Introducing DBRX: A New State-of-the-Art Open LLM
Today, we are excited to introduce DBRX, an open, general-purpose LLM created by Databricks. Across a range of standard benchmarks, DBRX sets a new state-of-the-art for established open LLMs. Moreover, it provides the open community and enterprises building their own LLMs with capabilities that were previously limited to closed model APIs; according to our measurements, it surpasses GPT-3.5, and it is competitive with Gemini 1.0 Pro. It is an especially capable code model, surpassing specialized models like CodeLLaMA-70B on programming, in addition to its strength as a general-purpose LLM.
This state-of-the-art quality comes with marked improvements in training and inference performance. DBRX advances the state-of-the-art in efficiency among open models thanks to its fine-grained mixture-of-experts (MoE) architecture. Inference is up to 2x faster than LLaMA2-70B, and DBRX is about 40% of the size of Grok-1 in terms of both total and active parameter-counts. When hosted on Databricks Model Serving, DBRX can generate text at up to 150 tok/s/user. Our customers will find that training MoEs is also about 2x more FLOP-efficient than training dense models for the same final model quality. End-to-end, our overall recipe for DBRX (including the pretraining data, model architecture, and optimization strategy) can match the quality of our previous-generation MPT models with nearly 4x less compute.
The weights of the base model (DBRX Base) and the finetuned model (DBRX Instruct) are available on Hugging Face under an open license. Starting today, DBRX is available for Databricks customers to use via APIs, and Databricks customers can pretrain their own DBRX-class models from scratch or continue training on top of one of our checkpoints using the same tools and science we used to build it. DBRX is already being integrated into our GenAI-powered products, where - in applications like SQL - early rollouts have surpassed GPT-3.5 Turbo and are challenging GPT-4 Turbo. It is also a leading model among open models and GPT-3.5 Turbo on RAG tasks.
Training mixture-of-experts models is hard. We had to overcome a variety of scientific and performance challenges to build a pipeline robust enough to repeatably train DBRX-class models in an efficient manner. Now that we have done so, we have a one-of-a-kind training stack that allows any enterprise to train world-class MoE foundation models from scratch. We look forward to sharing that capability with our customers and sharing our lessons learned with the community.
Download DBRX today from Hugging Face (DBRX Base, DBRX Instruct), or try out DBRX Instruct in our HF Space, or see our model repository on github: databricks/dbrx.
What is DBRX?
DBRX is a transformer-based decoder-only large language model (LLM) that was trained using next-token prediction. It uses a fine-grained mixture-of-experts (MoE) architecture with 132B total parameters of which 36B parameters are active on any input. It was pre-trained on 12T tokens of text and code data. Compared to other open MoE models like Mixtral and Grok-1, DBRX is fine-grained, meaning it uses a larger number of smaller experts. DBRX has 16 experts and chooses 4, while Mixtral and Grok-1 have 8 experts and choose 2. This provides 65x more possible combinations of experts and we found that this improves model quality. DBRX uses rotary position encodings (RoPE), gated linear units (GLU), and grouped query attention (GQA). It uses the GPT-4 tokenizer as provided in the tiktoken repository. We made these choices based on exhaustive evaluation and scaling experiments.
DBRX was pretrained on 12T tokens of carefully curated data and a maximum context length of 32k tokens. We estimate that this data is at least 2x better token-for-token than the data we used to pretrain the MPT family of models. This new dataset was developed using the full suite of Databricks tools, including Apache Spark™ and Databricks notebooks for data processing, Unity Catalog for data management and governance, and MLflow for experiment tracking. We used curriculum learning for pretraining, changing the data mix during training in ways we found to substantially improve model quality.
