Introducing Redshift Data Source for Spark

This is a guest blog from Sameer Wadkar, Big Data Architect/Data Scientist at Axiomine.
The Spark SQL Data Sources API was introduced in Apache Spark 1.2 to provide a pluggable mechanism for integration with structured data sources of all kinds. Spark users can read data from a variety of sources such as Hive tables, JSON files, columnar Parquet tables, and many others. Third party data sources are also available via spark-package.org. This post discusses a new Spark data source for accessing the Amazon Redshift Service. Redshift Data Source for Spark is a package maintained by Databricks, with community contributions from SwiftKey and other companies.
Prior to the introduction of Redshift Data Source for Spark, Spark’s JDBC data source was the only way for Spark users to read data from Redshift. While this method is adequate when running queries returning a small number of rows (order of 100’s), it is too slow when handling large-scale data. The reason being that JDBC provides a ResultSet based approach, where rows are retrieved in a single thread in small batches. Furthermore, the use of JDBC to store large datasets in Redshift is only practical when data needs to be moved between tables inside a Redshift database. The JDBC-based INSERT/UPDATE queries are only practical for small updates to Redshift tables. For users hoping to load or store large volumes of data from/to Redshift, JDBC leaves much to be desired in terms of performance and throughput.
Using this package simplifies the integration with the Redshift service by automating the set of manual steps that would otherwise be required to move large amounts of data in and out of Redshift. To understand how it does so, let us look at how you would integrate large datasets from a Redshift database with datasets from other data sources.
We will also explore how this package expands the range of possibilities for Redshift as well as Spark users. Traditionally, data had to be moved from HDFS to Redshift for analytics. However, this package will allow Redshift to interoperate seamlessly (via the Unified Data Sources API) with data stored in S3, Hive tables, CSV or Parquet files on HDFS. This will simplify ETL pipelines and allow users to operate on a logical and unified view of the system.
Reading from Redshift
Say you want to process an entire table (or a query which returns a large number of rows) in Spark and combine it with a dataset from another large data source such as Hive. The set of commands to load the Redshift table (query) data into a schema compliant DataFrame instance is:
The above command provides a DataFrame instance for the Redshift table (query). The user only needs to provide the JDBC URL, temporary S3 folder to which this package unloads Redshift data, and the name of the table or query.
The DataFrame instance can be registered as a temporary table in Spark and queries can be executed directly against it.
The same results can be achieved using the SQL Command Line Interface (CLI) as follows:
Note how we registered the retrieved Redshift table as a temporary table sales_from_redshift in Spark and executed a query directly on it with:
Under the hood, this package executes a Redshift UNLOAD command (using JDBC) which copies the Redshift table in parallel to a temporary S3 bucket provided by the user. Next it reads these S3 files in parallel using the Hadoop InputFormat API and maps it to an RDD instance. Finally, it applies the schema of the table (or query) retrieved using JDBC metadata retrieval capabilities to the RDD generated in the prior step to create a DataFrame instance.
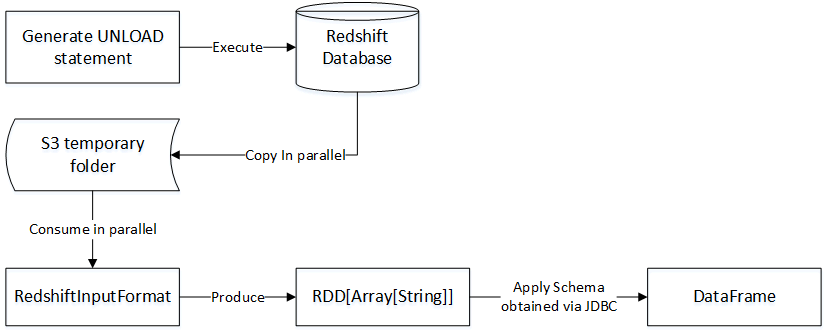
Redshift Data Source for Spark cannot automatically clean up the temporary files that it creates in S3. As a result, we recommend that you use a dedicated temporary S3 bucket with an object lifecycle configuration to ensure that temporary files are automatically deleted after a specified expiration period.
Writing to Redshift
Spark Data Sources API is a powerful ETL tool. A common use case in Big Data systems is to source large scale data from one system, apply transformations on it in a distributed manner, and store it back in another system. For example, it is typical to source data from Hive tables in HDFS and copy the tables into Redshift to allow for interactive processing. This package is perfectly suited for this use case.
Assume that a transaction table sourced from Hive is available in the Spark environment and needs to be copied to a corresponding Redshift table redshift_transaction. The following command achieves this goal:
Using SQL CLI the same results can be obtained as follows:
Note the mode(SaveMode.Overwrite) in the Scala code above. This indicates to Redshift Data Source for Spark to overwrite the table if it exists. By default (only mode available in SQL CLI mode) this package will throw an error if the table already exists.(SaveMode.ErrorIfExists) There is also a SaveMode.Append mode that creates the table if it does not exist and appends to the table if it does exist. The last mode is SaveMode.Ignore which creates the table if it does not exist and quietly ignores the entire command if the table already exists.
Under the hood, Redshift Data Source for Spark will first create the table in Redshift using JDBC. It then copies the partitioned RDD encapsulated by the source DataFrame (a Hive table in our example) instance to the temporary S3 folder. Finally, it executes the Redshift COPY command that performs a high performance distributed copy of S3 folder contents to the newly created Redshift table.

Integration with other Data Sources
Data read via this package is automatically converted to DataFrame objects, Spark’s primary abstraction for large datasets. This promotes interoperability between data sources since types are automatically converted to Spark’s standard representations (for example StringType, DecimalType). A Redshift user can, for instance, join Redshift tables with data stored in S3, Hive tables, CSV or Parquet files stored on HDFS. This flexibility is important to users with complex data pipelines involving multiple sources.
Using Redshift Data Source for Spark
Our goal in this blog entry was to introduce this package and provide an overview on how it integrates Redshift into Spark’s Unified Data Processing platform. To try these new features, download Spark 1.5 or sign up for a 14-day free trial with Databricks today. We also provide a very detailed tutorial. The tutorial will walk you through the process of creating a sample Redshift database. It will then demonstrate how to interact with Redshift via this package from your local development environment.

