LLM Training and Inference with Intel Gaudi 2 AI Accelerators
by Abhi Venigalla and Daya Khudia
At Databricks, we want to help our customers build and deploy generative AI applications on their own data without sacrificing data privacy or control. For customers who want to train a custom AI model, we help them do so easily, efficiently, and at a low cost. One lever we have to address this challenge is ML hardware optimization; to that end, we have been working tirelessly to ensure our LLM stack can seamlessly support a variety of ML hardware platforms (e.g., NVIDIA [1][2], AMD [3][4]).
Today, we are excited to discuss another entrant in the AI training and inference market: the Intel® Gaudi® family of AI Accelerators. These accelerators are available via AWS (first-generation Gaudi), the Intel Developer Cloud (Gaudi 2), and for on-premises implementations, Supermicro and WiWynn (Gaudi and Gaudi 2 accelerators).
In this blog, we profile the Intel Gaudi 2 for LLM training using our open source LLM Foundry and for inference using the open source Optimum Habana library. We find that overall, the Intel Gaudi 2 accelerator has the 2nd best training performance-per-chip we've tested (only bested by the NVIDIA H100), with over 260 TFLOP/s/device achieved when training MPT-7B on 8 x Gaudi 2. For multi-node training, we had access to 160x Intel Gaudi 2 accelerators and found near-linear scaling across the cluster. For LLM inference, we profiled LLaMa2-70B and found that the 8 x Gaudi 2 system matches the 8 x H100 system in decoding latency (the most expensive phase of LLM inference).
Because the Gaudi 2 accelerator is publicly available via the Intel Developer Cloud (IDC), we could also estimate performance-per-dollar. Based on public, on-demand pricing from Lambda and Intel, we find that Intel Gaudi 2 is a compelling option for training and inference workloads.
All results in this blog were measured using SynapseAI 1.12 and BF16 mixed precision training. In the future, we look forward to exploring SynapseAI 1.13, which unlocks Gaudi 2's support for FP8 training, successfully demonstrated in their MLPerf Training 3.1 GPT3 submission as achieving 379 TFLOP/s/device on a cluster of 256xGaudi 2 and 368 TFLOP/s/device on a cluster of 384xGaudi 2. These FP8 training results are nearly 1.5x faster than our results with BF16. SynapseAI 1.13 is also expected to bring a lift in LLM inference performance.
Read on for details on the Intel Gaudi platform, LLM training and inference results, LLM convergence results, and more. In future blog posts, we'll also show you how to get large performance increases on NVIDIA H100 with FP8 support.
Intel Gaudi 2 Hardware
The Intel Gaudi 2 accelerator supports both deep learning training and inference for AI models like LLMs. The Intel Gaudi 2 accelerator is built on a 7nm process technology. It has a heterogeneous compute architecture that includes dual matrix multiplication engines (MME) and 24 programmable tensor processor cores (TPC). When compared to popular cloud accelerators in the same generation, such as the NVIDIA A100-40GB and A100-80GB, the Gaudi 2 has more memory (96GB of HBM2E), higher memory bandwidth, and higher peak FLOP/s. Note that the AMD MI250 has higher specs per chip but comes in smaller system configurations of only 4xMI250. In Table 1a we compare the Intel Gaudi 2 against the NVIDIA A100 and AMD MI250, and in Table 1b we compare the upcoming Intel Gaudi 3 against the NVIDIA H100/H200 and AMD MI300X.
The Intel Gaudi 2 accelerator ships in systems of 8x Gaudi 2 accelerators and has a unique scale-out networking design built on RDMA over Converged Ethernet (RoCEv2). Each Gaudi 2 accelerator integrates 24 x 100 Gbps Ethernet ports, with 21 ports dedicated to all-to-all connectivity within a system (3 links to each of the seven other devices) and the remaining three links dedicated to scaling out across systems. Overall, this means each 8x Gaudi 2 system has 3 [scale-out links] * 8 [accelerators] * 100 [Gbps] = 2400 Gbps of external bandwidth. This design enables fast, efficient scale-out using standard Ethernet hardware.
At Databricks, we obtained access to a large multi-node Intel Gaudi 2 cluster via the Intel Developer Cloud (IDC), which was used for all profiling done in this blog.
