If you’ve been following the world of industry-grade LLM technology for the last year, you’ve likely observed a plethora of frameworks and tools in production. Startups are building everything from Retrieval-Augmented Generation (RAG) automation to custom fine-tuning services. Langchain is perhaps the most famous of all these new frameworks, enabling easy prototypes for chained language model components since Spring 2023. However, a recent, significant development has come not from a startup, but from the world of academia.
In October 2023, researchers working in Databricks co-founder Matei Zaharia’s Stanford research lab released DSPy, a library for compiling declarative language model calls into self-improving pipelines. The key component of DSPy is self-improving pipelines. As an example: while ChatGPT appears as a single input-output interface, it’s clear there’s not just a single LLM call happening under the hood. Instead, the model interacts with external tools like web browsing or RAG from custom document uploads in a multi-stage pipeline. These tools produce intermediate outputs that are combined with an initial input to produce a final answer. Just as data pipelines and machine learning models led to the emergence of MLOps, LLMOps is being shaped by DSPy’s framework of LLM pipelines and foundation models like DBRX.
Where DSPy truly shines is in the self-improvement of these pipelines. In a complex, multi-stage LLM pipeline, there are often multiple prompts along the way that require tuning. Most industry LLM developers are all too familiar with single words within their prompts that can make or break a deployment (Figure 1). With DSPy, JetBlue is making manual prompt-tuning a thing of the past.
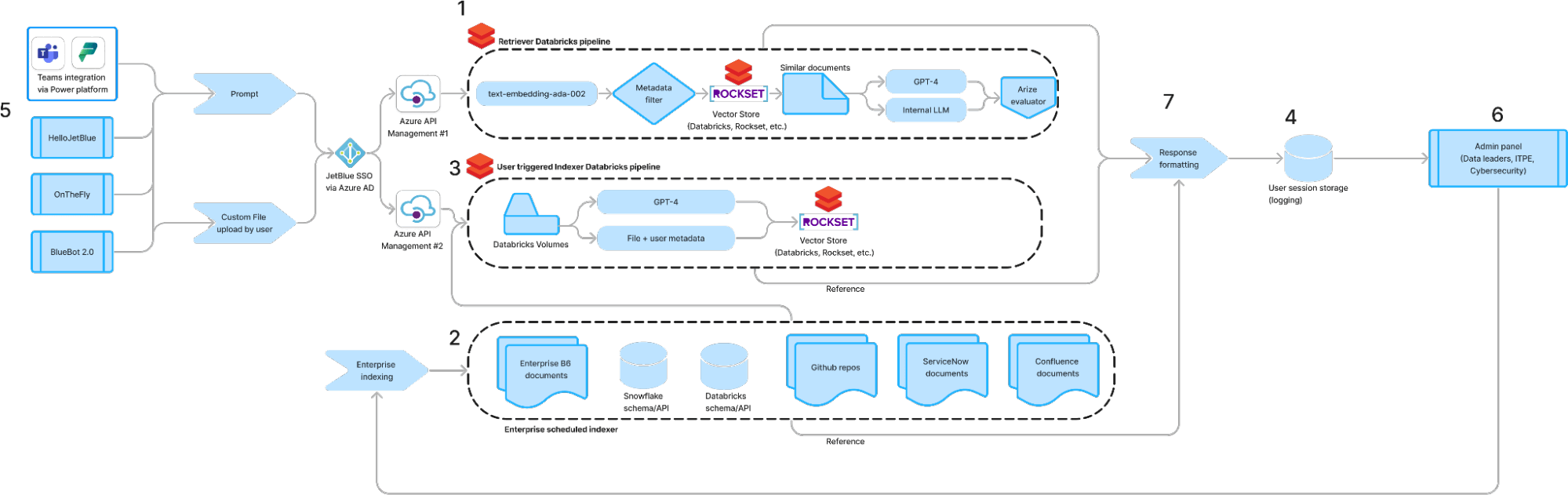
In this blog post, we’ll discuss how to build a custom, multi-tool LLM agent using readily available Databricks Marketplace models in DSPy and how to deploy the resulting chain to Databricks Model Serving. This end-to-end framework has enabled JetBlue to quickly develop cutting-edge LLM solutions, from revenue-driving customer feedback classification to RAG-powered predictive maintenance chatbots that bolster operational efficiency.
