Model Risk Management, a true accelerator to corporate AI


Special thanks to EY's Mario Schlener, Wissem Bouraoui and Tarek Elguebaly for their support throughout this journey and their contributions to this blog and solution accelerator.
Model Risk Management (MRM) – rare are three-letter acronyms that can bring such a level of anxiety to many model developers and data scientists in the financial services industry. MRM is the discipline upon which governance and compliance teams will carefully identify and mitigate the adverse consequences caused by incorrect or misused models. Not limited to artificial intelligence (AI) or machine learning (ML) models, AI/ML models represent a small fraction of models under management in banking; its purview easily extends to end user computing applications, complex statistical packages, or rules-based processes.
But if the Fourth Industrial Revolution brought with it a range of exciting new technological and analytical breakthroughs, past AI experiments (e.g., Twitter chatbot Tay) and corporate scandals (e.g., Cambridge Analytica) have also raised additional awareness around the danger of AI, its lack of explainability, as well as new risk factors (such as ethics, fairness) that organizations must now take into account. As new models, such as ChatGPT and generative AI, are sparking many conversations in the financial services industry, AI/ML will increasingly require tighter linkage with data governance and other risk management frameworks, such as privacy, information security and third-party risk management.
Compliance officers — dark knights of AI
Regardless of their complexity, every model in banking or insurance is thoroughly reviewed by an independent team of experts whose sole responsibilities are to identify shortcomings in a modeling approach. For a newer generation of technologists well versed in a world of AI, this process is oftentimes considered counterproductive, outdated and somewhat patronizing—not many practitioners like their skills to be challenged. This could not be farther from the truth.
Independent validation units (IVUs) would not simply identify shortcomings in a modeling strategy but would verify that risks were identified from the get-go and that necessary steps were taken throughout the entire model development lifecycle to mitigate adverse consequences. If risks cannot be mitigated, they need to be at the very least understood, articulated and quantified. After all, managing risks is a primary function of every financial services institution (FSI).
By enforcing strict development standards, defining corporate guidelines and confirming regulatory compliance of every model, oftentimes at the expense of their own popularity, compliance officers and model validators have become the dark knights of corporate AI—preserving the integrity of the financial ecosystem and enhancing model efficacy (model is fit for purpose), while reducing their associated risks for the firm and/or their customers, resulting in shortened time to market for analytical projects.
Model explainability vs. model transparency
ML models are often "black boxes" that make their interpretation difficult. To the question of model explainability often comes a simple answer: Shapley Additive Explanations, commonly known as SHAP values. This method is overused by practitioners to increase interpretability of ML models. But if it nicely exhibits the influence (positive or negative) of a given feature to the outcome of a model, it does not evaluate the quality of the prediction itself, forcing compliance teams to privilege simpler approaches, such as generalized linear models (GLMs), over techniques such as XGBoost for critical decisioning processes, such as credit underwriting. This is where the status quo ends.
If this technique can be used to bring some level of transparency to more complex models trained over a hundred or a thousand parameters, how would this apply to a newer generation of AI trained over a billion parameters? Dolly, our new open-source initiative that aims at democratizing generative AI for commercial use, was trained over six billion parameters! But, most importantly, even the most explainable technique, such as linear regression, would still be considered black box if one did not capture the data this model was trained against or does not know the current version running in production.
This is where documentation and development guidelines supersede AI explainability. The model risk guidance from around the world very highly emphasizes the need for effective documentation throughout the model life cycle, from inception to decommission.
SR 11-7 Model Risk Management from U.S. Federal Reserve Board:
[...] Documentation is a necessary ingredient in the model development process. It ensures that other parties can understand the model, implement it and construct suitable benchmarks for comparison.
E-23 OSFI for Canada:
[...] Model owners should be responsible for maintaining thorough documentation – that is easily accessible to all model stakeholders – at each stage of a model's life cycle.
We believe that explainability of a model lies in its developmental history and conceptual soundness more than the understanding of each of its input parameters. A model, in its lifecycle, goes through many tasks, each involving data, metrics, assumptions, tools, frameworks and decisions executed by model stakeholders. One needs to connect data, infrastructure, processes, code and models together to bring the necessary transparency to AI. This simplicity is the promise of the Databricks Lakehouse.
