Improving Text2SQL Performance with Ease on Databricks
by Matthew Hayes, Evion Kim, Linqing Liu, Alnur Ali, Ritendra Datta and Sam Shah
Want to raise your LLM into the top 10 of Spider, a widely used benchmark for text-to-SQL tasks? Spider evaluates how well LLMs can convert text queries into SQL code.
For those unfamiliar with text-to-SQL, its significance lies in transforming how businesses interact with their data. Instead of relying on SQL experts to write queries, people can simply ask questions of their data in plain English and receive precise answers. This democratizes access to data, enhancing business intelligence and enabling more informed decision-making.
The Spider benchmark is a widely recognized standard for evaluating the performance of text-to-SQL systems. It challenges LLMs to translate natural language queries into precise SQL statements, requiring a deep understanding of database schemas and the ability to generate syntactically and semantically correct SQL code.
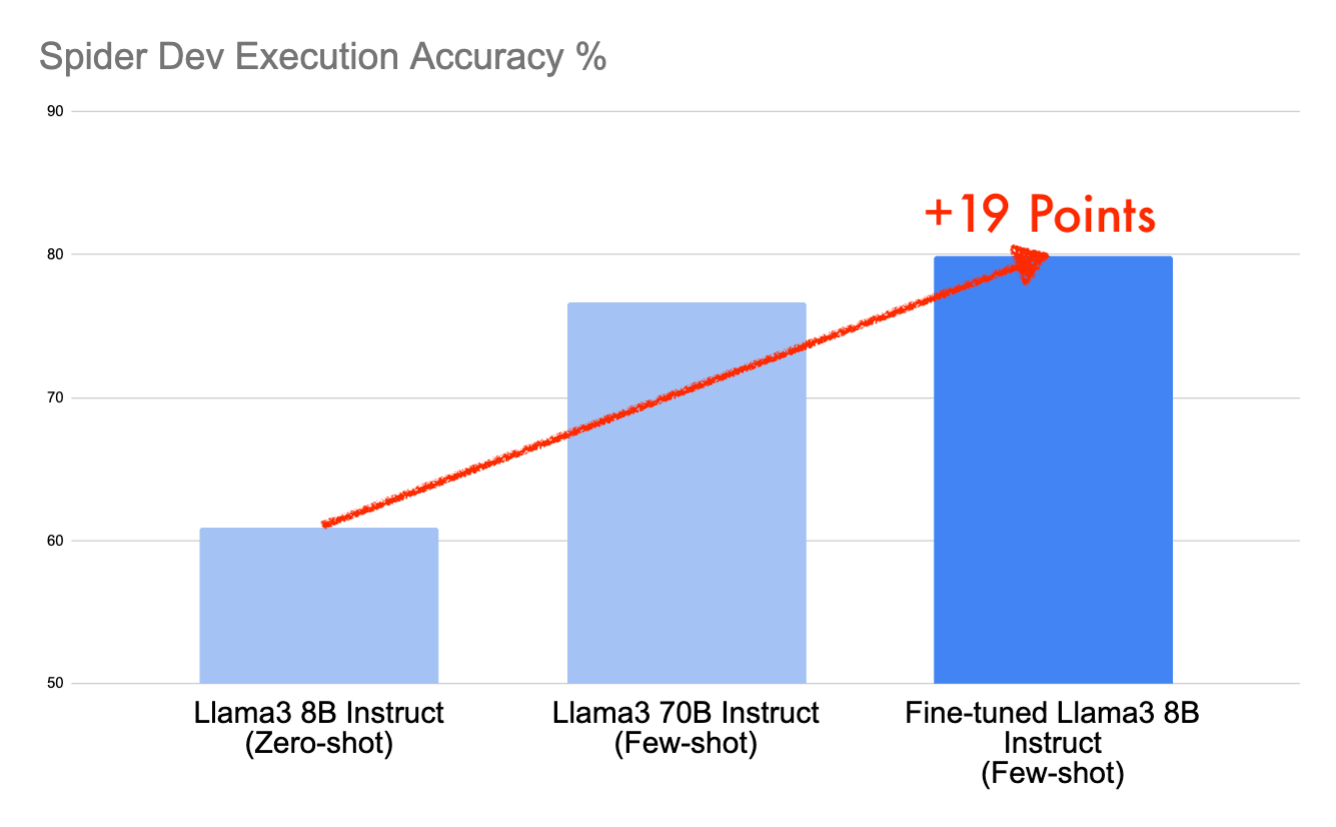
In this post, we’ll dive into how we achieved scores of 79.9% on the Spider development dataset and 78.9% on the test dataset in less than a day of work using the open-source Llama3 8B Instruct model – a remarkable 19-point improvement over the baseline. This performance would place it in a top-10 spot on the now-frozen Spider leaderboard, thanks to strategic prompting and fine-tuning on Databricks.