| Intel Gaudi 2 | AMD MI250 | NVIDIA A100-40GB | NVIDIA A100-80GB | |||||
|---|---|---|---|---|---|---|---|---|
| Single Card | 8x Gaudi2 | Single Card | 4x MI250 | Single Card | 8x A100-40GB | Single Card | 8x A100-80GB | |
| FP16 or BF16 TFLOP/s | ~400 TFLOP/s | ~3200 TFLOP/s | 362 TFLOP/s | 1448 TFLOP/s | 312 TFLOP/s | 2496 TFLOP/s | 312 TFLOP/s | 2496 TFLOP/s |
| HBM Memory (GB) | 96 GB | 768 GB | 128 GB | 512 GB | 40GB | 320 GB | 80GB | 640 GB |
| Memory Bandwidth | 2450 GB/s | 19.6 TB/s | 3277 GB/s | 13.1 TB/s | 1555 GB/s | 12.4TB/s | 2039 GB/s | 16.3 TB/s |
| Peak Power Consumption | 600W | 7500 W | 560W | 3000 W | 400W | 6500 W | 400W | 6500 W |
| Rack Units (RU) | N/A | 8U | N/A | 2U | N/A | 4U | N/A | 4U |
| Intel Gaudi 3 | AMD MI300X | NVIDIA H100 | NVIDIA H200 | |||||
|---|---|---|---|---|---|---|---|---|
| Single Card | 8x Gaudi3 | Single Card | 8x MI300X | Single Card | 8x H100 | Single Card | 8x H200 | |
| FP16 or BF16 TFLOP/s | ~1600 TFLOP/s | ~12800 TFLOP/s | 1307 TFLOP/s | 10456 TFLOP/s | 989.5 TFLOP/s | 7916 TFLOP/s | 989.5 TFLOP/s | 7916 TFLOP/s |
| HBM Memory (GB) | N/A | N/A | 192 GB | 1536 GB | 80GB | 640 GB | 141GB | 1128 GB |
| Memory Bandwidth | ~3675 GB/s | ~29.4 TB/s | 5300 GB/s | 42.4 TB/s | 3350 GB/s | 26.8 TB/s | 4800 GB/s | 38.4 TB/s |
| Peak Power Consumption | N/A | N/A | 750 W | N/A | 700 W | 10200 W | 700 W | 10200 W |
| Rack Units (RU) | N/A | N/A | N/A | 8U | N/A | 8U | N/A | 8U |
Table 1a (top) and Table 1b (bottom): Hardware specs for NVIDIA, AMD, and Intel accelerators. Please note that only a subset of specs have been released publicly as of Dec 2023. The TFLOP/s numbers for Gaudi 2 are estimated using microbenchmarks run by Databricks, and the TFLOP/s and Memory Bandwidth for Gaudi 3 are projected using public information from Intel.
Intel SynapseAI Software
The Intel SynapseAI® software suite crucially enables PyTorch programs to run seamlessly on Gaudi devices with minimal modifications. SynapseAI provides a graph compiler, a runtime, optimized kernels for tensor operations, and a collective communication library. Figure 1 shows Intel Gaudi's software stack with all its key components. More details about SynapseAI are available in the official documentation.
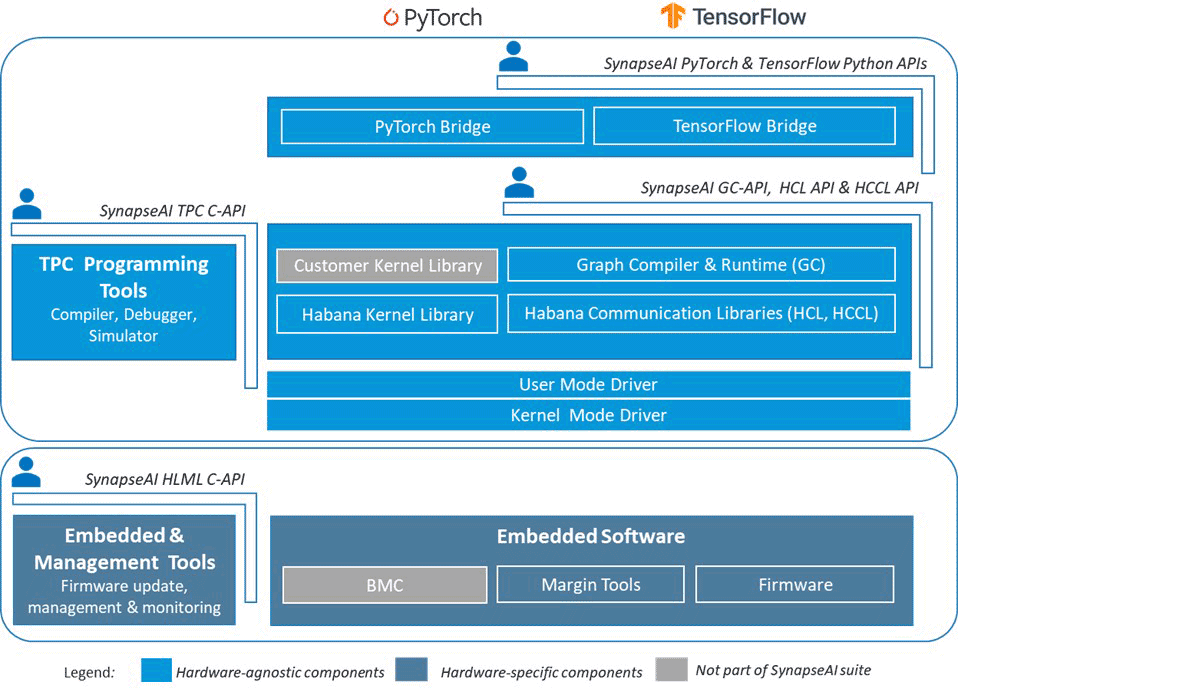
One of the most popular libraries for ML programmers is PyTorch, and developers should be excited to know that PyTorch runs in eager mode or lazy mode on Intel accelerators like Gaudi 2. All you need to do is install the Gaudi-provided build of PyTorch (install matrix here) or start from one of their Docker images. Generally, running HuggingFace/PyTorch code on Gaudi hardware requires minimal code modifications. These changes typically include substituting tensor.cuda( ) commands with tensor.to( 'hpu' ) commands or using a PyTorch trainer like Composer or HF Trainer, which already has Gaudi support built in.