Quality on Benchmarks vs. Leading Open Models
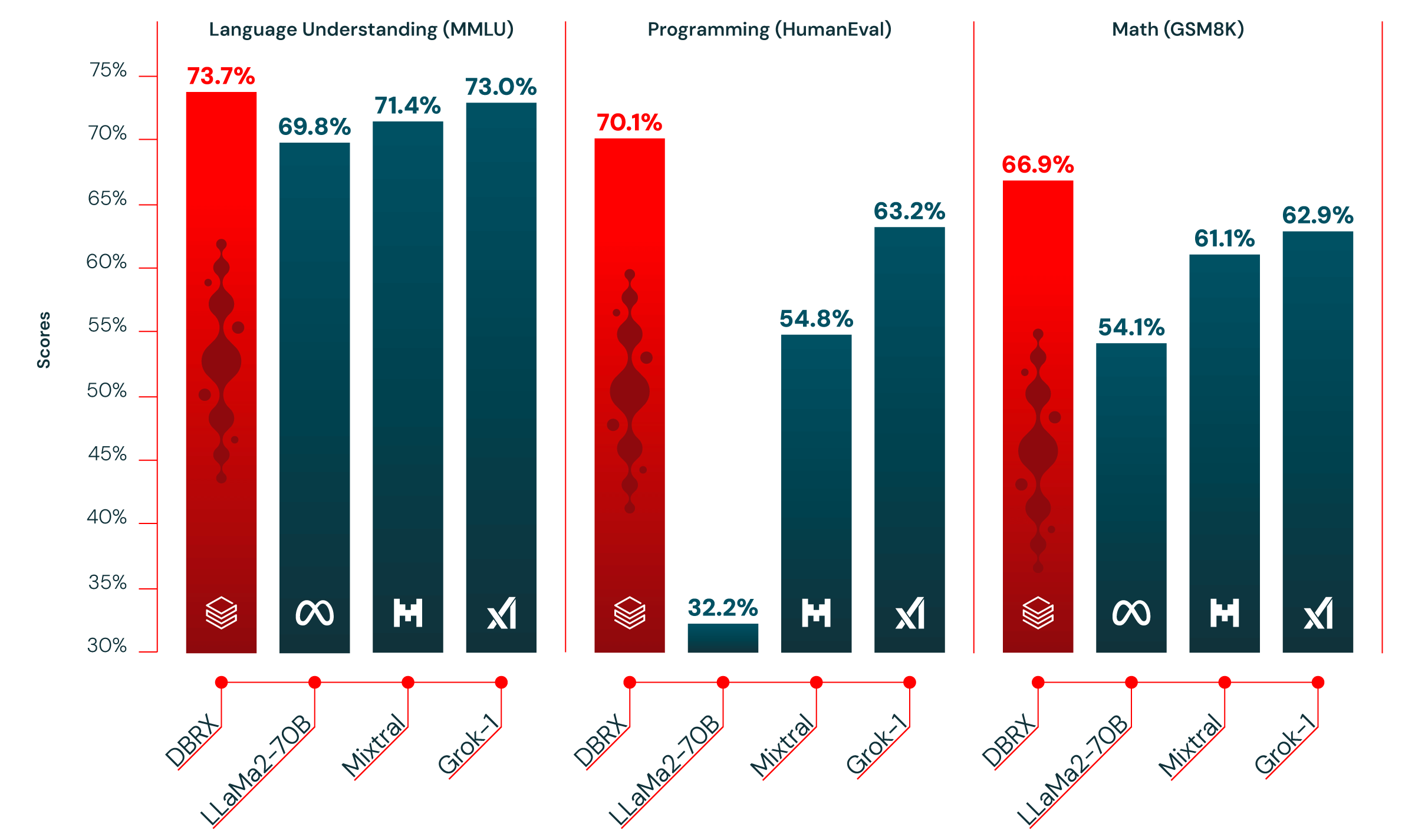
Table 1 shows the quality of DBRX Instruct and leading established, open models. DBRX Instruct is the leading model on composite benchmarks, programming and mathematics benchmarks, and MMLU. It surpasses all chat or instruction finetuned models on standard benchmarks.
Composite benchmarks. We evaluated DBRX Instruct and peers on two composite benchmarks: the Hugging Face Open LLM Leaderboard (the average of ARC-Challenge, HellaSwag, MMLU, TruthfulQA, WinoGrande, and GSM8k) and the Databricks Model Gauntlet (a suite of over 30 tasks spanning six categories: world knowledge, commonsense reasoning, language understanding, reading comprehension, symbolic problem solving, and programming).
Among the models we evaluated, DBRX Instruct scores the highest on two composite benchmarks: the Hugging Face Open LLM Leaderboard (74.5% vs. 72.7% for the next highest model, Mixtral Instruct) and the Databricks Gauntlet (66.8% vs. 60.7% for the next highest model, Mixtral Instruct).
