Managing CI/CD Kubernetes Authentication Using Operators
by Albert Zhong
This summer at Databricks, I interned on the Compute Lifecycle team in San Francisco. I built a Kubernetes operator that rotates service account tokens used by CI/CD deployment jobs to securely authenticate to our multi-cloud Kubernetes clusters. In this blog, I will explain how my project leverages the Kubernetes operator pattern to solve several pain points with cluster authentication.
Background
Databricks heavily uses Kubernetes to orchestrate containerized workloads for product microservices and data-processing jobs. Today, we run thousands of Kubernetes clusters and manage millions of pods across hundreds of product microservices. We offer our product on top of multiple cloud providers: to support this, we operate a mix of self-managed and cloud-managed Kubernetes clusters (EKS, AKS, GKE). We create cloud-agnostic abstractions on top of these compute systems so that other Databricks engineers can build and deploy applications without needing to consider cloud-specific details.
Databricks deploys services and resources to these Kubernetes clusters via deployment jobs run by our CI/CD pipelines. Security is a key concern: we must ensure that only privileged users or jobs can access specific clusters.
Problem
How do deployment jobs authenticate to Kubernetes clusters? For context, engineering teams own specific deployment jobs for each service. Each team has read access to their own cloud provider credentials in Hashicorp Vault. Previously, each team's job would fetch their cloud provider credentials in Vault to authenticate to a cloud-managed Kubernetes cluster. For example, to access an AKS cluster, a deployment job would fetch its team's Azure service principal credentials and authenticate via the Azure CLI. A similar authentication process exists for EKS clusters by using AWS IAM roles instead.
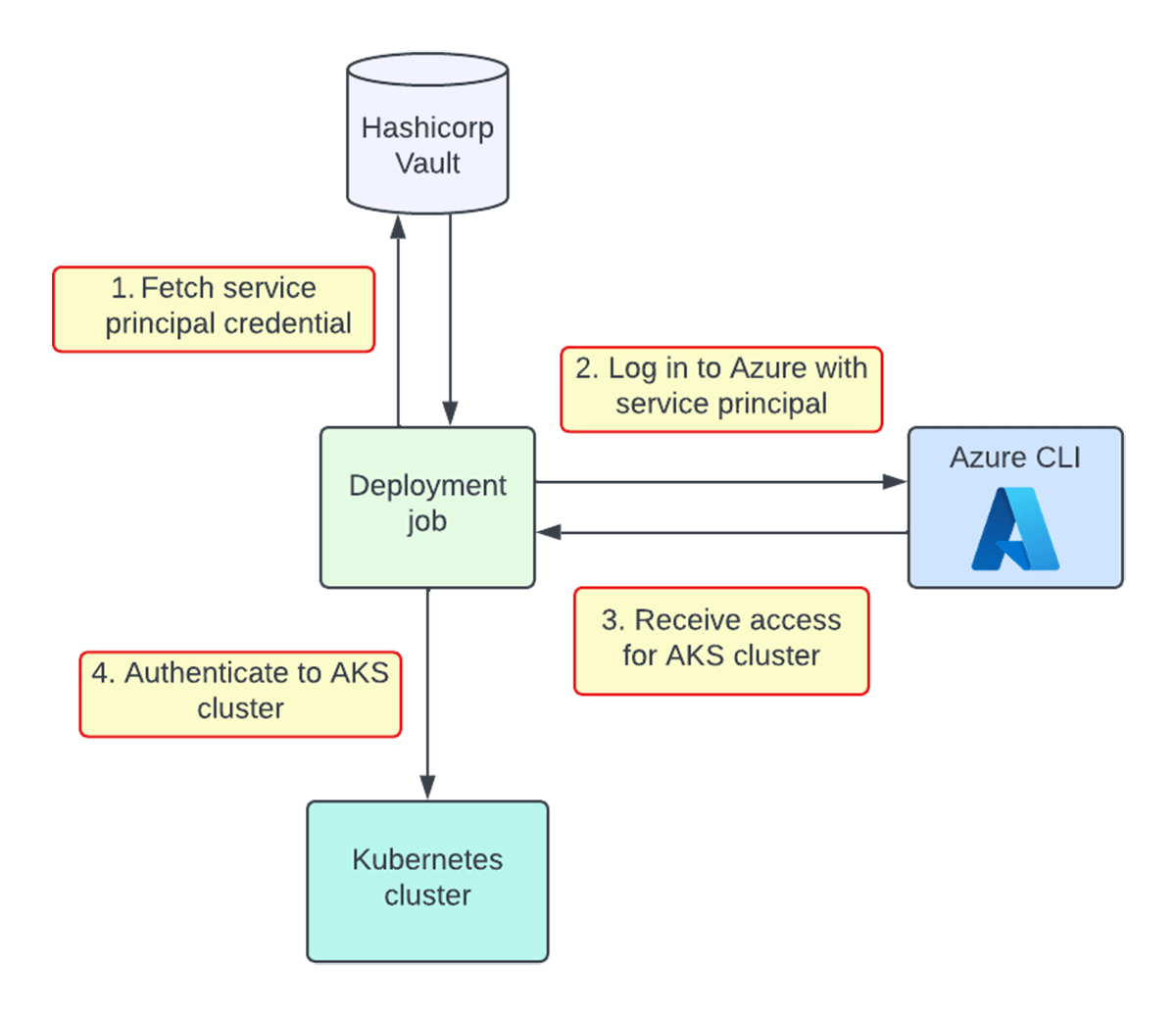
This approach is not ideal for several reasons:
- Cloud-specific - deployment job scripts must maintain separate logic to handle cluster authentication for each cloud