Better together
We understand the critical importance of effective model risk management in the financial services industry. That's why we are excited to introduce our Databricks and EY Model Risk Management Accelerator for AI explainability which offers complete model auditability, removing the guesswork from compliance. Our accelerator will empower end-users to achieve transparency and interpretability in their models as data expands and modeling techniques evolve. With the goal of satisfying the inputs required for AI governance, the solution advocates for a consistent and streamlined approach to documenting models and addressing changes, both regulatory and business related, in an optimized timeline.
This accelerator provides financial services firms with an automatically generated model documentation solution that leverages reusable notebooks complying to regulatory standards. This solution also plugs into a full suite of offerings, including data visualization and configurable dashboard reporting, allowing teams to leverage automated and centralized tools, labs, and libraries built on a unified analytics architecture. By doing so, it streamlines the management and governance of the model lifecycle activities.
The benefits for financial services firms to leverage our MRM accelerator include:
- Enhanced visualizations and reporting capabilities, allowing financial services firms to make informed decisions and better understand their risk exposures.
- Automated controls for model development, validation, and implementation, as well as issues management, improving overall efficiency.
- Real-time risk reporting and analytics across the inventory, providing an overall health check at the product/portfolio level so you can proactively monitor and mitigate risks, reducing the potential for any negative impact on the business.
Data intelligence reshapes industries

Unified governance with Databricks Lakehouse
Databricks Lakehouse is a modern cloud data architecture that combines the reliability and performance of data warehousing systems with the economics, scale and flexibility offered by data lake capabilities. Adopted by more than 1,000 FSIs, this pattern helps banks, insurers and asset managers unlock value from their data across a variety of use cases of different materialities, from risk management to marketing analytics.
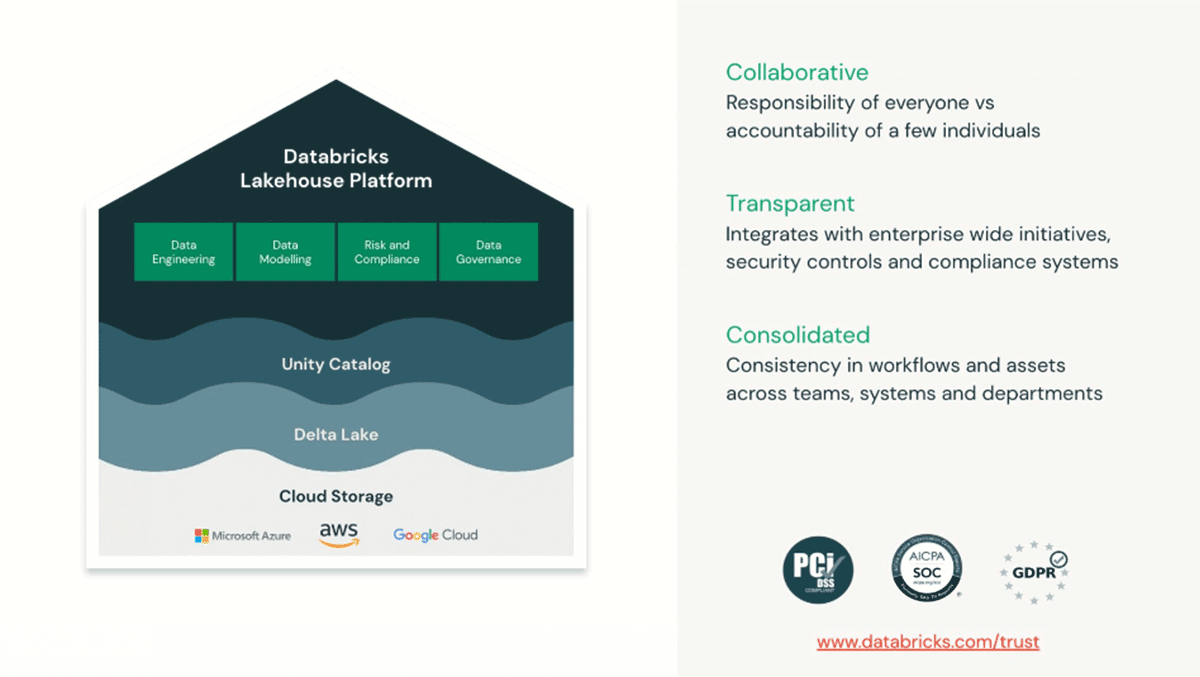
Built on open-source standards, the promise of a lakehouse architecture is to simplify all unnecessary steps and different technologies used throughout the entire value chain of data, from its ingestion, to value creation.
