Product descriptions:
FreeWheel empowers all segments of The New TV Ecosystem. It is structured to provide the full breadth of solutions the advertising industry needs to achieve their goals. It provides the technology, data enablement and convergent marketplaces required to ensure buyers and sellers can transact across all screens, data types and sales channels, in order to ensure the ultimate goal – results for marketers. When FreeWheel sought new ways to enhance operational efficiency for their streaming platform, the company selected Databricks to power the platform, resulting in improved performance for their core business.
Streaming application inefficiencies cost time and money
FreeWheel serves both the supply and demand side of advertising. On the supply side, their SupplySuite product provides a platform for publishers, programmers and distributors to access demand and enable fluid delivery across all endpoints. On the demand side, their DemandSuite product enables advertisers and trading desks to plan and execute ad campaigns, perform bidding in real time on ad inventory, and monitor, analyze and optimize their campaigns. Bidding is a complex, multistage process that occurs in a fraction of a second, resulting in an ad impression.
Enter Beeswax, FreeWheel’s programmatic buying platform on the demand side. “Beeswax offers a best-in-class platform that provides media buyers with full transparency, granular data, better customizability and more control over their campaigns,” Sharif Doghmi, Lead Software Engineer at FreeWheel, said.
Beeswax also contains a data platform with their own streaming application, called Waggle, which reads streaming ad events from a massive Kinesis data stream at over 5GB/s using the Kinesis Client Library (KCL). Waggle then parses, transforms and joins these ad events in a streaming fashion, and routes the output to hundreds of heterogeneous destinations, including S3 data lake, HTTP and Kinesis endpoints. Among those destinations are external customer endpoints receiving streaming ad logs, internal application endpoints and the data platform’s data warehouse, which serves as the single source of truth for Beeswax and is heavily used for reporting and analytics. Waggle is a massive application, built on over 30,000 lines of code, that processes more than 3 million ad events per second, totaling over 400 terabytes of data per day.
This scale posed significant challenges for FreeWheel. The system lacked stability, with frequent instance failures that resulted in lost work that needed to be reprocessed, increasing unnecessary costs. Frozen instances were also common, often requiring manual intervention to diagnose and terminate, taking up valuable time. Maintenance and troubleshooting were complicated and time-consuming, preventing engineers from spending time on higher-value tasks. All of these inefficiencies resulted in higher explicit and implicit costs.
Furthermore, the performance of KCL in terms of processing latency left something to be desired. While processing lag was acceptable most of the time, spikes in lag were happening more than desired for some Kinesis shards. A more stable system with fewer spikes and lower variance in processing latency was desired to improve satisfaction among customers who acted in real time on streaming ad events.
To address these issues, the company redesigned and migrated Waggle from KCL to Spark Structured Streaming on Databricks.
Redesign and migration to Spark Structured Streaming on Databricks
FreeWheel evaluated several streaming processing technologies, including Apache Flink, Apache Storm and others, but ultimately selected Spark Structured Streaming on Databricks because of its maturity, reliability, cost-efficiency and feature-richness. FreeWheel redesigned and migrated Waggle to address system stability, improve operational efficiencies and minimize maintenance and troubleshooting time. “Our strategy involved rearchitecting the system to eliminate unnecessary complexity, adopting Spark Structured Streaming on Databricks and transitioning from a bulky Java-based application to a better-structured Scala-based one, redesigned in a top-down approach with efficiency in mind,” Sharif said.
In the new design, Waggle uses Spark Structured Streaming on the Databricks Data Intelligence Platform. FreeWheel also migrated customer log configurations to Databricks, stored as Delta Tables in Unity Catalog, and plans to migrate more data assets to the Unity Catalog to unlock more of its potential.
Results of the migration include:
-
System performance, as measured by data consumption latency, improved 7-fold (See charts below)
-
Error rates affecting data accuracy and completeness (malformed or missing output records) dropped 4-fold: 15 incidents to now only 4 incidents over comparable 6-month periods
-
System stability, as measured by the frequency of node failures, improved significantly. Node failures — previously a weekly event — are now a very rare event.
