Scalable Kubernetes Upgrade Using Operators
by Ziyuan Chen
At Databricks, we run our compute infrastructure on AWS, Azure, and GCP. We orchestrate containerized services using Kubernetes clusters. We develop and manage our own OS images that bootstrap cloud VMs into Kubernetes nodes. These OS images include critical components for Kubernetes, such as the kubelet, container runtime, and kube-proxy, etc. They also contain OS-level customizations necessary to Databricks' services.
Self-managed OS images require regular updates to pick up CVE patches, kernel updates, code changes to custom configurations, etc. Regularly releasing OS images to a large fleet of clusters across three clouds is very challenging.
This blog post covers how we went from a legacy system using Spinnaker, Jenkins, and Python scripts to a new one based on Kubernetes operators. The new approach is cloud native, scalable, fast, reliable, and addresses a number of pain points that we will cover in later sections.
Legacy system
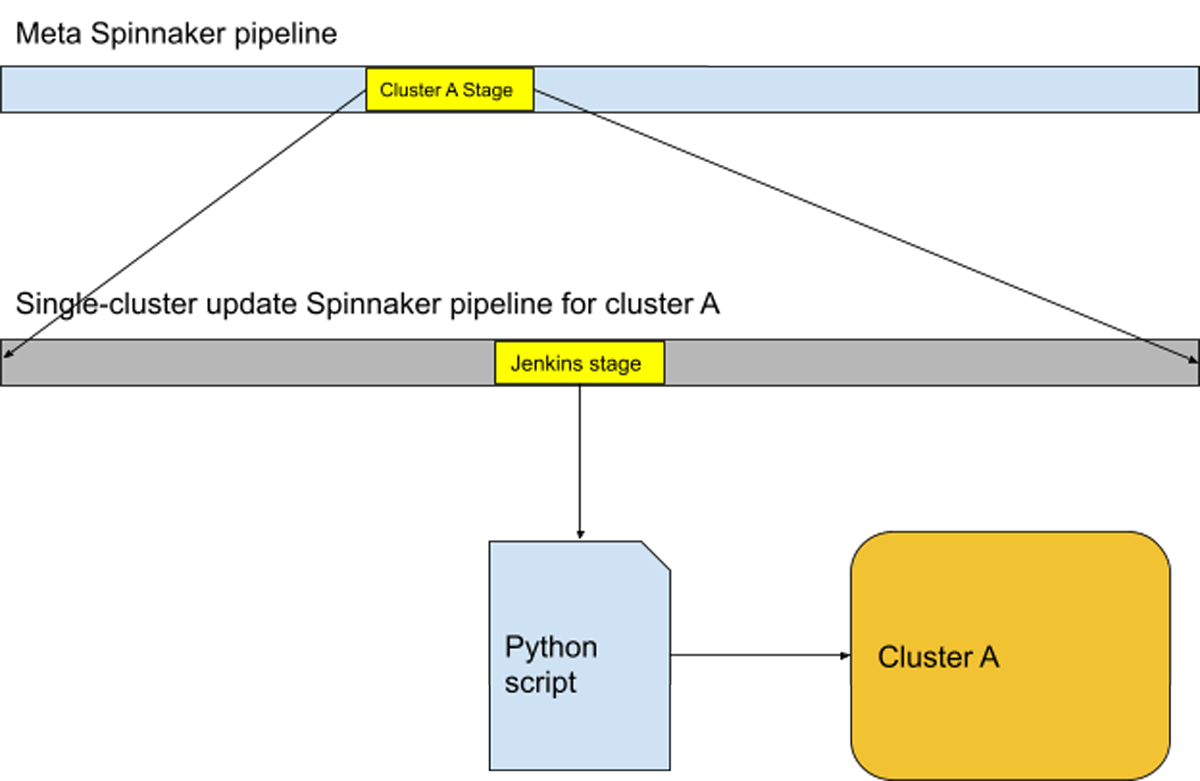
Infrastructure operations at Databricks had traditionally been performed using Spinnaker, Jenkins, and Python scripts. A Spinnaker pipeline consisting of many Jenkins stages, each running a Python script, was the implementation for blue-green node upgrade. The workflow of an engineer performing such an upgrade was:
- The engineer triggers a "meta" Spinnaker pipeline that knows the list of Kubernetes clusters to upgrade. There is one stage of execution per cluster, and in each stage, child Spinnaker pipelines are triggered for node pools in the Kubernetes cluster within that stage.
- The child Spinnaker pipeline executes several stages, each being a Jenkins job that runs the Python script with certain flags.
- If any of the Spinnaker stages failed for any reason, the oncall engineer would be notified. The engineer would need to use the Spinnaker UI to manually investigate and restart the failed Spinnaker stages in order for the whole upgrade process to proceed.
The Python script contains the core blue-green upgrade algorithm with the following steps to upgrade Kubernetes nodes with services running on them without downtime.
For each node pool in a cluster:
- Select a batch size 1 <= n <= N, where N is the total number of nodes in the node pool.
- Bring up n new nodes that use the new image, then drain n nodes that use the old image, while respecting PodDisruptionBudgets (PDBs).
- Terminate the n nodes drained in the previous step.
- Repeat the above for all nodes running the old image, until all such nodes are terminated, and the entire node pool contains only nodes running the new image.