Delta Lake is the storage layer that provides the foundation for storing data and tables in the Databricks Lakehouse Platform. Each operation that modifies a Delta Lake table creates a new table version. One can use history information to audit operations or query a table at a specific point in time (also known as time travel).
MLFlow tracks all the ML and non-ML experiments, automatically logging model parameters, metrics, libraries, dependencies and different versions, but equally capturing "as-of code" (e.g., an associated notebook at the time of the experiment) and "as-of data."
With a simplified architecture comes a simplified governance model. Unity Catalog becomes the single pane of glass capable of tracking upstream and downstream use of data and enforcing access policies accordingly (model owner, data owner, etc.). In the example below, we represent a complex workflow used for credit decisioning, linking data used for transformation, model training and model evaluation all in the same directed acyclic graph (DAG).
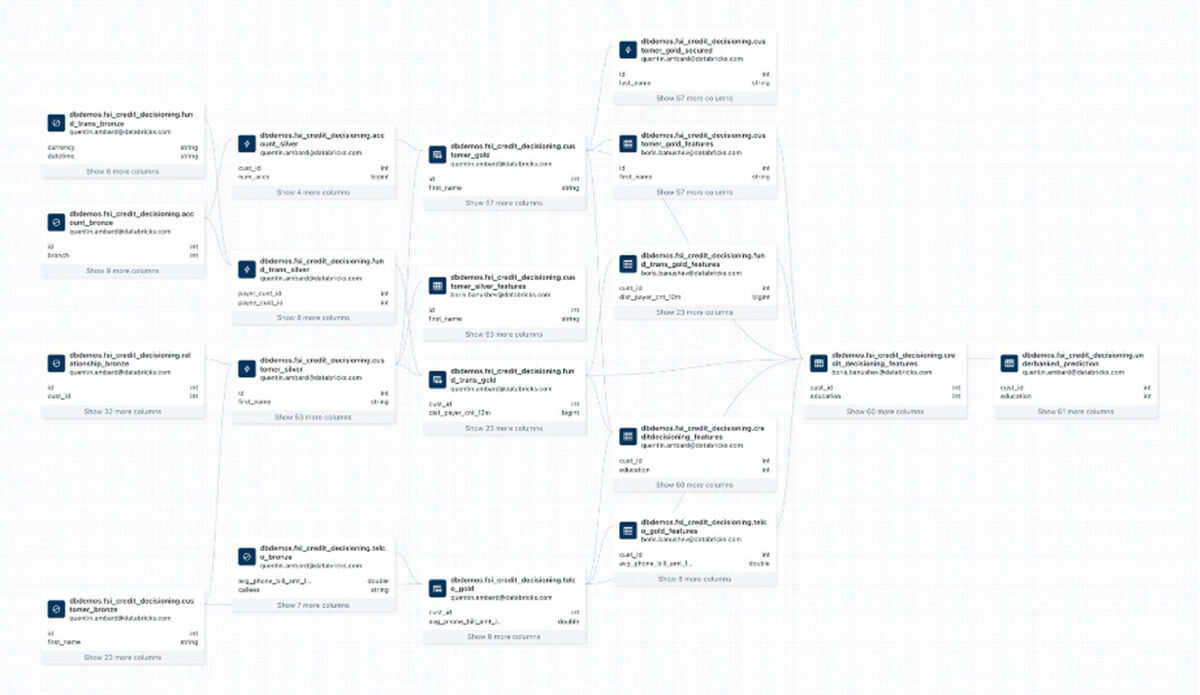
By programmatically bringing together data, infrastructure dependencies, the model and associated experiments, Unity Catalog provides the robust foundtation required to operate and reproduce a model. However, technology itself would not solve for the rigorous documentation required to meet the "consistency" and "completeness" check by the second and third lines of defense.
Model documentation
In efforts to standardize, simplify the process and bring consistency, compliance and model governance teams, typically run by a centralized group, often publish standard templates covering generic elements for model developer documentation. While a template is largely applicable across many use cases, it often is adjusted by each different business area to fit their needs. This sometimes results in inconsistencies and can lead to larger validation times.
- The process requires pulling data from multiple systems, which can involve going back in time to review handwritten notes for experiment tracking.
- Developers prefer to focus on modeling activities rather than mundane copy-paste and formatting tasks.
