Providence Health: Scaling ML/AI Projects with Databricks Mosaic AI

Summary
By working with Databricks solutions architects and product engineers, Providence Health was able to improve our initial results and support 7x the number of departments at a time (from ~40 to 300+) while delivering accurate departmental arrivals and occupancy forecasting in well under an hour. This was accomplished by optimizing code both on the Databricks AutoML and the Providence side. Providence's goal of providing baseline forecasts daily has been achieved and continues to scale.
Providence Health's extensive network spans 50+ hospitals and numerous other facilities across multiple states, presenting many challenges in predicting patient volume and daily census within specific departments. This information is critical to making informed decisions about short-term and long-term staffing needs, transfer of patients, and general operational awareness. In the early stages of Databricks adoption, Providence sought to create a simple baseline census model that would get new requests going quickly, aid in exploration and in many cases provide an initial forecast. We also realized that scaling this census to support thousands of departments in near real-time was going to take some work.
We began our implementation of Databricks Mosaic AI tools with Databricks AutoML. We appreciated the ability to automatically run forecasts from a few lines of code every time our scheduled workflow ran. AutoML doesn't require a detailed model setup, making it ideal for getting a first look at our data in a forecast. We created a notebook that defined our forecasting classes and included a few lines of AutoML code. When we ran the forecasts from our scheduled workflows, AutoML not only created model training experiments but also automatically generated the supporting notebooks and data analysis. This capability enabled us to review any specific job run, assess forecast performance, compare the performance of different trials, and access other essential details as needed.
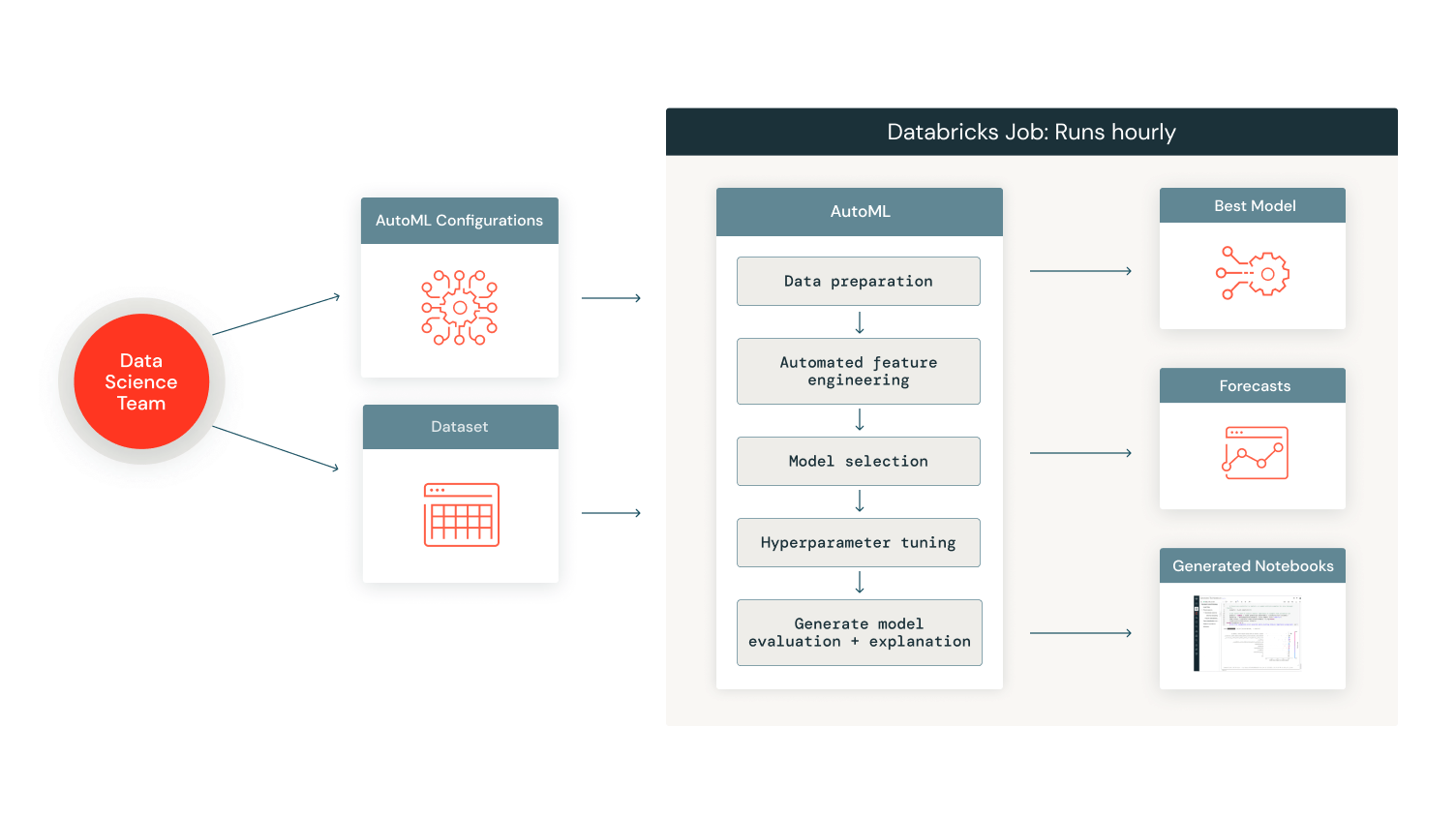
Providence prides itself on being an industry leader in machine learning and AI. Our initial trial of 40+ emergency departments averaged a census delivery forecast that was well over our benchmark of 1 hour. Given our goal of near real-time forecasting, this was clearly not an acceptable result. Fortunately, Providence and Databricks have partnered over the last few years to find creative solutions to difficult problems in healthcare technology and we saw an opportunity to continue that relationship.
By working closely with Databricks solutions architects and product engineers, we were able to improve our initial results and support 7x the number of departments at a time (from ~40 to 300+) while delivering accurate departmental arrivals and occupancy forecasting in well under an hour. This was accomplished by optimizing code both on the Databricks AutoML and the Providence side. Today, our goal of providing baseline forecasts daily has been achieved and continues to scale. For models not currently in AutoML, we use other Databricks Notebooks with MLFlow and we are looking forward to including them in AutoML in the near future. As we continue our ongoing optimization work, we anticipate the ability to provide thousands of forecasts to Providence customers in near real-time.
Big Book of MLOps

This blog post was jointly authored by Susan McNerney (Providence Health) and Dan McCurley (Databricks).
Additional Reading:
Learn more about low-code ML solutions from Databricks using Mosaic AutoML
Get started with AutoML experiments through a low-code UI or a Python API