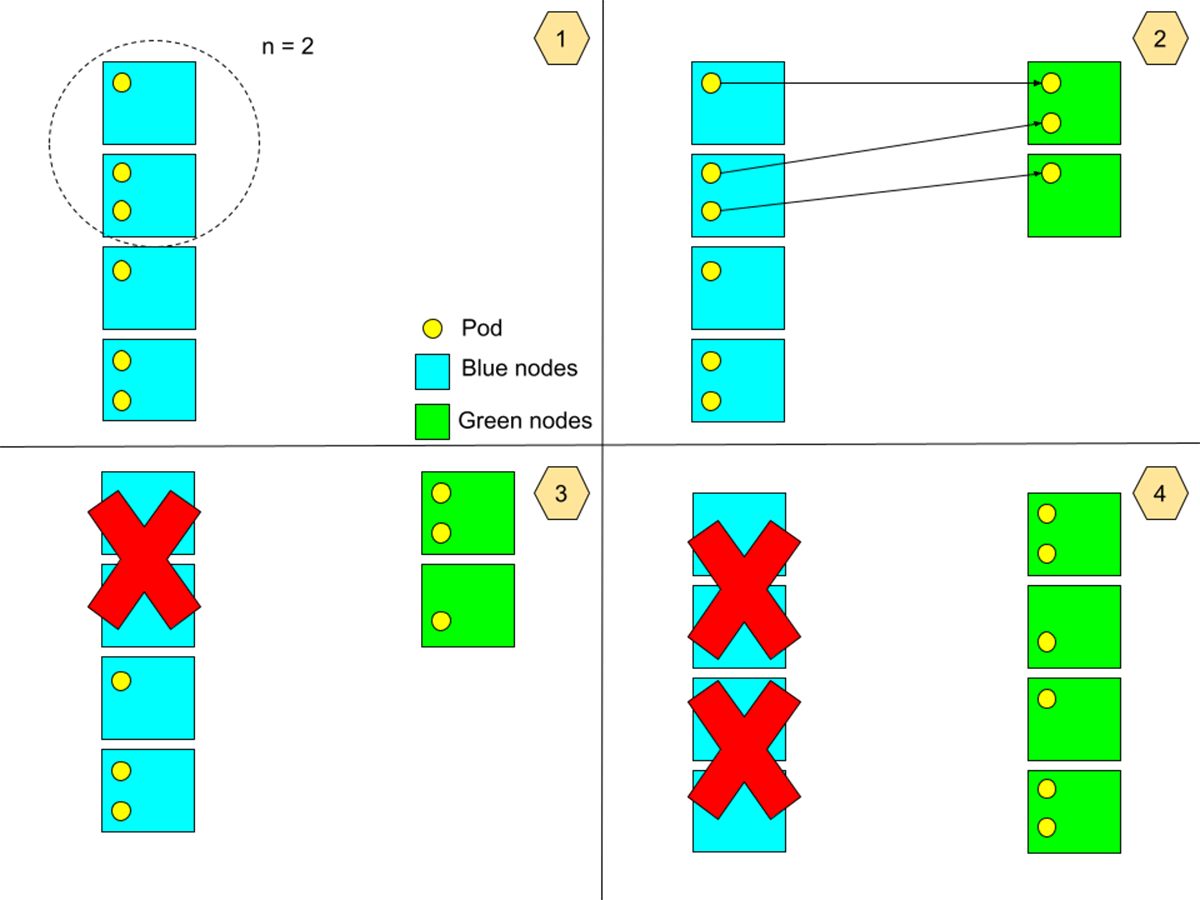
We chose to handle the blue-green upgrade in small batches over many iterations, instead of performing a full blue-green upgrade of all nodes in one iteration, to reduce the maximum total number of nodes in the cluster during an upgrade operation. This reduces the chance of encountering cloud quota issues, and the cloud cost on VM instances.
Pain points
This legacy system presented many issues mainly in the following aspects:
Reliability
The legacy system depended on Spinnaker and Jenkins, so it was subject to Spinnaker and Jenkins reliability issues. Its Python script also contained many external dependencies added over the years, resulting in numerous points of failure. The purely sequential nature of the Python scripts meant that the system was subject to transient issues in production Kubernetes clusters and cloud provider APIs, such as when a pod could not be evicted, a pod could not be scheduled on a new node, certain signals indicated the cluster was in a bad state, etc. It was also highly susceptible to timeouts of any operation, as there was only a finite number of retries that can be had in a sequential logic. Therefore, 95% of the oncall pages were due to self-recoverable issues that the legacy system could not tolerate, and it amounted to > 100-150 oncall alerts per week for our fleet. The oncall engineer had to constantly manually restart and track (on a spreadsheet!) the failed Spinnaker stages.
Idempotency
Because self-recoverable errors are frequent, any system that performs the node upgrades would have to have many retries. However, due to both technical debt and the sequential nature of Python scripts, it was very difficult to ensure the idempotency of every piece of logic, and even impossible in some cases. This is because if a Python script exited due to an error or a timeout, then the oncall engineer would have to manually restart the Jenkins stage, which would re-run the Python script from a clean state. Because of the ephemeral nature of Jenkins jobs, the restarted Jenkins job would be oblivious of the context. This could result in incorrect behaviors such as bringing up 2n nodes for updating a batch of n nodes.
Scalability
The scalability of the legacy system was poor in two ways.
Firstly, each Jenkins job was deployed as a pod, and required the Jenkins scheduler to reserve a large amount of computing resources due to the inefficiency in the Python script. Jenkins was hosted in one single Kubernetes cluster, creating a scalability bottleneck due to that cluster's limited resources.
Secondly, the human operational scalability was poor. As mentioned in Reliability, the oncall engineer had to respond to 100-150 pages a week, greatly straining the engineer.
Testability
Jenkins and Spinnaker pipelines were non-testable other than manual tests on real Kubernetes clusters, which would take many hours to test only one possible code path. The Python scripts, although testable, had low test coverage due to historical neglect of unit tests. As a result, the legacy system was poorly tested, and the team often discovered breaking changes during real cluster node upgrade operations.