- Inconsistency in the structure followed by different model groups can cause difficulties in maintaining standards.
- Variations for different model groups and types make it harder to keep up with standards.
- Demanding business requirements and timelines can impose time constraints on quality documentation.
- It is difficult for the model governance and policy team to roll out updates and standards due to the variety of model groups and fast-changing model and regulatory landscapes.
But the fundamental issue is not about the model documentation itself, but rather how this documentation is being delivered and enforced. As a separate activity from the model development process, usually handled after the fact (i.e., after a model is built), this process will cause a lot of manual effort, administrative overhead and unnecessary back-and-forth communication between model developers and validation teams, resulting in long delivery timelines and impacting model efficacy to a point where the model may no longer be fit for purpose (e.g., customer behavior may have changed).
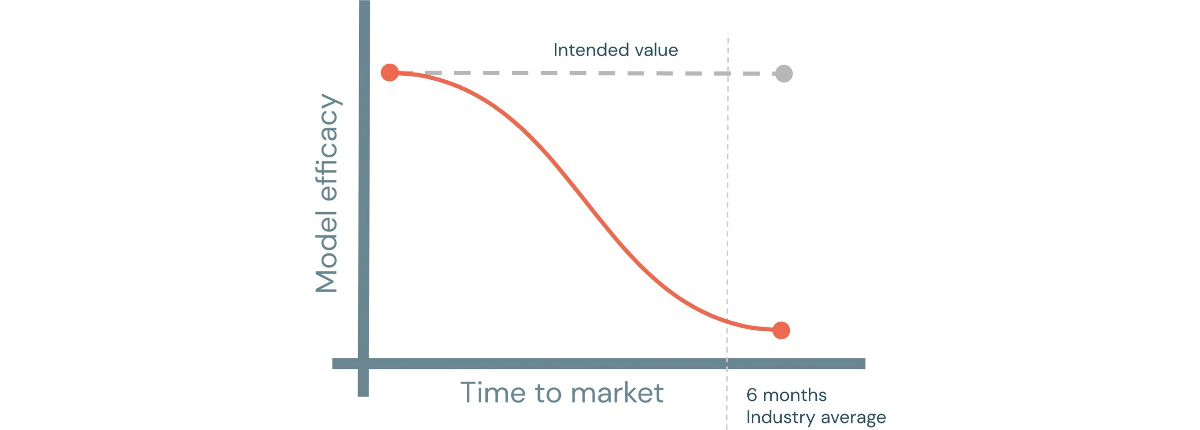
But this dynamic can be shifted when documentation is no longer enforced as a separate activity but rather embedded in the development process of a model through template notebooks and markdown commentary, guiding a developer through a series of steps prior to model validation. Most of the questions required by the IVU process could be addressed upfront (at the model development phase) to increase the model validation success rate and dramatically reduce time from exploration to production of analytical use cases.
Solution accelerator for model documentation
Codeveloped by the EY organization and Databricks, our new solution accelerator for MRM automatically generates a document by extracting details of several model artifacts. It is a template-driven framework built atop the Databricks Lakehouse architecture, which makes it easy to extract all necessary artifacts for model documentation.
