
How should you finetune a large language model for general-purpose question answering?
One intriguing approach is that of supervised finetuning on a small number of high-quality samples. The recent LIMA (“Less Is More for Alignment”) study boldly claimed that general-purpose instruction following could be achieved by simply training on 1,000 diverse, high-quality question-answering pairs; several other contemporaneous studies also argue that this type of “style alignment” finetuning can be achieved with a small number of high-quality samples (e.g. Vicuna, Alpagasus, and Tülü, but see also The False Promise of Imitating Proprietary LLMs).
We were initially skeptical of this approach. Could a few thousand samples really improve the quality of an LLM?
In a paper we presented at a NeurIPS workshop in December, we considered the style alignment approach from LIMA and examined whether a small amount of high-quality instruction finetuning samples could improve performance on both traditional perplexity-based NLP benchmarks such as MMLU and BIG-bench, and open-ended, model-based evaluation (i.e. “LLM-as-a-judge”).
We found that finetuning on just a few thousand samples can improve model perfomance, with one important detail - that the finetuning dataset must be be aligned with the evaluation paradigm you care about.
When we first finetuned our MPT-7B and 30B models on the 1,000 LIMA samples, we were pleasantly surprised to find that it did boost model performance when using an LLM-as-a-judge. However, it didn’t do particularly well on traditional NLP benchmarks in our open-source Eval Gauntlet.
We then took 1,000 random samples from our best instruction tuning dataset and finetuned our models on that. Much to our surprise, these models did better than expected on our traditional NLP evaluation suite.
We then asked whether it was possible to do well on both perplexity-based and model-based evaluation paradigms with just a few thousand finetuning samples. As we show in our paper, it is indeed possible by simply mixing datasets!
TLDR
So what should you do if you want to effectively and cheaply “instruction finetune” an LLM?
- Finetune on a small number of diverse, high-quality samples for style alignment. When instruction finetuning your LLM, make sure to include diverse samples with different styles and from different sources that also match your evaluation paradigm. For example, we found it particularly helpful to combine trivia-like multiple choice QA samples (in a style similar to benchmarks like MMLU) with longer, more open-ended “AI-assistant” style QA examples (which are favored by LLMs “as-a-judge”). We found that mixing 2,000 - 6,000 samples was surprisingly effective at the 7B and 30B model scales.
- Use multiple evaluation paradigms. Make sure to evaluate your model using both traditional NLP evaluation paradigms such as MMLU as well as newer paradigms like LLM-as-a-judge.
Doing these two things will optimize your LLM for standard NLP benchmarks as well as more fluid “AI assistant”-like conversation evaluation methods.
Why does this work?
Pretrained LLMs aren’t particularly good at responding coherently out of the box. At a minimum, they have to be finetuned in order to respond in a particular style.
“Finetuning” is an umbrella term that can include small datasets like LIMA as well as large datasets such as FLANv2, which contains more than 15 million examples of question-answer pairs extracted from a wide swath of traditional NLP datasets and organized into instruction templates for 1,836 tasks.
It is helpful to disentangle the process of finetuning to introduce new factual knowledge into an LLM, from the process of finetuning to align an LLM to a question answering format. There is ample evidence that �“more data is better” when it comes to introducing new knowledge to a model. However, if all you want to do is take a base LLM and finetune it to respond in a particular style, then maybe you don’t need that many finetuning samples. Following the LIMA paper, we use the term “style alignment” to refer to the general idea that LLMs can be finetuned to match a particular style.
General users expect LLMs to respond in the style of a general-purpose “AI assistant,” with polite, paragraph-length responses to open-ended queries. Researchers and developers, on the other hand, often optimize LLMs to do well on academic benchmarks such as MMLU and BIG-bigBench that require a different style with a multiple-choice, terse format.
The stylistic differences are reflected in different evaluation paradigms. NLP evaluation benchmarks such as MMLU contain short, academic-style questions and expect an exact token match. However, it is difficult to evaluate the quality and style of a model’s responses to more general, open-ended questions when using traditional perplexity-based NLP benchmarks. With the advent of easily accessible high-quality LLMs like LLaMA and ChatGPT, it became possible to evaluate model quality by using another LLM as a judge (e.g. AlpacaEval and MTBench). In this model-based evaluation paradigm, an LLM is prompted with an instruction and is asked to judge a pair of corresponding responses.
