Handling "Right to be Forgotten" in GDPR and CCPA using Delta Live Tables (DLT)

The amount of data has exploded over the last decades and governments are putting regulations in place to provide greater protection and rights to individuals over their personal data. The General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA) are one of the most stringent privacy and data security laws that must be followed by businesses. Among other data management and data governance requirements, these regulations require companies to permanently and completely delete all personally identifiable information (PII) collected about a customer upon their explicit request. This procedure, also known as the "Right to be Forgotten", is to be executed during a specified period (eg. within one calendar month). Although this scenario might sound like a challenging task, it is well supported while utilizing Delta Lake, which was also described in our previous blog. This post presents various ways to handle the "Right to be Forgotten" requirements in the Data Lakehouse using Delta Live Tables (DLT). Delta table is a way to store data in tables, whereas Delta Live Tables is a declarative framework that manages delta tables, by creating them and keeping them up to date.
Approach to implementing the "Right to be Forgotten"
While there are many different ways of implementing the "Right to be Forgotten" (e.g. Anonymization, Pseudonymization, Data Masking), the safest method remains a complete erasure. Throughout the years, there have been several examples of incomplete or wrongfully conducted anonymization processes which resulted in the re-identification of individuals. In practice, eliminating the risk of re-identification often requires a complete deletion of individual records. As such the focus of this post will be deleting personally identifiable information (PII) from the storage instead of applying anonymization techniques.
Point Deletes in the Data Lakehouse
With the introduction of Delta Lake technology which supports and provides efficient point deletes in large data lakes using ACID transactions and deletion vectors, it is easier to locate and remove PII data in response to consumer GDPR/CCPA requests. To accelerate point deletes, Delta Lake offers many optimizations built-in, such as data skipping with Z-order and bloom filters, to reduce the amount of data needed to be read (eg. Z-order on fields used during DELETE operations).
Challenges in implementing the "Right to be Forgotten"
The data landscape in an organization can be large, with many systems storing sensitive information. Therefore, it’s essential to identify all PII data and make the whole architecture compliant with regulations, which means permanently deleting the data from all Source Systems, Delta tables, Cloud Storage, and other systems potentially storing sensitive data for a longer period (eg. dashboards, external applications).
If deletes are initiated in the source, they have to be propagated to all subsequent layers of a medallion architecture. To handle deletes initiated in the source, change data capture (CDC) in Delta Live Tables may come in handy. However, since Delta Live Tables manage delta tables within a pipeline and currently don’t support Change Data Feed, the CDC approach cannot be used end-to-end across all layers to track row-level changes between the version of a table. We need a different technical solution as presented in the next section.
By default, Delta Lake retains table history including deleted records for 30 days, and makes it available for "time travel" and rollbacks. But even if previous versions of the data are removed, the data is still retained in the cloud storage. Therefore, running a VACUUM command on the Delta tables is necessary to remove the files permanently. By default, this will reduce the time travel capabilities to 7 days (configurable setting) and remove historical versions of the data in question from the cloud storage as well. Using Delta Live Tables is convenient in this regard because the VACUUM command is run automatically as part of the maintenance tasks within 24 hours of a delta table being updated.
Now, let’s look into various ways of implementing the "Right to be Forgotten" requirements and solving the above challenges to make sure all layers of the medallion architecture are compliant with regulations.
Gartner®: Databricks Cloud Database Leader

Technical approaches for implementing the "Right to be Forgotten"
Solution 1 - Streaming Tables for Bronze and Materialized Views afterward
The most straightforward solution to handle the "Right to be Forgotten", is to directly delete records from all tables by executing a DELETE command.
A common medallion architecture includes append-only ingestion of source data to bronze tables with simple transformations. This is a perfect fit for streaming tables which apply transformations incrementally and keep the state. Streaming tables may also be used to incrementally process the data in the Silver layer. However, the challenge is that streaming tables can only process append queries (queries where new rows are inserted into the source table and not modified). As a result, deleting any record from a source table used for streaming is not supported and breaks the stream.

Therefore, the Silver and Gold tables need to be materialized using Materialized Views and recomputed fully whenever records are deleted from the Bronze layer. The full recomputation may be avoided by using Enzyme optimization (see Solution 2) or by using the skipChangeCommits option to ignore transitions that delete or modify existing records (see Solution 3).