New system based on Kubernetes operators
To solve the problems mentioned above, the team decided to move the majority of the node upgrade operations into a new implementation in the form of Kubernetes operators. Kubernetes operators have many advantages over the legacy system, but the major ones are:
- Idempotent.
- Declarative. In our case, the goal state is that all nodes in a node pool are running the new OS image. Even outside of node upgrade operations, the operators can continuously ensure that all nodes are running the correct OS image by draining and terminating any incorrectly-created nodes that run the incorrect OS image.
- No external infra dependency. They can be hosted in the same Kubernetes clusters they perform upgrades on, improving the scalability and eliminating cross-cluster dependencies in the legacy system.
- Better ecosystem support. They are written in Go using KubeBuilder and controller-runtime. They have better Kubernetes support, better performance, better testability, and higher reliability than the old Python scripts, which are non-typed and interpreted.
- Easily end-to-end testable.
- Their model is asynchronous, allowing different node pools to be upgraded in parallel, greatly reducing the time needed for a full cluster node upgrade.
New user workflow
In this new system, the workflow of an engineer performing a node upgrade is:
- The engineer triggers a meta Spinnaker pipeline that knows the list of Kubernetes clusters to upgrade. It, in each of its stages, creates/updates Kubernetes Custom Resources for the node pools in the cluster to kick-start the node upgrades.
- The oncall engineer can assume that the upgrade is progressing without issues unless alerted by the system. There is also a monitoring dashboard to track the overall progress in all clusters.
High-level architecture
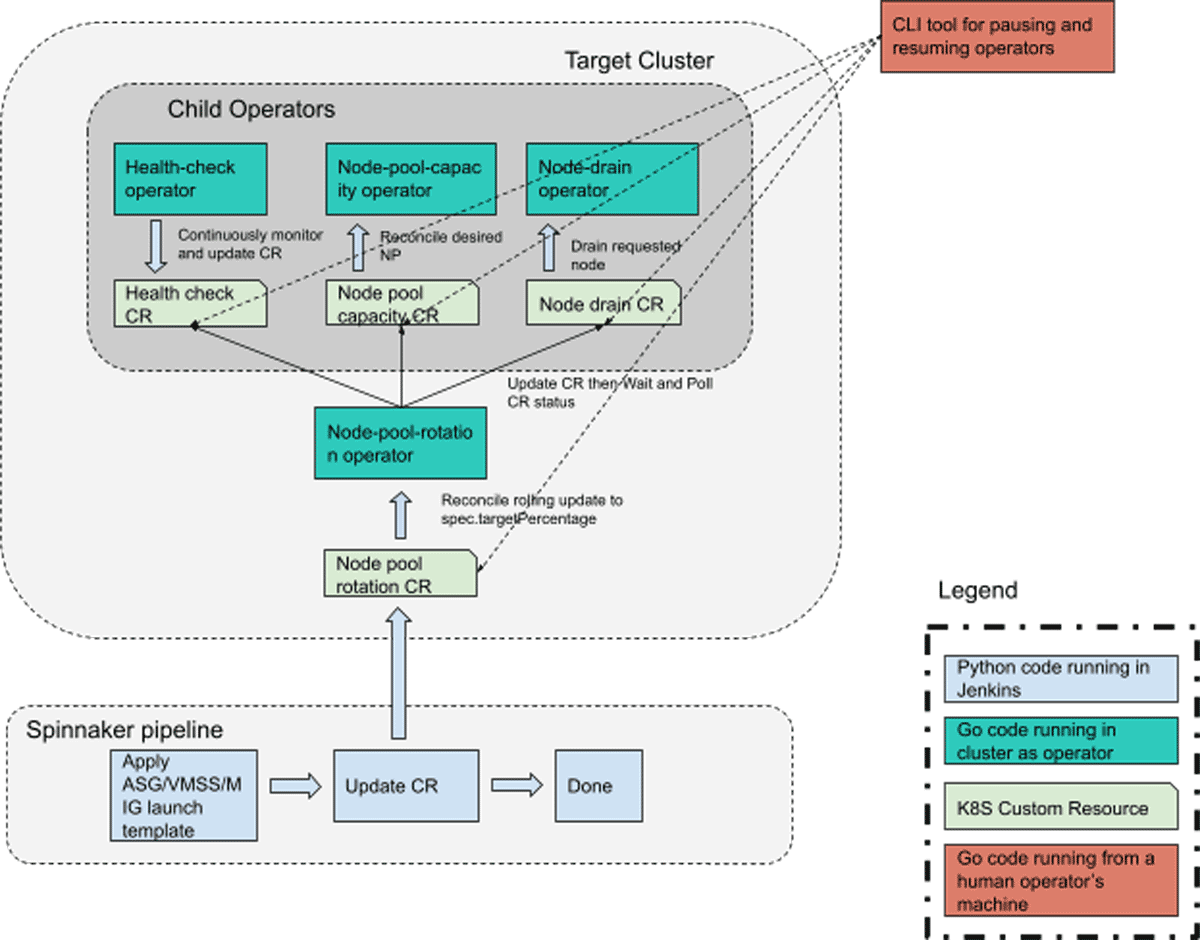
The system consists of four Kubernetes operators whose controllers are run as pods in each of our Kubernetes clusters. They each have their CustomResourceDefinition(CRD) as the API interface between them and their callers.
The Spinnaker pipeline still exists, but is greatly simplified. It now only contains two operations: (1) applying the new launch template such that in the new ASG/VMSS/MIG so that new nodes will be using the new OS image, and (2) updating the "node pool rotation" CustomResource(CR). The node-pool-rotation operator, upon observing the upgrade on the node-pool-rotation CR(s), will start reconciling the corresponding node pools in parallel. It will invoke the three child operators using their respective CRDs to perform node-draining, health-checking, and node-pool-scaling, all of which are needed to perform a blue-green upgrade without causing service downtime.