When framed in this way, it makes sense that finetuning an LLM to respond in a terse, multiple choice format might simply require just a handful of samples. Similarly, if we want a model to sound like ChatGPT, finetuning on a handful of samples is sufficient.
This work is extensively detailed in our arXiv paper LIMIT: Less Is More for Instruction Tuning Across Evaluation Paradigms (Jha et al. 2022). For a technical summary of our experiments, keep on reading!
Technical Deep Dive
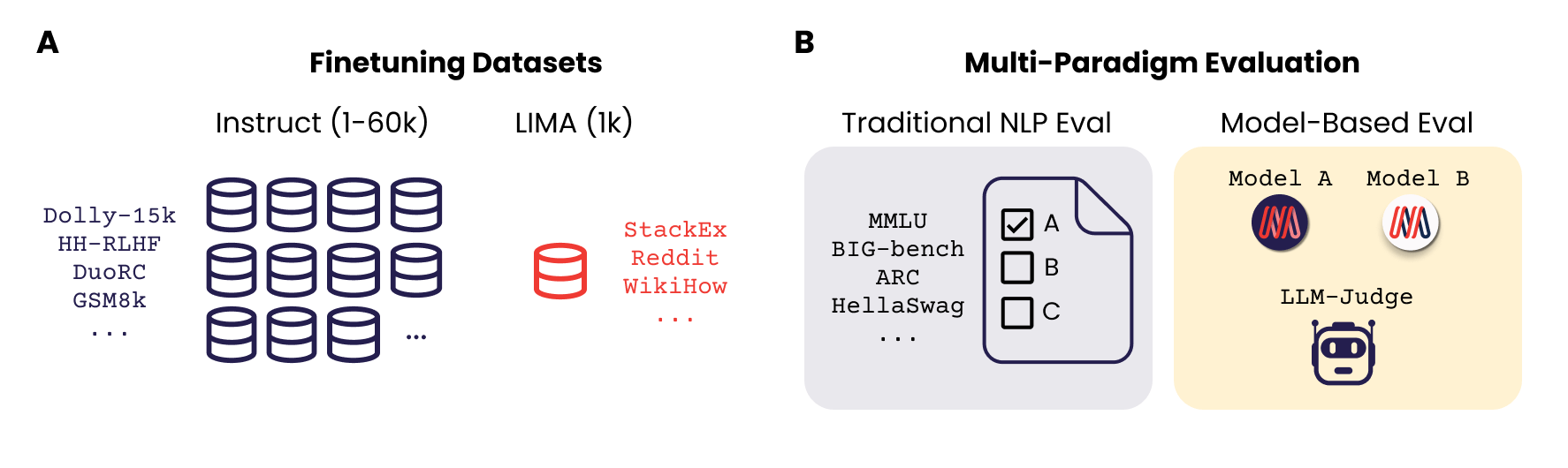
We chose to focus on two open-source models from the Mosaic MPT family, MPT-7B and MPT-30B, as well as three open-source instruction tuning datasets: Instruct-v1 (59.3k samples, also called dolly_hhrlhf) and Instruct-v3 (56.2k samples), which are the corresponding instruction finetuning datasets for MPT-7B-Instruct and MPT-30B-Instruct, and the LIMA dataset (1k samples). We evaluate model performance using (1) Mosaic’s efficient, open-source Eval Gauntlet, which is based on traditional NLP benchmarks such as MMLU and BIG-bench, as well as (2) AlpacaEval’s suite for model-based evaluation using GPT-4 as the judge.
