Using Streaming Delta Live Tables and AWS DMS for Change Data Capture From MySQL

In this article we will walk you through the steps to create an end-to-end CDC pipeline with Terraform using Delta Live Tables, AWS RDS, and AWS DMS service. We also provide a GitHub repo containing all scripts.
Note: This article is a follow-up to Migrating Transactional Data to a Delta Lake using AWS DMS. Jump down to Change Data Capture read the beginning of this blog.
Previous blog goes over the Challenges with Moving Data and benefits of Delta Lake excerpt below
Challenges with moving data from databases to data lakes
Large enterprises are moving transactional data from scattered data marts in heterogeneous locations to a centralized data lake. Business data is increasingly being consolidated in a data lake to eliminate silos, gain insights and build AI data products. However, building data lakes from a wide variety of continuously changing transactional databases and keeping data lakes up to date is extremely complex and can be an operational nightmare.
Traditional solutions using vendor-specific CDC tools or Apache SparkTM direct JDBC ingest are not practical in typical customer scenarios represented below:
(a) Data sources are usually spread across on-prem servers and the cloud with tens of data sources and thousands of tables from databases such as PostgreSQL, Oracle, and MySQL databases
(b) Business SLA for change data captured in the data lake is within 15 mins
(c) Data occurs with varying degrees of ownership and network topologies for Database connectivity.
In scenarios such as the above, building a data lake using Delta Lake and AWS Database Migration Services (DMS) to migrate historical and real-time transactional data proves to be an excellent solution. This blog post walks through an alternate easy process for building reliable data lakes using AWS Database Migration Service (AWS DMS) and Delta Lake, bringing data from multiple RDBMS data sources. You can then use the Databricks Unified Analytics Platform to do advanced analytics on real-time and historical data.
What is Delta Lake?
Delta Lake is an open source storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake and is fully compatible with Apache Spark APIs.
Specifically, Delta Lake offers:
- ACID transactions on Spark: Serializable isolation levels ensure that readers never see inconsistent data.
- Scalable metadata handling: Leverages Spark's distributed processing power to handle all the metadata for petabyte-scale tables with billions of files at ease.
- Streaming and batch unification: A table in Delta Lake is a batch table as well as a streaming source and sink. Streaming data ingest, batch historic backfill, interactive queries all just work out of the box.
- Schema enforcement: Automatically handles schema variations to prevent insertion of bad records during ingestion.
- Time travel: Data versioning enables rollbacks, full historical audit trails, and reproducible machine learning experiments.
- Upserts with Managed Delta Lake on Databricks: The MERGE command allows you to efficiently upsert and delete records in your data lakes. MERGE dramatically simplifies how a number of common data pipelines can be built; all the complicated multi-hop processes that inefficiently rewrote entire partitions can now be replaced by simple MERGE queries. This finer-grained update capability simplifies how you build your big data pipelines for change data capture from AWS DMS changelogs.
This is the end of the excerpt from the previous blog.
Gartner®: Databricks Cloud Database Leader

Change Data Capture
As enterprises go along their journey to adopt the Databricks Lakehouse Platform, one of the most important data sources to bring into the data lakehouse is relational databases (RDBMS). These databases often power companies' external/internal applications and having that data in Delta Lake lets them do analysis with enrichment from other data sources, without putting a load on the databases themselves. AWS offers its Relational Database Service (RDS) to easily manage an RDBMS with engines ranging from MySQL and Postgres to Oracle and SQL Server.
Change Data Capture (CDC) is the best and most efficient way to replicate data from these databases. In a CDC process, a listener is attached to the transaction log of the RDBMS and all of the record level changes to the data are captured and written to another location, along with metadata to signify if the change is an Insert, Update, Delete, etc. AWS offers its own service to perform this, called AWS Database Migration Service (DMS). CDC captures the changes from an RDS instance and writes them to S3 on a continuous basis
Once you have configured AWS DMS to write the CDC data to Amazon S3, Databricks makes it easy to replicate this into your Delta Lake and keep the tables as fresh as possible. Delta Live Tables (DLT) with Autoloader can continuously ingest files in a streaming data pipeline as they arrive on S3. When writing to Delta Lake, DLT leverages the APPLY CHANGES INTO API to upsert the updates received from the source database. With APPLY CHANGES INTO, the complexity of checking for the most recent changes and replicating them, in the correct order, to a downstream table is abstracted away. Additionally, the API provides the option to capture the history of all changes using a Type 2 Slowly Changing Dimension update pattern. This preserves the full change history of a record, data that can be extremely valuable in Machine Learning and Predictive Analytics. By seeing the full history of a particular data point, e.g. customer's home address, Data Scientists can build more advanced predictive models.
Architecture overview
Diagram below shows at a high level the services we deploy to build our CDC pipeline.
