Unlock Faster Machine Learning with Graviton
Databricks Machine Learning Runtime now supports Graviton
by Ying Chen, Lu Wang (Databricks) and Lin Yuan
We are excited to announce that Graviton, the ARM-based CPU instance offered by AWS, is now supported on the Databricks ML Runtime cluster. There are several ways that Graviton instances provide value for machine learning workloads:
- Speedups for various machine learning libraries: ML libraries like XGBoost, LightGBM, Spark MLlib, and Databricks Feature Engineering could see up to 30-50% speedups.
- Lower cloud vendor cost: Graviton instances have lower rates on AWS than their x86 counterparts, making their price performance more appealing.
What are the benefits of Graviton for Machine Learning?
When we compare Graviton3 processors with an x86 counterpart, 3rd Gen Intel® Xeon® Scalable processors, we find that Graviton3 processors accelerate various machine learning applications without compromising model quality.
- XGBoost and LightGBM: Up to 11% speedup when training classifiers for the Covertype dataset. (1)
Databricks AutoML: When we launched a Databricks AutoML experiment to find the best hyperparameters for the Covertype dataset, AutoML could run 63% more hyperparameter tuning trials on Graviton3 instances than Intel Xeon instances, because each trial run (using libraries such as XGBoost or LightGBM) completes faster. (2) The higher number of hyperparameter