Optimizing AWS S3 Access for Databricks
by Al Thrussell and JD Braun
Databricks, an open cloud-native lakehouse platform is designed to simplify data, analytics and AI by combining the best features of a data warehouse and data lakes making it easier for data teams to deliver on their data and AI use cases.
With the intent to build data and AI applications, Databricks consists of two core components: the Control Plane and the Data Plane. The control plane is fully managed by Databricks and consists of the Web UI, Notebooks, Jobs & Queries and the Cluster Manager. The Dataplane resides in your AWS Account and is where Databricks Clusters run to process data.
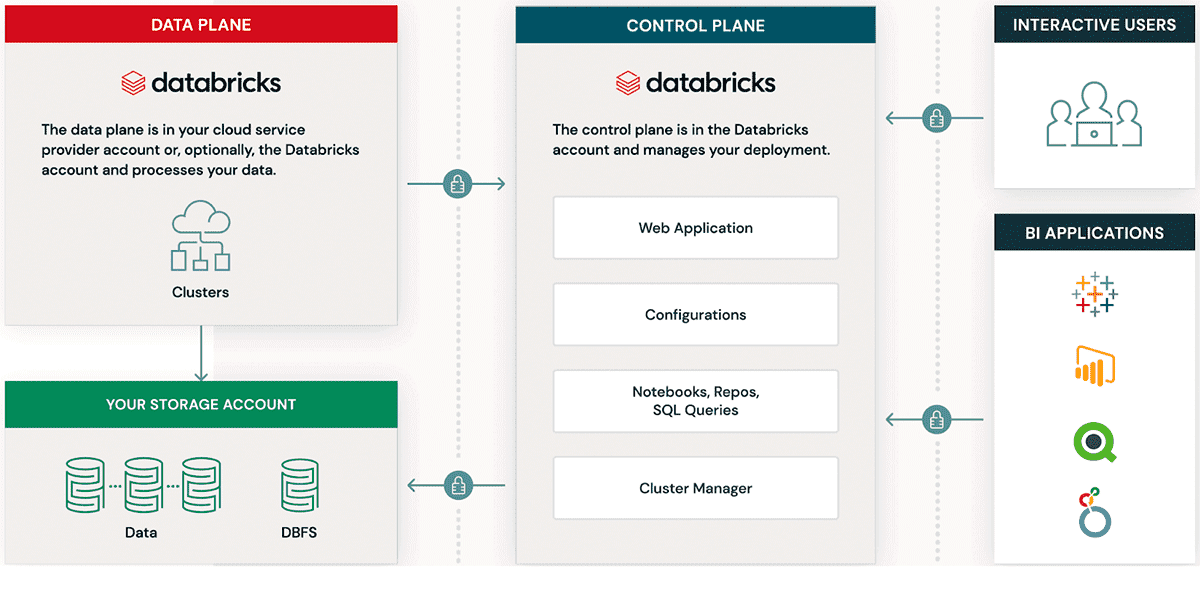
Overview:
If you're familiar with a Lakehouse architecture, it's safe to assume you're familiar with cloud object stores. Cloud object stores are a key component in the Lakehouse architecture, because they allow you to store data of any variety typically cheaper than other cloud databases or on-premises alternatives. This blog post will focus on reading and writing to one cloud object store in particular - Amazon Simple Storage (S3). Similarly this approach can be applied to Azure Databricks to Azure Data Lake Storage (ADLS) and Databricks on Google Cloud to Google Cloud Storage (GCS).
Since Amazon Web Services (AWS) offers many ways to design a virtual private cloud (VPC) there are many potential paths a Databricks cluster can take to access your S3 bucket.
In this blog, we will discuss some of the most common S3 networking access architectures and how to optimize them to cut your AWS cloud costs. After you've deployed Databricks into your own Customer Managed VPC, we want to make it as cheap and simple as possible to access your data where it already lives.
Below are the five scenarios that we'll be covering:
- Single NAT Gateway in a Single Availability Zone (AZ)
- Multiple NAT Gateways for High Availability
- S3 Gateway Endpoint
- Cross Region: NAT Gateway and S3 Gateway Endpoint
- Cross Region: S3 Interface Endpoint
Note: Before we walk through the scenarios, we'd like to set the stage on costs and the example Databricks workspace architecture:
- We will walk through the potential costs that may occur in estimates. These costs are in USD and modeled in AWS region North Virginia (us-east-1), these are not guaranteed cloud costs in your AWS environment.