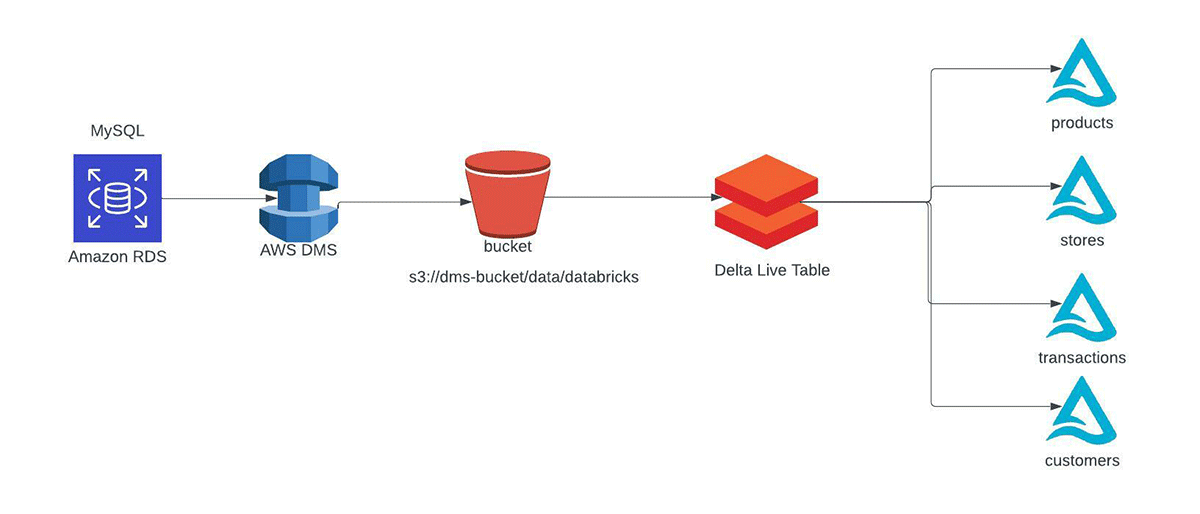
In a production environment the general flow is creating one to many DMS replication tasks that will do a full snapshot and ongoing CDC of a database (or specific tables) from your RDS. These get dropped to S3 as CSV files, which are ingested by Delta Live Tables using Auto Loader into the Bronze table. This Bronze table is then used as the source for APPLY CHANGES INTOprocessing the data into a Silver quality table using SCD Type 1 or Type 2 semantics.
Example usage of the python API for APPLY CHANGES INTO:
The Terraform script will deploy a MySQL instance on AWS RDS and populate it with a database with tables and synthetic data using AWS Lambda. The AWS DMS Instance is created (including all relevant AWS artifacts) and will do an initial snapshot of the table data to S3 and monitor it for any changes. After the initial snapshot is done we then run AWS Lambda again to make updates in the database. AWS DMS will see these changes and pipe them over to S3 in the same location as the full snapshot.
From there we will create an Instance Profile that can access the S3 bucket where the data is located and update the Databricks Cross Account Role with the Instance Profile. Afterwards we will add the Notebook to your workspace and create and run Delta Live Table pipeline with the Instance Profile.
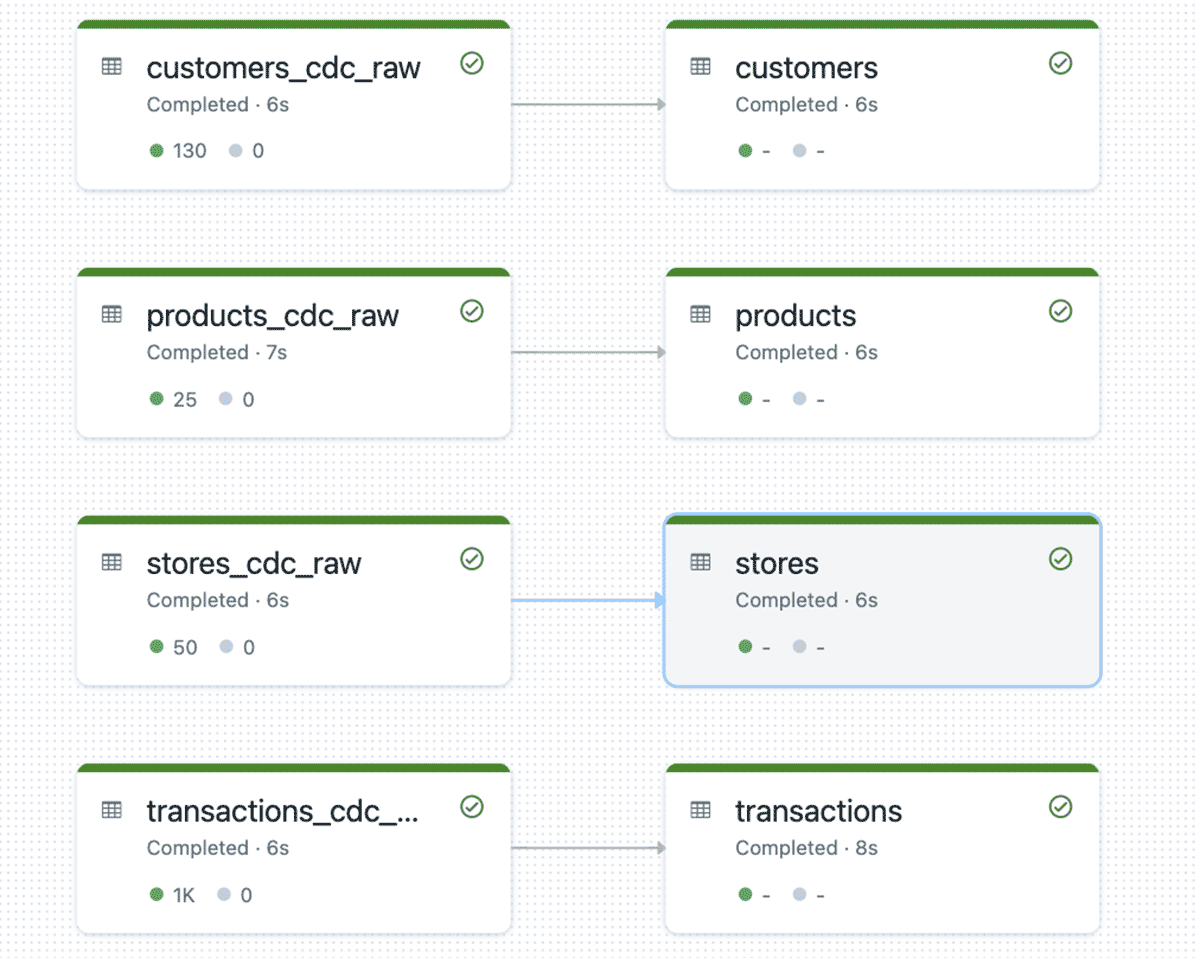
Once this completes, an interactive cluster is created and another notebook is uploaded. A URL will be outputted from Terraform; clicking that link will take you to a notebook that can be attached to the interactive cluster and run.

When you run the notebook you be able to inspect the tables and will l see that it has the columns __START_AT and __END_AT that's because the pipeline runs in SCD Type 2. This lets us easily see that records were updated and when updated the old value has __END_AT filled with timestamp whereas the latest update __END_AT will be NULL indicating that it is the most recent and valid.

How to Run
In order to run this repo there are a set of prerequisites and environment variables needed. Please ensure that all are met in for this demo to run properly.
Prerequisites
- E2 Databricks Workspace