Figure 2: Common prompt-engineering methodology before DSPy
DSPy Signatures and Modules
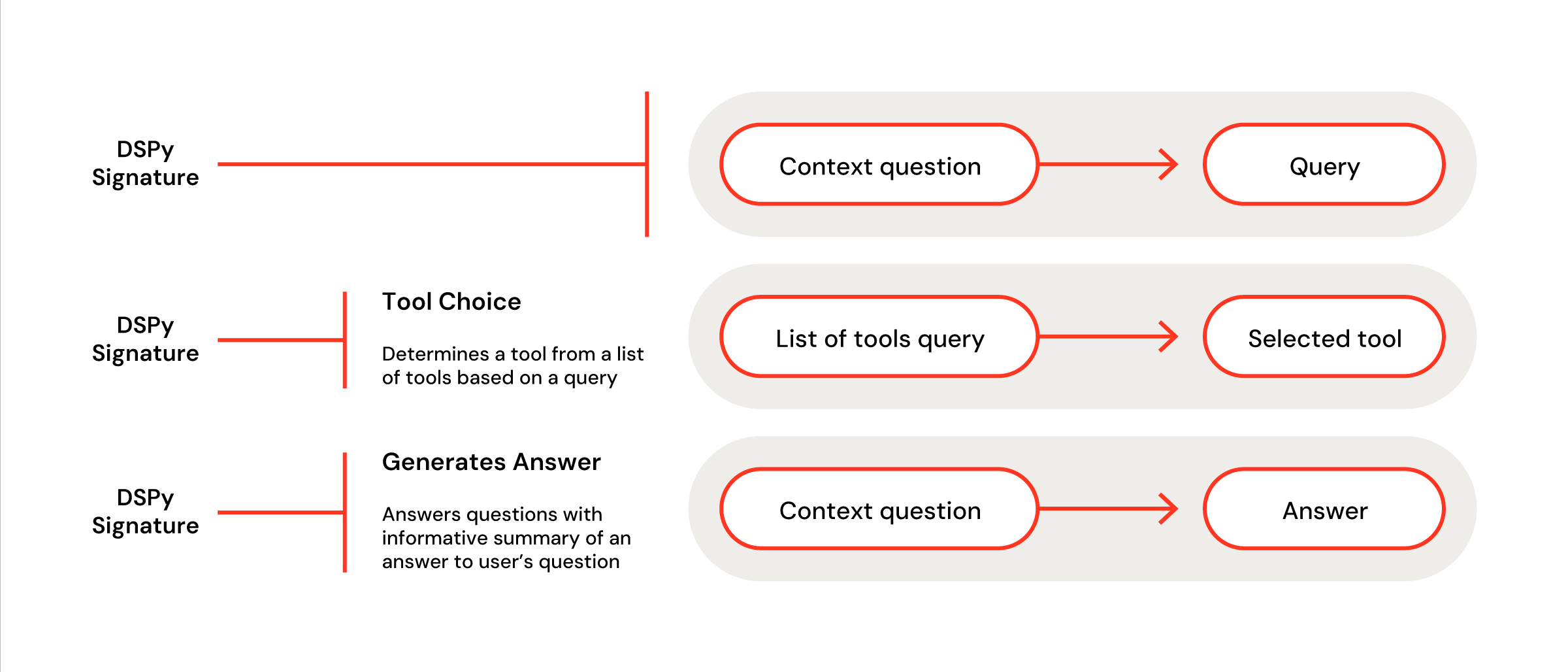
Behind every bespoke DSPy model is a custom signature and module. For context: think of a signature as a customized, single LLM call in a pipeline. A common, first signature would be to reformat an initial user question into a query using some pre-defined context. That can be composed in one line as: dspy.ChainOfThought("context, question -> query") . For a little more control, one can define this component as a Pythonic class (Figure 2). Once you get the hang of writing custom signatures, the world is your oyster.