Child operators
Node-drain operator
The node drain operator is responsible for draining workloads running on any given node, while respecting their PDBs and special handling requirements.
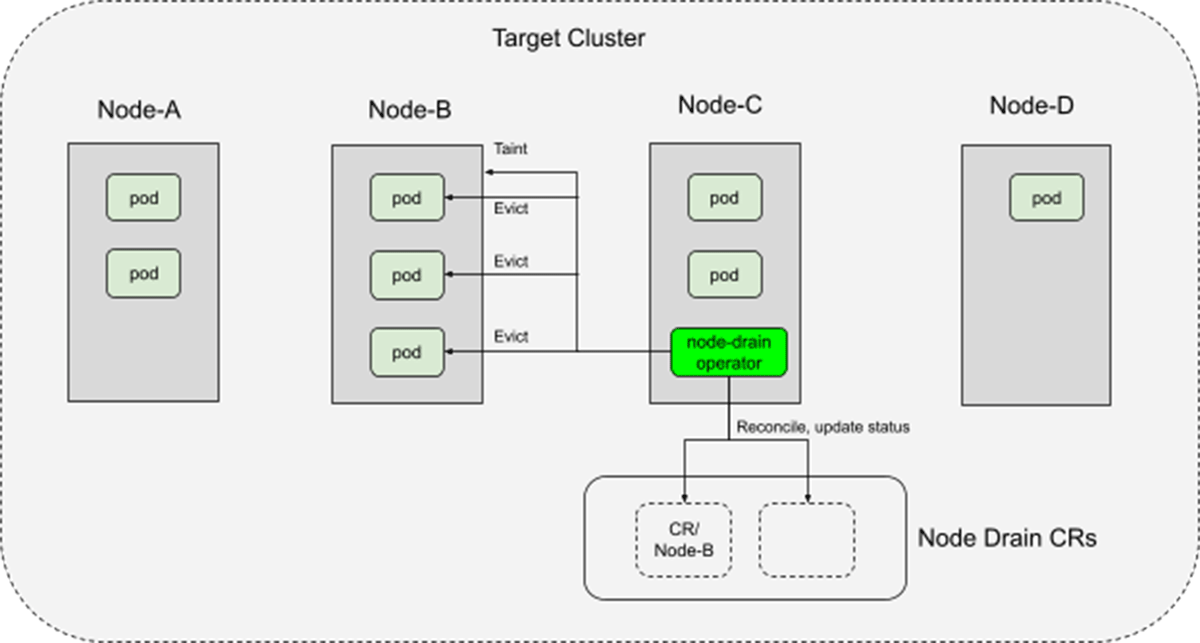
The node-drain operator, being self-hosted in the Kubernetes cluster, will inevitably drain itself and other three operators. But due to the idempotent and declarative nature of the operators, once their pods are rerunning on new nodes, they will pick up where they left off.
Node-pool-capacity operator
The node-pool-capacity operator consists of two Kubernetes controllers: the node-pool-capacity controller of the same name, and the node-termination controller. They both use cloud providers' Go SDKs to interact with their APIs.
