Privacy-centric collaboration on AI with Databricks Clean Rooms
Learn how Databricks Clean Rooms lets your data science team train ML models on sensitive data.

Summary
- Use Databricks Clean Rooms to train ML models on sensitive data without exposing raw underlying data
- Enable secure collaboration across teams, departments, or external partners
- Scale model development across multiple use cases using clean rooms
Access to high-quality, real-world data is crucial for developing effective machine learning models. However, when this data contains sensitive information, organizations face a significant hurdle in enabling data science teams to work with valuable data assets without compromising privacy or security. Traditional approaches often involve time-consuming data anonymization processes or restrictive access controls, which can hinder productivity and limit the potential insights gleaned from the data.
Databricks Clean Rooms reimagines this paradigm. By offering a secure, collaborative environment, clean rooms enable data science teams to train or fine-tune ML models on sensitive data without directly accessing or exposing the underlying information. This innovative approach not only enhances data protection but also accelerates the development of powerful, data-driven models.
Machine learning on sensitive data has diverse applications across industries. In healthcare, models can predict patient outcomes or classify cell types using protected health information without exposing individual records. Financial institutions can develop sophisticated credit scoring and fraud detection models using confidential transaction data. In advertising, companies can leverage machine learning to improve ad targeting and personalization while preserving user privacy.
This blog walks you through the process and setup that Databricks customers can use to train and deliver ML models in a privacy-centric way. We’ll use the example of a healthcare provider who wants to build a model to predict patient readmission risk using sensitive data from electronic health records (EHR).
Scenario & Actors
In a typical organization, data management and data analysis are separated by departments. For example, for a healthcare provider, data is typically governed and managed centrally by data owners. Individuals analyzing the data are typically subject matter or technical experts who understand the domain. For our example, let's assume there are two actors:
- Data Owner - Responsible for the governance, quality, and security of EHR data within the organization. They establish policies for data access, usage, and compliance.
- ML Expert - A data scientist responsible for developing and assessing ML models using healthcare data. They work with clinical experts to frame relevant questions and build models according to requirements.