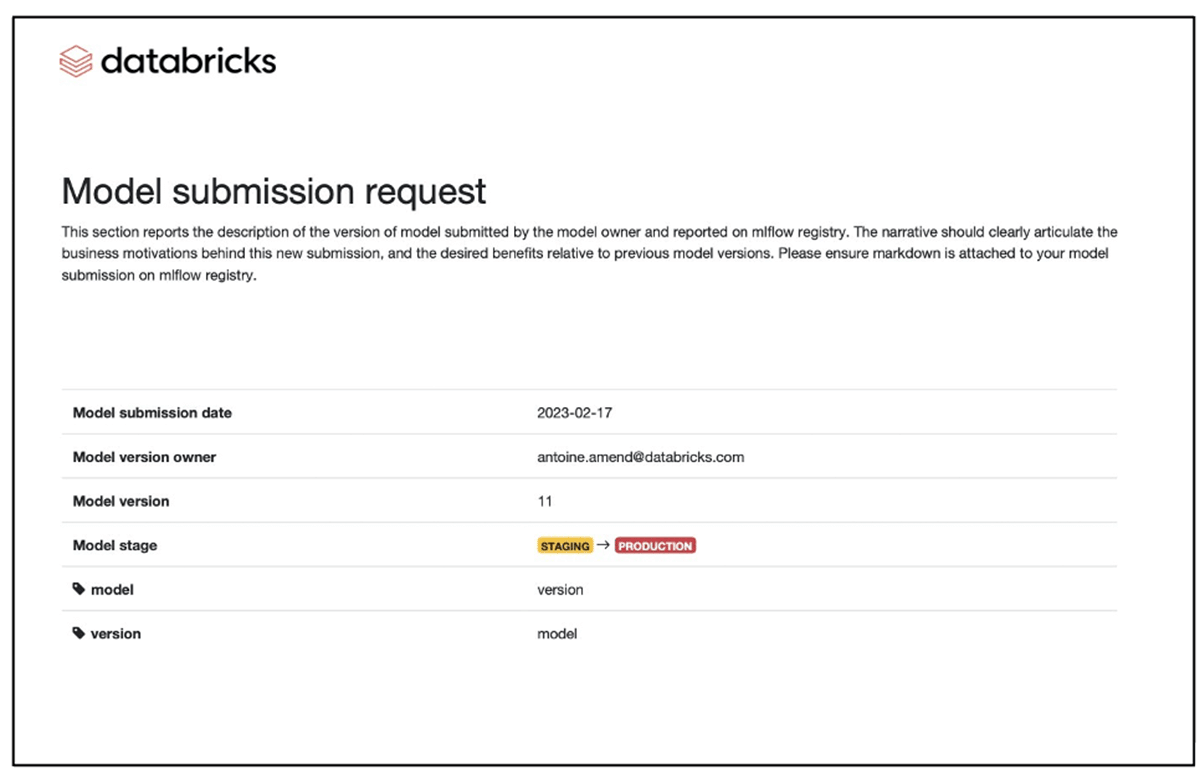
The template is a Databricks notebook-based tool with a predefined structure and placeholders for model developers' subject matter. Since it is a notebook with placeholders that support markdown text, latex equations, code and graphics, it makes it easy to extend the model development placemat into a model document or vice versa.

Not only does it meet the needs of model artifacts, the solution extends the effectiveness of model documentation by extracting data governance and lineage, making it a complete tool for reporting model artifacts.
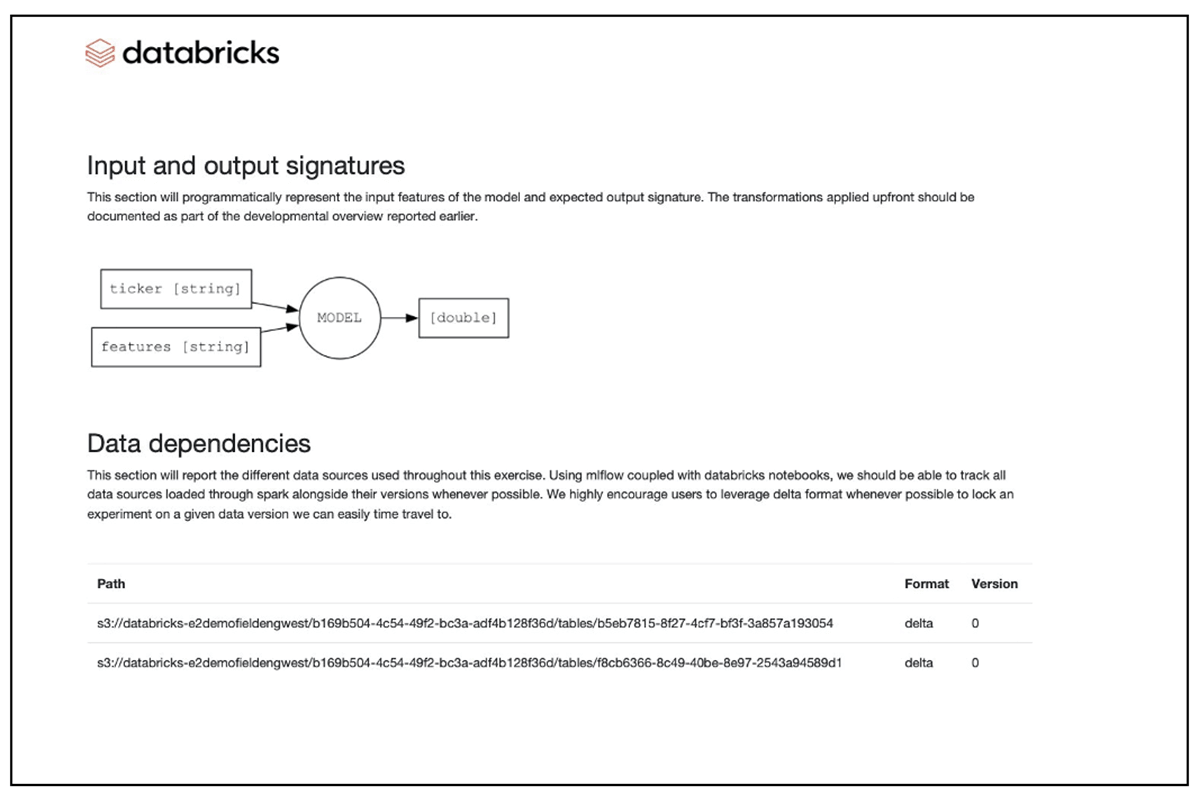
This utility library provides a technical foundation and framework to automatically generate the document. This represents one side of the coin. The other side relates to the design, structure and content of the document that pertains to the model in scope. With subject-matter knowledge supporting several model