LLM Training Performance
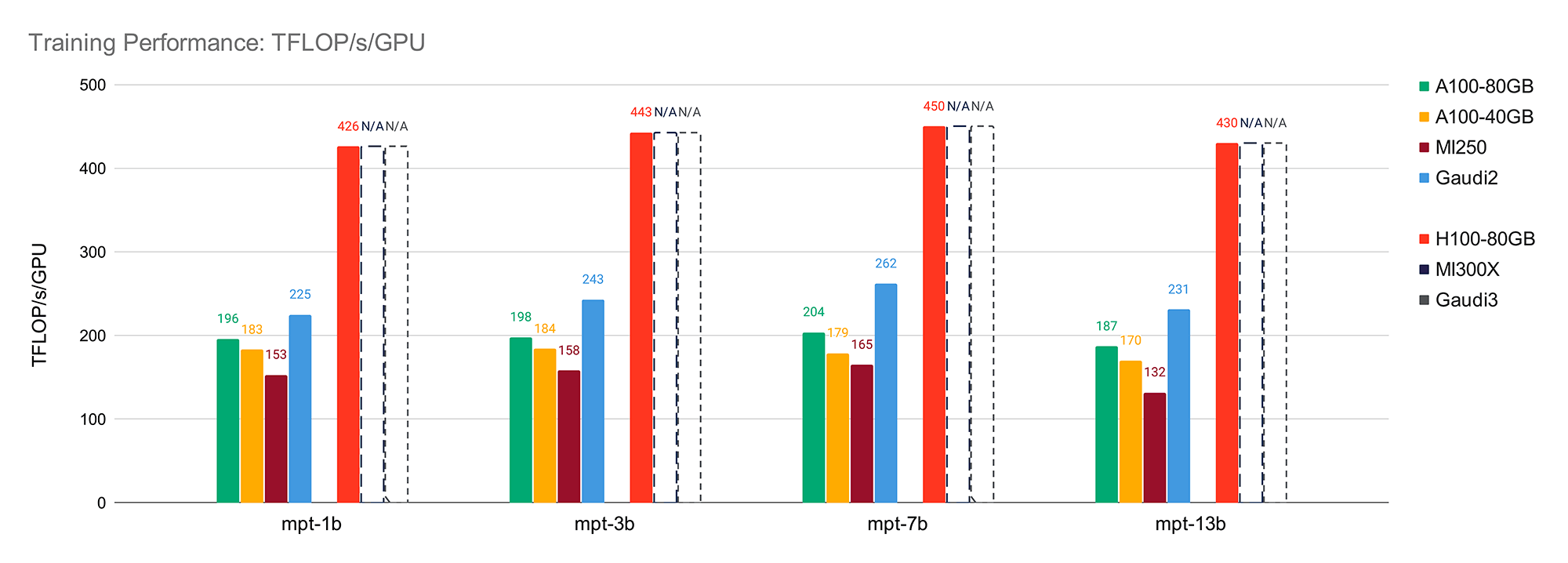
For single-node LLM training performance, we found that the Intel Gaudi 2 has compelling performance for AI workloads, with the caveat that availability is currently restricted to the Intel Developer Cloud. Gaudi 2 reaches over 260 TFLOP/s/device with SynapseAI 1.12 and BF16 mixed precision training. See Figure 2 for a comparison of the Intel Gaudi 2 vs. NVIDIA and AMD GPUs.
On each platform, we ran the same training scripts from LLM Foundry using MPT models with a sequence length of 2048, BF16 mixed precision, and the ZeRO Stage-3 distributed training algorithm. On NVIDIA or AMD systems, this algorithm is implemented via PyTorch FSDP with sharding_strategy: FULL_SHARD. On Intel systems, this is currently done via DeepSpeed ZeRO with Stage: 3 but FSDP support is expected to be added in the near future.
On each system, we also used the most optimized implementation of scaled-dot-product-attention (SDPA) available:
- NVIDIA: Triton FlashAttention-2
- AMD: ROCm ComposableKernel FlashAttention-2
- Intel: Gaudi TPC FusedSDPA
Finally, we tuned the microbatch size for each model on each system to achieve maximum performance. All training performance measurements are reporting model FLOPs rather than hardware FLOPs. See our benchmarking README for more details.
Under the right circumstances, we found that Gaudi 2 had the highest LLM training performance vs. the same-generation NVIDIA A100 and AMD MI250 GPUs, with an average speedup of 1.22x vs. the A100-80GB, 1.34x vs. the A100-40GB, and 1.59x vs. the MI250.
When compared against the NVIDIA H100, there is still a significant gap to close: on average, the Intel Gaudi 2 performs at 0.55x the H100. Looking forward, the next-gen Intel Gaudi 3 has been publicly announced to have 4x the BF16 performance of the Gaudi 2 and 1.5x the HBM bandwidth, making it a strong competitor to the H100.
Although this blog focuses on BF16 training, we anticipate that FP8 training will soon become a standard among major accelerators (NVIDIA H100/H200, AMD MI300X, Intel Gaudi 2/Gaudi 3), and we look forward to reporting on those numbers in future blogs. For the Intel Gaudi 2, FP8 training is supported, beginning with SynapseAI version 1.13. For preliminary FP8 training results for the NVIDIA H100 and Intel Gaudi 2, check out the MLPerf Training 3.1 GPT3 results.
Now, performance is great, but what about performance per dollar? We used publicly available pricing to compute an average training performance per dollar. Note that Gaudi 2 is currently only available in the IDC, while NVIDIA GPUs are available from many providers. For a fair comparison, we used NVIDIA GPUs hosted by Lambda Labs, which historically has low pricing.
| System | Cloud Service Provider | On-Demand $/Hr | On-Demand $/Hr/Device | Avg MPT Training BF16 Performance [TFLOP/s/Device] | Performance-per-dollar [ExaFLOP / $] |
|---|---|---|---|---|---|
| 8xA100-80GB | Lambda | $14.32/hr | $1.79/hr/GPU | 196 | 0.3942 |
| 8xA100-40GB | Lambda | $10.32/hr | $1.29/hr/GPU | 179 | 0.4995 |
| 4xMI250 | N/A | N/A | N/A | 152 | N/A |
| 8xGaudi 2 | IDC | $10.42/hr | $1.30/hr/Device | 240 | 0.6646 |
| 8xH100 | Lambda | $27.92/hr | $3.49/hr/GPU | 437 | 0.4508 |
Table 2: Training Performance-per-Dollar for various AI accelerators available in Lambda's GPU cloud and the Intel Developer Cloud (IDC).