Zero-shot Prompting for Baseline Performance
Let's start by evaluating the performance of Meta Llama 3 8B Instruct on the Spider dev dataset using a very simple prompt format consisting of the CREATE TABLE statements that created the tables and a question we'd like to answer using those tables:
This type of prompt is often referred to as "zero-shot" because there are no other examples in the prompt. For the first question in the Spider dev dataset this prompt format produces:
Running the Spider benchmark on the dev dataset using this format produces an overall score of 60.9 when measured using execution accuracy and greedy decoding. This means that 60.9% of the time the model produces SQL that when executed produces the same results as a "gold" query representing the correct solution.
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Zero-shot | 78.6 | 69.3 | 42.5 | 31.3 | 60.9 |
With the baseline score established, before we even get into fine-tuning let's try different prompting strategies to try to raise the score for the base model on the Spider dev benchmark dataset.
Prompting With Sample Rows
One of the drawbacks with the first prompt we used is that it doesn't include any information about the data in the columns beyond the data type. A paper on evaluating text-to-SQL capabilities of models with Spider found that adding sampled rows to the prompt led to a higher score, so let's try that.
We can update the prompt format above so that the create table queries also include the first few rows from each table. For the same question from earlier we not have an updated prompt:
Including sample rows for each table raises the overall score by about 6 percentage points to 67.0:
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Zero-shot with sample rows | 80.6 | 75.3 | 51.1 | 41.0 | 67.0 |
Few-shot Prompting
Few-shot prompting is a well known strategy used with LLMs where we can improve the performance on a task such as generating correct SQL by including some examples demonstrating the task to be performed. With a zero-shot prompt we provided the schemas and then asked a question. With a few-shot prompt we provide some schemas, a question, the SQL that answers that question, and then repeat that sequence a couple times before getting to the actual question we want to ask. This generally results in better performance than a zero-shot prompt.
A good source of examples demonstrating the SQL generation task is actually the Spider training dataset itself. We can take a random sample of a few questions from this dataset with their corresponding tables and construct a few-shot prompt demonstrating the SQL that can answer each of these questions. Since we are now using sample rows as of the previous prompt we should also ensure one of these examples also includes sample rows as well to demonstrate their usage.
Another improvement we can make on the previous zero-shot prompt is to also include a "system prompt" at the beginning. System prompts are typically used to provide detailed guidance to the model that outline the task to be performed. While a user may ask multiple questions throughout the course of chat with a model, the system prompt is just provided once before the user even asks a question, essentially establishing expectations for how the "system" should perform during the chat.
With these strategies in mind, we can construct a few-shot prompt that also starts with a system message represented as a large SQL comment block at the top followed by three examples:
This new prompt has resulted in a score of 70.8, which is another 3.8 percentage point improvement over our previous score. We have raised the score nearly 10 percentage points from where we started just through simple prompting strategies.
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Few-shot with sample rows | 83.9 | 79.1 | 55.7 | 44.6 | 70.8 |
We are probably now reaching the point of diminishing returns from tweaking our prompt. Let's fine-tune the model to see what further gains can be made.
Fine-Tuning with LoRA
If we are fine-tuning the model the first question is what training data to use. Spider includes a training dataset so this seems like a good place to start. To fine-tune the model we will use QLoRA so that we can efficiently train the model on a single A100 80GB Databricks GPU cluster such as Standard_NC24ads_A100_v4 in Databricks. This can be completed in about four hours using the 7k records in the Spider training dataset. We have previously discussed fine-tuning with LoRA in an earlier blog post. Interested readers can refer to that post for more details. We can follow standard training recipes using the trl, peft, and bitsandbytes libraries.
Although we are getting the training records from Spider, we still need to format them in a way that the model can learn from. The goal is to map each record, consisting of the schema (with sample rows), question and SQL into a single text string. We start by performing some processing on the raw Spider dataset. From the raw data we produce a dataset where each record consists of three fields: schema_with_rows, question, and query. The schema_with_rows field is derived from the tables corresponding to the question, following the formatting of the CREATE TABLE statement and rows used in the few-shot prompt earlier.
Next load the tokenizer:
We'll define a mapping function that will convert each record from our processed Spider training dataset into a text string. We can use apply_chat_template from the tokenizer to conveniently format the text into the chat format expected by the Instruct model. Although this isn't the exact same format we're using for our few-shot prompt, the model generalizes well enough to work even if the boilerplate formatting of the prompts is slightly different.
For SYSTEM_PROMPT we use the same system prompt used in the few-shot prompt earlier. For USER_MESSAGE_FORMAT we similarly use:
With this function defined all that is left is to transform the processed Spider dataset with it and save it as a JSONL file.