Instruction Finetuning Dataset Details
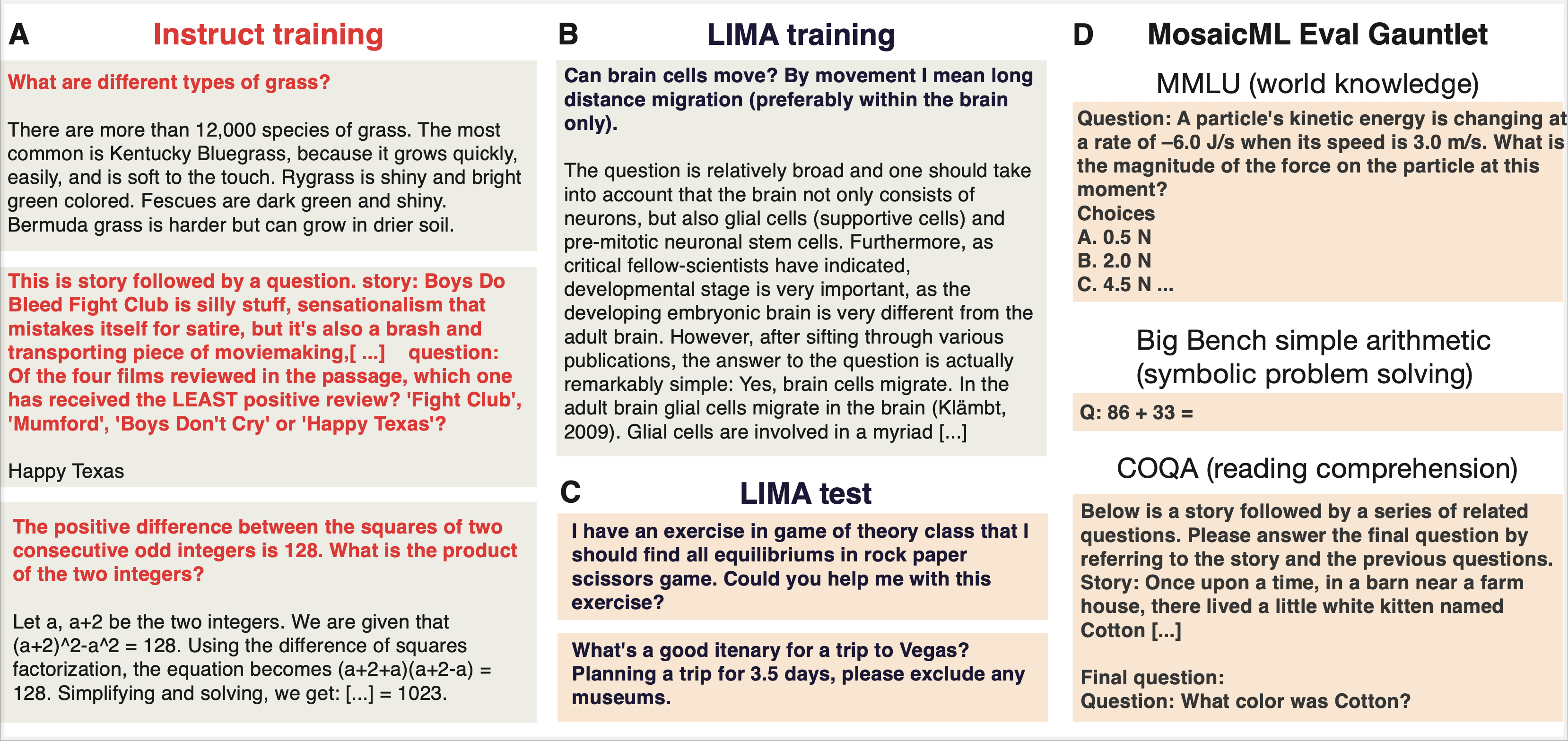
We used three publicly available finetuning datasets. The LIMA training and test sets have high-quality samples of open-ended questions and multi-paragraph answers written in the tone of a general-purpose AI assistant. The MPT Instruct-v1 and MPT Instruct-v3 training (and test sets) contain trivia-like questions and answers that tend to be shorter than one paragraph. In our paper, we explored the differences between these datasets in detail; each of the three datasets is briefly described below.
LIMA Dataset: The LIMA training set contains 1,000 samples (750,000 tokens) curated from Reddit, Stack Overflow, wikiHow, Super-NaturalInstructions, and examples manually written by the paper authors. The examples were selected after strict filtering to ensure diversity and quality. LIMA’s authors sampled an equal number of prompts from various categories within StackExchange (programming, math, English, cooking, etc.) and selected the top answer for each prompt, which then went through additional filtering based on length and writing style. In this study, we only used the single-turn examples.
You can get a sense of what kind of questions and responses are in this dataset by looking at a clustered version maintained by Lilac AI. Browsing this dataset reveals creative writing prompts, such as “Write a poem from the perspective of a dog,” marketing questions such as “How to make your LinkedIn profile stand out?” as well as programming questions, relationship advice, fitness and wellness tips, etc. Most of the curated responses span multiple paragraphs.