Programming and mathematics. DBRX Instruct is especially strong at programming and mathematics. It scores higher than the other open models we evaluated on HumanEval (70.1% vs. 63.2% for Grok-1, 54.8% for Mixtral Instruct, and 32.2% for the best-performing LLaMA2-70B variant) and GSM8k (66.9% vs. 62.9% for Grok-1, 61.1% for Mixtral Instruct, and 54.1% for the best-performing LLaMA2-70B variant). DBRX outperforms Grok-1, the next best model on these benchmarks, despite the fact that Grok-1 has 2.4x as many parameters. On HumanEval, DBRX Instruct even surpasses CodeLLaMA-70B Instruct, a model built explicitly for programming, despite the fact that DBRX Instruct is designed for general-purpose use (70.1% vs. 67.8% on HumanEval as reported by Meta in the CodeLLaMA blog).
MMLU. DBRX Instruct scores higher than all other models we consider on MMLU, reaching 73.7%.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 1. Quality of DBRX Instruct and leading open models. See footnotes for details on how numbers were collected. Bolded and underlined is the highest score.
Quality on Benchmarks vs. Leading Closed Models
Table 2 shows the quality of DBRX Instruct and leading closed models. According to the scores reported by each model creator, DBRX Instruct surpasses GPT-3.5 (as described in the GPT-4 paper), and it is competitive with Gemini 1.0 Pro and Mistral Medium.
Across nearly all benchmarks we considered, DBRX Instruct surpasses or - at worst - matches GPT-3.5. DBRX Instruct outperforms GPT-3.5 on general knowledge as measured by MMLU (73.7% vs. 70.0%) and commonsense reasoning as measured by HellaSwag (89.0% vs. 85.5%) and WinoGrande (81.8% vs. 81.6%). DBRX Instruct especially shines on programming and mathematical reasoning as measured by HumanEval (70.1% vs. 48.1%) and GSM8k (72.8% vs. 57.1%).
DBRX Instruct is competitive with Gemini 1.0 Pro and Mistral Medium. Scores for DBRX Instruct are higher than Gemini 1.0 Pro on Inflection Corrected MTBench, MMLU, HellaSwag, and HumanEval, while Gemini 1.0 Pro is stronger on GSM8k. Scores for DBRX Instruct and Mistral Medium are similar for HellaSwag, while Mistral Medium is stronger on Winogrande and MMLU and DBRX Instruct is stronger on HumanEval, GSM8k, and Inflection Corrected MTBench.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 2. Quality of DBRX Instruct and leading closed models. Other than Inflection Corrected MTBench (which we measured ourselves on model endpoints), numbers were as reported by the creators of these models in their respective whitepapers. See footnotes for additional details.
Quality on Long-Context Tasks and RAG
DBRX Instruct was trained with up to a 32K token context window. Table 3 compares its performance to that of Mixtral Instruct and the latest versions of the GPT-3.5 Turbo and GPT-4 Turbo APIs on a suite of long-context benchmarks (KV-Pairs from the Lost in the Middle paper and HotpotQAXL, a modified version of HotPotQA that extends the task to longer sequence lengths). GPT-4 Turbo is generally the best model at these tasks. However, with one exception, DBRX Instruct performs better than GPT-3.5 Turbo at all context lengths and all parts of the sequence. Overall performance for DBRX Instruct and Mixtral Instruct are similar.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 3. The average performance of models on the KV-Pairs and HotpotQAXL benchmarks. Bold is the highest score. Underlined is the highest score other than GPT-4 Turbo. GPT-3.5 Turbo supports a maximum context length of 16K, so we could not evaluate it at 32K. *Averages for the beginning, middle, and end of the sequence for GPT-3.5 Turbo include only contexts up to 16K.
One of the most popular ways to leverage a model’s context is retrieval augmented generation (RAG). In RAG, content relevant to a prompt is retrieved from a database and presented alongside the prompt to give the model more information than it would otherwise have. Table 4 shows the quality of DBRX on two RAG benchmarks - Natural Questions and HotPotQA - when the model is also provided with the top 10 passages retrieved from a corpus of Wikipedia articles using the embedding model bge-large-en-v1.5. DBRX Instruct is competitive with open models like Mixtral Instruct and LLaMA2-70B Chat and the current version of GPT-3.5 Turbo.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 4. The performance of the models measured when each model is given the top 10 passages retrieved from a Wikipedia corpus using bge-large-en-v1.5. Accuracy is measured by matching within the model’s answer. Bold is the highest score. Underlined is the highest score other than GPT-4 Turbo.
