How PepsiCo Established an Enterprise-grade Data Intelligence Platform Powered by Databricks Unity Catalog
by Bhaskar Palit and Sudipta Das
This blog is authored by Bhaskar Palit, Senior Director, Data & Analytics, PepsiCo, and Sudipta Das, Data Architect Senior Manager, PepsiCo
PepsiCo has woven itself into the fabric of our daily life. Our products are enjoyed by consumers more than one billion times a day in more than 200 countries and territories around the world. PepsiCo generated more than $91 billion in net revenue in 2023, driven by a complimentary beverage and convenient foods portfolio that includes Lay's, Doritos, Cheetos, Gatorade, Pepsi-Cola, Mountain Dew, Quaker and SodaStream.
PepsiCo has more than 200,000 products. We operate across the globe and manage a great deal of warehouses and suppliers, which all add up to a massive amount of data. Having that level of data detail allows us to be more efficient across our enterprise supply chain, helping reduce food waste, save fuel costs, and stay ahead of customer demand. Four years ago, we embarked on a journey to establish an enterprise-grade data platform encompassing six critical components: data modeling, data ingestion, data serving, data quality, data cataloging, and data monitoring across 30+ digital products. Our goal was to improve data quality and governance, which is how we found Databricks Unity Catalog. In this blog we are sharing our progress and success so far.
To hear more, check out our session at the Data + AI Summit 2024.
The Shift from Siloed Analytics to Unified Data Intelligence
Over the years, PepsiCo has expanded its product portfolio, which resulted in data being spread across multiple systems. This separation, in some cases, led to data sprawl and duplication, a common challenge in large organizations. To address these issues, PepsiCo planned to unify all its global data under a single data architecture. This strategic move has had a groundbreaking impact, with data, analytics, and AI enabling employees to enhance their performance. For example, by centralizing data, sales teams can access up-to-date information during store visits, improving customer service and enabling immediate product recommendations to boost sales.
Furthermore, PepsiCo aimed to advance its analytics capabilities by moving from descriptive to predictive and prescriptive analytics with machine learning and artificial intelligence. At PepsiCo, data and AI have become vital tools for the business and our employees. It’s a fundamental part of PepsiCo’s digital transformation, enhancing our digital resources across the board, from the optimal time to plan potatoes to predicting the number of Doritos bags to stock on store shelves.
We selected Microsoft Azure as our cloud provider to meet these specific requirements. Given our need to process large volumes of data efficiently, Databricks emerged as a natural choice due to its seamless integration within the Azure environment. This integration is crucial as it enhances our data processing capabilities. The choice was also influenced by the widespread use of Apache Spark™ in the data engineering space and the availability of skilled professionals familiar with Databricks. Furthermore, Databricks’ open and cloud-agnostic nature adds an extra layer of flexibility, allowing us to operate across various cloud environments without constraints.
Transforming Data Management and Governance with Databricks Unity Catalog
PepsiCo is enhancing its business operations from seed to shelf by leveraging millions of data points daily as products are packaged and transported across approximately 1.3 billion miles worldwide, reaching our consumers over a billion times a day. As we manage diverse data from numerous global sources, we are continuously improving our centralized data governance system to ensure data accuracy and reliability. By streamlining the environment for our data engineers, we aim to boost operational efficiency and scalability, supporting our commitment to delivering quality products to our customers.
To address these requirements, we turned to Databricks Unity Catalog, which offered the solution we needed to meet all our requirements for stringent security and sophisticated access controls. Databricks Unity Catalog is now an integral part of the PepsiCo Data Foundation, our centralized global system that consolidates over 6 petabytes of data worldwide. It streamlines the onboarding process for more than 1,500 active users and enables unified data discovery for our 30+ digital product teams across the globe, supporting both business intelligence and artificial intelligence applications. For example, we leverage data to connect with farmers, who play a crucial role in PepsiCo's Positive (pep+) ambition to promote regenerative farming practices across 7 million acres by 2030. By providing them with enhanced data and analytics, farmers can use their land and water more efficiently, ultimately improving our supply chain at its source.