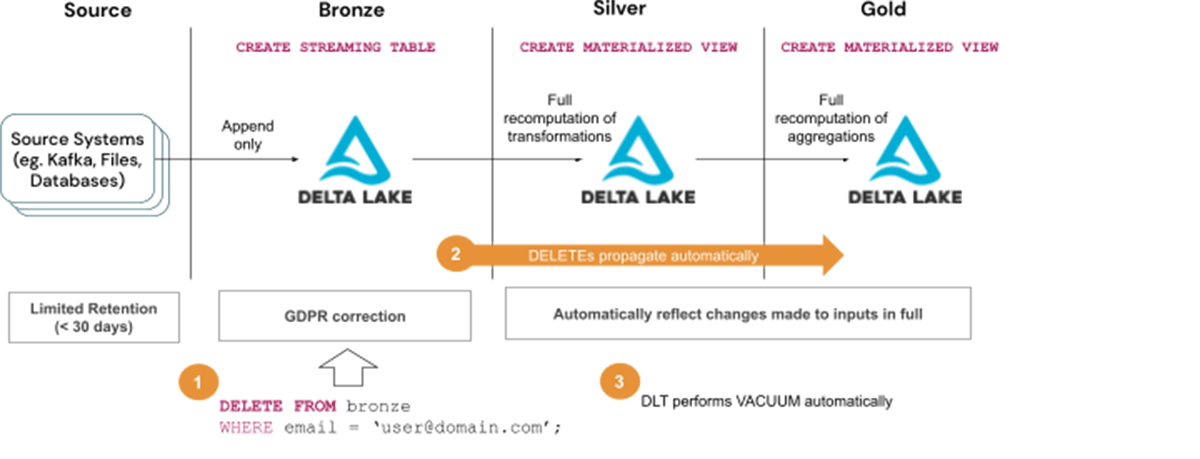
Steps to handle GDPR/CCPA requests with Solution 1:
- Delete user information from Bronze tables
- Wait for the deletes to propagate to subsequent layers, ie. Silver and Gold tables
- Wait for the Vacuum to run automatically as part of DLT maintenance tasks
Consider using Solution 1 when:
- The type of query used is not supported by Enzyme optimization, otherwise, use Solution 2 as described below
- Full recomputation of tables is acceptable
The main disadvantage of the above solution is that the Materialized Views must recompute the results in full which might not be desirable due to cost and latency constraints. Let’s look now at how to improve this by using Enzyme optimization in DLT.
Solution 2 - Streaming Tables for Bronze and Materialized Views with Enzyme afterward
Enzyme optimization (in private preview) improves DLT pipeline latency by automatically and incrementally computing changes to Materialized Views without the need to use Streaming Tables. That means, deletes performed in the Bronze tables will incrementally propagate to subsequent layers without breaking the pipeline. The DLT pipeline with Enzyme enabled will only update rows in the Materialize View necessary to materialize the result which can greatly reduce infrastructure costs.
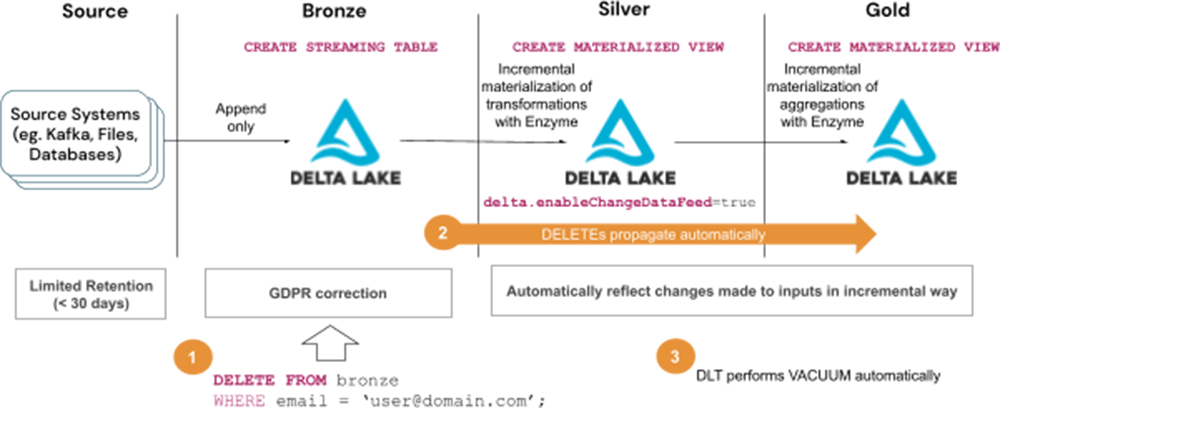
Steps to handle GDPR/CCPA requests with Solution 2:
- Delete user information from Bronze tables
- Wait for the deletes to propagate to subsequent layers, ie. Silver and Gold tables
- Wait for the Vacuum to run automatically as part of DLT maintenance tasks
Consider using Solution 2 when:
- The type of query used is supported by Enzyme optimization*
- Full recomputation of tables is not acceptable due to cost and latency requirements
*DLT Enzyme optimization, at the time of writing is in private preview with support to a few selected scenarios. The scope of which types of queries can be incrementally computed will expand over time. Please contact your Databricks representative to get more details.