- See Appendix if you need to create WS
- Admin on Databricks Workspace
- We use Admin Databricks Account to keep the demo simple
- Admin on AWS Account
- We use Admin AWS Account here to keep the demo simple
- Needs to run in the same AWS account and region that Databricks is Deployed in
- python3
- pip install databricks-cli
- Terraform Installed
- Make sure TF can authenticate to AWS
- Environment Variable authentication is recommended for the demo
- If you chose an alternative you will need to modify the aws provider blocks to authenticate properly
- Environment Variable authentication is recommended for the demo
- Make sure TF can authenticate to AWS
- Make sure TF can authenticate to Databricks
- Create bash environment variables below
- How to generate PAT
Terraform Environment Variables
As part of this Terraform deployment we need to provide the Databricks Cross Account role name, this lets the deployment apply the IAM instance profile that we need to access the s3 bucket where the s3 files are located.
- When Databricks Workspace is deployed part of the deployment is a Cross Account Role. An example of the ARN
arn:aws:iam::<aws account id>:role/databricks, you need to provide just the role name e.g.
- AWS/Databricks Region where workspace is deployed in
Steps
- Fork https://github.com/databricks/delta-live-tables-notebooks
- Clone your fork
- cd ./dms-dlt-cdc-demo/deployments/dms-dlt-cdc-demo
- terraform init
- terraform plan
- terraform apply -auto-approve
When done you can run terraform destroy, which will tear down AWS RDS, DMS, and Lambda services.
Appendix
If you do not have a Databricks Workspace deployed or wish to deploy a PoC environment for this Blog please follow the instructions below.
Same prerequisites as above aside from the environment variables you will need to provide the following
- Fork https://github.com/databricks/delta-live-tables-notebooks
- Clone your fork
- cd ./dms-dlt-cdc-demo/deployments/e2-simple-workspace
- terraform init
- terraform plan
- terraform apply -auto-approve
When done you can run terraform destroy, which will tear down the databricks workspace and all aws infra associated with it.
Try Databricks for free to run this example.