Based on these public on-demand quoted prices from Lambda and IDC, we found that the Intel Gaudi 2 has compelling training performance per dollar, with an average advantage of 1.69x vs. the NVIDIA A100-80GB, 1.33x vs. the NVIDIA A100-40GB, and 1.47x vs. the NVIDIA H100. Once again, these comparisons may vary based on customer-specific discounts on different cloud providers.
Moving on to multi-node performance, the Intel Gaudi 2 cluster has great scaling performance for LLM training. In Figure 3, we trained an MPT-7B model with fixed global train batch size samples on [1, 2, 4, 10, 20] nodes and saw a performance of 262 TFLOP/s/device at one node (8x Gaudi 2) to 244 TFLOP/s/device at 20 nodes (160x Gaudi 2). Note that for these results, we used DeepSpeed with ZeRO Stage-2 rather than Stage-3 for maximum multi-node performance.
For more details about our training configs and how we measured performance, see our public LLM Foundry training benchmarking page.
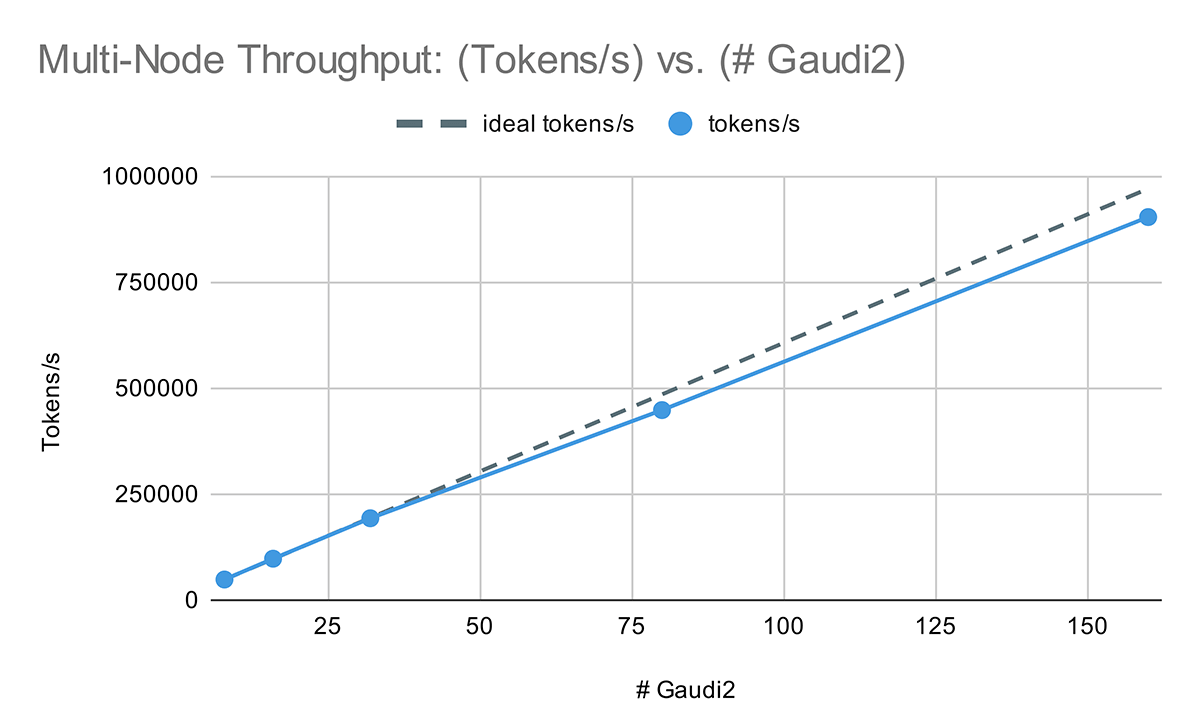
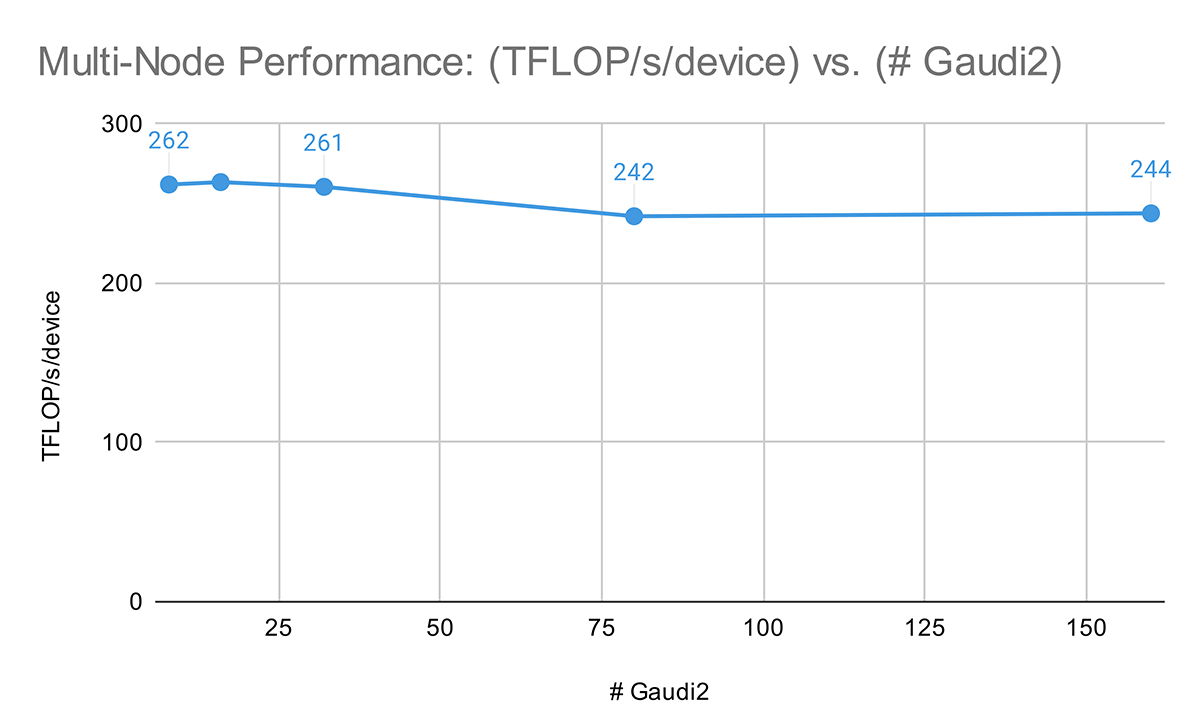
Given these results, in addition to Intel's MLPerf Training 3.1 results training GPT3-175B on up to 384x Gaudi 2, we are optimistic about Intel Gaudi 2 performance at higher device counts, and we look forward to sharing results on larger Intel Gaudi 2/Gaudi 3 clusters in the future.
LLM Convergence
To test training stability on Intel Gaudi 2, we trained MPT-1B, MPT-3B, and MPT-7B models from scratch on the C4 dataset using Chinchilla-optimal token budgets to confirm that we could successfully train high-quality models on the Intel Gaudi platform.
We trained each model on the multi-node Gaudi 2 cluster with BF16 mixed precision and DeepSpeed ZeRO Stage-2 for maximum performance. The 1B, 3B, and 7B models were trained on 64, 128, and 128 Gaudi 2 accelerators, respectively. Overall, we found that training was stable, and we saw no issues due to floating point numerics.
When we evaluated the final models on standard in-context-learning (ICL) benchmarks, we found that our MPT models trained on Intel Gaudi 2 achieved similar results to the open source Cerebras-GPT models. These are a family of open source models trained with the same parameter counts and token budgets, allowing us to compare model quality directly. See Table 2 for results. All models were evaluated using the LLM Foundry eval harness and using the same set of prompts. These convergence results give us confidence that customers can train high-quality LLMs on Intel AI Accelerators.
