Guest Post: Using Lamini to train your own LLM on your Databricks data
by Sharon Zhou
This is a guest post from our startup partner, Lamini.
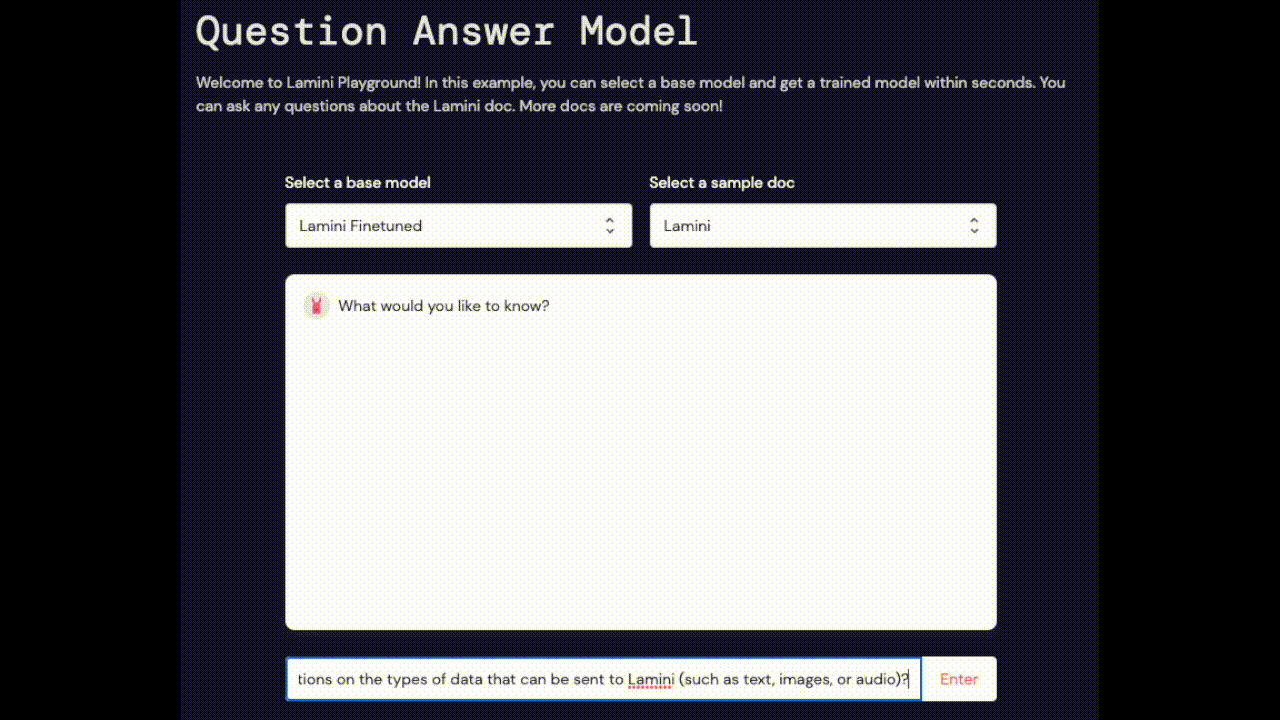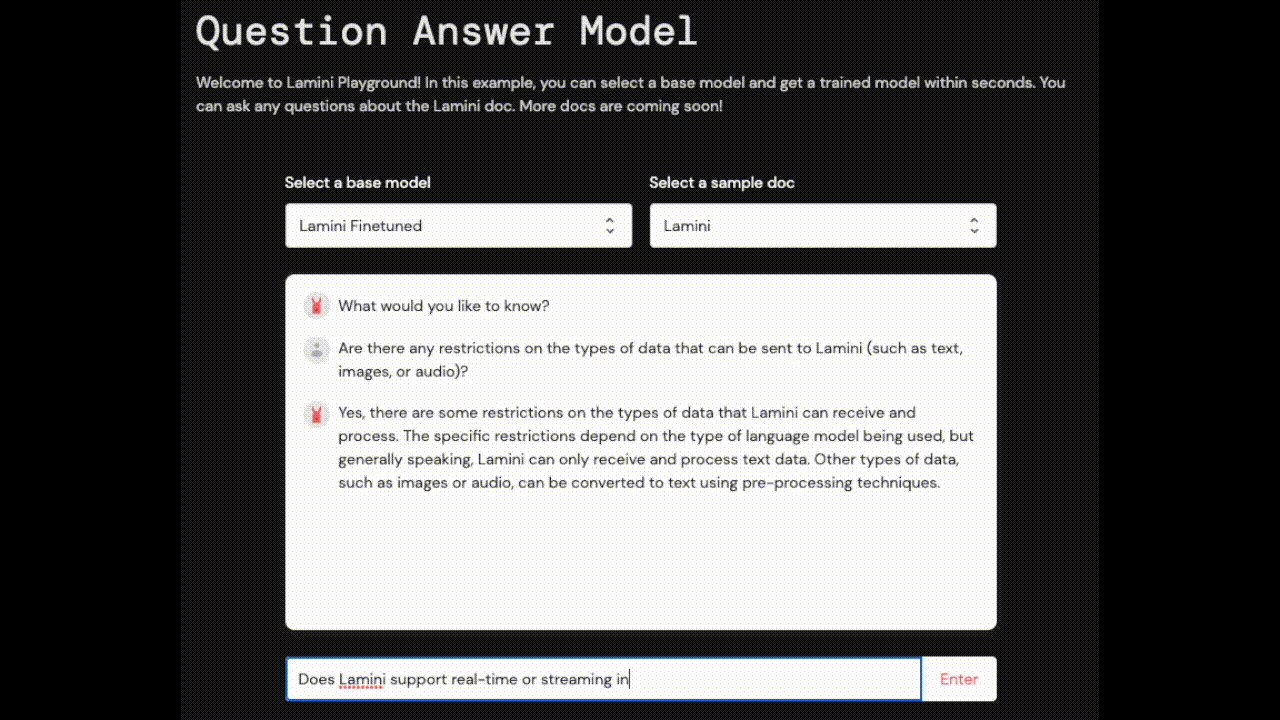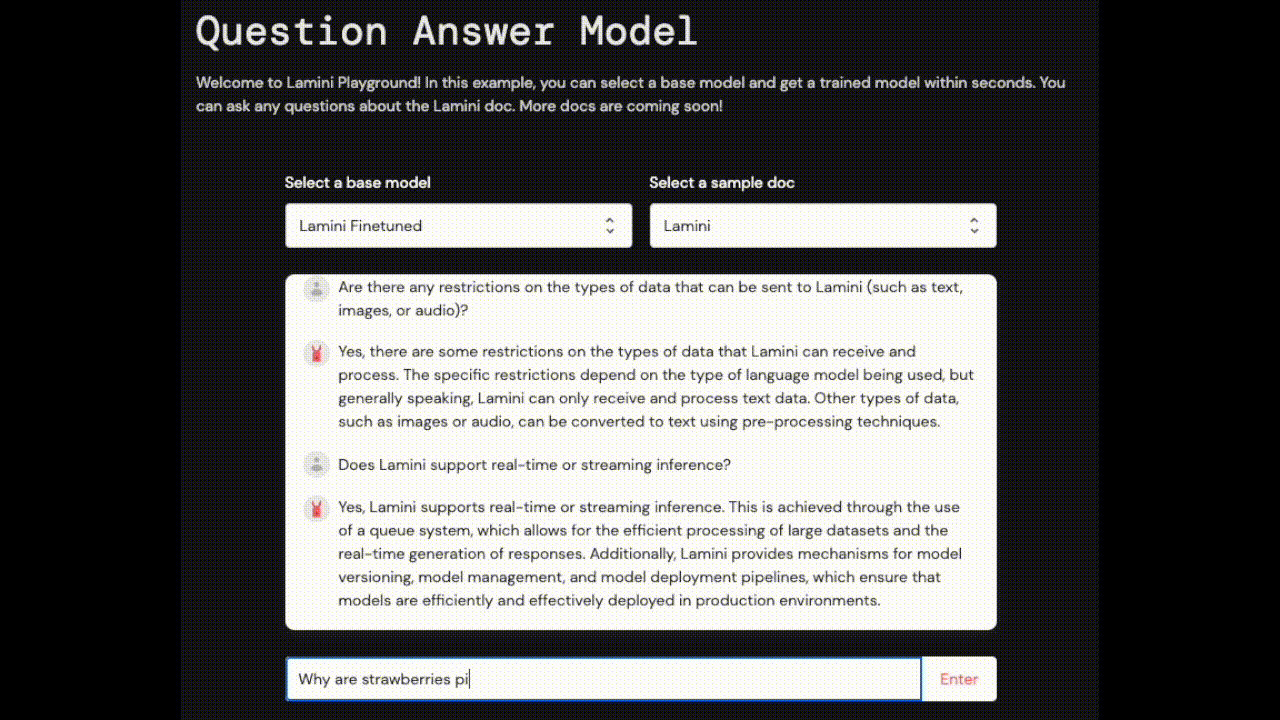