MPT Instruct-v1 Dataset (a.k.a “Dolly-HHRLHF”): This training set was used to train the MPT-7BInstruct model. The MPT Instruct-v1 dataset contains the Databricks Dolly-15k dataset and a curated subset of Anthropic’s Helpful and Harmless (HH-RLHF) datasets, both of which are open source and commercially licensed. Mosaic’s MPT-7B-Instruct model was finetuned using this dataset. It contains 59.3k examples; 15k are derived from Dolly-15k and the rest are from Anthropic’s HH-RLHF dataset. Dolly-15k contains several classes of prompts including classification, closed-book question answering, generation, information extraction, open QA, and summarization. Anthropic’s HH-RLHF dataset contains crowd-sourced conversations of workers with Anthropic’s LLMs. Only the first turn of multi-turn conversations was used, and chosen samples were restricted to be helpful and instruction-following in nature (as opposed to harmful).
MPT Instruct-v3 Dataset: This training set was used to train the MPT-30B-Instruct model. It contains a filtered subset of MPT Instruct-v1, as well as several other publicly available datasets: Competition Math, DuoRC, CoT GSM8k, Qasper, SQuALITY, Summ Screen FD and Spider. As a result, Instruct-v3 has a large number of reading comprehension examples, where the instructions contain a long passage of text followed by questions related to the text (derived from DuoRC, Qasper, Summ Screen FD, SQuALITY). It also contains math