- You can assume that the Databricks workspace is deployed across two availability zones (AZs). While you can deploy Databricks workspaces across every availability zone in the region, we are simplifying the deployment for the purpose of the article.
Single NAT gateway in one availability zone (AZ):
The architecture we see most often is Databricks using two availability zones for clusters but a single NAT Gateway and no S3 Gateway Endpoints. So what's wrong with this? It does work, but. with this architecture, there are a couple of issues.
- A single AZ is a point of failure. We design systems across AZs to offer fault tolerance should an AZ experience issues. If AWS had a problem with AZ1, your Databricks deployment would be jeopardized if there was only one NAT Gateway in AZ1, despite the cluster being in AZ2.
- With only one NAT Gateway in AZ1 traffic from AZ2 Clusters will incur cross AZ data charges. Currently charged at a list price of $0.01 per GB in each direction.
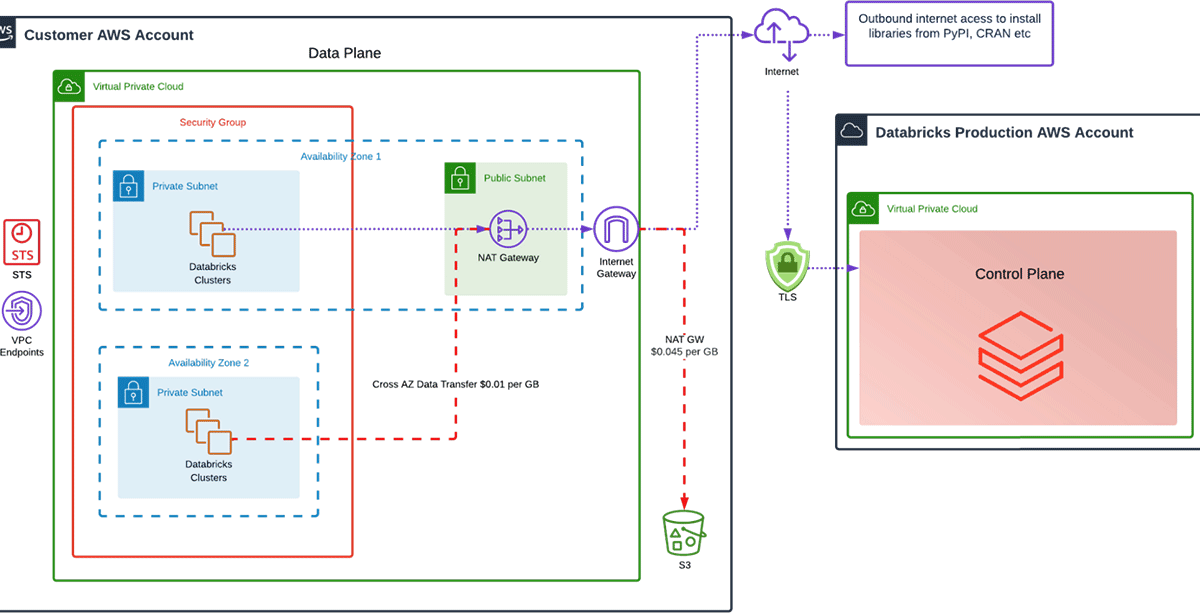
What does this architecture cost in Data Transfer Charges?
Clusters in AZ1 will route traffic to the NAT gateway in AZ1, out the Internet Gateway and hit the public S3 endpoint. Clusters in AZ2 will have to send traffic across AZs, from AZ2 to the NAT Gateway in AZ1, out the Internet Gateway and hit the Public S3 endpoint. Therefore AZ2 is incurring more data transfer costs than AZ1.
Example Scenario: 10TB processed per month, 5TB per Availability Zone
- AZ1 Costs :
- 5120GB via NAT GW = $0.045 per GB * 5120 = $230.40
- $0.045 per Hour for NAT Gateway * 730 hours in a Month = $32.85
- AZ2 Costs :
- 5120GB via NAT GW = $0.045 per GB * 5120 = $230.40
- 5120GB Cross AZ = $0.01 per GB * 5120 = $51.20
- TOTAL: $ 544.85
In the AWS Cost Explorer, you will see high costs for NATGateway-Bytes and Data Transfer-Regional-Bytes (cross AZ data charges)
Two NAT gateways in two availability zones:
Now, can we make this more cost-effective by running a second NAT Gateway and improving our availability?