The node-pool-capacity controller is illustrated below. It uses cloud provider APIs to adjust the number of VMs in a node pool's underlying ASG/VMSS/MIG. It also coordinates with the cluster-autoscaler, which we have deployed to our Kubernetes clusters as well, to ensure that any newly-brought-up nodes will not be scaled down by the latter during the node upgrade operation.
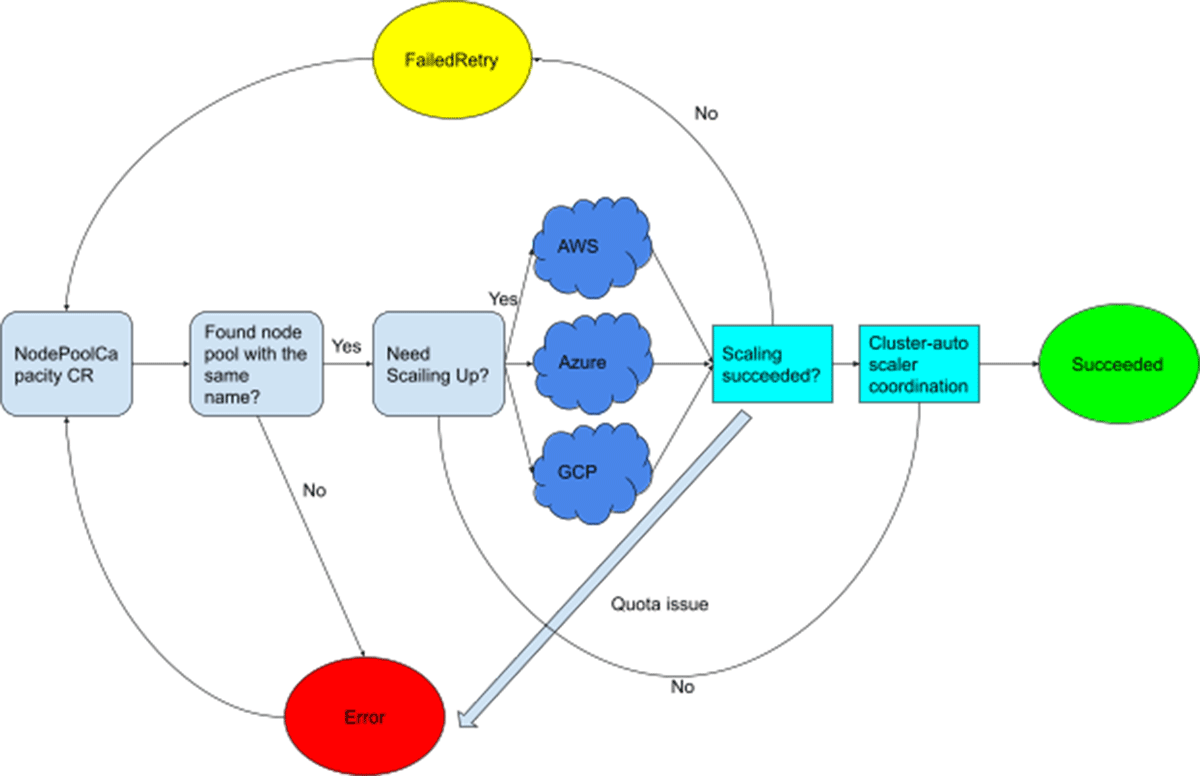
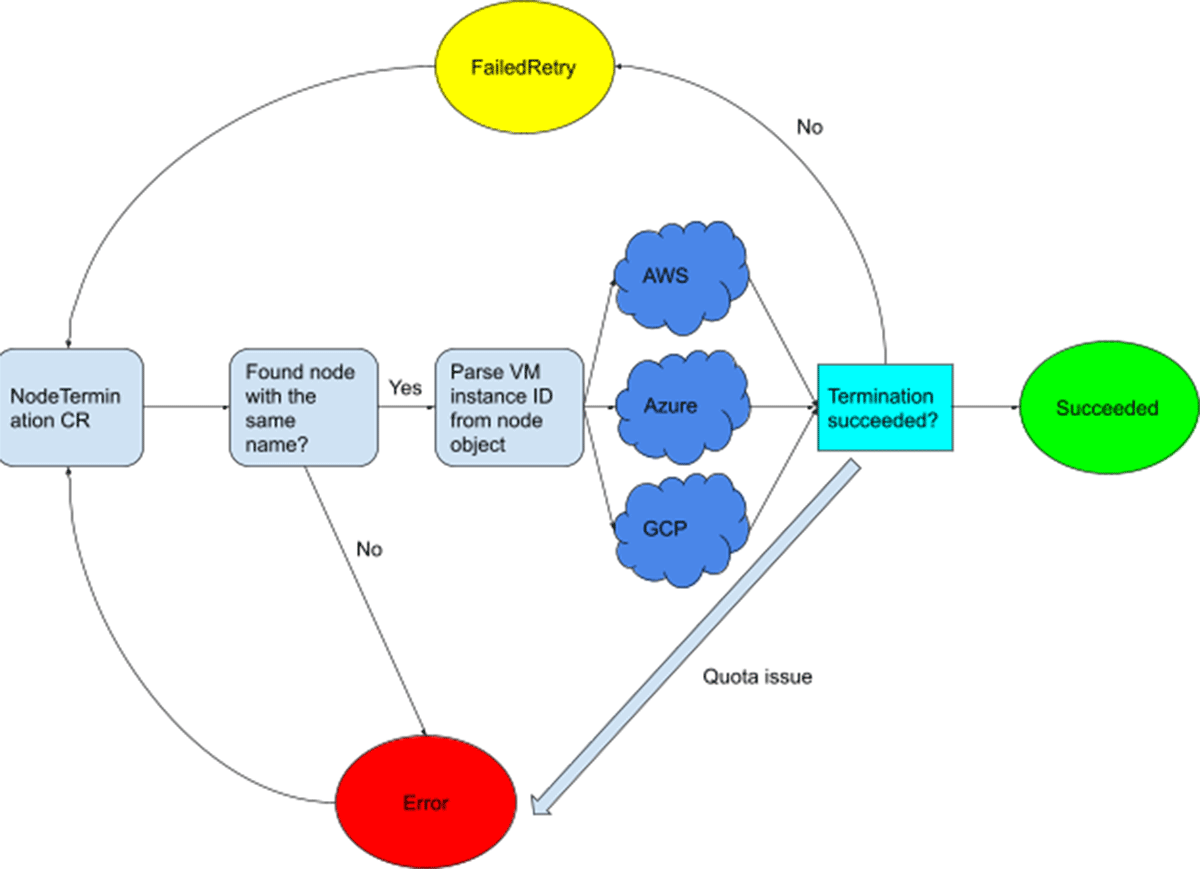
The node-termination controller is illustrated below. It terminates any given node by finding its underlying VM in the cloud provider, and terminates the underlying VM by calling the corresponding cloud API.