problems derived from CompetitionMath and CoT GSM8K, as well as text-to-SQL prompts derived from Spider. Instruct-v3 has a total of 56.2k samples. Both Instruct-v1 and Instruct-v3 were purpose-built to improve performance on traditional NLP benchmarks.
You can also get a sense of how different instruct-v3 is from the LIMA dataset by looking at topic clusters here. This dataset contains thousands of math problems such as “Solve for x: 100^3 = 10^x” as well as questions on plot summaries, sports and entertainment trivia, and history trivia such as “What year did the first cold war start?” When skimming through the examples, it is clear that multiple examples are often included in the instructions (i.e. a form of in-context learning) and that correct responses are usually shorter than a single sentence.
LIMA finetuning does not do well on perplexity based NLP benchmarks
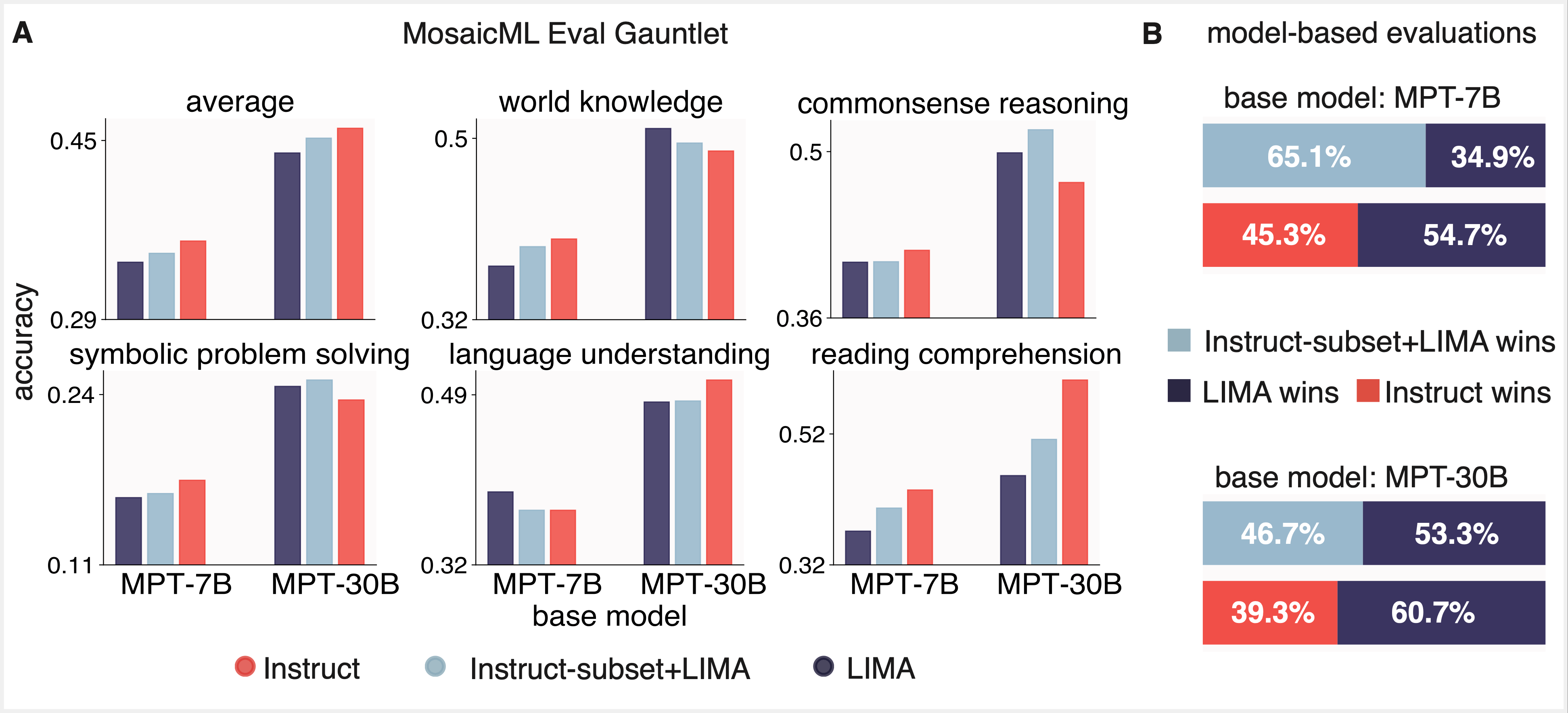
We first asked whether LIMA’s 1,000 sample dataset could deliver on its promise: could we finetune a MPT base model on LIMA that delivers optimal performance on traditional NLP benchmarks AND performs well when evaluated by an LLM? We finetuned MPT-7B and MPT-30B base models on LIMA and evaluated the resulting models using Mosaic’s Eval Gauntlet as well as AlpacaEval’s model-based evaluation suite with GPT-4 as the “judge” (Figures 3 and 4). While the resulting models were judged favorably by GPT-4, we found that they did not perform on par with MPT-7B and MPT-30B trained on the somewhat larger instruction finetuning datasets (Instruct-v1 and Instruct-v3, respectively).