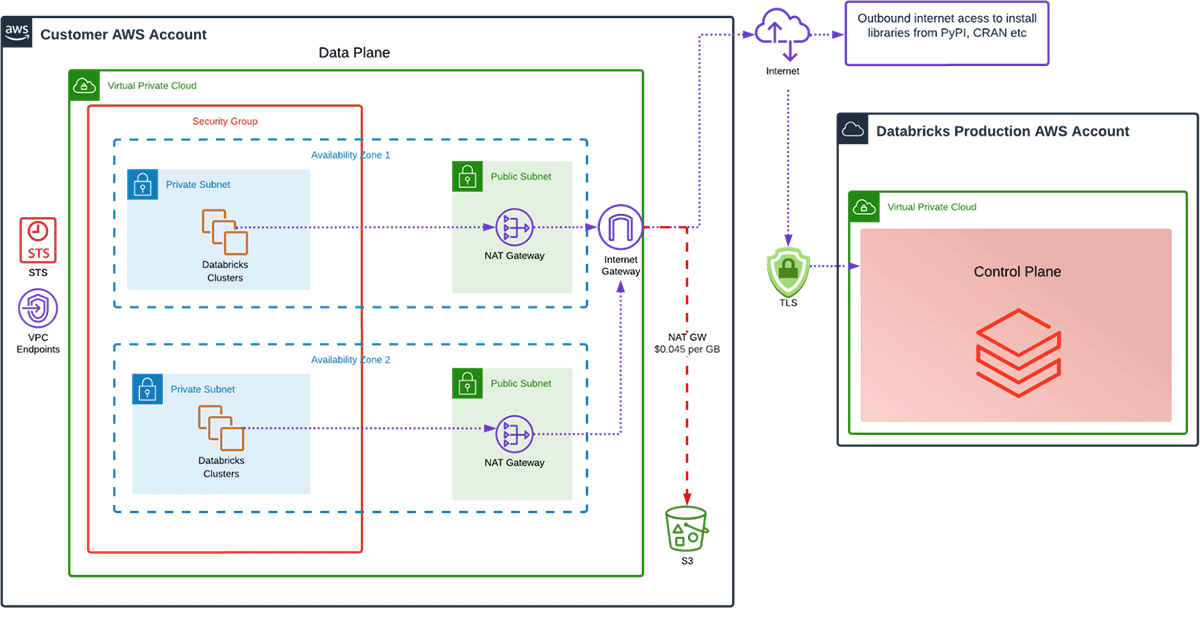
Example Scenario: 10TB processed per month, 5TB per Availability Zone
- AZ1 Costs:
- 5120GB via NAT GW = $0.045 per GB * 5120 = $230.40
- $0.045 per Hour for NAT Gateway - 730 hours in a Month = $32.85
- AZ2 Costs:
- 5120GB via NAT GW = $0.045 per GB * 5120 = $230.40
- $0.045 per Hour for NAT Gateway * 730 hours in a Month = $32.85
- TOTAL: $526.50 (3.5% Saving = $18.35 per month)
Therefore, adding an extra NAT increases availability for our architecture and should cut costs. However, 3.5% isn't much to brag about, is it? Is there any way we can do better?
S3 gateway endpoint:
Enter the S3 Gateway Endpoint. It's a common architectural pattern that customers want to access S3 in the most secure way possible, and not traverse over a NAT Gateway and Internet Gateway.
Because of this common architecture pattern, AWS released the S3 Gateway Endpoint. It is a Regional VPC Endpoint Service and needs to be created in the same region as your S3 buckets.
As you can see in the diagram below any S3 requests for buckets in the same region will route via the S3 Gateway Endpoint and will completely bypass the NAT gateways. The best part is there are no charges for the endpoint or any data transferred through it.