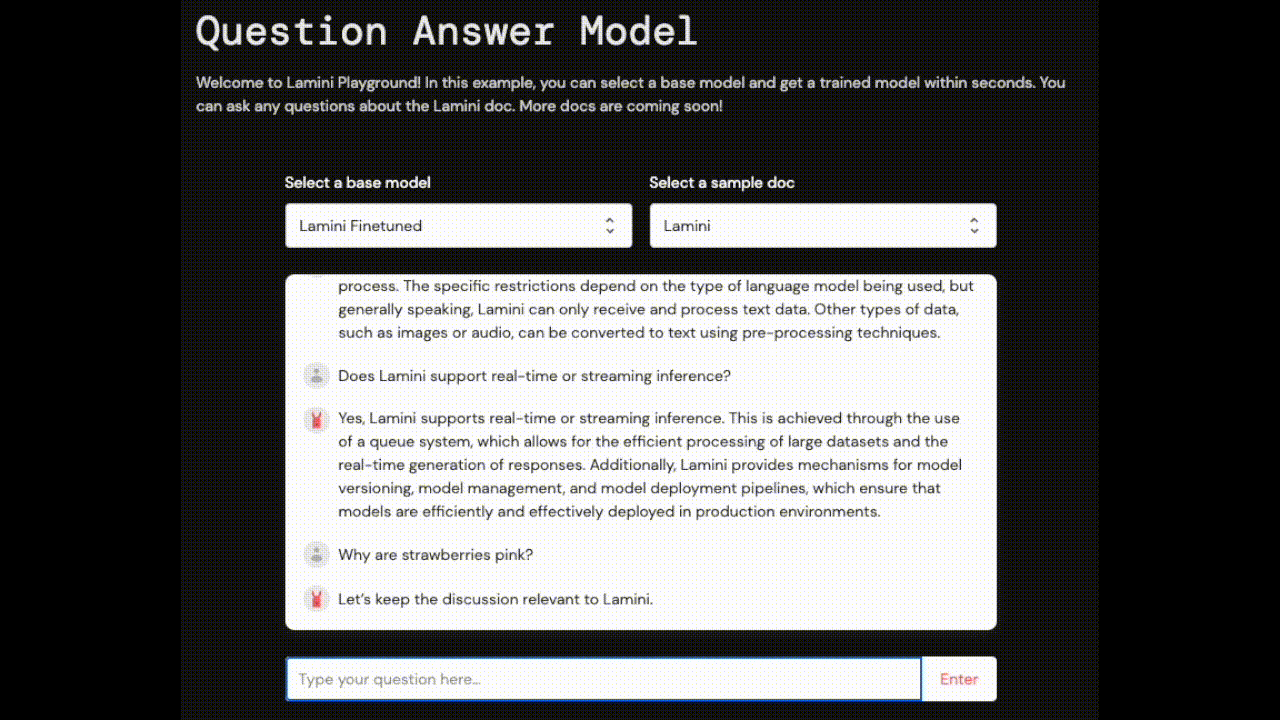
Play with this LLM pictured above, trained on Lamini documentation. Live now!