tuning runs can potentially yield better results, as AutoML is able to explore the hyperparameter search space more exhaustively. In our AutoML experiment using the Covertype dataset, after 2 hours of exploration, the experiment on Graviton3 instances could find hyperparameter combinations with a better F1 score.
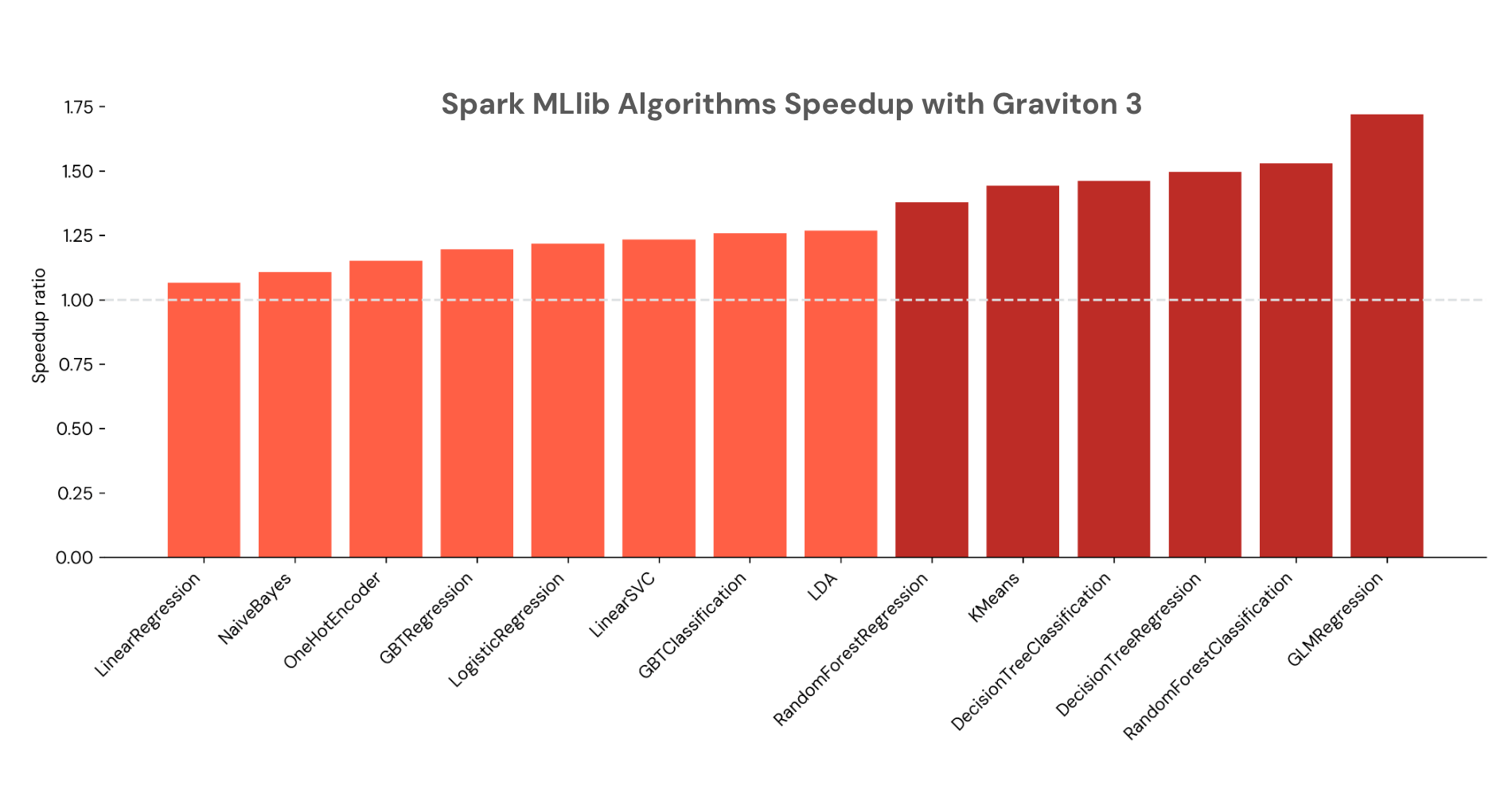
- Spark MLlib: Various algorithms from Spark MLlib also run faster on Graviton3 processors, including decision trees, random forests, gradient-boosted trees, and more, with up to 1.7x speedup. (3)
- Feature Engineering with Spark: Spark's faster speed on Graviton3 instances makes time-series feature tables with a Point-in-Time join up to 1.5x faster than with 3rd Gen Intel Xeon Scalable processors.
What about Photon + Graviton?
As mentioned in the previous blog post, Photon accelerates Spark SQL and Spark DataFrames APIs, which is particularly useful for feature engineering. Can we combine the acceleration of Photon and Graviton for Spark? The answer is yes, Graviton provides additional speedup on top of Photon.
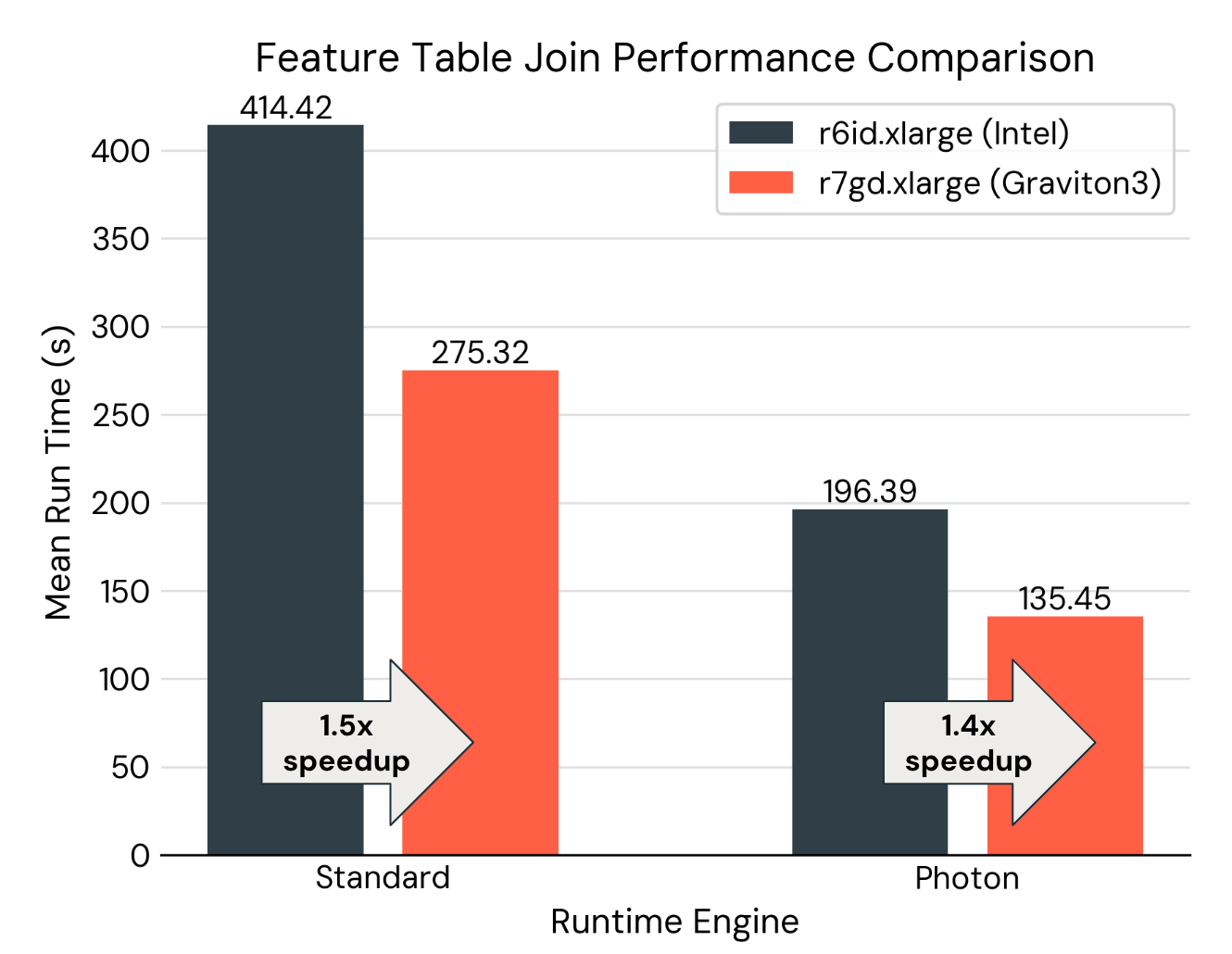
The figure below shows the run time of joining a feature table of 100M rows with a label table. (4) Whether or not Photon is enabled, swapping to Graviton3 processors provides up to a 1.5x speedup. Combined with enabling Photon, there is a total of 3.1x improvement when both accelerations are enabled with Databricks Machine Learning Runtime.