- Manual - for every team that is onboarded to our deployment system, cloud provider credentials need to be manually created, stored, and rotated in Vault
- Slow - these setup steps take multiple engineering hours, and new teams must wait a few days of clock time before credentials are ready
We needed a better solution that would allow teams to quickly gain access to dynamically created clusters, and scale across multiple cloud providers in cloud-managed and self-managed clusters with minimal human interaction.
Solution
Our proposal was to create a credential management service that automatically generates and rotates credentials for all teams and clusters. Instead of using cloud-specific credentials, we opted to use Kubernetes service account tokens: JWTs used to authenticate to a Kubernetes cluster under a service account. Service accounts are a natively supported concept in Kubernetes, which is compatible with both self-managed and cloud-managed Kubernetes clusters. These tokens are cloud-agnostic, short-lived, and dynamically created, which is a significant improvement over long-lived cloud provider credentials.
Our credential manager creates a unique service account token for each combination of a team and a Kubernetes cluster, and stores these tokens in Vault. In addition, this service dynamically creates tokens as new teams and clusters are added. This will allow deployment jobs to authenticate to Kubernetes clusters by fetching a cloud-agnostic service account token instead of a cloud provider credential from Vault.
Kubernetes operator model
The Kubernetes operator pattern provides a powerful, declarative API for managing complex infrastructure. Databricks already runs many controllers managing Custom Resources to govern various objects in our infrastructure stack. One example is a DatabricksKubernetesCluster - an abstraction for an internal Kubernetes cluster that may be hosted on Azure, AWS, or GCP. At Databricks, we leverage the Go Kubebuilder SDK to handle common operator scaffolding such as defining custom resources, implementing control loops, and interfacing with the Kubernetes API.