frameworks, regulator guidelines and the custom needs of many FSIs, the EY MRM suite provides proven model documentation templates corresponding to business domains in the financial services industry.
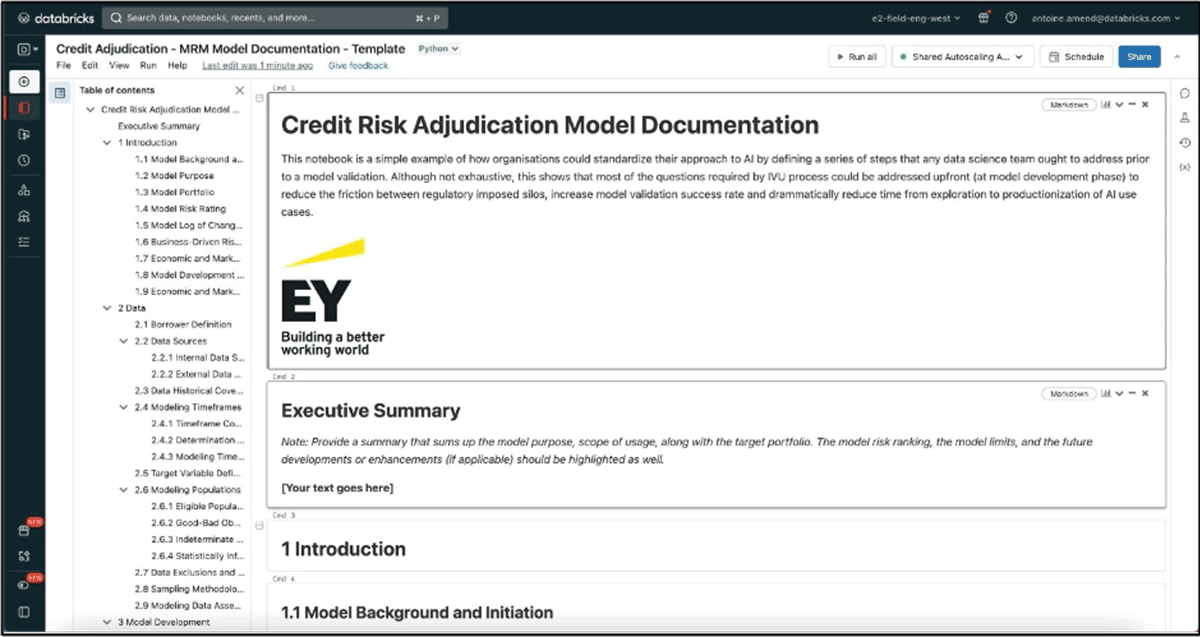
Available through reusable notebooks, these templates become documentation add-ons built atop of the same generic and reusable framework that can bring consistency in a company's model development strategy — a true accelerator to corporate AI. By adopting a similar approach, we have seen regulated organizations reduce their model delivery lifecycle from 12 months to a few weeks.
Check out our new solution accelerator and reach out to your Databricks or EY representative for more information about lakehouse for model risk management.
The views reflected in this article are the views of the authors and do not necessarily reflect the views of Ernst & Young LLP or other members of the global EY organization.