-
Time spent maintaining and troubleshooting Waggle has dropped 12-fold, from just under 100 monthly person-hours to around 8
-
More infrastructure management has been delegated to Databricks, freeing up time for developers to focus on higher-value tasks
-
Delivery semantics improved from at-least-once to exactly-once most of the time, reducing duplication, enhancing efficiency and increasing customer satisfaction
-
Complex customer log configurations can now be queried using SQL, which increases their availability, not just to engineers but also to other nontechnical stakeholders who need to explore them often, such as product managers and customer support
Charting the success
The new system improved performance by lowering both the average and maximum latencies across Kinesis shards and time. As can also be seen from the charts, the new system exhibits less variability, and produces more predictable and stable output in terms of processing latency.
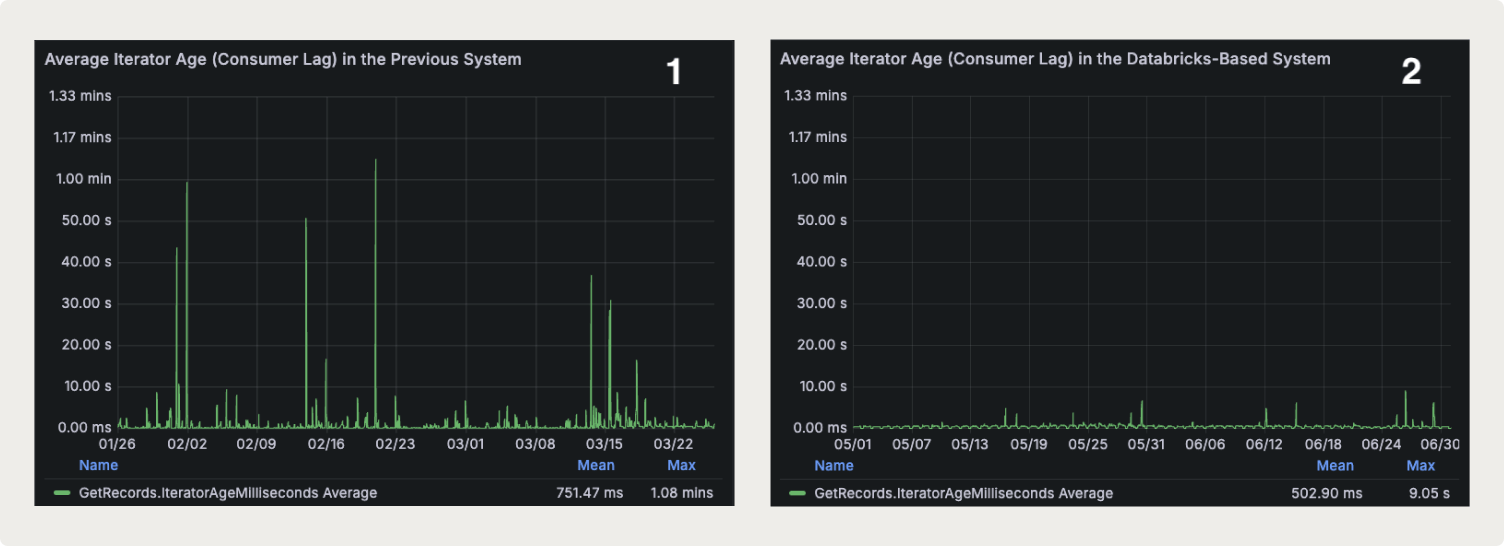
The average Kinesis iterator age (or consumer lag in Kafka terms) across all shards peaked at 1.08 minutes in the previous system over a 2-month period (Chart 1), just before the new Databricks-based system was launched. In comparison, this metric dropped to only 9.05 seconds over a 2-month period after the Databricks system went live (Chart 2), reflecting a 7-fold improvement.