You want to build an LLM for your business — and you're not alone with over 20% of the S&P 500 bringing up AI in their earnings calls in the first quarter this year (2023). LLMs can add magic to your product, delighting your customers and increasing your top line. Customers can answer their own questions in seconds, accessing all of your documentation, including personalized information. And every new feature would be 10x faster to build with a copilot, reducing your engineering and operational costs.
But public LLMs, such as GPT-4, are almost entirely trained on someone else's data. They're good, sure, but lack personalization to your data and your use cases. Imagine how powerful GPT-4 would be if it were tuned to your business in particular!
To make matters worse, you can't just hand your most valuable data over, because it's proprietary. You're worried about data leaks and the promises you've made to your customers. You're worried about sending all your IP and source code to a third party, and giving up the data moat you've worked so hard to build. You're worried about the reliability and maintenance of these AI services as they adapt so quickly that new versions break your critical use cases.
Your other option is to hire dozens of top AI researchers to build a private LLM for you, like Github did for Github Copilot or OpenAI did for ChatGPT, which took months to build, even though the base model GPT-3 had been out for years. Either solution is slow and costly, with very, very low ROI. So you feel stuck.
We're excited to announce a new product that empowers developers to create their own LLMs, trained on their own data. No team of AI researchers, no data leaving your VPC, no specialized model expertise.
Customers have told us they couldn’t have gotten to this level of LLM use and accuracy without Lamini. They’ve also told us their own LLM trained with Lamini was the best and closest to their use case in a blind test, comparing the model to ChatGPT with retrieval.
But first: why train your own LLM?

ChatGPT has wowed many. But from the perspective of AI researchers who have been in the field for decades, the promise has always been in models trained on your data. Imagine ChatGPT but tailored to your specific needs and content. There are a few reasons why training your own LLM makes sense, both in the short and long run.
- Better performance: You want consistent outputs from the LLM, and you want it to stop hallucinating, such as making false claims or bringing up your competitors. You want better performance for your use case like an expert with decades of time to scan through all your data would. Nothing substantial fits into the tiny prompt relative to your gigabytes or terabytes of data.
- Data privacy: You want the LLM to access your private data, while keeping everything on your own infrastructure. You don't want to send anything to a third party, because a breach would be a major threat to your business. And you don't want your proprietary data (or derivatives of it) being used to improve a general model that could benefit your competitors or threaten your data moat.
- Cost: You want to run at a lower cost. Off-the-shelf solutions can become prohibitively expensive with frequent usage by customers.
- Latency: You want to choose and control latency over time. Off-the-shelf APIs are often rate-limited or too slow for your production use cases.
- Uptime: Off-the-shelf APIs have inconsistent uptime, with < 99% uptime for even the best solutions. You want your DevOps team to have control over the servers instead of a third party where other customers are fighting for usage at high-traffic times or if there's an outage.
- Ownership: You want your engineering team to build it without hiring dozens of new ML experts. And you don't want to contract professional services because your engineers know your products and data best, and you'll need to refresh your LLM constantly because of how fast the field is advancing.
- Flexibility: You want to control which LLM providers or open source solutions you use, so you can adapt your modeling stack to your use case and custom applications.
- Bias: Off-the-shelf models have biases. You can train the LLM to unlearn biases along dimensions you care about through training.
- Content control: You have control over the training data you provide to the model, which is important for mitigating inappropriate and unlicensed content, meeting legal requirements of properly licensed, relevant data. Some base models are more transparent about the data they've been exposed to, and you can select a base model based on that.
How training your own LLM works
The idea of training your own LLM might seem daunting. It's a lot of code and expertise to get your data in the right format to improve the LLM beyond the base model, and to host it reliably on your own infrastructure and GPUs. The Lamini library simplifies the process down to writing a small amount of code and accessing your existing data in Databricks.

- First, Lamini connects to your Databricks cluster with a quick installation. You point to the important data that you want your LLM to be exposed to and align the grain of your data.
- Then, Lamini automatically manages the infrastructure: base model selection, data transformation for training, retrieval-augmented training, parameter-efficient fine-tuning, data generation, auto-evaluation, etc. This infrastructure is normally built by AI researchers and AI infrastructure engineers over the course of several months, and maintained over time. Both high and low level functions are available through code and hosted notebooks.