We are now ready to train. A few hours later we have a fine-tuned Llama3 8B Instruct. Rerunning our few-shot prompt on this new model resulted in a score of 79.9, which is another 9 percentage point improvement over our previous score. We have now raised the total score by ~19 percentage points over our simple zero-shot baseline.
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Few-shot with sample rows (Fine-tuned Llama3 8B Instruct) |
91.1 | 85.9 | 72.4 | 54.8 | 79.9 |
| Few-shot with sample rows (Llama3 8B Instruct) |
83.9 | 79.1 | 55.7 | 44.6 | 70.8 |
| Zero-shot with sample rows (Llama3 8B Instruct) |
80.6 | 75.3 | 51.1 | 41.0 | 67.0 |
| Zero-shot (Llama3 8B Instruct) |
78.6 | 69.3 | 42.5 | 31.3 | 60.9 |
You might be wondering now how the Llama3 8B Instruct model and the fine-tuned version compare against a larger model such as Llama3 70B Instruct. We have repeated the evaluation process using the off-the-shelf 70B model on the dev dataset with eight A100 40 GB GPUs and recorded the results below.
| Few-shot with sample rows (Llama3 70B Instruct) |
89.5 | 83.0 | 64.9 | 53.0 | 76.7 |
| Zero-shot with sample rows (Llama3 70B Instruct) |
83.1 | 81.8 | 59.2 | 36.7 | 71.1 |
| Zero-shot (Llama3 70B Instruct) |
82.3 | 80.5 | 57.5 | 31.9 | 69.2 |
As expected, comparing the off-the-shelf models, the 70B model beats the 8B model when measured using the same prompt format. But what's surprising is that the fine-tuned Llama3 8B Instruct model scores higher than the Llama3 70B Instruct model by 3 percentage points. When focused on specific tasks such as text-to-SQL, fine-tuning can result in small models that are comparable in performance with models that are much larger in size.
Deploy to a Model Serving Endpoint
Llama3 is supported by Databricks Model Serving, so we could even deploy our fine-tuned Llama3 model to an endpoint and use it to power applications. All we need to do is log the fine-tuned model to Unity Catalog and then create an endpoint using the UI. Once it is deployed we can query it using common libraries.
Wrapping Up
We kicked off our journey with the Llama3 8B Instruct on the Spider dev dataset using a zero-shot prompt, achieving a modest score of 60.9. By enhancing this with a few-shot prompt—complete with system messages, multiple examples, and sample rows—we boosted our score to 70.8. Further gains came from fine-tuning the model on the Spider training dataset, propelling us to an impressive 79.9 on Spider dev and 78.9 on Spider test. This significant 19-point climb from our starting point and a 3-point lead over the base Llama3 70B Instruct not only showcases our model's prowess but also would secure us a coveted spot in the top-10 results on Spider.
Learn more about how to leverage the power of open source LLMs and the Data Intelligence Platform by registering for Data+AI Summit.
Appendix
Evaluation Setup
Generation was performed using vLLM, greedy decoding (temperature of 0), two A100 80 GB GPUs, and 1024 max new tokens. To evaluate the generations we used the test suite from the taoyds/test-suite-sql-eval repo in Github.
Training Setup
Here is the specific details about the fine-tuning setup:
| Base Model | Llama3 8B Instruct |
| GPUs | Single A100 80GB |
| Max Steps | 100 |
| Spider train dataset records | 7000 |
| Lora R | 16 |
| Lora Alpha | 32 |
| Lora Dropout | 0.1 |
| Learning Rate | 1.5e-4 |
| Learning Rate Scheduler | Constant |
| Gradient Accumulation Steps | 8 |
| Gradient Checkpointing | True |
| Train Batch Size | 12 |
| LoRA Target Modules | q_proj,v_proj,k_proj,o_proj,gate_proj,up_proj,down_proj |
| Data Collator Response Template | <|start_header_id|>assistant<|end_header_id|> |
Zero-shot Prompt Example
This is the first record from the dev dataset we used for evaluation formatted as a zero-shot prompt that includes the table schemas. The tables the question is concerning are represented using the CREATE TABLE statements that created them.
Zero-shot with Sample Rows Prompt Example
This is the first record from the dev dataset we used for evaluation formatted as a zero-shot prompt that includes the table schemas and sample rows. The tables the question is concerning are represented using the CREATE TABLE statements that created them. The rows were selected using "SELECT * {table_name} LIMIT 3" from each table, with the column names appearing as a header.
Few-shot with Sample Rows Prompt Example
This is the first record from the dev dataset we used for evaluation formatted as a few-shot prompt that includes the table schemas and sample rows. The tables the question is concerning are represented using the CREATE TABLE statements that created them. The rows were selected using "SELECT * {table_name} LIMIT 3" from each table, with the column names appearing as a header.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.