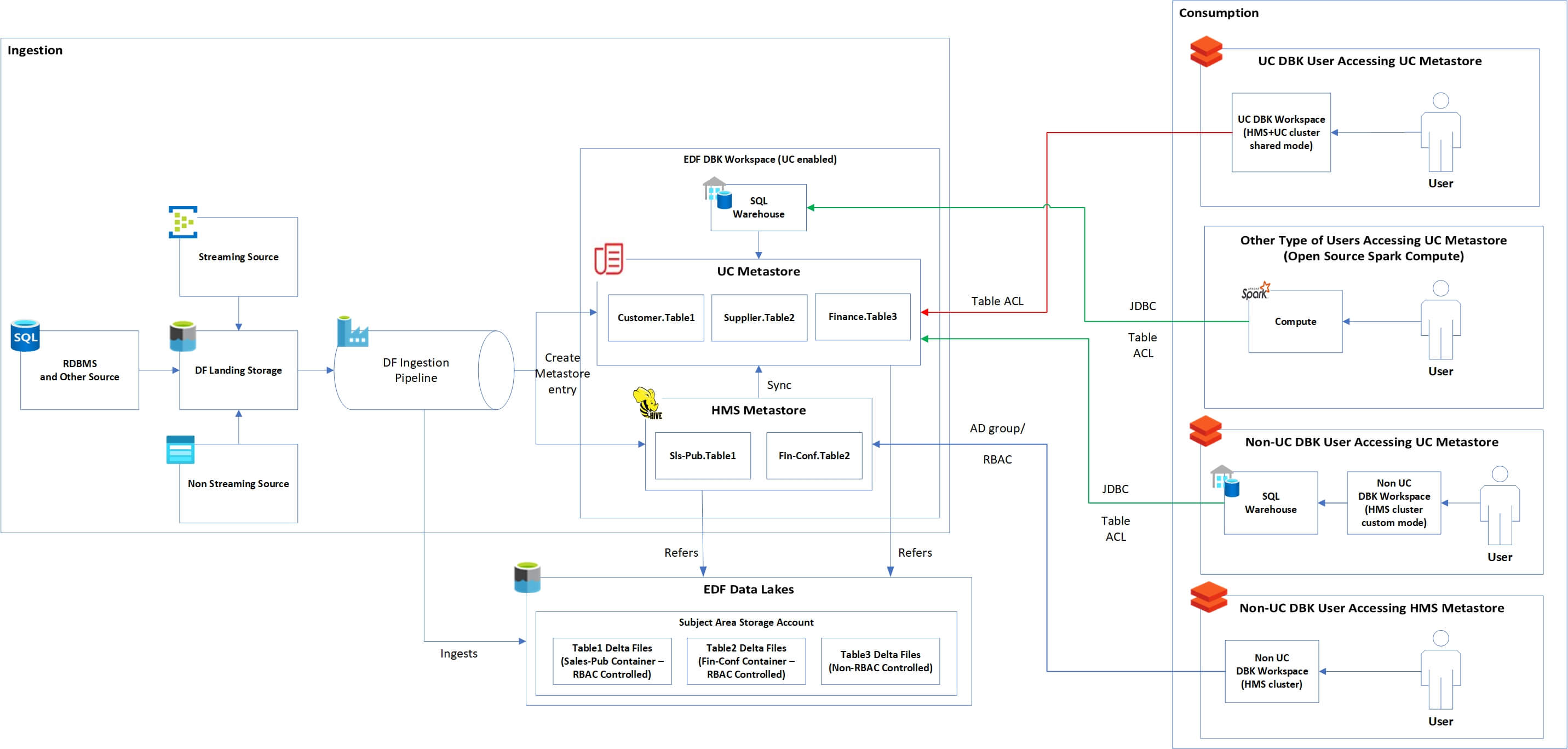

With Unity Catalog, we have realized benefits in the following areas in particular:
Data security:
- Implemented table-level access control, replacing schema-based access in HMS, which aligns with the least privileged access control policy and removes the need to maintain 64 AD groups for storage container access.
- Enabled granular row and column-level access for over 50 restricted tables across Finance, HR, and R&D data domains.
- Established volume-level access control, eliminating the exposure risk of over 100 unsecured DBFS locations.
Auditability:
- Provided insights into queries run by identities, allowing the platform admin team to monitor over 5,000 queries daily.
Monitoring and Observability:
- Integrated with Databricks APIs for end-to-end data lineage, enabling the creation of lineage for over 7,000 bronze tables and 1,000 silver tables from 150 different data sources.
- Enabled command-level review of cost consumption for over 2,000 notebooks and generated alerts for notebooks exceeding cost thresholds.
Faster Onboarding with Databricks Unity Catalog
Based on our experience, Databricks Unity Catalog has proven to be a scalable solution for centralized access management, data governance, and data lineage management. Transitioning to Unity Catalog has streamlined our access control processes, reducing onboarding time by 30% and enhancing cost management. Additionally, with comprehensive data lineage capabilities, we have increased confidence in our data by being able to trace its origins and track any changes in real-time. This transparency allows us to maintain high data integrity and reliability.
Ultimately, Databricks has enabled us to achieve greater security, governance and efficiency levels in an evolving and complex data and AI landscape.
To learn more about our journey, join our session, PepsiCo's Low-Code, Global Data Platform powered by Unity Catalog at the Data + AI Summit 2024
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.