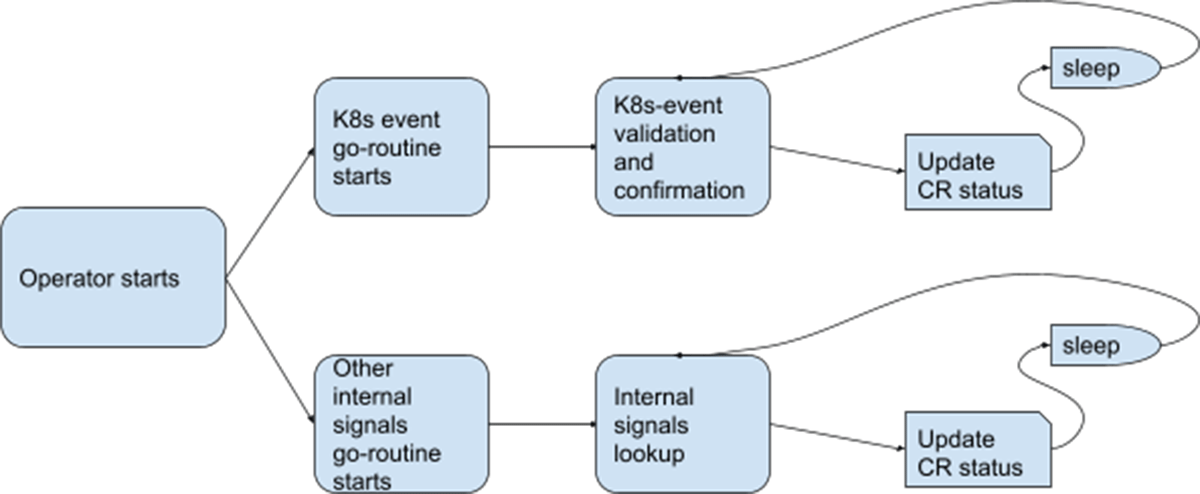
Health-check operator
The health-check operator analyzes Kubernetes events and certain internal signals to determine the cluster's health (including the services running on it). It exports the health status to CR instances of the HealthCheck CRD. These CRs are consumed by the node-pool-rotation operator at many points during its reconciliation to ensure that the cluster and workloads remain in a healthy state after certain critical migration / update steps.
The operator's core logic is illustrated below:
Node-pool-rotation operator
The node pool rotation operator watches both the NodePoolRotation CR and all nodes in the cluster. If a node pool rotation CR is updated or a node running the incorrect OS image is brought up, then it will trigger a reconciliation. The reconciliation follows the following stage and checkpoint model:
Stage 1: Pre-checking, initialization, cleaning up certain objects in bad states, calculations
Stage 2: Performing the batch update of n nodes from the old OS image to the new OS image
Stage 3: Post-checking, cleanup, post-handling of nodes requiring special handling
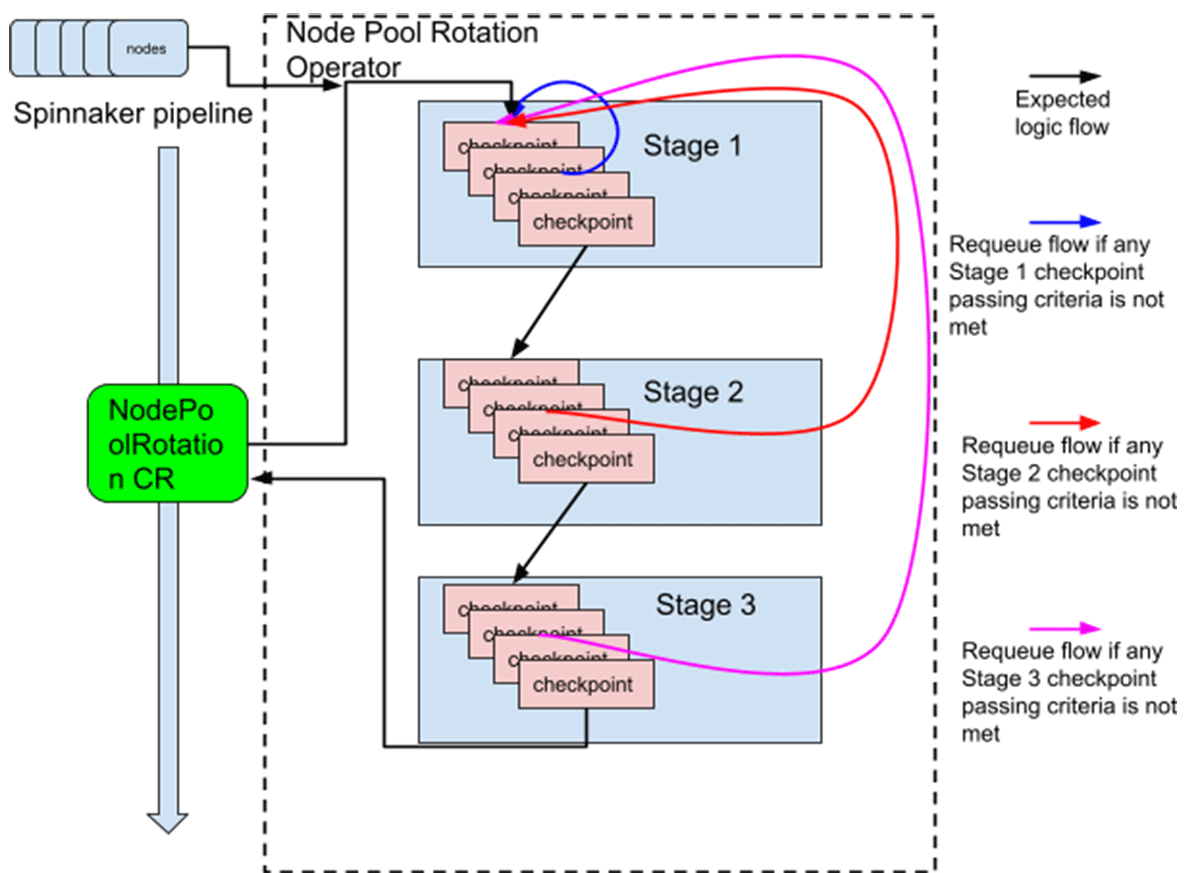
A "checkpoint" is defined as a step during the upgrade of a batch of n nodes. For example, "bringing up n nodes running the new OS image" is a checkpoint, and "drain n nodes running the old OS image" is another checkpoint. The checkpoint model is illustrated below:
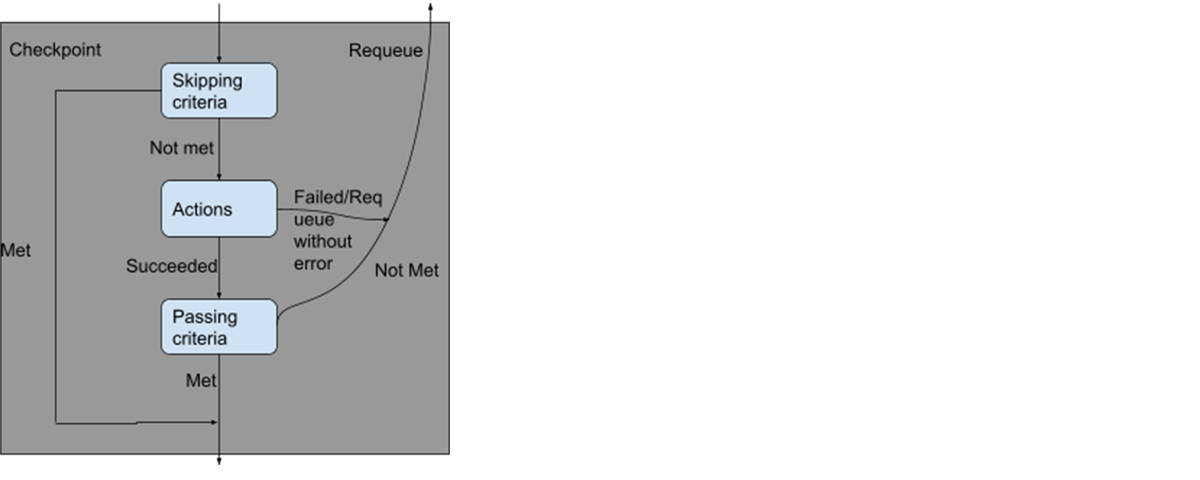
This model ensures idempotency by requiring all function calls in the skipping criteria and the passing criteria are pure functions, excluding the calls to any APIs, which are inherently not idempotent.