Select Machine Learning Runtime with Graviton Instances
Starting from Databricks Runtime 15.4 LTS ML, you can create a cluster with Graviton instances and Databricks Machine Learning Runtime. Select the runtime version as 15.4 LTS ML or above; to search for Graviton3 instances, type in “7g” in the search box to find instances that have “7g” in the name, such as r7gd, c7gd, and m7gd instances. Graviton2 instances (with “6g” in the instance name) are also supported on Databricks, but Graviton3 is a newer generation of processors and has better performance.

To learn more about Graviton and Databricks Machine Learning Runtime, here are some related documentation pages:
Notes:
- The compared instance types are c7gd.8xlarge with Graviton3 processor, and c6id.8xlarge with 3rd Gen Intel Xeon Scalable processor.
- Each AutoML experiment is run on a cluster with 2 worker nodes, and timeout set as 2 hours.
- Each cluster used for comparison has 8 worker nodes. The compared instance types are m7gd.2xlarge (Graviton3) and m6id.2xlarge (3rd Gen Intel Xeon Scalable processors). The dataset has 1M examples and 4k features.
- The feature table has 100 columns and 100k unique IDs, with 1000 timestamps per ID. The label table has 100k unique IDs, with 100 timestamps per ID. The setup was repeated five times to calculate the average run time.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.