![Figure 4: Training loss curves of MPT-[1B, 3B, 7B], each trained from scratch on multi-node Gaudi2 clusters with Chinchilla-optimal token budgets.](https://www.databricks.com/sites/default/files/inline-images/db-850-blog-images-5.png)
| Model | Params | Tokens | ARC-c | ARC-e | BoolQ | Hellaswag | PIQA | Winograd | Winogrande | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| Cerebras-GPT-1.3B | 1.3B | 26B | .245 | .445 | .583 | .380 | .668 | .630 | .522 | .496 |
| Intel-MPT-1B | 1.3B | 26B | .267 | .439 | .569 | .499 | .725 | .667 | .516 | .526 |
| Cerebras-GPT-2.7B | 2.7B | 53B | .263 | .492 | .592 | .482 | .712 | .733 | .558 | .547 |
| Intel-MPT-3B | 2.7B | 53B | .294 | .506 | .582 | .603 | .754 | .729 | .575 | .578 |
| Cerebras-GPT-6.7B | 6.7B | 133B | .310 | .564 | .625 | .582 | .743 | .777 | .602 | .600 |
| Intel-MPT-7B | 6.7B | 133B | .314 | .552 | .609 | .676 | .775 | .791 | .616 | .619 |
Table 2: Training Performance-per-Dollar for various AI accelerators available in Lambda's GPU cloud and the Intel Developer Cloud (IDC).
LLM Inference
Moving on to inference, we leveraged the Optimum Habana package to run inference benchmarks with LLMs from the HuggingFace Transformer library on Gaudi 2 hardware. Optimum Habana is an efficient intermediary, facilitating seamless integration between the HuggingFace Transformer library and Gaudi 2 architecture. This compatibility allows for direct, out-of-the-box deployment of supported HuggingFace models on Gaudi 2 platforms. Notably, after the necessary packages were installed, we observed that the LLaMa2 model family was compatible with the Gaudi 2 environment, enabling inference benchmarking to proceed smoothly without requiring any modifications.
For our inference benchmarking on Nvidia's A100 and H100 devices, we utilized TRT-LLM (main branch as of 16/11/2023 when the experiments were done), an advanced inference solution recently introduced for LLMs. TRT-LLM is specially designed to optimize the inference performance of LLMs on Nvidia hardware, leveraging the best available software from various NVIDIA libraries. We use the standard benchmark config provided by NVidia's TRT-LLM library to obtain these numbers. The standard benchmark config runs Llama-70B with GPT attention and GEMM plugins using the FP16 datatype. Please note that all comparative numbers are done with BF16 datatype on both the hardware. FP8 is available on both the hardware but is not used for benchmarking here. The software for H100 and Gaudi 2 is advancing rapidly, especially in terms of FP8 kernels and algorithms. We plan to make the results of FP8 experiments available in a future blog.