Training Efficiency
Model quality must be placed in the context of how efficient the model is to train and use. This is especially so at Databricks, where we build models like DBRX to establish a process for our customers to train their own foundation models.
We found training mixture-of-experts models to provide substantial improvements in compute-efficiency for training (Table 5). For example, training a smaller member of the DBRX family called DBRX MoE-B (23.5B total parameters, 6.6B active parameters) required 1.7x fewer FLOPs to reach a score of 45.5% on the Databricks LLM Gauntlet than LLaMA2-13B required to reach 43.8%. DBRX MoE-B also contains half as many active parameters as LLaMA2-13B.
Looking holistically, our end-to-end LLM pretraining pipeline has become nearly 4x more compute-efficient in the past ten months. On May 5, 2023, we released MPT-7B, a 7B parameter model trained on 1T tokens that reached a Databricks LLM Gauntlet score of 30.9%. A member of the DBRX family called DBRX MoE-A (7.7B total parameters, 2.2B active parameters) reached a Databricks Gauntlet score of 30.5% with 3.7x fewer FLOPs. This efficiency is the result of a number of improvements, including using an MoE architecture, other architecture changes to the network, better optimization strategies, better tokenization, and - very importantly - better pretraining data.
In isolation, better pretraining data made a substantial impact on model quality. We trained a 7B model on 1T tokens (called DBRX Dense-A) using the DBRX pretraining data. It reached 39.0% on the Databricks Gauntlet compared to 30.9% for MPT-7B. We estimate that our new pretraining data is at least 2x better token-for-token than the data used to train MPT-7B. In other words, we estimate that half as many tokens are necessary to reach the same model quality. We determined this by training DBRX Dense-A on 500B tokens; it outperformed MPT-7B on the Databricks Gauntlet, reaching 32.1%. In addition to better data quality, another important contributor to this token-efficiency may be the GPT-4 tokenizer, which has a large vocabulary and is believed to be especially token-efficient. These lessons about improving data quality translate directly into practices and tools that our customers use to train foundation models on their own data.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 5. Details of several test articles that we used to validate the training efficiency of the DBRX MoE architecture and end-to-end training pipeline
Inference Efficiency
Figure 2 shows the end-to-end inference efficiency of serving DBRX and similar models using NVIDIA TensorRT-LLM with our optimized serving infrastructure and 16-bit precision. We aim for this benchmark to reflect real-world usage as closely as possible, including multiple users simultaneously hitting the same inference server. We spawn one new user per second, each user request contains an approximately 2000 token prompt, and each response comprises 256 tokens.
In general, MoE models are faster at inference than their total parameter-counts would suggest. This is due to the fact that they use relatively few parameters for each input. We find that DBRX is no exception in this respect. DBRX inference throughput is 2-3x higher than a 132B non-MoE model.
Inference efficiency and model quality are typically in tension: bigger models typically reach higher quality, but smaller models are more efficient for inference. Using an MoE architecture makes it possible to attain better tradeoffs between model quality and inference efficiency than dense models typically achieve. For example, DBRX is both higher quality than LLaMA2-70B and - thanks to having about half as many active parameters - DBRX inference throughput is up to 2x faster (Figure 2). Mixtral is another point on the improved pareto frontier attained by MoE models: it is smaller than DBRX, and it is correspondingly lower in terms of quality but reaches higher inference throughput. Users of the Databricks Foundation Model APIs can expect to see up to 150 tokens per second for DBRX on our optimized model serving platform with 8-bit quantization.

How We Built DBRX
DBRX was trained on 3072 NVIDIA H100s connected by 3.2Tbps Infiniband. The main process of building DBRX - including pretraining, post-training, evaluation, red-teaming, and refining - took place over the course of three months. It was the continuation of months of science, dataset research, and scaling experiments, not to mention years of LLM development at Databricks that includes the MPT and Dolly projects and the thousands of models we have built and brought to production with our customers.
To build DBRX, we leveraged the same suite of Databricks tools that are available to our customers. We managed and governed our training data using Unity Catalog. We explored this data using newly acquired Lilac AI. We processed and cleaned this data using Apache Spark™ and Databricks notebooks. We trained DBRX using optimized versions of our open-source training libraries: MegaBlocks, LLM Foundry, Composer, and Streaming. We managed large scale model training and finetuning across thousands of GPUs using our Databricks Training service. We logged our results using MLflow. We collected human feedback for quality and safety improvements through Databricks Model Serving and Inference Tables. We manually experimented with the model using the Databricks Playground. We found the Databricks tools to be best-in-class for each of their purposes, and we benefited from the fact that they were all part of a unified product experience.