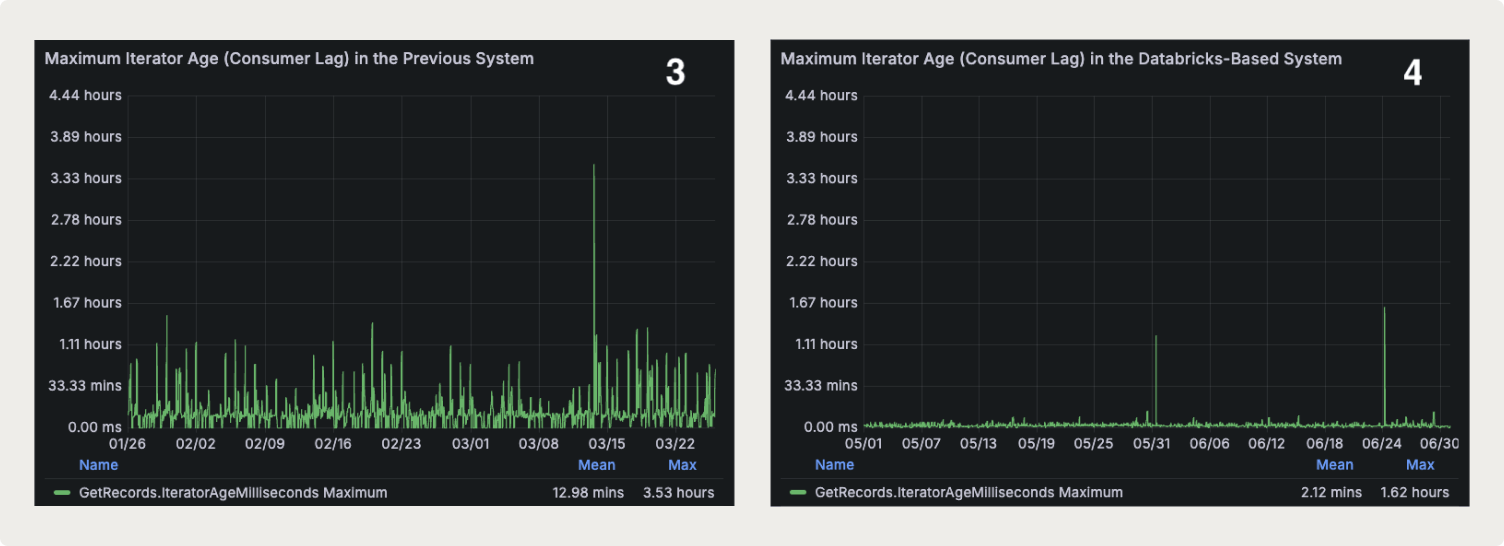
The maximum Kinesis iterator age (or consumer lag in Kafka terms) across all shards averaged 12.98 minutes over a 2-month period in the previous system (Chart 3). With the Databricks system, it decreased to just 2.12 minutes (Chart 4), representing a 6-fold improvement. The worst-case scenario (the highest iterator age recorded across all shards throughout the 2-month period) also improved significantly, dropping from 3.53 hours to 1.62 hours (Chart 4), more than doubling the performance.
Better performance, improved data quality and lower costs
FreeWheel’s redesign and migration of their streaming application using Databricks achieved impressive results. “With Spark Structured Streaming on Databricks, we have enhanced system performance, improved data quality, increased system stability and reduced time spent on system maintenance. This project has set the stage for future innovations and improvements in our data processing capabilities,” Sharif said. Additionally, “Databricks’ Spark implementation has been a game changer for our data processing needs, offering a reliable, mature, flexible and highly efficient platform. The exceptional support from Databricks, combined with the platform’s robust features and performance, has made it an invaluable asset to our data infrastructure,” Donghui Li, Lead Software Engineer at FreeWheel, said.
With their migration to Databricks, FreeWheel also wanted to improve their developer experience. The company leveraged key Databricks features, including:
-
Intuitive APIs such as the DataFrame API, which is simple and unified across batch and streaming applications. It has a rich set of functions and seamlessly integrates with various data sources and storage systems.
-
Databricks Terraform provider, which allows teams to quickly and easily define Databricks infrastructure and resources using code
-
Databricks Asset Bundles, which bring an infrastructure as code (IAC) approach to CI/CD
-
Databricks Assistant, which helps teams generate, explain and fix code. Powered by data intelligence, it uses signals from across the Databricks environment to create context-aware generative AI models that make the assistant more accurate and relevant.
-
AI-generated comments for Unity Catalog tables and columns, which serve as a convenient starting point for developers and can be edited as needed. These suggested comments encourage early documentation and save developers’ time.
FreeWheel is looking forward to implementing Databricks’ serverless streaming and autoscaling. “Adopting serverless technology will help us further delegate more of our infrastructure management to Databricks, and it will allow us to benefit from the economies of scale that come with Databricks’ vast serverless infrastructure,” Sharif said. “It will also give us access to several performance enhancements available on serverless, such as stream pipelining.”
The company will continue to evaluate expanding their Databricks footprint to achieve coordination among their products. This includes migrating other adjacent workloads to Databricks and moving more data stores to Unity Catalog to leverage its powerful features.