Figure 5 shows the latency-throughput curves for the Llama2-70B model for all three profiled hardware configurations. We used the same model and the same input/output lengths on all three hardware configurations. We used BF16 model weights and math for all systems. This plot allows users to estimate the achievable throughput on specified hardware configurations based on a set latency target. 8x Gaudi 2 sits between 8x A100-80GB and 8x H100 based on these results. However, for smaller batch sizes (i.e., low latency regime), 8x Gaudi 2 is much closer to 8xH100. Further analysis shows that prefill time (i.e., prompt processing time) is much slower on Gaudi 2 than H100, while token generation time on Gaudi 2 is pretty much identical, as shown in the subsequent figures. For example, for 64 concurrent users, the prefill time on H100 is 1.62 secs, while on Gaudi 2 it is 2.45 secs. Slower prefill time can be improved by incorporating better software optimizations, but this is mostly expected due to the large gap in peak FLOPs (989.5 for H100 and ~400 for Gaudi 2).
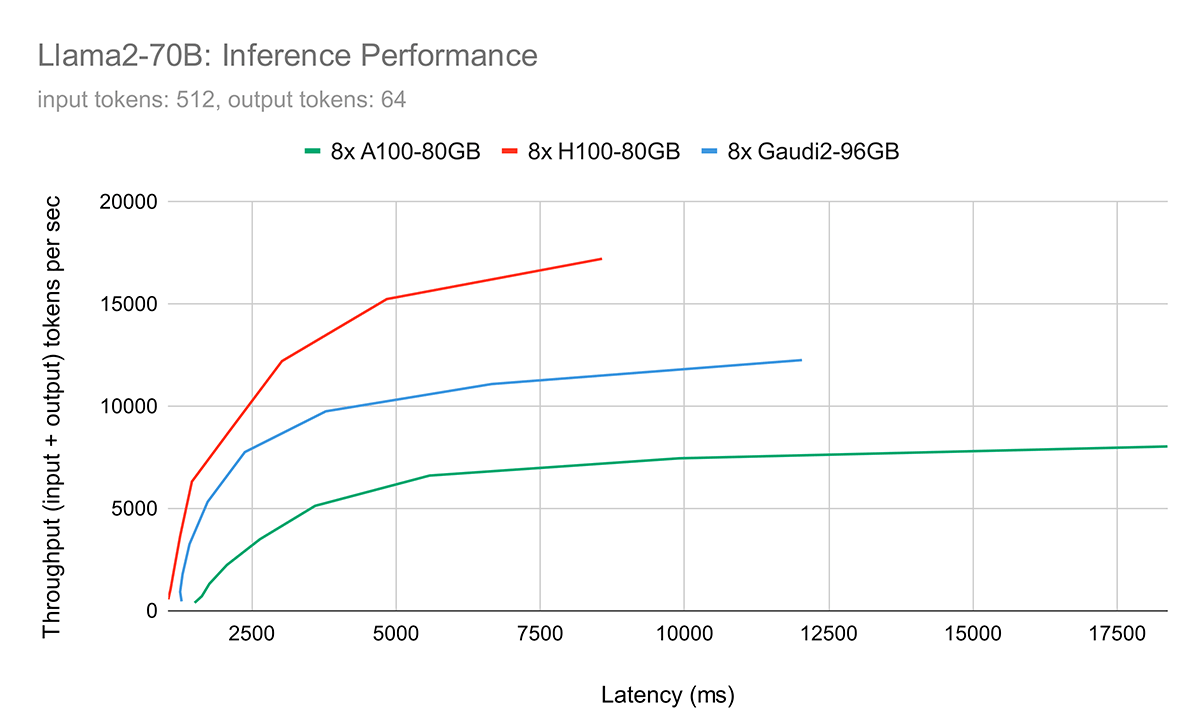
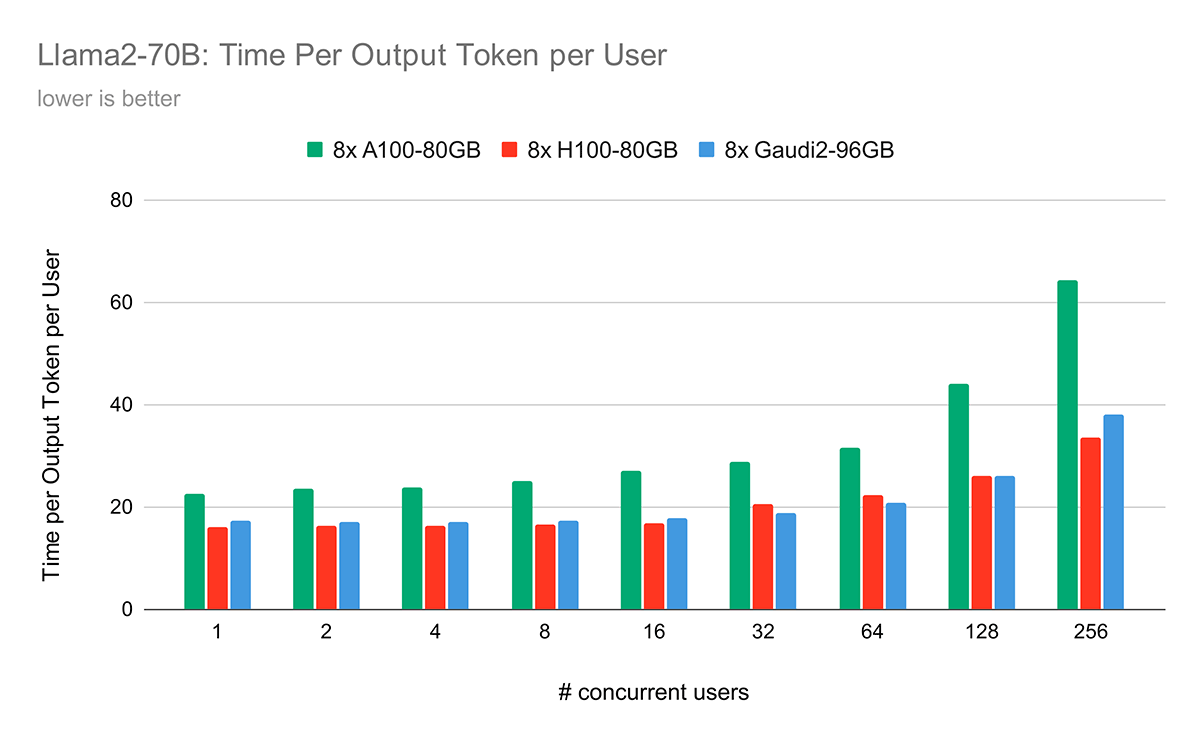
