MLOps Best Practices - MLOps Gym: Crawl
Building the foundations for repeatable ML workflows
- MLOps is a journey, not a project, and involves practices and organizational behaviors, not just tools or technology.
- Essential tools for MLOps include MLflow, Unity Catalog, Feature Stores, and version control with Git.
- Best practices for MLOps include writing clean code, choosing the right development environment, and monitoring AI systems.
Introduction
MLOps is an ongoing journey, not a once-and-done project. It involves a set of practices and organizational behaviors, not just individual tools or a specific technology stack. The way your ML practitioners collaborate and build AI systems greatly affects the quality of your results. Every detail matters in MLOps—from how you share code and set up your infrastructure to how you explain your results. These factors shape the business's perception of your AI system's effectiveness and its willingness to trust its predictions.
The Big Book of MLOps covers high-level MLOps concepts and architecture on Databricks. To provide more practical details for implementing these concepts, we’ve introduced the MLOps Gym series. This series covers key topics essential for implementing MLOps on Databricks, offering best practices and insights for each. The series is divided into three phases: crawl, walk, and run—each phase builds on the foundation of the previous one.
“Introducing MLOps Gym: Your Practical Guide to MLOps on Databricks” outlines the three phases of the MLOps Gym series, their focus, and example content.
- “Crawl” covers building the foundations for repeatable ML workflows.
- “Walk” is focused on integrating CI/CD in your MLOps process.
- “Run” talks about elevating MLOps with rigor and quality.
In this article, we'll summarize the articles from the crawl phase and highlight the key takeaways. Even if your organization has an existing MLOps practice, this crawl series may be helpful by providing details on improving specific aspects of your MLOps.
Laying the Foundation: Tools and Frameworks
While MLOps isn't solely about tools, the frameworks you choose play a significant role in the quality of the user experience. We encourage you to provide common pieces of infrastructure to reuse across all AI projects. In this section, we share our recommendations for essential tools to establish a solid MLOps setup on Databricks.
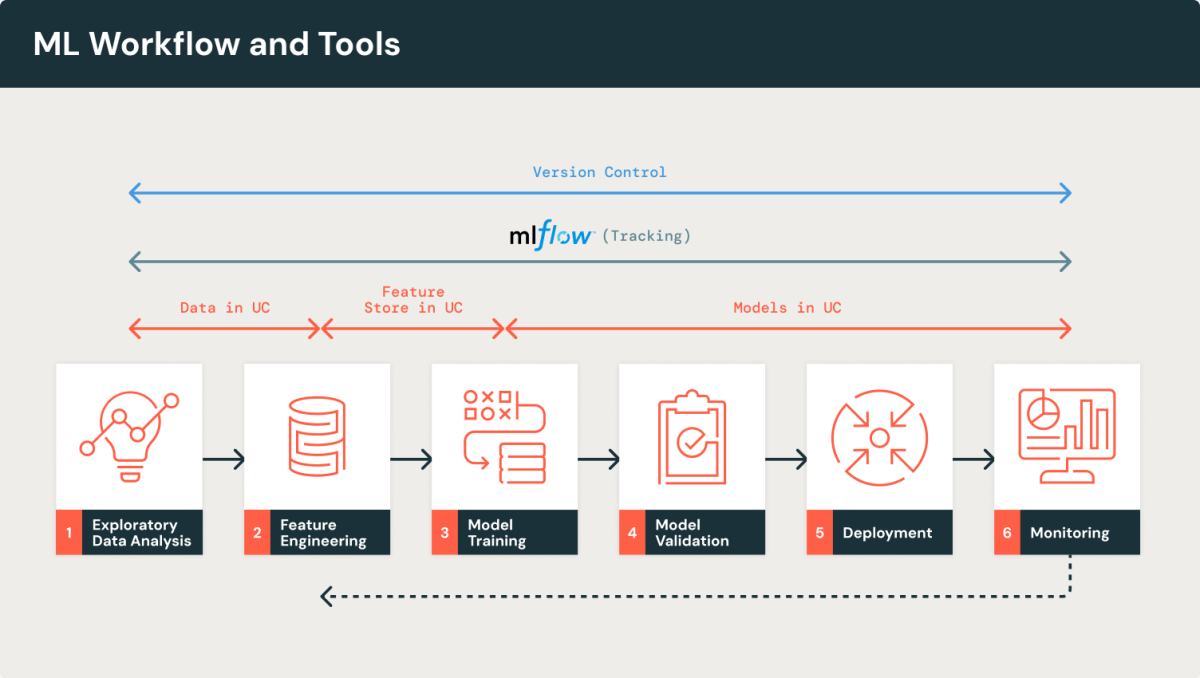
MLflow (Tracking and Models in UC)
MLflow stands out as the leading open source MLOps tool, and we strongly recommend its integration into your machine learning lifecycle. With its diverse components, MLflow significantly boosts productivity across various stages of your machine learning journey. In the Beginners Guide to MLflow, we highly recommend using MLflow Tracking for experiment tracking and the Model Registry with Unity Catalog as your model repository (aka Models in UC). We then guide you through a step-by-step journey with MLflow, tailored for novice users.