We also made sure that Stage 2 were to be executed as an atomic unit, even if any checkpoint in Stage 2 failed and the reconciliation was requeued. This is because this stage contains the core sequence of "bring up new nodes, drain old nodes, terminate old nodes" and cannot be idempotent unless atomic. For example, if we are in the process of bringing up 5 new nodes, and we requeued because the status of the node-pool-capacity operator is not "ready", then when we reconcile again, we may find that 3 out of 5 nodes have been brought up, but the reconciler has no historical knowledge that we were bringing up 5 new nodes, so it will try to bring up 5 new nodes again. This will result in the cluster's size growing indefinitely. We ensure such atomicity by writing the state of this stage to the "status" field of the NodePoolRotation CR to provide the reconciler with the historical context.
Monitoring and alerting
In the new workflow, we follow a "trigger and forget" model where the Spinnaker pipeline merely kick-starts the upgrade, then completes. As a result, we need a way to observe the progress of such upgrades and alert us if anything goes wrong.
We rely on Prometheus metrics to report both the upgrade progress and any errors. We use Grafana to build dashboards visualizing these metrics.
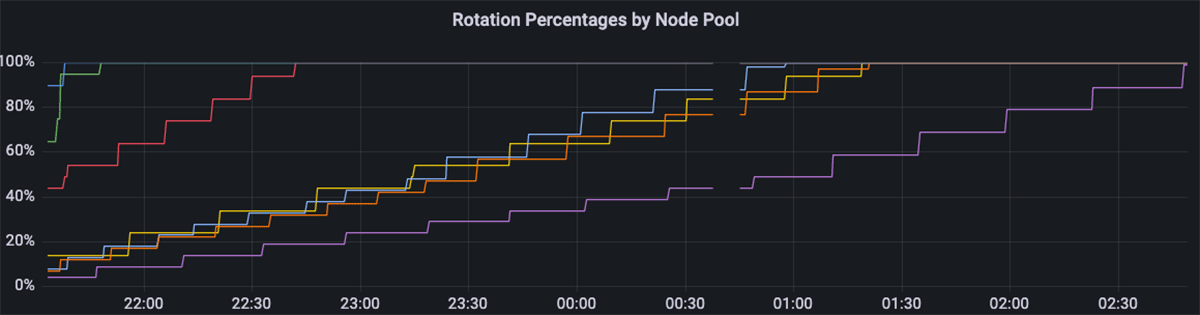
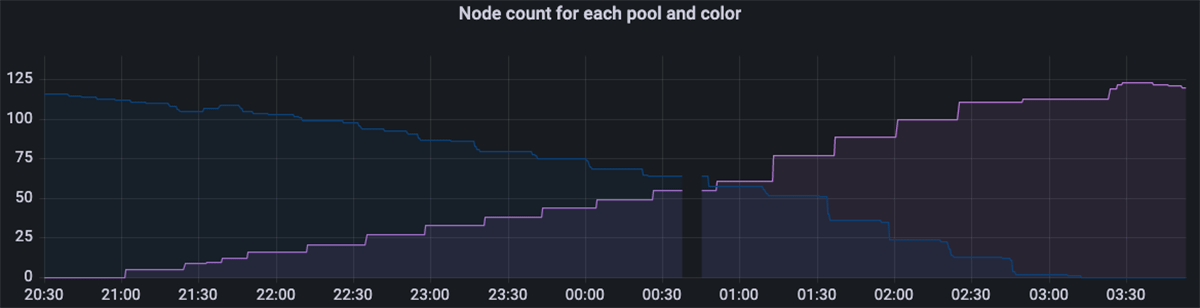
There can be gaps of up to a few minutes in the metrics, because as mentioned in the "Node-drain operator" section, the operators themselves, which are single-replica, are drained and re-spawned during an upgrade, but this has minimal impact on the accuracy of our metrics.