- Finally, your data and custom LLM stay in your VPC throughout the training process. From here, you can train more LLMs for different use cases and different data all across your organization.
Now, let's see an example of a private LLM that outperforms ChatGPT in action. Or just start playing with it now.
Case study: Training an LLM on your internal engineering documentation
You have a huge amount of internal engineering documentation. You want to chat over them like ChatGPT, so you can have an internal wiki of your codebase and be able to ask questions about areas that don't require you to learn the specific architecture or get help debugging errors from another team that impacts your work. But ChatGPT isn't aware of your entire codebase, cannot make reliably accurate connections across it, makes up new convincing knowledge that is not actually true, and cannot steer the conversation back to relevant topics.
Take the example of chatting over Lamini's engineering documentation.
Here are comparisons of giving an LLM all of your data, compared to prompt-engineering ChatGPT with retrieval:
| User's question | Private LLM Trained with Lamini and Databricks Data | ChatGPT + Retrieval |
|---|---|---|
| Are there any restrictions on the types of data that can be sent to Lamini (such as text, images, or audio)? | Yes, there are some restrictions on the types of data that Lamini can handle. The documentation provides guidelines for optimizing the data format and ensuring privacy and security. | Lamini AI supports multi-modal inputs, such as combining text with images or audio. |
| Does Lamini support real-time or streaming inference? | Yes, Lamini supports real-time or streaming inference. This means that the model can be updated in real-time and can generate results in real-time, making it suitable for applications such as chatbots or virtual assistants. | No, Lamini does not currently support real-time or streaming inference. |
| Why are strawberries pink? | Let's keep the discussion relevant to Lamini. | I don't know. |
Table: Please note that the results are always improving on our live version, so expect some differences.
ChatGPT with retrieval doesn't have sufficient context to synthesize information, so it frequently hallucinates, such as the first example in the table above, where it says that Lamini "supports multi-modal inputs, such as combining text with images or audio," which is not the case.
It has read only <1% of the data to make a decision and will miss information that does exist, e.g. when retrieval fails, such as in the second case in the table above where it says "No" when the real answer is in fact "Yes". In many of these cases, prompt-engineering is simply not enough.