Unity Catalog
Databricks Unity Catalog is a unified data governance solution designed to manage and secure data and ML assets across the Databricks Data Intelligence Platform. Setting up Unity Catalog for MLOps offers a flexible, powerful way to manage assets across diverse organizational structures and technical environments. Unity Catalog's design supports a variety of architectures, enabling direct data access for external tools like AWS SageMaker or AzureML through the strategic use of external tables and volumes. It facilitates tailored organization of business assets that align with team structures, business contexts, and the scope of environments, offering scalable solutions for both large, highly segregated organizations and smaller entities with minimal isolation needs. Moreover, by adhering to the principle of least privilege and leveraging the BROWSE privilege, Unity Catalog ensures that access is precisely calibrated to user needs, enhancing security without sacrificing discoverability. This setup not only streamlines MLOps workflows but also fortifies them against unauthorized access, making Unity Catalog an indispensable tool in modern data and machine learning operations.
Feature Stores
A feature store is a centralized repository that streamlines the process of feature engineering in machine learning by enabling data scientists to discover, share, and reuse features across teams. It ensures consistency by using the same code for feature computation during both model training and inference. Databricks' Feature Store, integrated with Unity Catalog, offers enhanced capabilities like unified permissions, data lineage tracking, and seamless integration with model scoring and serving. It supports complex machine learning workflows, including time series and event-based use cases, by enabling point-in-time feature lookups and synchronizing with online data stores for real-time inference.
In part 1 of Databricks Feature Store article, we outline the essential steps to effectively use Databricks Feature Store for your machine learning workloads.
Version Control for MLOps
While version control was once overlooked in data science, it has become essential for teams building robust data-centric applications, particularly through tools like Git.
Getting started with version control explores the evolution of version control in data science, highlighting its critical role in fostering efficient teamwork, ensuring reproducibility, and maintaining a comprehensive audit trail of project elements like code, data, configurations, and execution environments. The article explains Git's role as the primary version control system and how it integrates with platforms such as GitHub and Azure DevOps in the Databricks environment. It also offers a practical guide for setting up and using Databricks Repos for version control, including steps for linking accounts, creating repositories, and managing code changes.
Version control best practices explores Git best practices, emphasizing the "feature branch" workflow, effective project organization, and choosing between mono-repository and multi-repository setups. By following these guidelines, data science teams can collaborate more efficiently, keep codebases clean, and optimize workflows, ultimately improving the robustness and scalability of their projects.
When to use Apache Spark™ for ML?
Apache Spark, this open source, distributed computing system designed for big data processing and analytics is not only for highly skilled distributed systems engineers. Many ML practitioners face challenges such as out-of-memory error with Pandas which can easily be solved by Spark. In Harnessing the power of Apache Spark™ in data science/machine learning workflows, we've explored how data scientists can harness Apache Spark to build efficient data science and machine learning workflows, highlighted scenarios where Spark excels—such as processing large datasets, performing resource-intensive computations, and handling high-throughput applications—and discussed parallelization strategies like model and data parallelism, providing practical examples and patterns for their implementation.
Building Good Habits: Best Practices in Code and Development
Now that you've become acquainted with the essential tools needed to establish your MLOps practice, it's time to explore some best practices. In this section, we'll discuss key topics to consider as you enhance your MLOps capabilities.