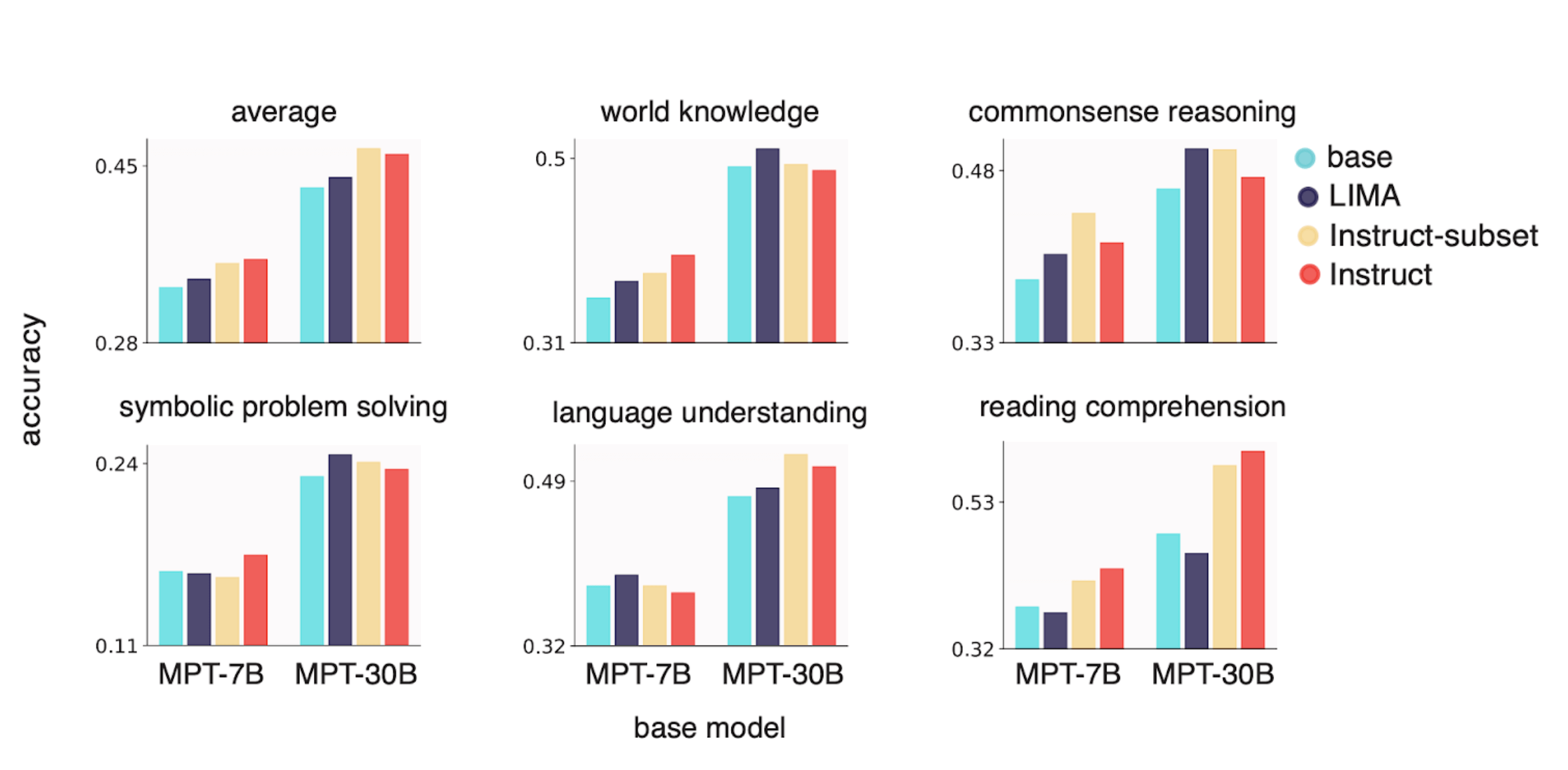
A few thousand “in-domain” samples are enough to do well on perplexity based NLP benchmarks
We suspected that the LIMA dataset was slightly out-of-domain with respect to MMLU and BIG-bench, so we investigated whether a random subset of 1,000-5,000 “in-domain” samples from Instruct-v1 and Instruct-v3 could reach parity on the Eval Gauntlet with the full datasets. We were pleasantly surprised to find that this small subset of finetuning data had similar performance on the Eval Gauntlet, corroborating the general small-sample approach of LIMA (Figure 3). However, these same models did poorly when evaluated by GPT-4 (Figure 4).
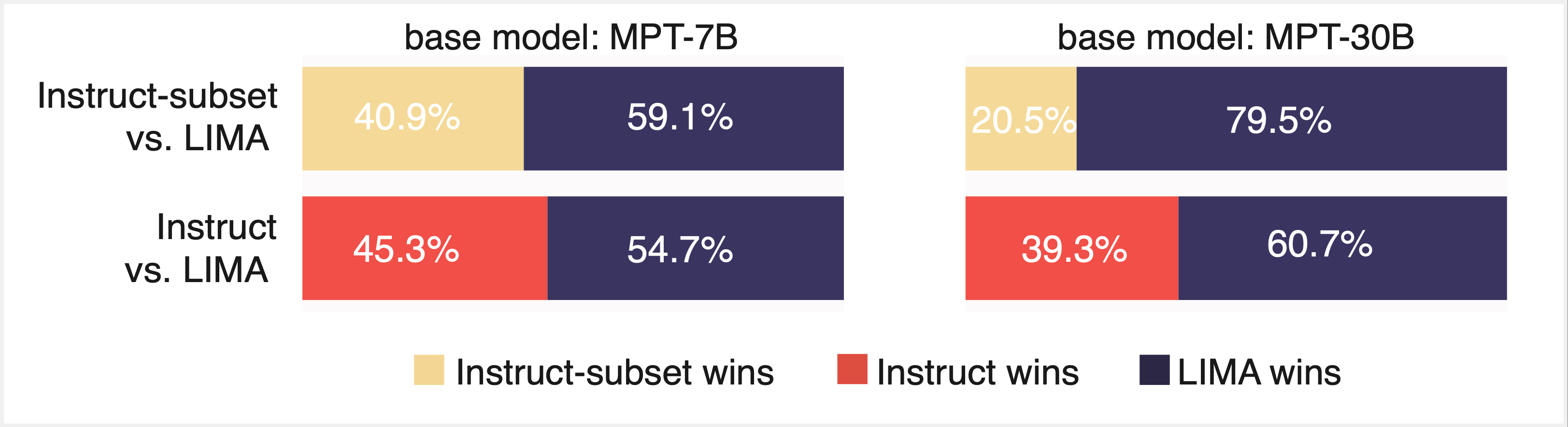
The best of both worlds: mixing Instruct and LIMA datasets improves performance across both evaluation paradigms
Finally, we considered whether we could get the best of both worlds—i.e. get good performance on both evaluation paradigms—by finetuning on a subset of a few thousand Instruct and LIMA samples (Figure 5). We found that this indeed led to good performance across both paradigms. While we were initially skeptical that effective finetuning could be achieved with less than 1,000 samples, our results replicated LIMA and built on the “less is more” approach to style alignment.