Figure 6 illustrates the time required for each hardware configuration to generate a single token per user. Notably, it highlights a key trend: Time Per Output Token (TPOT) per user is +/-8% for Intel Gaudi 2 vs. NVIDIA H100 under most of the user load scenarios. In some settings, the Gaudi 2 is faster, and in other settings, the H100 is faster. In general, across all hardware, as the number of concurrent users increases, the time taken to generate each token also increases, leading to reduced performance for every user. This correlation provides valuable insights into the scalability and efficiency of different hardware configurations under varying user loads.
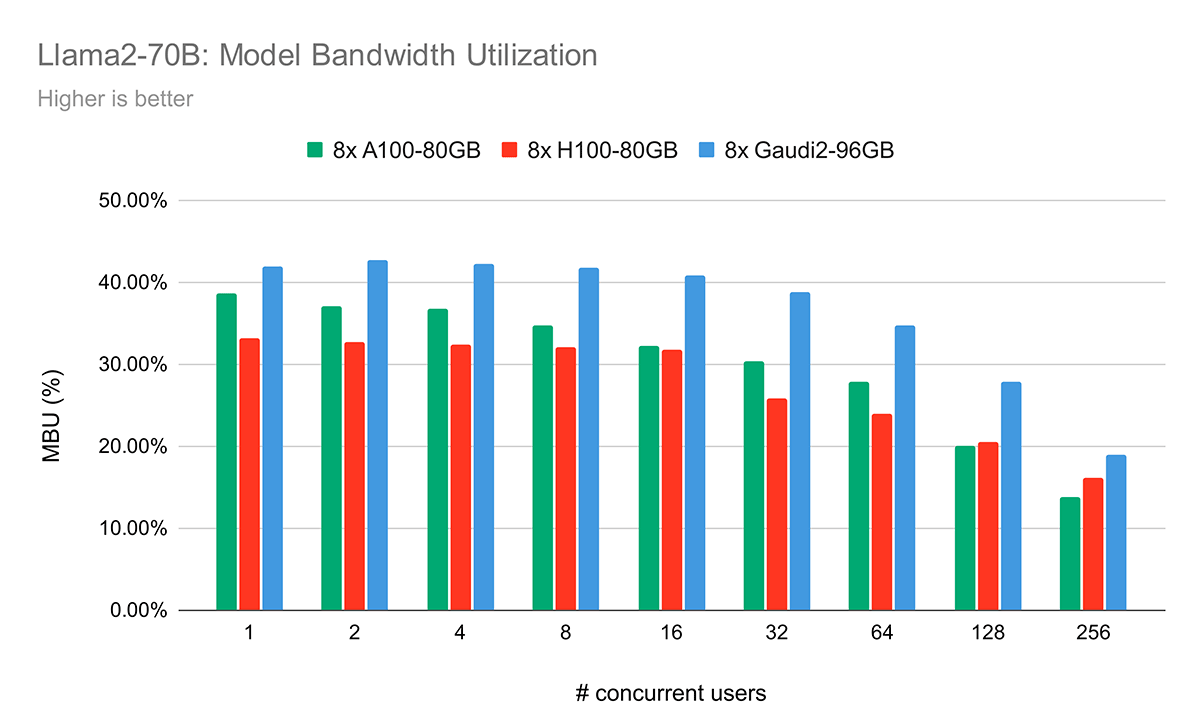
In Figure 7, we show a metric called Model Bandwidth Utilization (MBU). The concept of MBU is elaborated in greater detail in our previous LLM Inference blog post. Briefly, it denotes the measure of efficiency in scenarios where performance is primarily constrained by memory bandwidth. The process of token generation at smaller batch sizes predominantly hinges on achievable memory bandwidth. Performance in this context is heavily influenced by how effectively the software and hardware can utilize the peak memory bandwidth available. In our experiments, we observed that the Intel Gaudi 2 platform demonstrates superior MBU compared to the H100 for token generation tasks. This indicates that Intel Gaudi 2 is currently more efficient at leveraging available memory bandwidth than the A100-80GB or H100.
