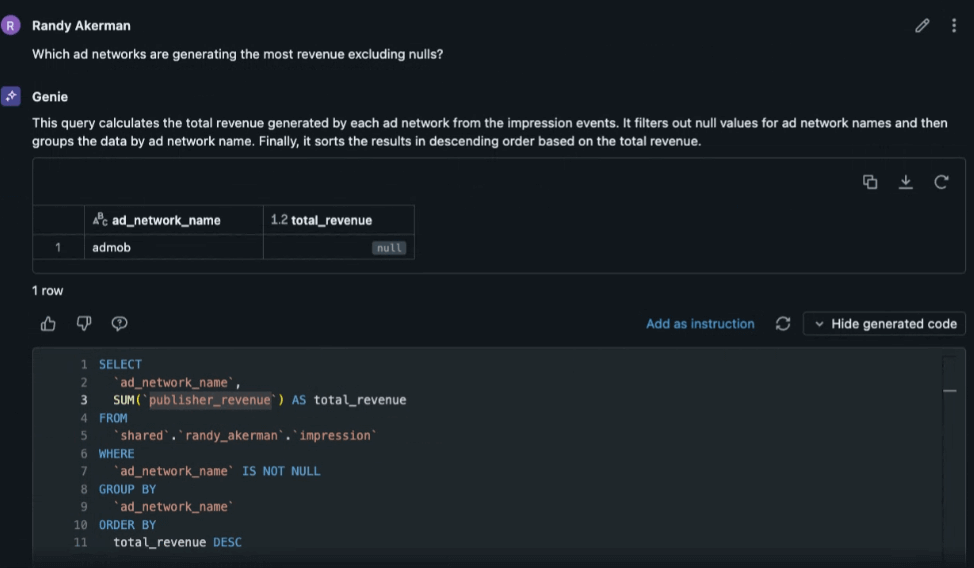
Here we see that total_revenue is being aggregated from ‘publisher_revenue’. When we look at that column we see that this column has the currency type listed, not the amount of revenue generated. The correct column is `publisher_revenue_usd_cents`. Since AI/BI Genie spaces aren’t black boxes you have the ability to add example questions, and queries, to help inform Genie going forward.
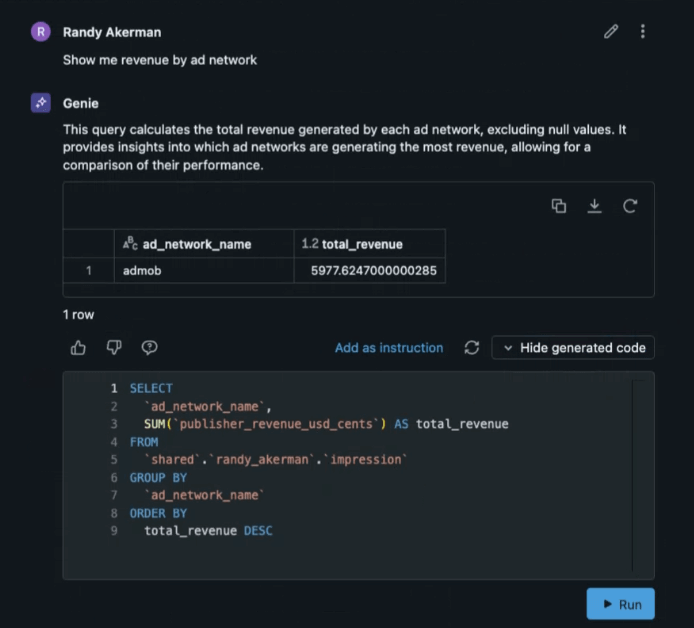
Now that we have added this question and the corrected query into the space, we can validate that it fixed our problem. To show that the input we provided is greater than just a “if I get this exact question, answer this way” and instead helps the space better understand the data, we ask a slightly different question. “Show me revenue by ad network.” With this query we would hope that revenue would now reference the `publisher_revenue_usd_cents` column. And here we see that it does.
In Summary
This solution accelerator shows:
- How to get data out of GameAnalytics and into Databricks
- A repeatable approach for doing the same with other data sources
- The value of having your core data in a data platform that you can use for insight generation
- Some ideas on how different capabilities found within Databricks, like Lakeview Dashboards and AI/BI Genie spaces can be a part of your insight discovery process
We feel privileged to have the opportunity to work with wonderful partners like GameAnalytics and to help the community bring the fun to their players. Obviously this is only step one, a single data source. If it were just about this data source you could work with the data provider, GameAnalytics in this case to add visualizations and insight that you need but aren’t built into the platform. By bringing this data, data from other third party services and your first party generated data into your data platform, you unlock greater value for the organization.
You can find the code for this solution accelerator here. If you’d like to connect with GameAnalytics for ingestion support or to hear more about their Data Export solution, please reach out to [email protected]. If you’d like to talk with the team behind this connector, the approach, or discuss the data challenges you are trying to solve for please reach out to your Databricks Account Team. We’re here to help.
Ready for more game data + AI use cases?
Download our Ultimate Guide to Game Data and AI. This comprehensive eBook provides an in-depth exploration of the key topics surrounding game data and AI, from the business value it provides to the core use cases for implementation. Whether you're a seasoned data veteran or just starting out, our guide will equip you with the knowledge you need to take your game development to the next level.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.