Get Started with DBRX on Databricks
If you’re looking to start working with DBRX right away, it’s easy to do so with the Databricks Foundation Model APIs. You can quickly get started with our pay-as-you-go pricing and query the model from our AI Playground chat interface. For production applications, we offer a provisioned throughput option to provide performance guarantees, support for finetuned models, and additional security and compliance. To privately host DBRX, you can download the model from the Databricks Marketplace and deploy the model on Model Serving.
Conclusions
At Databricks, we believe that every enterprise should have the ability to control its data and its destiny in the emerging world of GenAI. DBRX is a central pillar of our next generation of GenAI products, and we look forward to the exciting journey that awaits our customers as they leverage the capabilities of DBRX and the tools we used to build it. In the past year, we have trained thousands of LLMs with our customers. DBRX is only one example of the powerful and efficient models being built at Databricks for a wide range of applications, from internal features to ambitious use-cases for our customers.
As with any new model, the journey with DBRX is just the beginning, and the best work will be done by those who build on it: enterprises and the open community. This is also just the beginning of our work on DBRX, and you should expect much more to come.
Contributions
The development of DBRX was led by the Mosaic team that previously built the MPT model family, in collaboration with dozens of engineers, lawyers, procurement and finance specialists, program managers, marketers, designers, and other contributors from across Databricks. We are grateful to our colleagues, friends, family, and the community for their patience and support over the past months.
In creating DBRX, we stand on the shoulders of giants in the open and academic community. By making DBRX available openly, we intend to invest back in the community in hopes that we will build even greater technology together in the future. With that in mind, we gratefully acknowledge the work and collaboration of Trevor Gale and his MegaBlocks project (Trevor’s PhD adviser is Databricks CTO Matei Zaharia), the PyTorch team and the FSDP project, NVIDIA and the TensorRT-LLM project, the vLLM team and project, EleutherAI and their LLM evaluation project, Daniel Smilkov and Nikhil Thorat at Lilac AI, and our friends at the Allen Institute for Artificial Intelligence (AI2).
About Databricks
Databricks is the Data and AI company. More than 10,000 organizations worldwide — including Comcast, Condé Nast, Grammarly, and over 50% of the Fortune 500 — rely on the Databricks Data Intelligence Platform to unify and democratize data, analytics and AI. Databricks is headquartered in San Francisco, with offices around the globe and was founded by the original creators of Lakehouse, Apache Spark™, Delta Lake and MLflow. To learn more, follow Databricks on LinkedIn, X, and Facebook.
1 Numbers as reported by xAI. Due to a lack of Hugging Face-compatible checkpoint at release time, we could not evaluate Grok-1 ourselves on our full suite of benchmarks.
2 DBRX was measured by us using the EleutherAI Harness. All other numbers were as reported on the Hugging Face Open LLM Leaderboard.
3 DBRX was measured by us using the EleutherAI Harness with the same older commit that is used by the Hugging Face Open LLM Leaderboard. All other numbers were as reported on the Hugging Face Open LLM Leaderboard. Note that when using the latest commit of the EleutherAI Harness, which includes several parsing fixes, DBRX’s 5-shot score on GSM8k goes up to 72.8% as reported in Table 2. LLaMA2-70B Chat also goes up to 48.4%.
4 Measured by Databricks using Gauntlet v0.3.0 in LLM Foundry.
5 Unless otherwise noted, measured by Databricks.
6 This number is from the Mixtral Arxiv paper. We report this number because it is higher than what we measured when evaluating the model ourselves (36.7%)
7 All scores as reported in the GPT-4 paper. We could not collect Inflection Corrected MTBench because this version of GPT-3.5 is not available. We found the current version of GPT-3.5 Turbo to score 8.58 ± 0.04 on Inflection Corrected MTBench compared to 8.39 +/- 0.08 for DBRX Instruct.
8 All scores as reported in the GPT-4 paper. We could not collect Inflection Corrected MTBench because this version of GPT-4 is not available. We found the current version of GPT-4 Turbo to score 9.27 ± 0.10 on Inflection Corrected MTBench compared to 8.39 +/- 0.08 for DBRX Instruct.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.