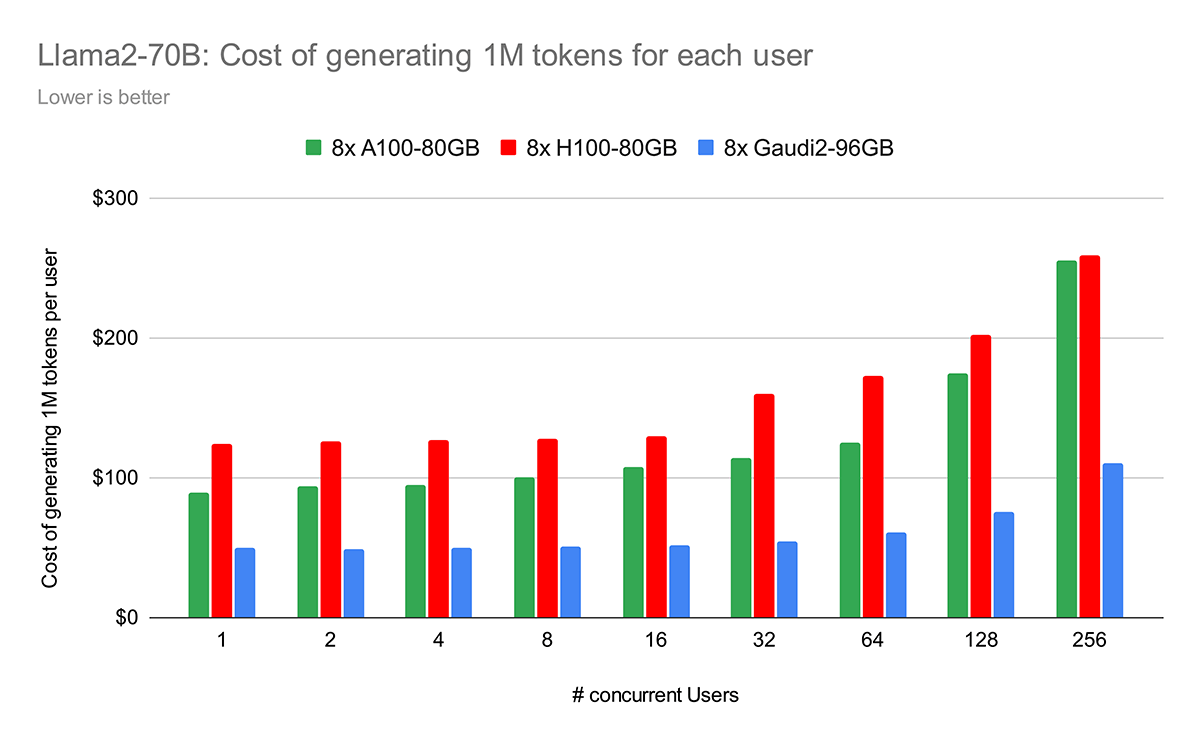
Finally, in Figure 8 we illustrate the cost of generating 1 million tokens per user across different hardware platforms. For instance, with four concurrent users, the total cost depicted is for 4 million tokens (1 million per user). This calculation is based on the pricing details provided in Table 2. Other insights include:
- H100 is more expensive than A100, primarily because its hourly cost is ~2x, while its performance gains do not proportionately match this increase (as detailed in Figure 8).
- Gaudi 2 is a compelling option due to its competitive pricing and comparable performance levels to H100.
It is important to note that none of the benchmarked hardware utilizes FP8 (available on H100 and Gaudi 2) or quantization. FP8 is a major feature of H100 and we plan to publish FP8 results in the near future.
What's Next?
In this blog, we've demonstrated that the Intel Gaudi 2 is a compelling option for LLM training and inference. Single-node and multi-node training on Gaudi 2 works well in the limited deployment we tested on Intel Developer Cloud. Performance-per-chip is the 2nd highest out of any accelerator we have tested, and the performance-per-dollar is the best when comparing on-demand pricing on Lambda and the Intel Developer Cloud. For convergence testing, we trained Chinchilla-style 1B, 3B, and 7B parameter models from scratch and found that the final model qualities matched or exceeded reference open source models.
On the inference side, we found that the Gaudi 2 punches above its weight, outperforming the NVIDIA A100 in tested deployment environments on the IDC and matching the NVIDIA H100 in decoding latency (the most expensive phase of LLM inference). This is thanks to the Intel Gaudi 2 software and hardware stack, which achieves higher memory bandwidth utilization than both NVIDIA chips. Putting it another way, with only 2450 GB/s of HBM2E memory bandwidth, the Gaudi 2 matches the H100 with 3350 GB/s of HBM3 bandwidth.
We believe these results strengthen the AI story for Intel Gaudi 2 accelerators, and thanks to the interoperability of PyTorch and open source libraries (e.g., DeepSpeed, Composer, StreamingDataset, LLM Foundry, Habana Optimum), users can run the same LLM workloads on NVIDIA, AMD, or Intel or even switch between the platforms.
Looking ahead to the Intel Gaudi 3, we expect the same interoperability but with even higher performance. The projected public information specs (See Table 1b) suggest that Intel Gaudi 3 should have more FLOP/s and memory bandwidth than all the major competitors (NVIDIA H100, AMD MI300X). Given the great training and inference utilization numbers we already see today on Gaudi 2, we are very excited about Gaudi 3 and look forward to profiling it when it arrives. Stay tuned for future blogs on Intel Gaudi accelerators and training at an even larger scale, as well as a follow-up blog post on NVIDIA H100 FP8 performance.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.