Using Enzyme optimization reduces infrastructure cost and lowers the processing latency compared to Solution 1 where full recomputation of Silver and Gold tables is needed. But if the type of query run is not yet supported by Enzyme, the solutions that follow might be more appropriate.
Solution 3 - Streaming Tables for Bronze & Silver and Materialized Views afterward
As mentioned before, executing a delete on a source table used for streaming will break the stream. For that reason, using Streaming Tables for Silver tables may be problematic for handling GDPR/CCPA scenarios. The streams will break whenever a request to delete PII data is executed on the Bronze tables. In order to solve this issue, two alternative approaches can be used as presented below.
Solution 3 (a) - Leveraging Full Refresh functionality
The DLT framework provides a Fully Refresh (selected) functionality so that the streams can be repaired by full recomputation of all or selected tables. This is useful as the "Right to be Forgotten" stipulates that personal information must be deleted only within a month from the request and not immediately. That means, the full recomputation can be decreased to just once a month. Moreover, the full recomputation of the Bronze layer can be avoided completely, by setting pipeline.reset.allow = false on the Bronze tables, allowing them to continue incremental processing.
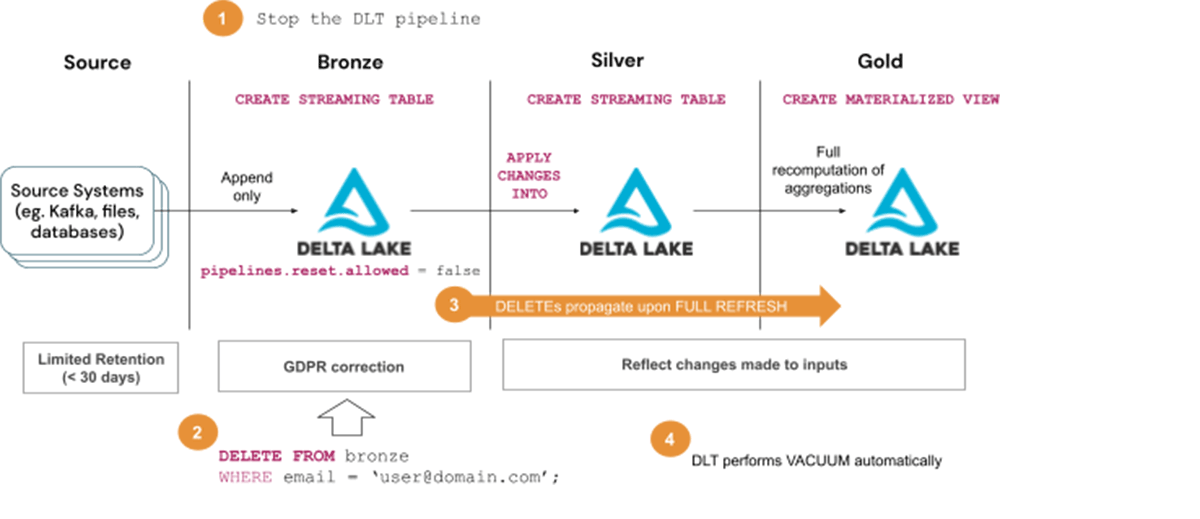
Steps to handle GDPR/CCPA requests with Solution 3 (a) - execute once per month or so:
- Stop the DLT pipeline
- Delete user information from Bronze tables
- Start the pipeline in full refresh (selected) mode and wait until deletes propagate to subsequent layers, ie. Silver and Gold tables
- Wait for the Vacuum to run automatically as part of DLT maintenance tasks
Consider using Solution 3 (a) when:
- The type of query used is not supported by Enzyme optimization, otherwise, use Solution 2
- Full recomputation of Silver tables is acceptable to run once per month
Solution 3 (b) - Leveraging skipChangeCommits option
As an alternative to the Full Refresh approach presented above, the skipChangeCommits option can be used to avoid full recomputation of tables. When this option is enabled the streaming will disregard file-changing operations entirely and will not fail if a change (e.g. DELETE) is detected on a table being used as a source. The drawback of this approach is that the changes will not be propagated to downstream tables hence the DELETEs need to be executed in the subsequent layers separately. Also, note that the skipChangeCommits option is not supported on queries that use APPLY CHANGES INTO statement.