Writing Clean Code for Sustainable Projects
Many of us begin by experimenting in our notebooks, jotting down ideas or copying code to test their feasibility. At this early stage, code quality often takes a backseat, leading to redundant, unnecessary, or inefficient code that wouldn’t scale well in a production environment. The guide 13 Essential Tips for Writing Clean Code offers practical advice on how to refine your exploratory code and prepare it to run independently and as a scheduled job. This is a crucial step in transitioning from ad-hoc tasks to automated processes.
Choosing the Right Development Environment
When setting up your ML development environment, you'll face several important decisions. What type of cluster is best suited for your projects? How large should your cluster be? Should you stick with notebooks, or is it time to switch to an IDE for a more professional approach? In this section, we'll discuss these common choices and offer our recommendations to help you make the best decisions for your needs.
Cluster Configuration
Serverless compute is the best way to run workloads on Databricks. It is fast, simple and reliable. In scenarios where serverless compute is not available for a myriad of reasons, you can fall back on classic compute.
Beginners Guide to Cluster Configuration for MLOps covers essential topics such as selecting the right type of compute cluster, creating and managing clusters, setting policies, determining appropriate cluster sizes, and choosing the optimal runtime environment.
We recommend using interactive clusters for development purposes and job clusters for automated tasks to help control costs. The article also emphasizes the importance of selecting the appropriate access mode—whether for single-user or shared clusters—and explains how cluster policies can effectively manage resources and expenses. Additionally, we guide you through sizing clusters based on CPU, disk, and memory requirements and discuss the critical factors in selecting the appropriate Databricks Runtime. This includes understanding the differences between Standard and ML runtimes and ensuring you stay up to date with the latest versions.
IDE vs Notebooks
In IDEs vs. Notebooks for Machine Learning Development, we dive into why that the choice between IDEs and notebooks depends on individual preferences, workflow, collaboration requirements, and project needs. Many practitioners use a combination of both, leveraging the strengths of each tool for different stages of their work. IDEs are preferred for ML engineering projects, while notebooks are popular in the data science and ML community.
Operational Excellence: Monitoring
Building trust in the quality of predictions made by AI systems is crucial even early in your MLOps journey. Monitoring your AI systems is the first step in building such trust.
All software systems, including AI, are vulnerable to failures caused by infrastructure issues, external dependencies, and human errors. AI systems also face unique challenges, such as changes in data distribution that can impact performance.
Beginners Guide to Monitoring emphasizes the importance of continuous monitoring to identify and respond to these changes. Databricks' Lakehouse Monitoring helps track data quality and ML model performance by monitoring statistical properties and data variations. Effective monitoring includes setting up monitors, reviewing metrics, visualizing data through dashboards, and creating alerts.
When problems are detected, a human-in-the-loop approach is recommended for retraining models.
Call to Action
If you are in the early stages of your MLOps journey, or you are new to Databricks and looking to build your MLOps practice from the ground up, here are the core lessons from MLOps Gym’s Crawl phase:
- Provide common pieces of infrastructure reusable by all AI projects. MLflow provides standardized tracking of AI development across all of your projects, and for managing models, the MLflow Model Registry with Unity Catalog (Models in UC) is our top choice. The Feature Store addresses training/inference skew and ensures easy lineage tracking across the Databricks Lakehouse platform. Additionally, always use Git to back up your code and collaborate with your team. If you need to distribute your ML workloads, Apache Spark is also available to support your efforts.
- Implement best practices from the start by following our tips for writing clean, scalable code and selecting the right configurations for your specific ML workload. Understand when to use notebooks and when to leverage IDEs for the most effective development.
- Build trust in your AI systems by actively monitoring your data and models. Demonstrating your ability to evaluate the performance of your AI system will help convince business users to trust the predictions it generates.
By following our recommendations in the Crawl phase, you will have transitioned from ad-hoc ML workflows to reproducible, reliable jobs, eliminating manual and error-prone processes. In the next phase of the MLOps Gym series — Walk — we will guide you on integrating CI/CD and DevOps best practices into your MLOps setup. This will enable you to manage fully developed ML projects that are thoroughly tested and automated using a DevOps tool rather than just individual ML jobs.
We regularly publish MLOps Gym articles on the Databricks Community blog. To provide feedback or questions on the MLOps Gym content email us at mlopsgym@databricks.com.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.