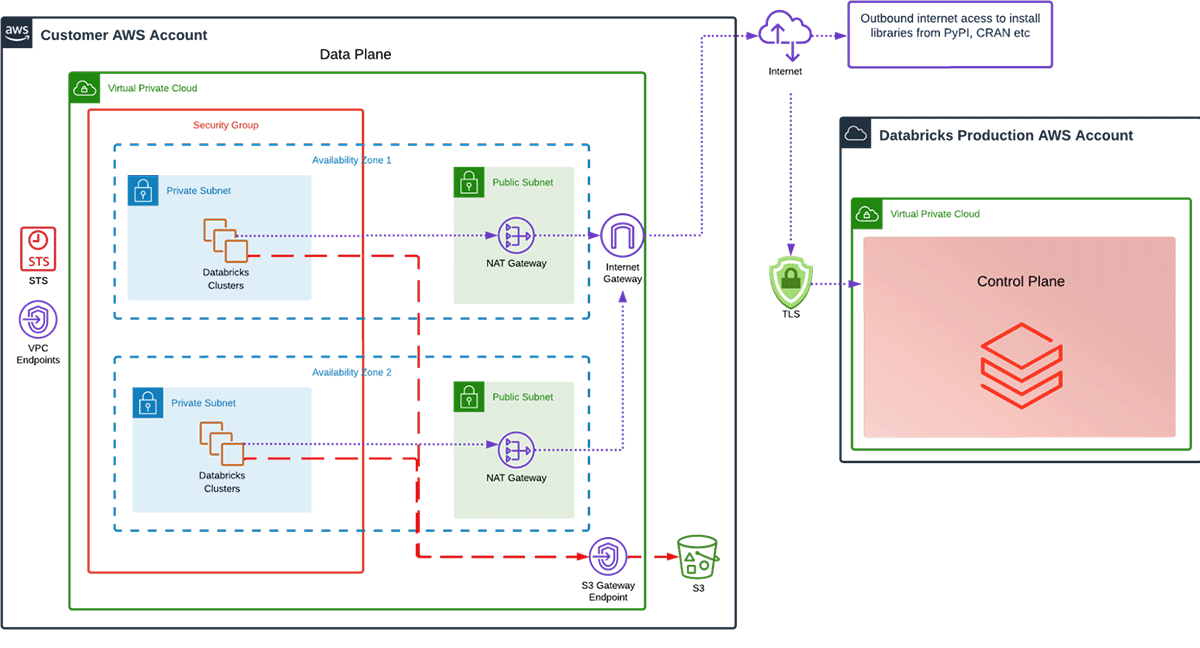
Instead of using a NAT Gateway and Internet Gateway to access our data in S3, what do the estimated costs look like when using an S3 Gateway endpoint?
Example Scenario: 10TB processed per month, 5TB per Availability Zone
- AZ1 Costs:
- 5120GB via S3 Gateway Endpoint Free = $0
- $0.045 per Hour for NAT Gateway - 730 hours in a Month = $32.85
- AZ2 Costs:
- 5120GB via S3 Gateway Endpoint Free = $0
- $0.045 per Hour for NAT Gateway - 730 hours in a Month = $32.85
- TOTAL: $ 65.70 (87.5% Saving = $460.80 per month)
87.5% SAVING, NATs what I'm talking about!
So if you see high NATGateway-Bytes or DataTransfer-Regional-Bytes you could benefit from an S3 Gateway Endpoint. Set your S3 Gateway Endpoint today and let's reduce that data transfer bill!
Cross region - S3 gateway endpoint and NAT:
As we mentioned before, an S3 Gateway Endpoint works when data is in the same region, but what if I have data in multiple regions, what can I do about that?
Performance and costs are best optimized if your user data and the Databricks' Data Plane can coexist in the same region. However, this isn't always possible. So, if we have a bucket in a different region, how will traffic flow?
In the diagram below, we have the Databricks' Data Plane in us-east-1, but we also have data in a S3 bucket in us-west-2. If we did nothing to our VPC architecture all traffic destined for the us-west-2 bucket will have to traverse the NAT Gateway.
Remember S3 Gateway endpoints are regional!