Only non-self-recoverable issues will cause an alert and page the oncall engineer. This is done by exporting Prometheus metrics tracking all non-self-recoverable errors, and by adding a timeout alert in case the node-pool-rotation operator has not made progress (i.e. stuck at a checkpoint for a certain percentage of new nodes brought up thus far) for several hours.
Results
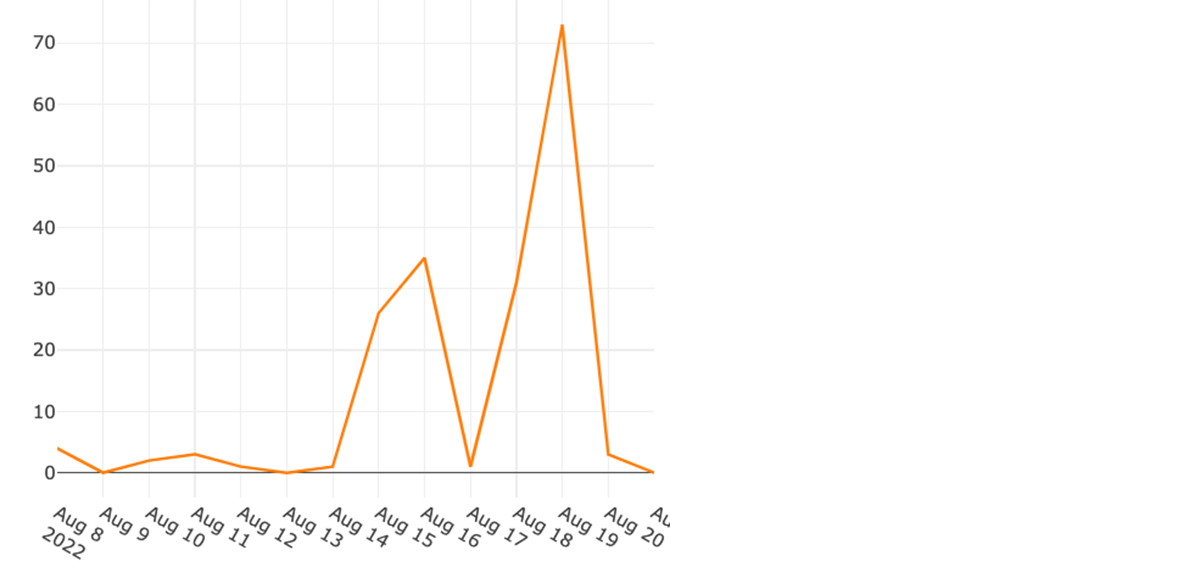
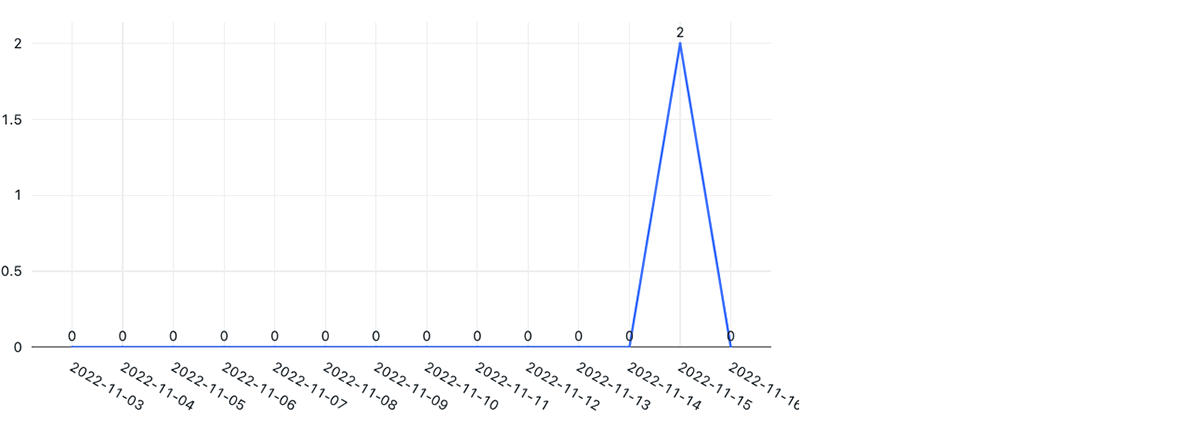
The new node upgrade architecture significantly improved operational efficiency (number of incidents due to node upgrade system failures reduced by more than 95%), operation velocity (reduced the time to upgrade each Kubernetes cluster by about 90%), and testability (in addition to our end-to-end tests, we achieved a unit test code coverage of >95%). Below are the number of daily incidents during our node update weeks in the legacy vs. new system.
What's next
We will work on improving our infrastructure to reduce and hope to eliminate the remaining failures that can happen during the node upgrade process. We are optimistic that soon we will achieve zero-touch, fully automated node upgrades in our entire Kubernetes fleet.
Conclusion
By utilizing Kubernetes operators, we have built a scalable, reliable, high-performance, automated node upgrade system that can tolerate any recoverable issues during upgrades. We greatly reduced our operational load, allowing our software engineers to spend their time on more productive tasks.
Databricks is working on many exciting projects in large-scale multi-cloud Kubernetes cluster management, container orchestration and isolation, cloud infrastructure, and distributed systems. If any of these topics interest you, please consider joining us, in San Francisco/Mountain View, Amsterdam, or our new Seattle location!
Acknowledgements
We'd like to thank the team (Tian Ouyang, Xuejia Lu, Max Wolffe, Charlene Zhao, Tony Zhao) for working together on designing and implementing this Kubernetes node upgrade system.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.