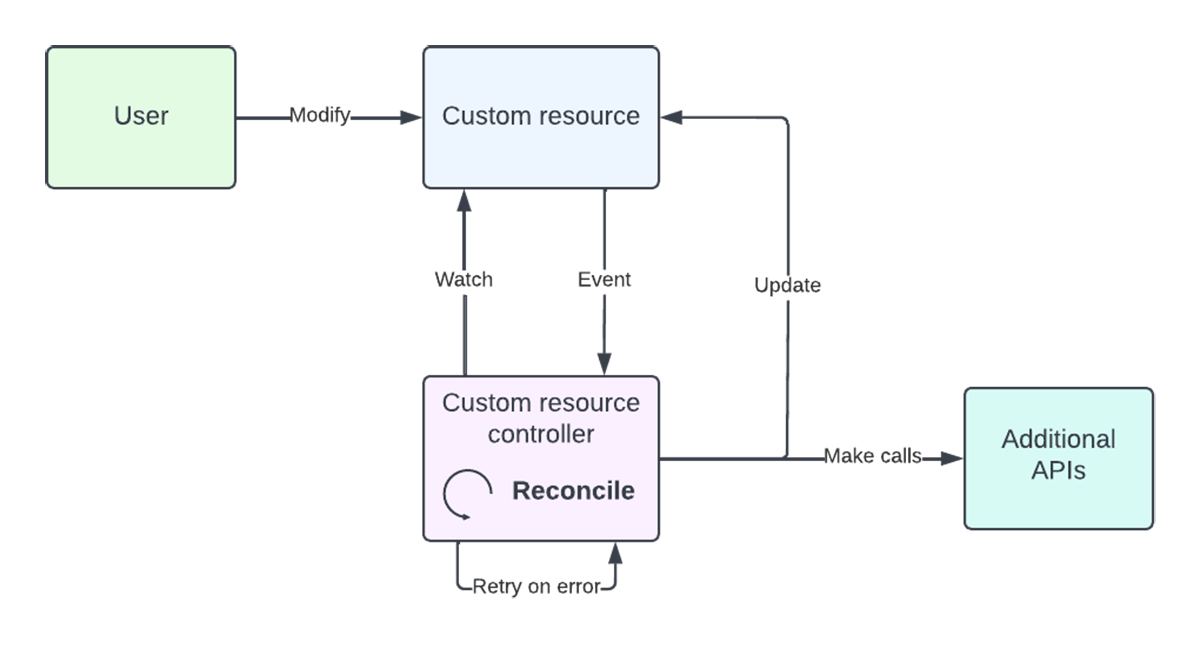
Rotating tokens with an operator
Our solution fits a declarative model: we want to specify what teams and clusters exist, and the operator should create the corresponding service account tokens. Each team has some desired state (what clusters they want to authenticate to) and current state (what clusters they can authenticate to via a token). To model this, we created a TeamFolderCluster custom resource that represents the edge between a team and a Kubernetes cluster they wish to authenticate to.
Figure 3: example of a CustomResource
Today, an existing internal service, Kubernetes Authentication Manager, creates and manages service accounts and service account tokens on target clusters, and this service is already used for just-in-time access for human users to Kubernetes clusters. When a TeamFolderCluster is reconciled, the new controller calls the Kubernetes Authentication Manager to create a new token if the previous one has expired. After creation, the controller stores the token in Vault. The controller always schedules another reconciliation when the token should be rotated, which is directly computed from the tokenCreationTime status field. Since all custom resources are reconciled at least once on controller bootup, this pattern ensures that token rotation is robust to controller crashes.
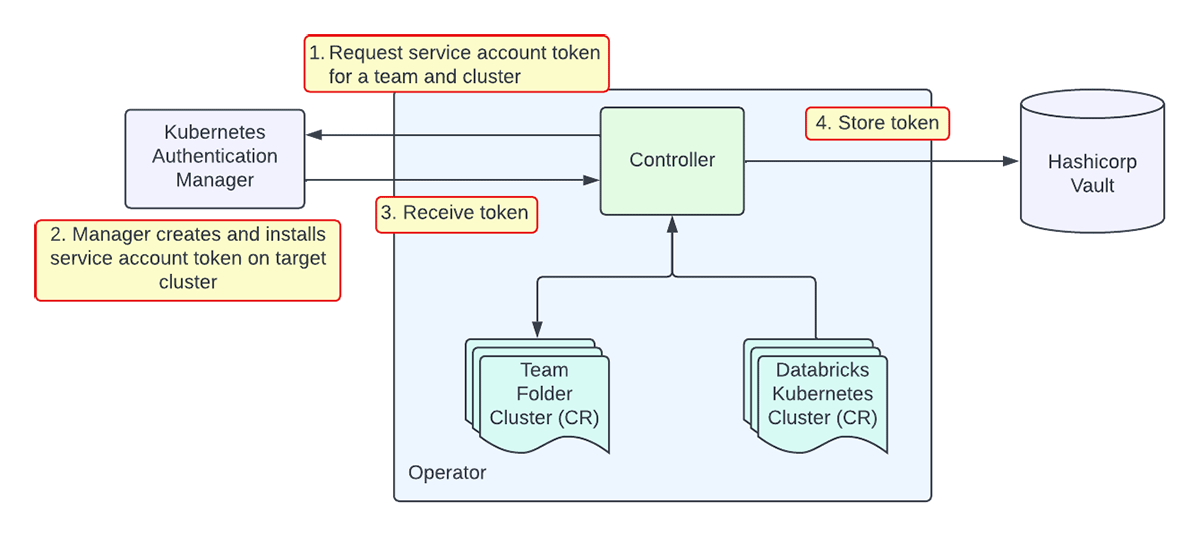