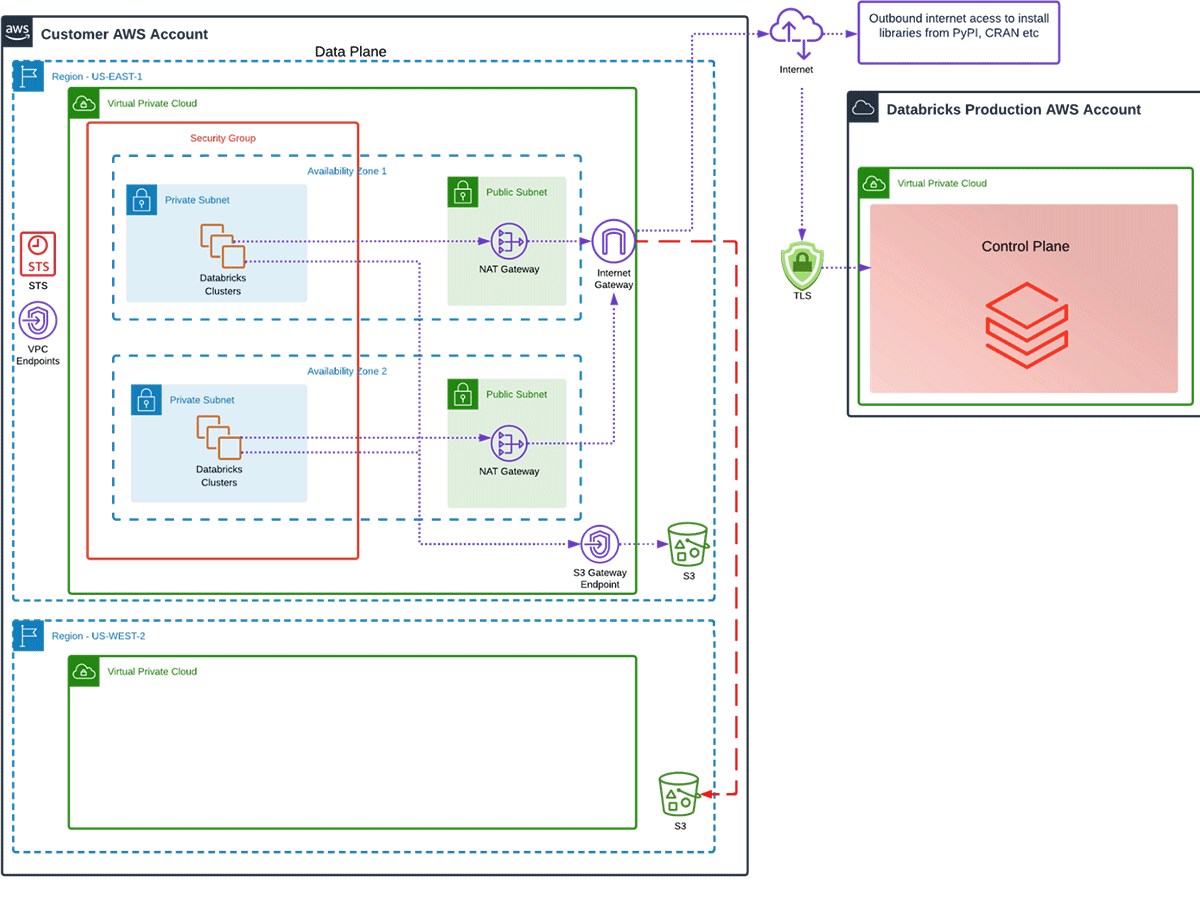
What does our cost look like in a situation with cross region traffic?
Example Scenario: 10TB Cross-Region
- 10TB Via NAT GW = 10TB (10 240GB) * $0.045 per GB = $460.80
- Cross-Region Data Transfer = 10TB (10 240GB) * $0.02 per GB = $204.80
- TOTAL: $ 665.60
Cross region - S3 interface endpoint:
Up until October 2021, it was not a simple task to connect to S3 in a different region and not use a public endpoint through a NAT Gateway, as shown above.
However,AWS took their PrivateLink service and soon released S3 Interface Endpoints. This allowed administrators to use existing private networks for inter-region connectivity while still enforcing VPC, bucket, account, and organizational access policies. This means I can peer to VPC's in different regions and route S3 traffic directly to the Interface Endpoint.