Figure 3: A custom signature with descriptions meant to choose a tool at the beginning of a DSPy pipeline, and generate a final answer at the end
These signatures are then composed into a PyTorch-like module (Figure 3). Each signature is accessed within the model’s forward method, sequentially passing an input from one step to the next. This can be interspersed with non-LLM-calling methods or control logic. The DSPy module enables us to optimize LLMOps for better control, dynamic updates, and cost. Instead of relying on an opaque agent, the internal components are modularized so that each step is clear and able to be assessed and modified. In this case, we take a generated query from user input, choose to use a vector store if appropriate, and then generate an answer from our retrieved context.
Figure 4: DSPy signatures are composed into pipelines via a Pytorch-like module
Deploying the Agent
We can follow the standard procedure for logging and deploying an MLflow PyFunc model by first using a PyFunc wrapper on top of the module we created. Within the PyFunc model, we can easily set DSPy to use a Databricks Marketplace model like Llama 2 70B. It should be noted that Databricks Model Serving expects DataFrame formatting, whereas DSPy is working with strings. For that reason, we’ll modify the standard predict and run functions as follows:
Figure 5: Modifications to PyFunc model serving definition needed for translating between DSPy and MLflow
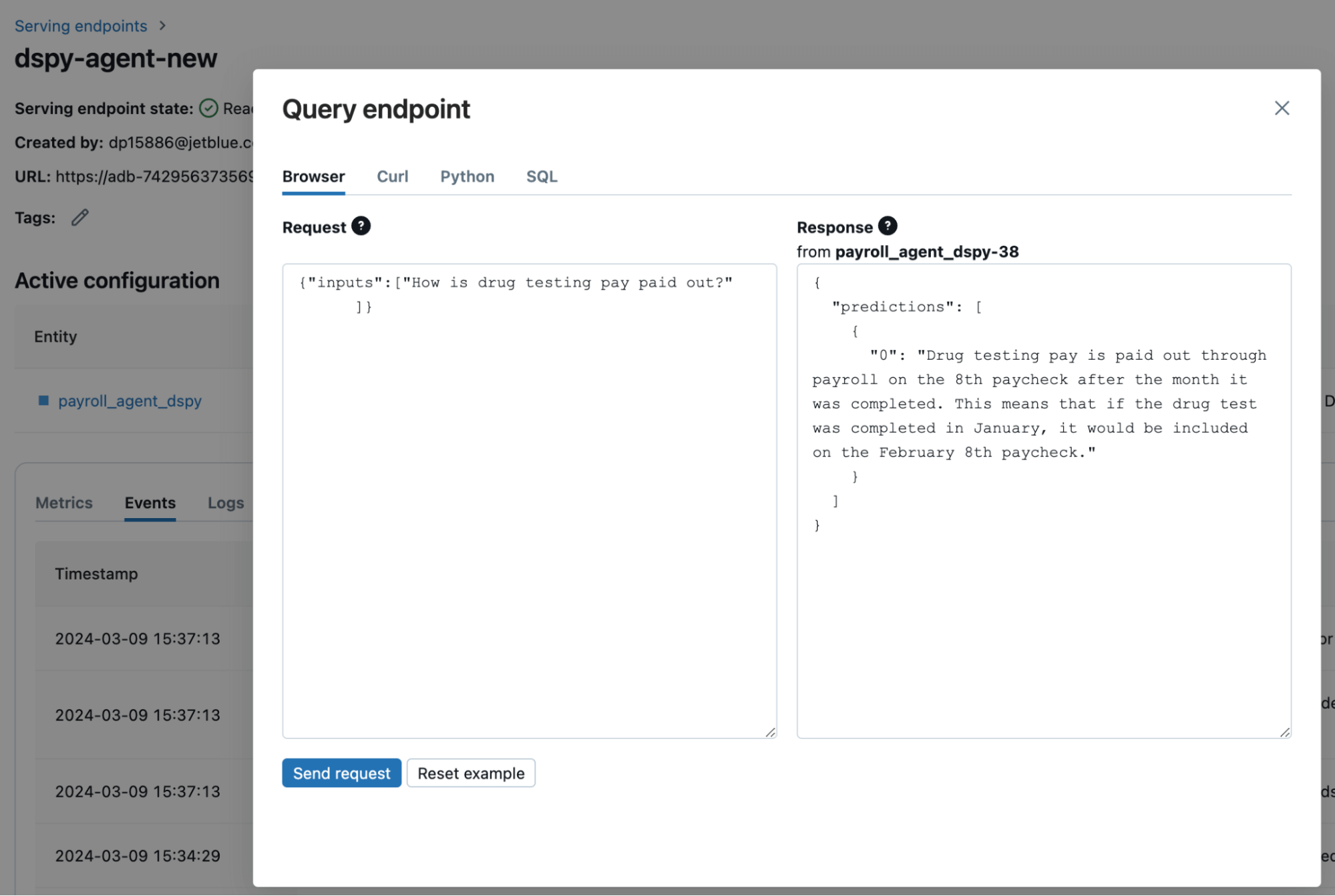
The model is created using the mlflow.pyfunc.log_model function, and deployed to one of JetBlue’s internal serving endpoints following the steps outlined in this Databricks tutorial. You can see how we can query the endpoint via Databricks (Figure 5), or by calling the endpoint via an API. We call the endpoint API through an application layer for our chatbots. Our RAG chatbot deployment was 2x faster than our Langchain deployment!
Self-Improving our Pipeline