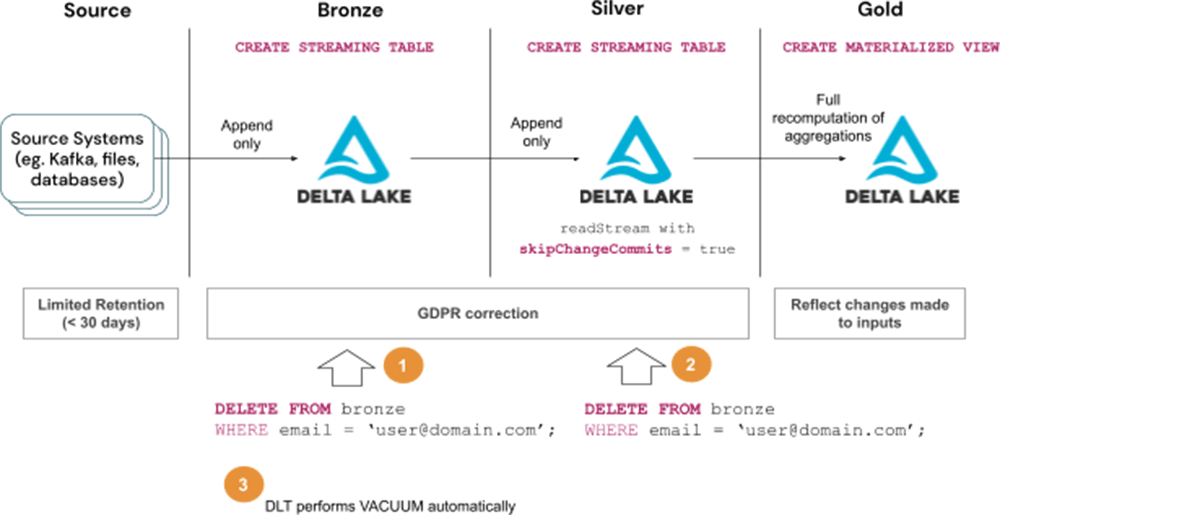
Steps to handle GDPR/CCPA requests with Solution 3 (b):
- Delete user information from Bronze tables
- Delete user information from Silver tables and wait for the changes to propagate to Gold tables
- Wait for the Vacuum to run automatically as part of DLT maintenance tasks
Consider using Solution 3 (b) when:
- The type of query used is not supported by Enzyme optimization, otherwise, use Solution 2
- Full recomputation of Silver tables is not acceptable
- Queries in the Silver layer are run in append mode (ie. not using APPLY CHANGES INTO statement)
Solution 3 (b) avoids full recomputation of tables and should be used in favor of Solution 3 (a) if APPLY CHANGES INTO statement is not used.