Once the token is stored in Vault, deployment jobs can simply authenticate to any cluster:
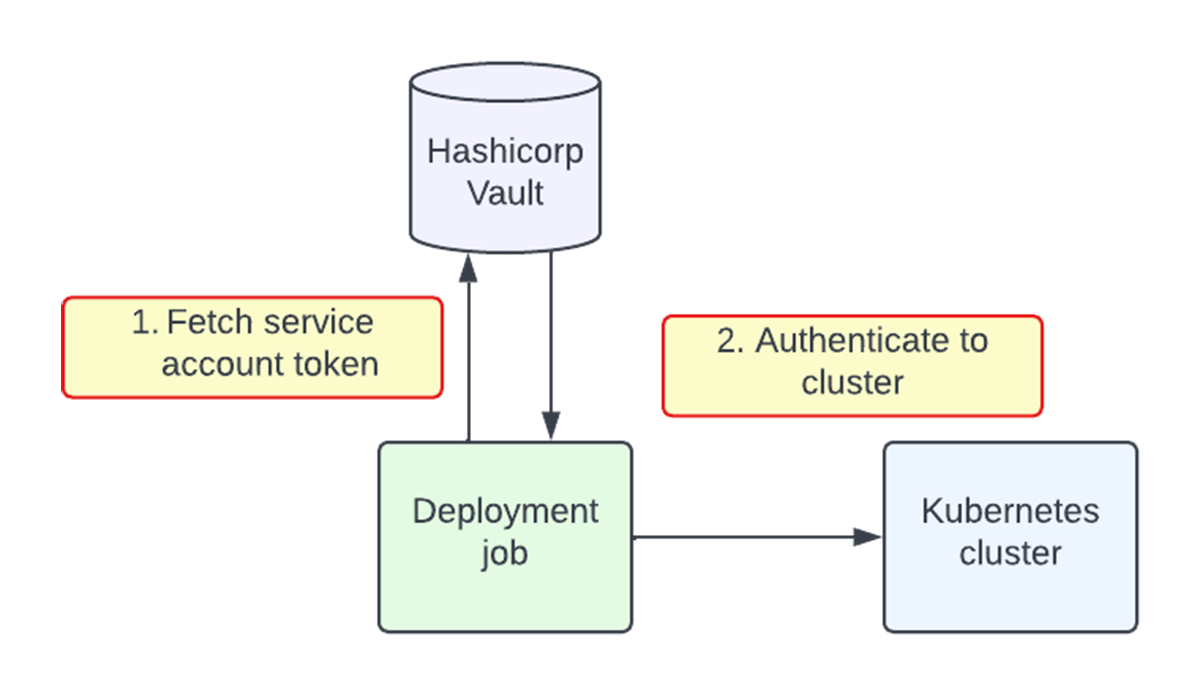
Conclusion
After we launched the operator, CI/CD deployment jobs can simply fetch service account tokens from Vault and use those tokens to deploy to Kubernetes clusters. The process to create and rotate the tokens is completely automated, even as new clusters and teams are dynamically added. In our engineering development environment alone, our service rotates thousands of tokens for hundreds of clusters on an hourly basis. Using short-lived, cloud-agnostic service account tokens improved our security, reduced complexity, and saved many engineering hours of manual setup.
I had an amazing time interning at Databricks. Diving into the details of Kubernetes, networking, and security has left me with a much deeper understanding of how to build and deploy software at scale. Having the opportunity to indepedently drive the project forward, make design tradeoffs, and collaborate with multiple teams has greatly improved my skills and confidence as a software engineer. Coworkers were friendly, passionate, and continuously gave me great feedback on ways to improve. I want to thank everyone at Databricks and the Compute Lifecycle team, and especially my mentor Austin for providing excellent support to help me grow as an engineer.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.