Compare this to the LLM that is trained on 100% of the Lamini documentation. It knows the specifics, aggregates information from disparate sections of documentation, and can steer the conversation back to what is relevant ("Let's keep the discussion relevant to Lamini" as opposed to just "I don't know"), as it was trained to do.
Play with this LLM live now! Just use your Google account to sign into Lamini and start asking questions.
3 steps to train your own LLM on your Databricks data 1️⃣2️⃣3️⃣
Here are the steps you need to get the same LLM on your own documentation (or other data) that is faster and better than anything else out there:
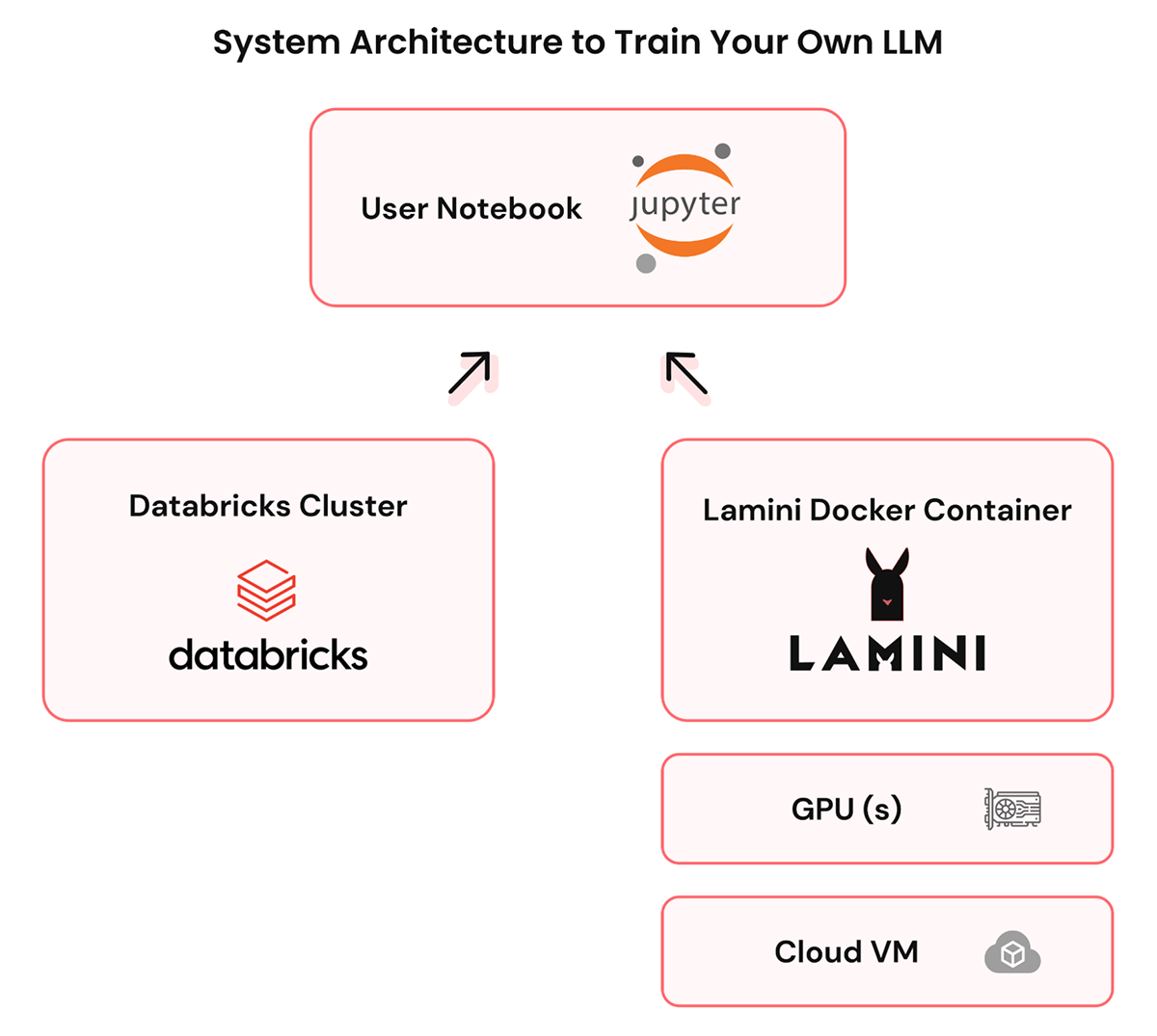
Step 1: Set up Lamini in your Databricks environment. Create a VM in your Databricks VPC and install the Lamini docker in it.
- Create a GPU instance that can run an LLM, i.e. modern Linux (e.g. Ubuntu), T4 GPU or higher, 100GB of disk
- Install GPU drivers and the Docker runtime
- Install Lamini (one tar.gz containing docker containers and one install script)
- Run lamini-up to bring up the Lamini service
- Open a port, e.g. 80, within your VPC that clients can access

Step 2: You point to the important data by writing code in the Lamini library to connect your data lakehouse to a base LLM. Data stays in your VPC.
- Open a notebook (e.g. Jupyter or Databricks) that can access Lamini and Databricks
- Use a Spark or SparkSQL to extract relevant data from databricks as a dataframe
- Define Lamini types matching the dataframe schema, convert the dataframe to Lamini objects
Step 3: Train your own private LLM with a few lines of code using the Lamini library. Lamini does what a team of AI researchers would otherwise do: fine-tuning, optimization, data generation, auto-evaluation, etc. This LLM is served in your VPC.
- Define a LLM using Lamini, e.g. `from lamini import LLM; llm = LLM(...., config={""}))`
- Add your data to the LLM, e.g. `llm.add_data(dataframe)`
- Evaluate the LLM, e.g. `answer = llm(question)`
Lamini empowers you to create your own LLM, trained on your own data. No team of AI researchers, no data leaving your VPC, no specialized model expertise.
You can learn all about the content in this post at the Data + AI Summit, where Sharon Zhou, co-founder and CEO of Lamini, will be hosting a session. Lamini is a technology partner of Databricks.
Join other top tech companies building their custom LLMs on Lamini and sign up for early access today!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.