Goal: The Data Owner wants to empower the ML Expert to build a model while restricting direct access to the sensitive EHR data. At the same time, the ML Expert wants to iterate on the training code and enhance the model as required. The result of this collaboration would generate a model output used to predict readmission.
Databricks Requirements
- An account that is enabled for serverless compute. See this guide to enable serverless compute.
- Workspace(s) that are enabled for Unity Catalog. Check out this guide to enable Unity Catalog.
- Delta Sharing enabled for the Unity Catalog metastore. Follow this guide to enable Delta Sharing on a metastore.
- Both the Data Owner and the ML Expert have the CREATE CLEAN ROOM privilege. Use this guide to manage privileges in the Unity Catalog.
The Setup
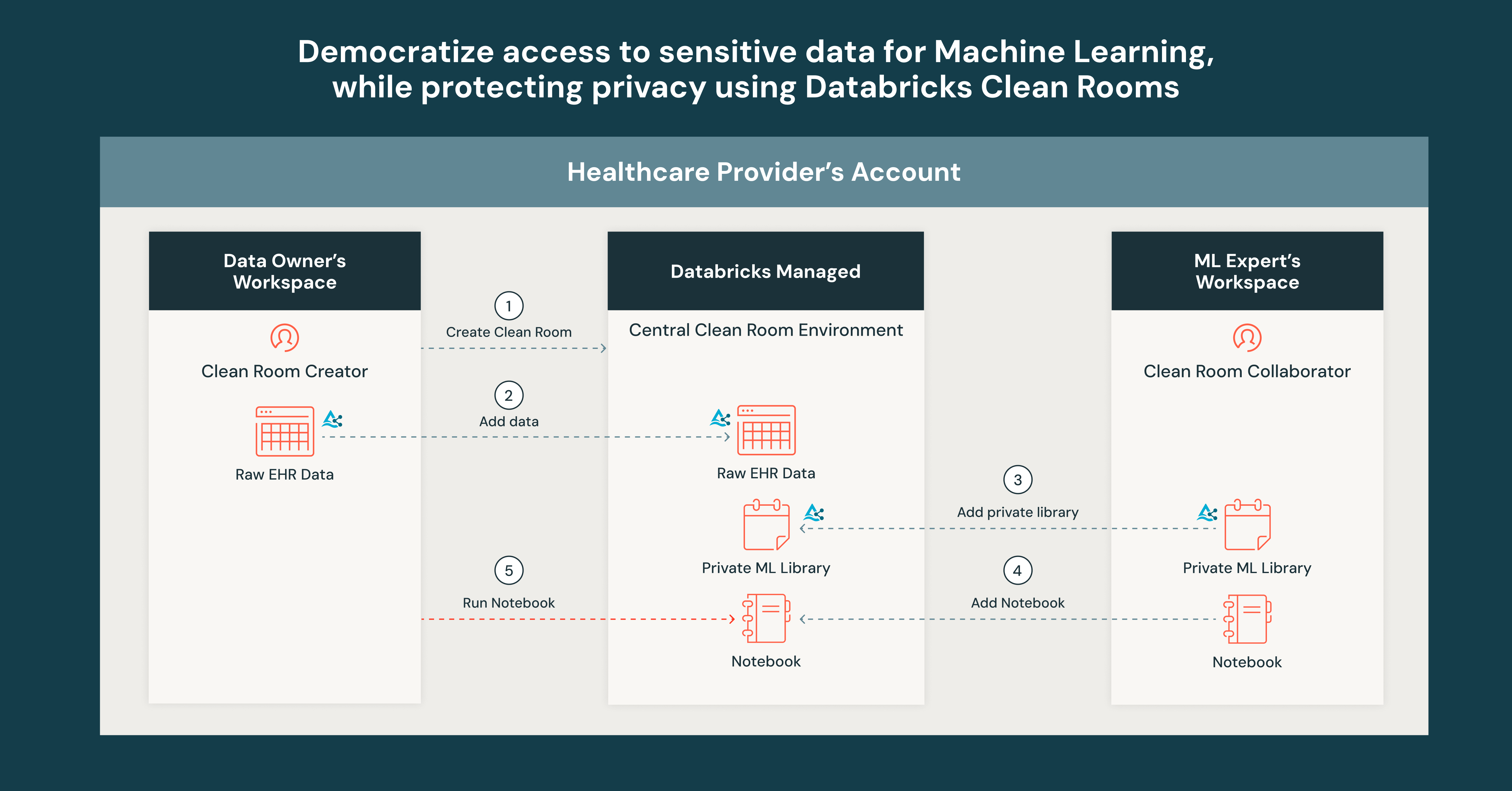
Step 1: The Data Owner (or user with CREATE CLEAN ROOM permission) creates a clean room with restricted internet access and invites the ML expert to collaborate using their clean room sharing identifier.
Step 2: The Data Owner adds the raw EHR data to the clean room. Behind the scenes, this data is delta-shared into the central clean room environment. The ML expert can only see the table metadata, not the underlying data.
Step 3: The ML expert develops a private library that contains code that builds a model using the raw EHR data and predicts readmission risk. The ML Expert packages their private library in a Python wheel, adds it to a volume, and adds the volume to the clean room. Behind the scenes, the volume is delta-shared into the clean room. The Data Owner cannot directly inspect the volume contents, so the training code stays secure and hidden.
Step 4: The ML expert also adds a notebook that uses the private library and outputs a model.
Step 5: The Data Owner runs the notebook and receives the output model within the clean room. By having the Data Owner run the notebook, they can ensure the private library does not exfiltrate or reveal the underlying data to the ML Expert. In addition, the ML Expert can update the training code in the private library at any time to further enhancements. The model can also be used for inferencing or shared with stakeholders for further analysis.
And that’s it! In just a few steps, the healthcare provider can protect sensitive EHR data while enabling the data science team to develop ML models for a variety of use cases.
Databricks Clean Rooms is now generally available on AWS and Azure! Whether you're collaborating within your organization or with external partners, Clean Rooms provides a secure environment for data sharing and analytics. Start using it today to enhance internal model building, streamline workflows, and unlock valuable insights.
Never miss a Databricks post
What's next?


Product
November 21, 2024/3 min read