To enable the architecture as shown in the diagram below we need a few things
- VPC Peering between the two regions you wish to connect. (We could use AWS Transit Gateway but since the point of this blog is lowest cost architecture we'll go with VPC Peering)
- S3 Interface Endpoint in the remote region
- DNS changes to route S3 requests to the S3 Interface Endpoint
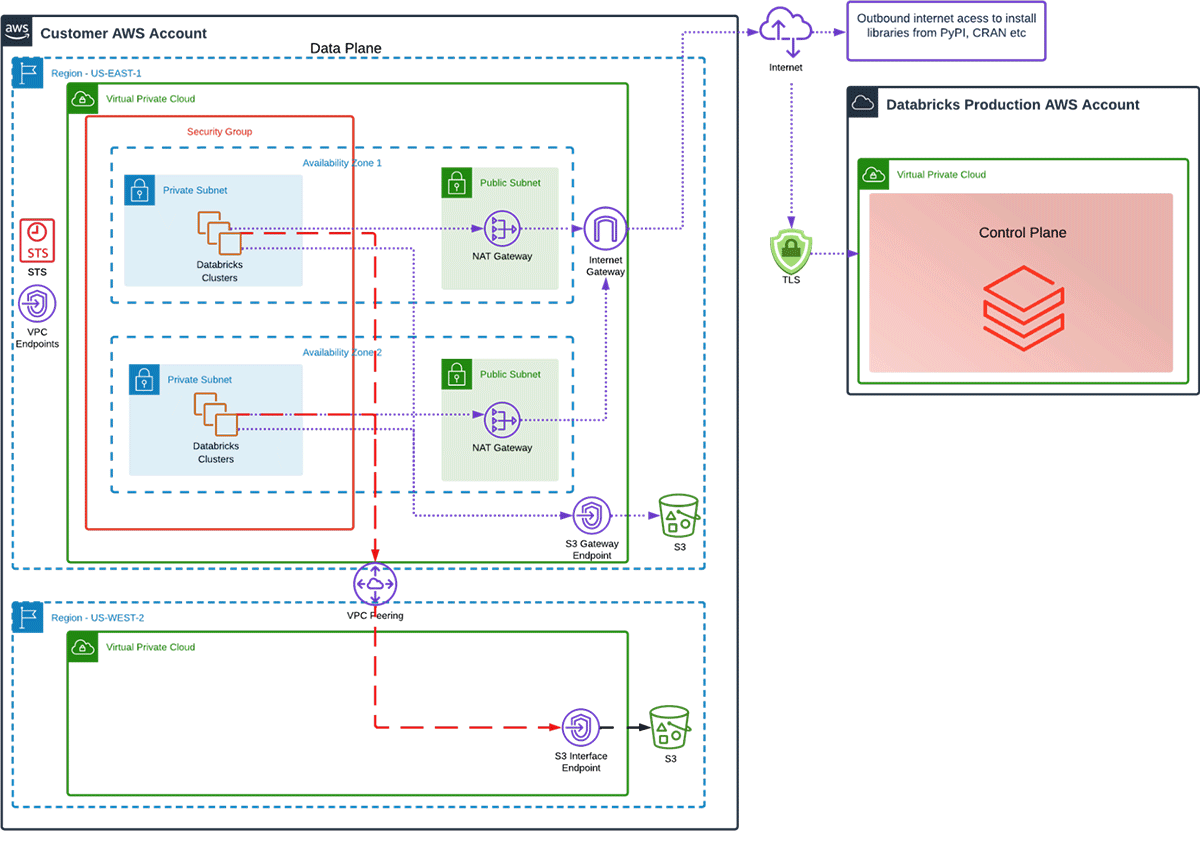
Now that we have an S3 interface in another region, what does our data transfer cost look like when compared to one regional S3 Gateway Endpoint and a NAT Gateway?
Example Scenario: 10TB Cross-Region
- 10TB Via S3 Interface Endpoint = 10TB (10 240GB) * $0.01 per GB = $102.40
- S3 Interface Endpoint = $0.01 per hour * 730 hours in a month = $7.30
- Cross-Region Data Transfer = 10TB (10 240GB) * $0.02 per GB = $204.80
- TOTAL : $ 314.50 (52% Saving or $351.10 per Month)
What should I do next?
- Use AWS Cost Explorer to see if you have high costs associated with NATGateway-Bytes or DataTransfer-Regional-Bytes.
- S3 Endpoint is almost always better than NAT Gateway. Make sure you have this configured so the Databricks clusters can access it. You can test the routing using AWS VPC Reachability Analyser
We hope this helps you reduce your data ingress and egress cost! If you'd like to discuss one of these architectures in more depth, please reach out to your Databricks representative.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.