Solution 4 - Separate PII data from the rest of the data
Rather than deleting records from all the tables, it may be more efficient to normalize and split them into separate tables:
- PII table(s) containing all sensitive data (eg. customer table) with individual records identifiable by a surrogate key (eg. customer_id)
- All other data which are not sensitive and lose their ability to identify a person without the other table
In this case, handling the GDPR/CCPA request is as simple as removing the records from the PII table. The rest of the tables remain intact. The surrogate key stored in the tables (customer_id in the diagram) cannot be used to identify or link a person so the data may still be used for ML or some analytics.
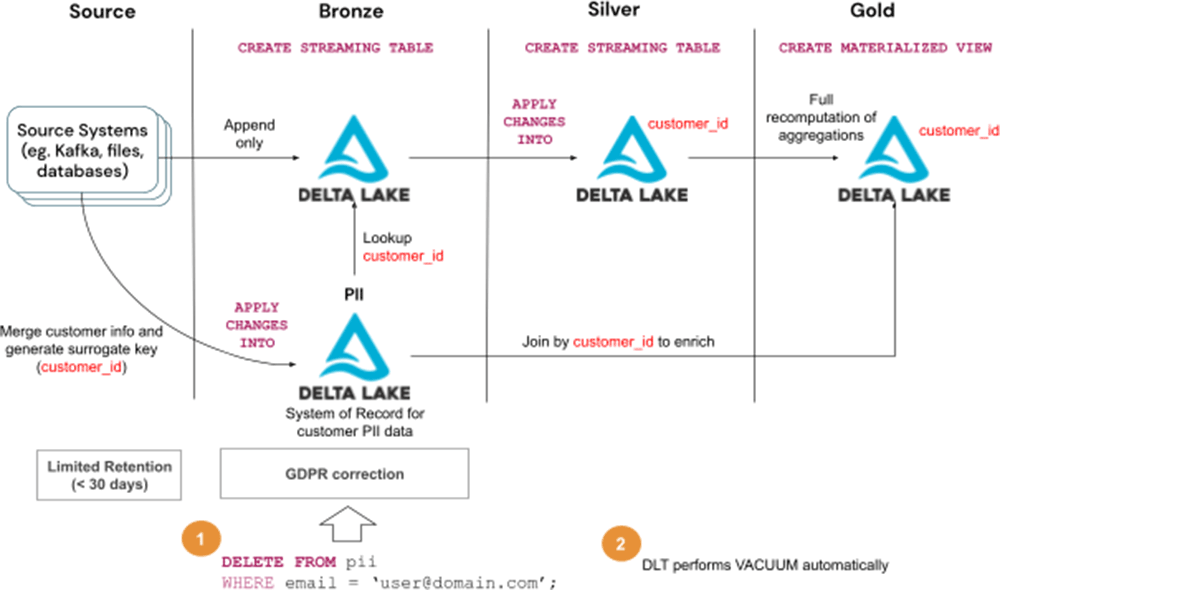
Steps to handle GDPR/CCPA requests:
- Delete user information from the PII table
- Wait for the Vacuum to run automatically as part of DLT maintenance tasks
Consider using Solution 4 when:
- Full recomputation of tables is not acceptable
- Designing a new data model
- Managing lots of tables and needing a simple method to make the whole system compliant with regulations
- Needing to be able to reuse most of the data (eg. building ML models) while being compliant with regulations
This approach tries to structure datasets to limit the scope of the regulations. It’s a great option when designing new systems and probably the best holistic solution for handling GDPR/CCPA requests available. However, it adds complexity to the presentation layer since the PII information needs to be retrieved (joined) from a separate table whenever needed.
Conclusion
Businesses that process and store personally identifiable information (PII) have to comply with legal regulations, eg. GDPR, and CCPA. In this post, different approaches for handling the "Right to be Forgotten" requirement of the regulations in question were presented using Delta Live Tables (DLT). Below please find a summary of all the solutions presented as a guide to decide which one should fit best.
| Solution | Consider using when |
|---|---|
|
1 - Streaming Tables for Bronze and Materialized Views afterward |
|
|
2 - Streaming Tables for Bronze and Materialized Views with Enzyme afterward |
|
|
3 (a) Full Refresh - Streaming Tables for Bronze & Silver and Materialized Views afterward |
|
|
3 (b) skipChangeCommits - Streaming Tables for Bronze & Silver and Materialized Views afterward |
|
|
4 - Separate PII data from the rest of the data |
|