What’s next in the field?
The shift away from instruction finetuning on larger and larger datasets was catalyzed by the open-source release of the LLaMA models and by the closed-source launch of GPT-3 and chatGPT. AI researchers quickly realized that open source LLMs such as LLaMA-7B could be effectively finetuned on high-quality instruction following data generated by state-of-the-art GPT models.
For example, Alpaca is a 7 billion parameter LLaMa model finetuned on 56,000 examples of question-response samples generated by GPT-3 (text-davinci-003). The authors of this study found that Alpaca responded in a similar style to the much larger GPT-3 model. While the methods used in the Alpaca study were somewhat questionable (the human preference evaluation was done by the 5 authors themselves), further finetuning studies such as Vicuna, MPT-7B-chat, Tülü, Baize, and Falcon-40B arrived at similar conclusions. Unfortunately, results across many of these papers are based on different evaluation paradigms, making them difficult to compare side-by-side.
Fortunately, additional research has begun to fill out the full picture. The Tülü paper “How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources” (Wang et al. 2023) argued that finetuned LLMs should be tested using traditional fact-recall capabilities with benchmarks like MMLU, along with model-based evaluation (using GPT-4) and crowd-sourced human evaluation. Both the Tülü and the follow up Tülü 2 paper found that finetuning LLaMA models over different datasets promotes specific skills and that no one dataset improves performance over all evaluation paradigms.
In “The false promise of imitating proprietary LLMs” (Gudibande et al. 2023), the authors showed that while finetuning small LLMs with “imitation” data derived from ChatGPT conversations can improve conversational style, this method does not lead to improved performance on traditional fact-based benchmarks like MMLU and Natural Questions. However, they did note that training on GPT-4-derived “imitation” data in the domain of Natural-Questions-like queries improves performance on the Natural Questions benchmark. Finally, the “AlpaGasus: Training A Better Alpaca with Fewer Data” (Chen et al. 2023) and “Becoming self-instruct: introducing early stopping criteria for minimal instruct tuning” (AlShikh et al. 2023) directly addressed the question of how many finetuning examples are necessary for good downstream performance. Our results align nicely with the above studies.
Acknowledgements and Code
This line of work was inspired by LIMA as well as the Tulu papers from AI2 (How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources and Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2).
All experiments were done using Mosaic’s Composer library and llm-foundry repository for LLM training in PyTorch 1.13. More details are available on our project website.
Finetuning Datasets
- Mosaic Instruct-v1 (aka “Dolly-HHRLHF”)
- Mosaic Instruct-v3
- LIMA
- Instruct-v1 subset (5k samples)
- Instruct-v3 subset (1k samples)
LLM Model Weights
- MPT-7B-Base
- MPT-30B-Base
- MPT-7B-Instruct (finetuned with instruct-v1)
- MPT-30B-Instruct (finetuned with instruct-v3)
This research was led by Aditi Jha and Jacob Portes with advice from Alex Trott. Sam Havens led the development of Instruct-v1 and Instruct-v3 datasets, and Jeremy Dohmann developed the Mosaic evaluation harness.
Disclaimer
The work detailed in this blog was performed for research purposes, and not for Databricks product development.