In JetBlue’s RAG chatbot use case, we have metrics related to retrieval quality and answer quality. Before DSPy we manually optimized our prompts to improve these metrics; now we can use DSPy to directly optimize these metrics and improve quality automatically. The key to understanding this is thinking of the natural language components of the pipeline as tunable parameters. DSPy optimizers tune these weights by maximizing toward a task objective, requiring just a defined metric (ie an LLM-as-a-judge assessing toxicity), some labeled or unlabeled data, and a DSPy program to optimize. The optimizers then simulate the program and determine “optimal” examples to tune the LM weights and improve performance quality on downstream metrics. DSPy offers signature optimizers as well as multiple in-context learning optimizers that feed optimized examples to the model as part of the prompt. DSPy effectively chooses which examples to use in context to improve the reliability and quality of the LLM’s responses. With integrations in DSPy now included with Databricks Model Serving Foundation Model API and Databricks Vector Search, users can craft DSPy prompting systems and optimize their data and tasks— all within the Databricks workflow.
Additionally, these capabilities complement Databricks’ LLM-as-a-judge offerings. Custom metrics can be designed using LLM-as-a-judge and directly improved upon using DSPy’s optimizers. We have additional use cases like customer feedback classification where we anticipate using LLM-generated feedback to fine-tune a multi-stage DSPy pipeline in Databricks. This drastically simplifies the iterative development process of all our LLM applications, making the need to manually iterate on prompts unnecessary.
The End of Prompting, The Beginning of Compound Systems
As more and more companies leverage LLMs, the limitations of a generic chatbot interface are increasingly clear. These off-the-shelf platforms are highly dependent on parameters that are outside the control of both end-users and administrators. By constructing compound systems that leverage a combination of LLM calls and traditional software development, companies can easily adapt and optimize these solutions to fit their use case. DSPy is enabling this paradigm shift toward modular, trustworthy LLM systems that can optimize themselves against any metric. With the power of Databricks and DSPy, JetBlue is able to deploy better LLM solutions at scale and push the boundaries of what is possible.